My Paper Reading List for 3D Face Reconstructions
[face-reconstruction cvpr ganfit gan 3ddfa prnet deep-learning avatarme mesh avatar 2dasl deca 3d Here is my paper reading lsit for 3D face reconstructions based on Papers with Code. 3D face reconstruction is the task of reconstructing a face from an image into a 3D form (or mesh). Most of the papers on the list are between 2017~2020.
Learning an animatable detailed 3D face model from in-the-wild images
2020
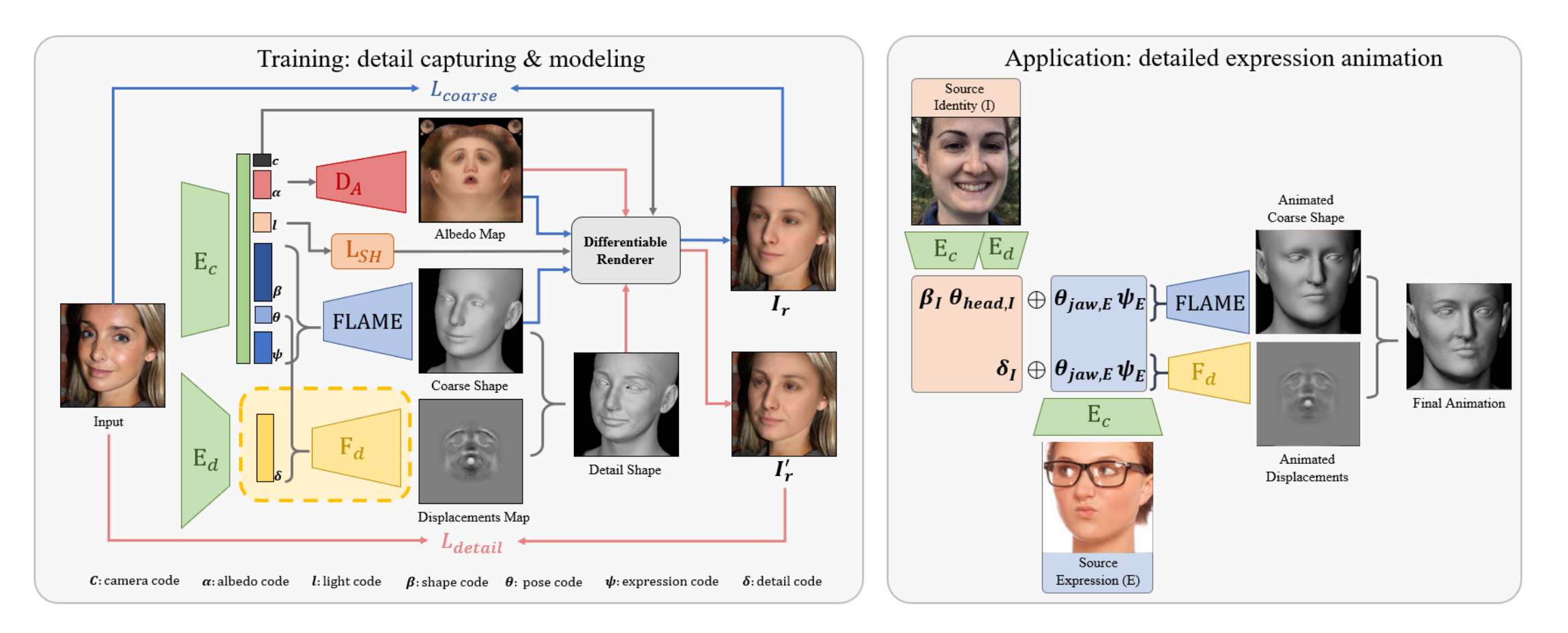
While current monocular 3D face reconstruction methods can recover fine geometric details, they suffer several limitations. Some methods produce faces that cannot be realistically animated because they do not model how wrinkles vary with expression. Other methods are trained on high-quality face scans and do not generalize well to in-the-wild images. We present the first approach to jointly learn a model with animatable detail and a detailed 3D face regressor from in-the-wild images that recovers shape details as well as their relationship to facial expressions. Our DECA (Detailed Expression Capture and Animation) model is trained to robustly produce a UV displacement map from a low-dimensional latent representation that consists of person-specific detail parameters and generic expression parameters, while a regressor is trained to predict detail, shape, albedo, expression, pose and illumination parameters from a single image. We introduce a novel detail-consistency loss to disentangle person-specific details and expression-dependent wrinkles. This disentanglement allows us to synthesize realistic person-specific wrinkles by controlling expression parameters while keeping person-specific details unchanged. DECA achieves state-of-the-art shape reconstruction accuracy on two benchmarks. Qualitative results on in-the-wild data demonstrate DECA’s robustness and its ability to disentangle identity and expression dependent details enabling animation of reconstructed faces. The model and code are publicly available at https://github.com/YadiraF/DECA.
