Tag: deep-learning
Deep learning is a subset of machine learning, which is a type of artificial intelligence (AI). It involves training artificial neural networks with many layers (hence "deep") to learn patterns and representations from large datasets. Deep learning has been particularly successful in tasks like image and speech recognition, natural language processing, and autonomous decision-making, making it a powerful tool for solving complex problems in various domains. It relies on the concept of hierarchical feature extraction to automatically discover and understand data patterns, allowing it to make predictions or classifications without explicit programming.- Inject Semantic Concepts into Image Tagging for Open-Set Recognition (16 Nov 2023)
This is my reading note for Inject Semantic Concepts into Image Tagging for Open-Set Recognition. This paper proposes an image tagging method based on CLIP. The major innovation is the introduction of image tag alignment loss which aligns image feature to the tag description feature. The tag descriptor is generated by LLM to describe the tog in a few sentences
- SAM-CLIP Merging Vision Foundation Models towards Semantic and Spatial Understanding (15 Nov 2023)
This is my reading note for SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding. This paper proposes a method to combine clip and Sam to perform zero shot semantic segmentation. To combined model merges the vision encoder of Sam and clip, but freezes the other encoders and heads. To avoid catastrophe forgetting, The paper uses two stage method, in first stage, only CLIP’S head is fine tuned; in second stage, the shared vision encode and two heads are fine tuned in a multi task way.
- Florence-2 Advancing a Unified Representation for a Variety of Vision Tasks (14 Nov 2023)
This is my reading note for Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks. This paper proposes to unify different vision tasks by formulating them as visual grounded text generation problem where vision task is specified as input text prompt. To this end, it annotates a large image dataset with different annotations.
- Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V (13 Nov 2023)
This is my reading note for Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V. This paper demonstrates how to combine the Sam with gpt-4v to perform more fine grained visual understanding of visual data. To this end, the paper first uses Sam to annotate the image with region marks and number. GPT-4V is then promoted to understand the image with those annotations.
- Chatting Makes Perfect Chat-based Image Retrieval (12 Nov 2023)
This is my reading note for [Chatting Makes Perfect: Chat-based Image Retrieval]. This paper proposes a method on using dialog (questions and answer pairs) to improve text based image retrieval. It experimented with different questioners (human, chatGPT and other LLM) and different answers (human, BLIP2). It showed that, dialog could significantly improves the retrieval performance. However, only chatGPT and human questioners could improve performance with more rounds of conversation.
- mPLUG-Owl2 Revolutionizing Multi-modal Large Language Model with Modality Collaboration (11 Nov 2023)
This is my reading note for mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration. This paper proposes a method to unify visual and text data for multi modal model. To this end, it uses QFormer to extract visual information and concatenate to text and feed to LLM. However, it separates the projection layer and layer norm for visual and text. This paper is similar to COGVLM.
- CogVLM Visual Expert for Pretrained Language Models (10 Nov 2023)
This is my reading note for CogVLM: Visual Expert for Pretrained Language Models. This paper proposes a vision language model similarly to mPLUG-OWL2. To avoid impacting the performance of LLM, it proposes a visual adapter which adds visual specific projection layer to each attention and feed forward layer.
- Ziya2 Data-centric Learning is All LLMs Need (09 Nov 2023)
This is my reading note for Ziya2: Data-centric Learning is All LLMs Need. This paper discusses how to improve LLM performance by improves quality of data.in addition. The supervised learning is found to be more effective than unsupervised learning.
- Tell Your Model Where to Attend Post-hoc Attention Steering for LLMs (08 Nov 2023)
This is my reading note for Tell Your Model Where to Attend: Post-hoc Attention Steering for LLMs. This paper proposes to improve LLM instruction follow performance by changes the attention weight to emphasize contents highlighted by user. The attention head to model is found by profiling the model on a small scale set of data.
- CoVLM Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding (07 Nov 2023)
This is my reading note for CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding. This paper proposes a vision language model to improve the capabilities of modeling composition relationship of objects across visual and text. To do that, it interleaves between language model generating special tokens and vision object detector detecting objects from image.
- TEAL Tokenize and Embed ALL for Multi-modal Large Language Models (06 Nov 2023)
This is my reading note for TEAL: Tokenize and Embed ALL for Multi-modal Large Language Models. This paper proposes a method of adding multi modal input and output capabilities to the existing LLM. To this end, it utilizes VQVAE and whisper to tokenize the image and audio respectively. Only The embedded and projection layer is trained . The result is not SOTA.
- The effectiveness of MAE pre-pretraining for billion-scale pretraining (05 Nov 2023)
This is my reading note for The effectiveness of MAE pre-pretraining for billion-scale pretraining. This paper proposes a pre-pretraining method: starts with MAE and then hashtag based week supervised learning. It shows improvement on over 10 vision tasks and scales by model size as well as dataset size.
- GPT-Fathom Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond (04 Nov 2023)
This is my reading note for GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond. This paper evaluates several LLMs and found 1) openAI’s GPT significantly outperformed all other competitors and Claude 2 is #2; 2) techniques like SFT and RLHF benefits smaller models most; 3) as the model evolves, some metric may slightly degrade.
- VAST A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset (03 Nov 2023)
This is my reading note for VAST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset. This paper proposes a method and a dataset for multimodal content understanding for video (vision, audio, subtitle and text). The major contribution is it proposes to use LLM to fuse different sources of text data (caption, subtitle, ASR text).
- TiC-CLIP Continual Training of CLIP Models (02 Nov 2023)
This is my reading note for TiC-CLIP: Continual Training of CLIP Models. This paper studies the problem of how a model performs as the dataset evolve over time. It then proposes the best solutions base on benchmark, which is fine tuned the existing model on the whole dataset, include both new and old data.
- ConvNets Match Vision Transformers at Scale (01 Nov 2023)
This is my reading note for ConvNets Match Vision Transformers at Scale. This paper shows that given same scale of data and same amount of train resources, CNN could perform similarly as transformer. A similarly observation was reported in # Battle of the Backbones A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
- The Impact of Depth and Width on Transformer Language Model Generalization (31 Oct 2023)
This is my reading note for The Impact of Depth and Width on Transformer Language Model Generalization. This paper shows that deeper transformer is necessary to have a good performance. Usually 4 to 6 layers is a good choice.
- CapsFusion Rethinking Image-Text Data at Scale (30 Oct 2023)
This is my reading note for CapsFusion: Rethinking Image-Text Data at Scale. The paper studies the quality of caption data in vision language dataset and shown the simple caption limits the performance of the trained model. The caption of those dataset is generated synthetic and filter out a lot of real would knowledge. As a result, the paper proposes to use chatGPT to combine the synthetic caption and raw caption to generates a better caption. It’ then results in a much
- Battle of the Backbones A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks (29 Oct 2023)
This is my reading note for Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks. This paper benchmarks different vision backbones and found that supervised ConvNext may show best performance. After it, supervised swin-transformer and clip based transformer is also very competitive. Different vision tasks shows highly correlated performance for different backbones.
- A Picture is Worth a Thousand Words Principled Recaptioning Improves Image Generation (28 Oct 2023)
This is my reading note for A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation. The papers found that the text data used to train text to image model is now quality, which is based alt text of images.it proposed to use an image caption model to generate high quality text for the images; then the diffusion model trained from this new text data show much better performance.