Ganfit: Generative adversarial network fitting for high fidelity 3D face reconstruction
CVPR 2018
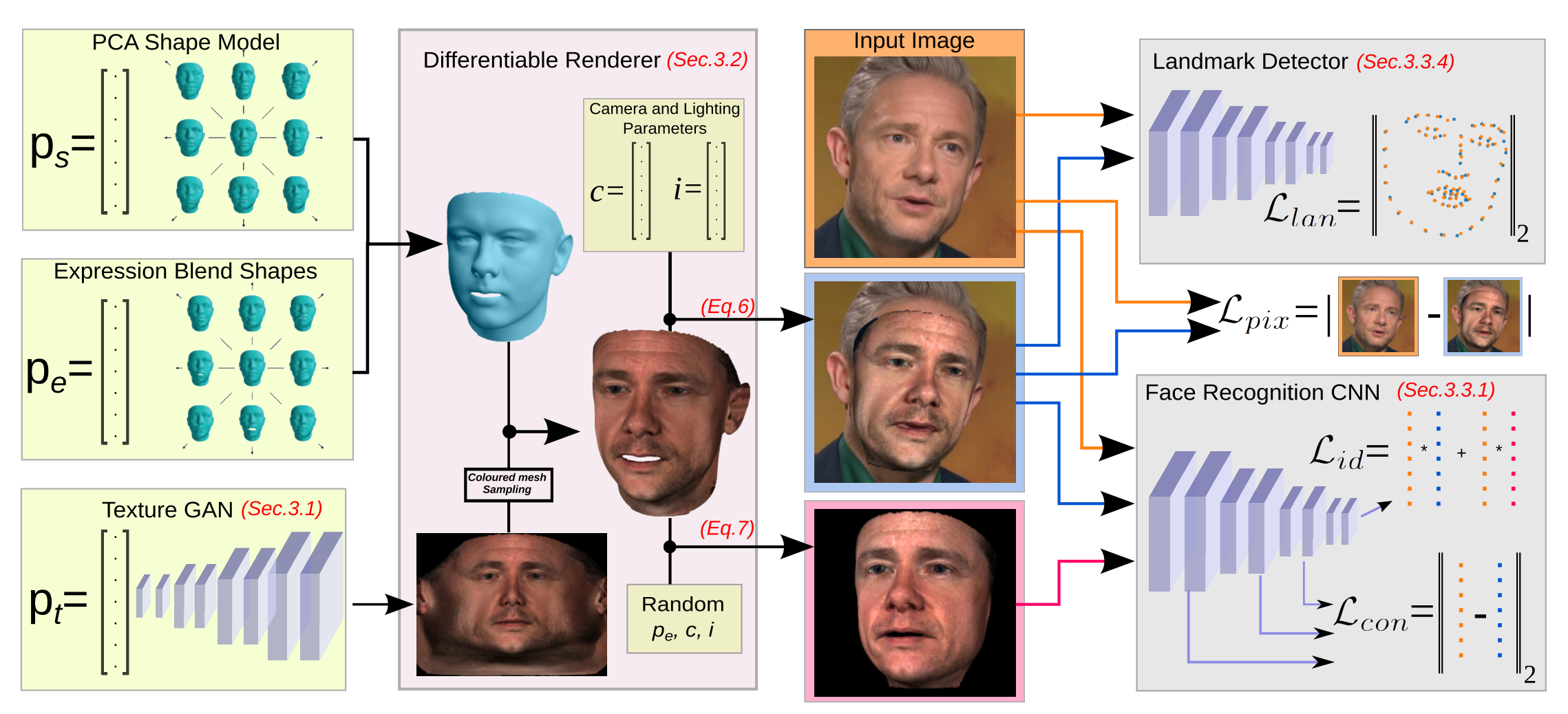
In the past few years, a lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the most recent works, differentiable renderers were employed in order to learn the relationship between the facial identity features and the parameters of a 3D morphable model for shape and texture. The texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction of the state-of-the-art methods is still not capable of modeling textures in high fidelity. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful generator of facial texture in UV space. Then, we revisit the original 3D Morphable Models (3DMMs) fitting approaches making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. We optimize the parameters with the supervision of pretrained deep identity features through our end-to-end differentiable framework. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
Accurate 3D face reconstruction with weakly-supervised learning: From single image to image set
CVPR Workshop 2019
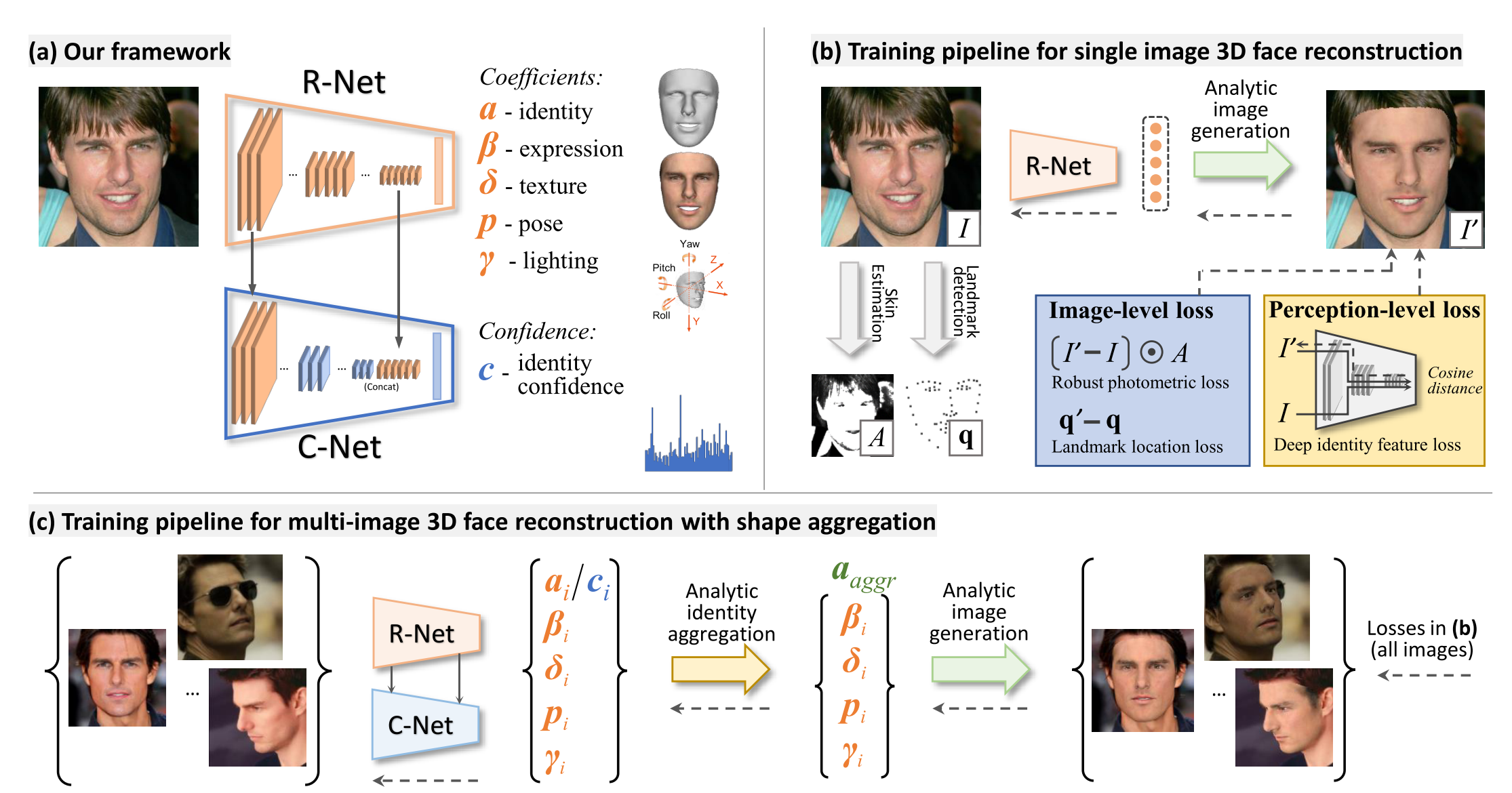
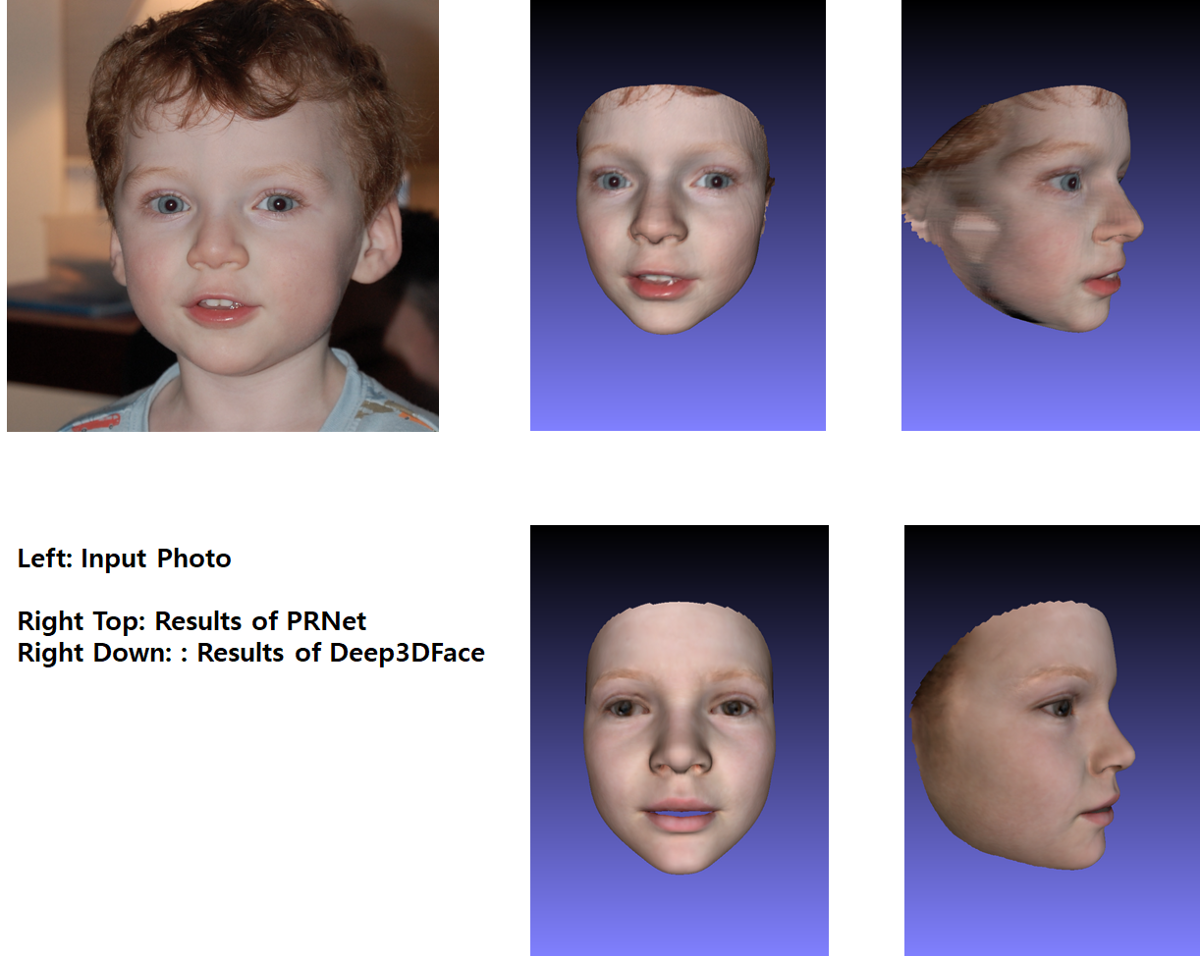
Recently, deep learning based 3D face reconstruction methods have shown promising results in both quality and efficiency. However, training deep neural networks typically requires a large volume of data, whereas face images with ground-truth 3D face shapes are scarce. In this paper, we propose a novel deep 3D face reconstruction approach that 1) leverages a robust, hybrid loss function for weakly-supervised learning which takes into account both low-level and perception-level information for supervision, and 2) performs multi-image face reconstruction by exploiting complementary information from different images for shape aggregation. Our method is fast, accurate, and robust to occlusion and large pose. We provide comprehensive experiments on MICC Florence and Facewarehouse datasets, systematically comparing our method with fifteen recent methods and demonstrating its state-of-the-art performance. Code available at https://github.com/Microsoft/Deep3DFaceReconstruction.
Avatarme: Realistically renderable 3d facial reconstruction ‘in-The-wild’
CVPR 2020
![]()
Over the last years, with the advent of Generative Adversarial Networks (GANs), many face analysis tasks have accomplished astounding performance, with applications including, but not limited to, face generation and 3D face reconstruction from a single ‘in-The-wild’ image. Nevertheless, to the best of our knowledge, there is no method which can produce high-resolution photorealistic 3D faces from ‘in-The-wild’ images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this paper, we introduce AvatarMe, the first method that is able to reconstruct photorealistic 3D faces from a single ‘in-The-wild’ image with an increasing level of detail. To achieve this, we capture a large dataset of facial shape and reflectance and build on a state-of-The-Art 3D texture and shape reconstruction method and successively refine its results, while generating the per-pixel diffuse and specular components that are required for realistic rendering. As we demonstrate in a series of qualitative and quantitative experiments, AvatarMe outperforms the existing arts by a significant margin and reconstructs authentic, 4K by 6K-resolution 3D faces from a single low-resolution image that, for the first time, bridges the uncanny valley.
Unsupervised Training for 3D Morphable Model Regression
CVPR 2018
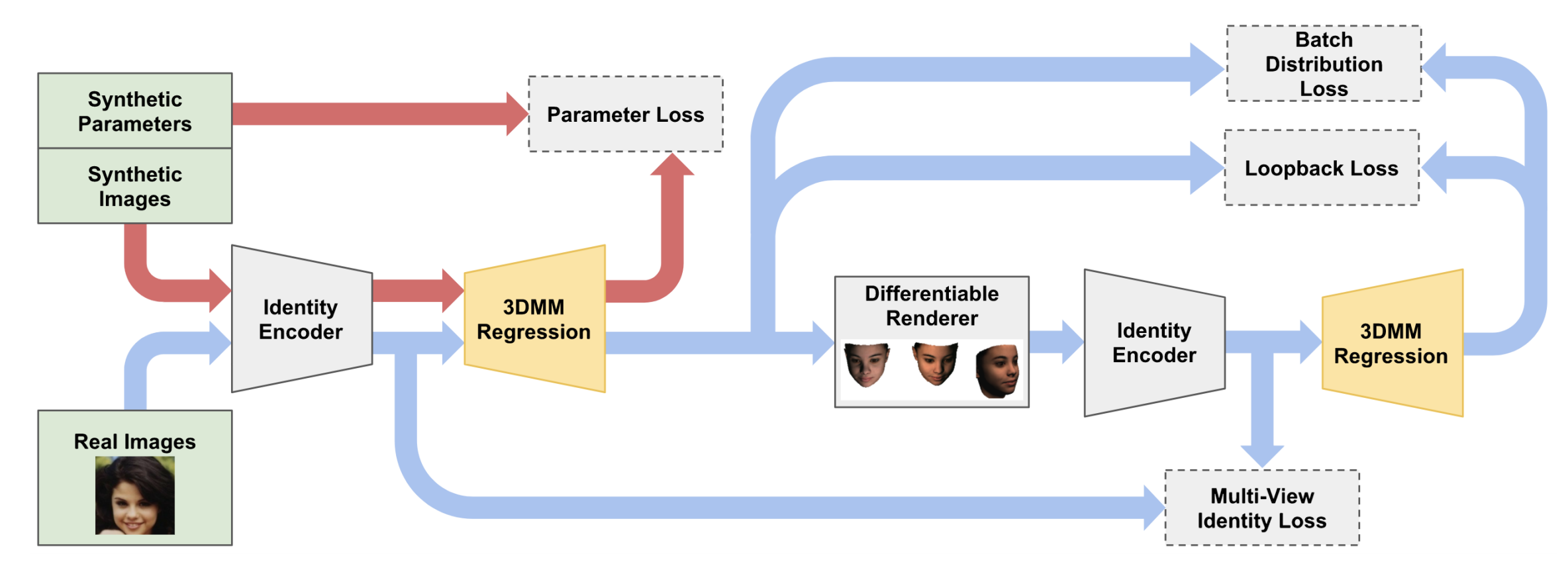
We present a method for training a regression network from image pixels to 3D morphable model coordinates using only unlabeled photographs. The training loss is based on features from a facial recognition network, computed on-the-fly by rendering the predicted faces with a differentiable renderer. To make training from features feasible and avoid network fooling effects, we introduce three objectives: A batch distribution loss that encourages the output distribution to match the distribution of the morphable model, a loopback loss that ensures the network can correctly reinterpret its own output, and a multi-view identity loss that compares the features of the predicted 3D face and the input photograph from multiple viewing angles. We train a regression network using these objectives, a set of unlabeled photographs, and the morphable model itself, and demonstrate state-of-the-art results.
3D Face Reconstruction from A Single Image Assisted by 2D Face Images in the Wild
IEEE Transactions on MultiMedia
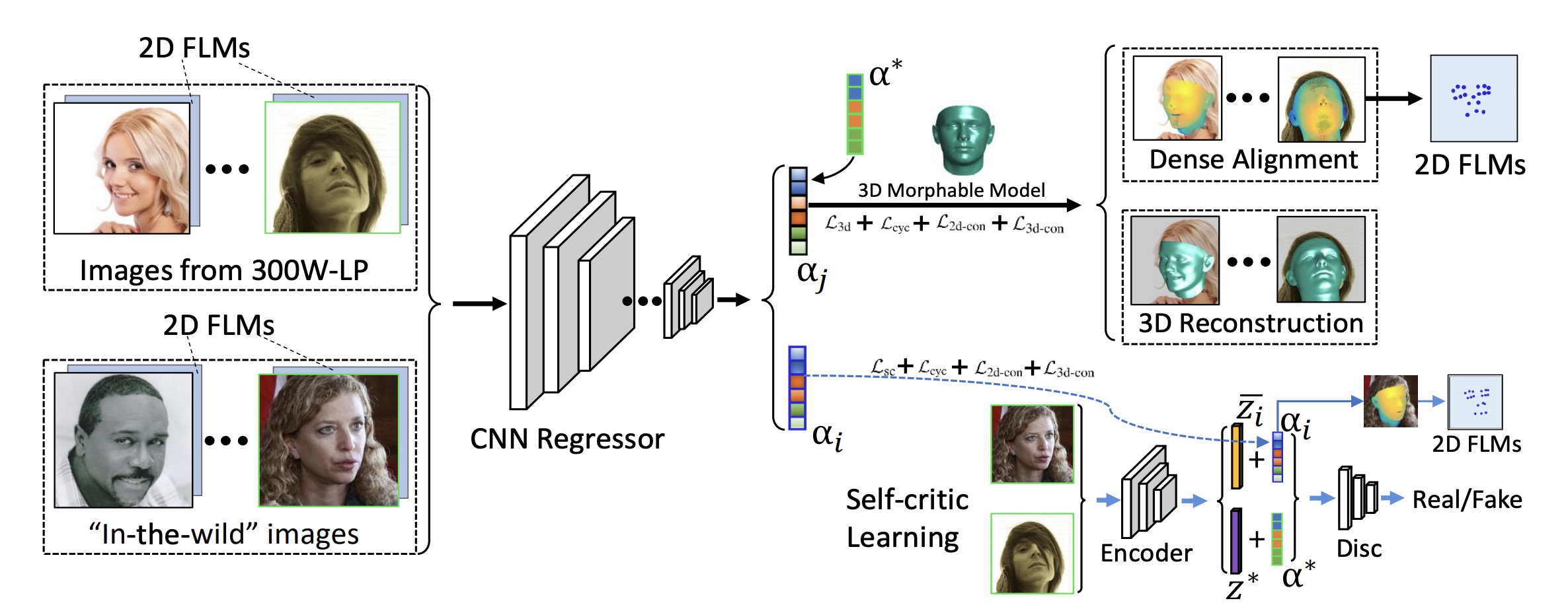
3D face reconstruction from a single image is an important task in many multimedia applications. Recent works typically learn a CNN-based 3D face model that regresses coefficients of a 3D Morphable Model (3DMM) from 2D images to perform 3D face reconstruction. However, the shortage of training data with 3D annotations considerably limits performance of these methods. To alleviate this issue, we propose a novel 2D-Assisted Learning (2DAL) method that can effectively use “in the wild” 2D face images with noisy landmark information to substantially improve 3D face model learning. Specifically, taking the sparse 2D facial landmark heatmaps as additional information, 2DAL introduces four novel self-supervision schemes that view the 2D landmark and 3D landmark prediction as a self-mapping process, including the landmark self-prediction consistency for 2D and 3D faces respectively, cycle-consistency over the 2D landmark prediction and self-critic over the predicted 3DMM coefficients based on landmark prediction. Using these four self- supervision schemes, 2DAL significantly relieves the demands for the the conventional paired 2D-to-3D annotations and gives much higher-quality 3D face models without requiring any additional 3D annotations. Experiments on AFLW2000-3D, AFLW-LFPA and Florence benchmarks show that our method outperforms state-of-the-arts for both 3D face reconstruction and dense face alignment by a large margin.
Towards Fast, Accurate and Stable 3D Dense Face Alignment
LNCS 2020
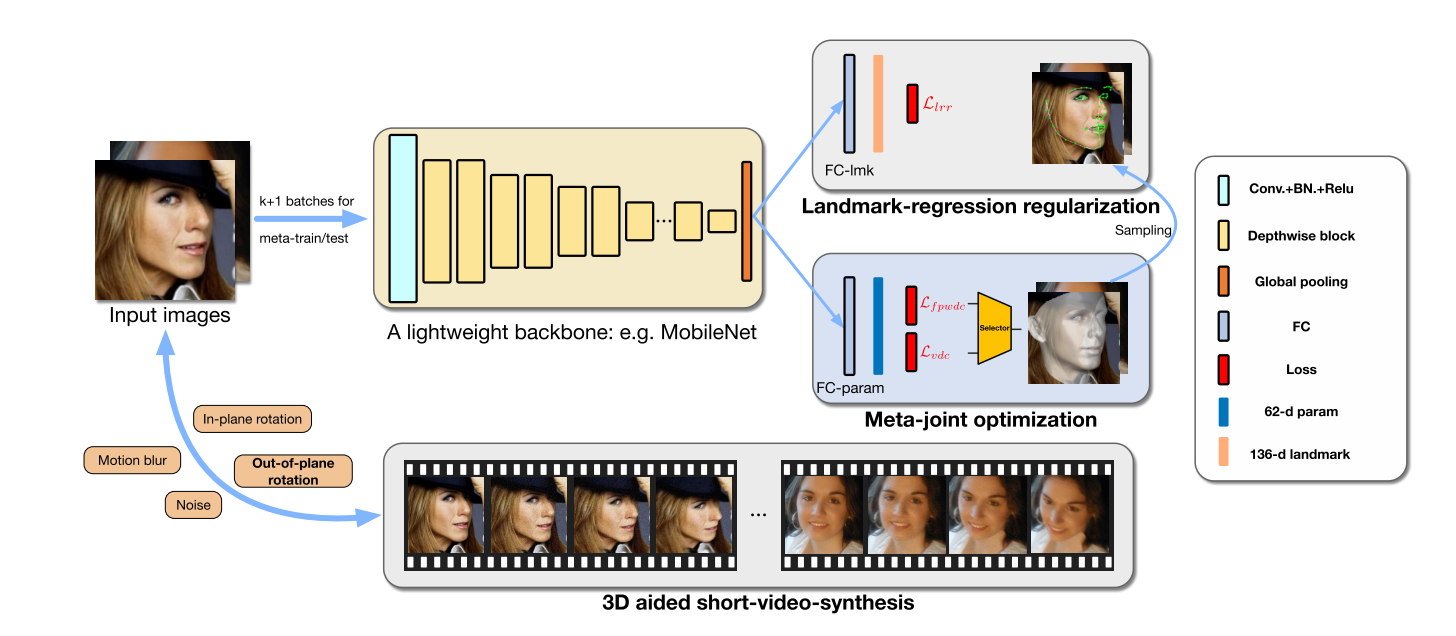
Existing methods of 3D dthus limiting the scope of their practical applications. In this paper, we propose a novel regression framework which makes a balance among speed, accuracy and stability. Firstly, on the basis of a lightweight backbone, we propose a meta-joint optimization strategy to dynamically regress a small set of 3DMM parameters, which greatly enhances speed and accuracy simultaneously. To further improve the stability on videos, we present a virtual synthesis method to transform one still image to a short-video which incorporates in-plane and out-of-plane face moving. On the premise of high accuracy and stability, our model runs at 50 fps on a single CPU core and outperforms other state-of-the-art heavy models simultaneously. Experiments on several challenging datasets validate the efficiency of our method. The code and models will be available at https://github.com/cleardusk/3DDFA_V2.
Learning to regress 3D face shape and expression from an image without 3D supervision
CVPR 2019
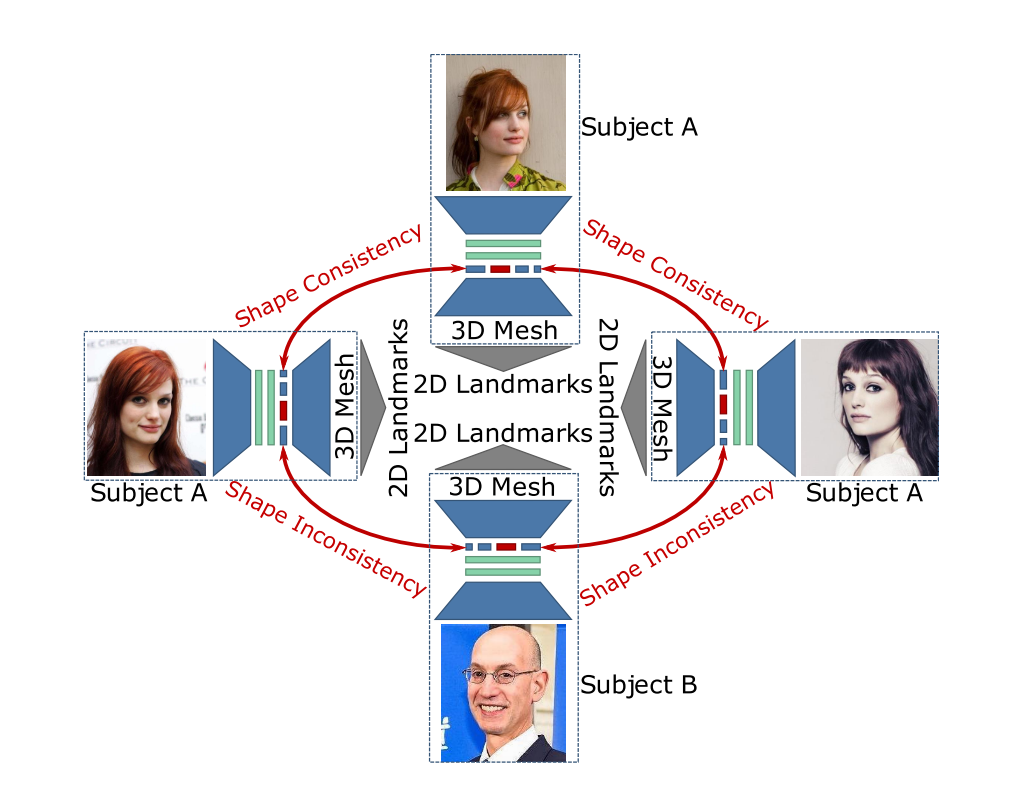
The estimation of 3D face shape from a single image must be robust to variations in lighting, head pose, expression, facial hair, makeup, and occlusions. Robustness requires a large training set of in-the-wild images, which by construction, lack ground truth 3D shape. To train a network without any 2D-to-3D supervision, we present RingNet, which learns to compute 3D face shape from a single image. Our key observation is that an individual’s face shape is constant across images, regardless of expression, pose, lighting, etc. RingNet leverages multiple images of a person and automatically detected 2D face features. It uses a novel loss that encourages the face shape to be similar when the identity is the same and different for different people. We achieve invariance to expression by representing the face using the FLAME model. Once trained, our method takes a single image and outputs the parameters of FLAME, which can be readily animated. Additionally we create a new database of faces ‘not quite in-the-wild’ (NoW) with 3D head scans and high-resolution images of the subjects in a wide variety of conditions. We evaluate publicly available methods and find that RingNet is more accurate than methods that use 3D supervision. The dataset, model, and results are available for research purposes at http://ringnet.is.tuebingen.mpg.de.
Regressing robust and discriminative 3D morphable models with a very deep neural network
CVPR 2017
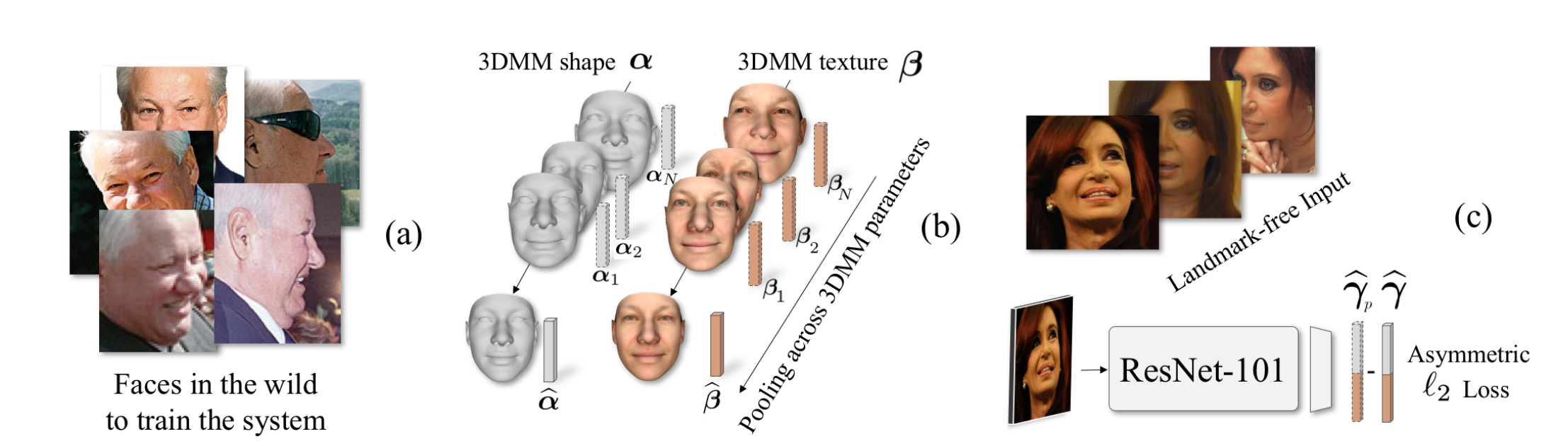
The 3D shapes of faces are well known to be discriminative. Yet despite this, they are rarely used for face recognition and always under controlled viewing conditions. We claim that this is a symptom of a serious but often overlooked problem with existing methods for single view 3D face reconstruction: when applied “in the wild”, their 3D estimates are either unstable and change for different photos of the same subject or they are over-regularized and generic. In response, we describe a robust method for regressing discriminative 3D morphable face models (3DMM). We use a convolutional neural network (CNN) to regress 3DMM shape and texture parameters directly from an input photo. We overcome the shortage of training data required for this purpose by offering a method for generating huge numbers of labeled examples. The 3D estimates produced by our CNN surpass state of the art accuracy on the MICC data set. Coupled with a 3D-3D face matching pipeline, we show the first competitive face recognition results on the LFW, YTF and IJB-A benchmarks using 3D face shapes as representations, rather than the opaque deep feature vectors used by other modern systems.
Joint 3d face reconstruction and dense alignment with position map regression network
LNCS 2018

We propose a straightforward method that simultaneously reconstructs the 3D facial structure and provides dense alignment. To achieve this, we design a 2D representation called UV position map which records the 3D shape of a complete face in UV space, then train a simple Convolutional Neural Network to regress it from a single 2D image. We also integrate a weight mask into the loss function during training to improve the performance of the network. Our method does not rely on any prior face model, and can reconstruct full facial geometry along with semantic meaning. Meanwhile, our network is very light-weighted and spends only 9.8Â ms to process an image, which is extremely faster than previous works. Experiments on multiple challenging datasets show that our method surpasses other state-of-the-art methods on both reconstruction and alignment tasks by a large margin. Code is available at https://github.com/YadiraF/PRNet.
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression
ICCV 2017
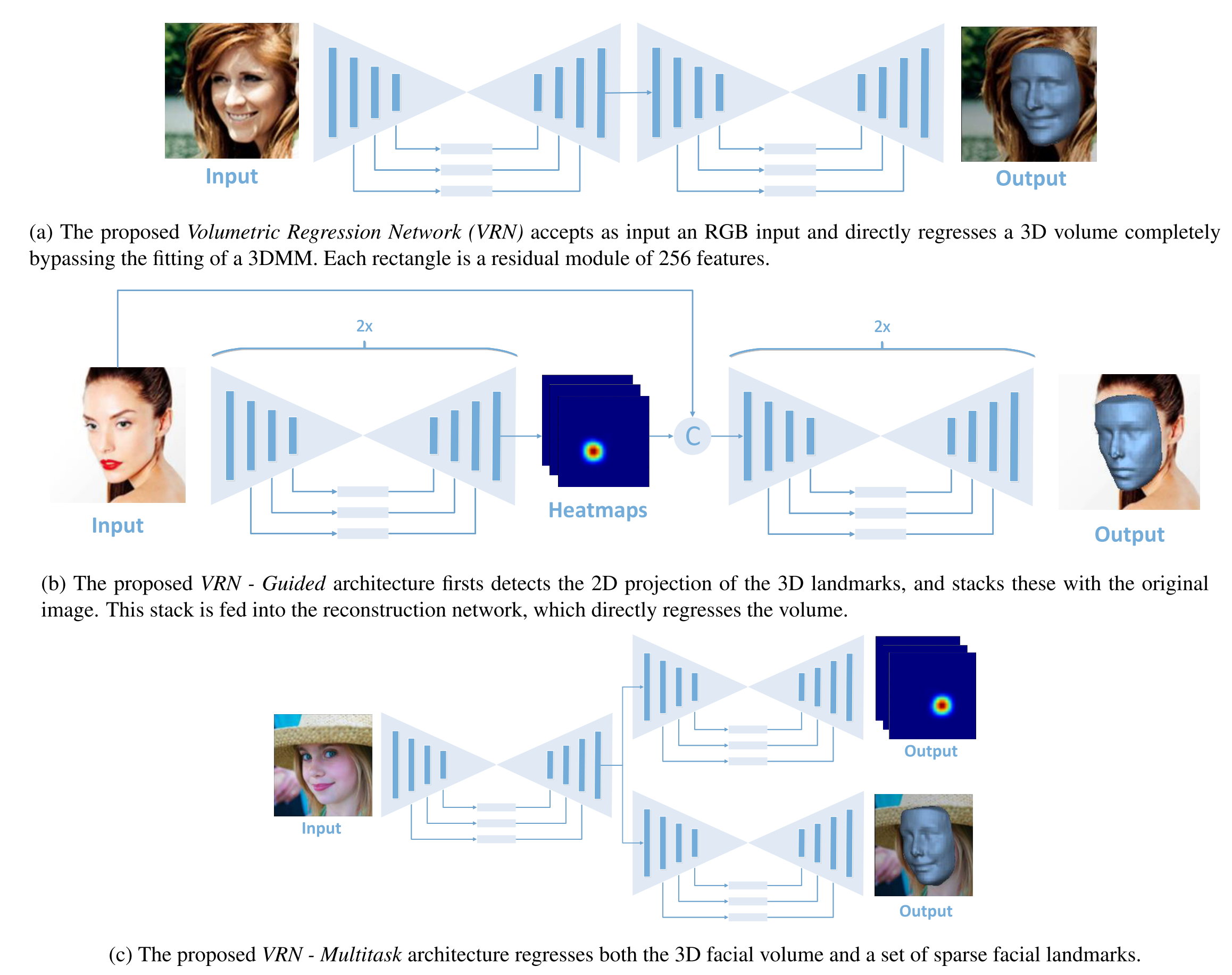
3D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty. Current systems often assume the availability of multiple facial images (sometimes from the same subject) as input, and must address a number of methodological challenges such as establishing dense correspondences across large facial poses, expressions, and non-uniform illumination. In general these methods require complex and inefficient pipelines for model building and fitting. In this work, we propose to address many of these limitations by training a Convolutional Neural Network (CNN) on an appropriate dataset consisting of 2D images and 3D facial models or scans. Our CNN works with just a single 2D facial image, does not require accurate alignment nor establishes dense correspondence between images, works for arbitrary facial poses and expressions, and can be used to reconstruct the whole 3D facial geometry (including the non-visible parts of the face) bypassing the construction (during training) and fitting (during testing) of a 3D Morphable Model. We achieve this via a simple CNN architecture that performs direct regression of a volumetric representation of the 3D facial geometry from a single 2D image. We also demonstrate how the related task of facial landmark localization can be incorporated into the proposed framework and help improve reconstruction quality, especially for the cases of large poses and facial expressions.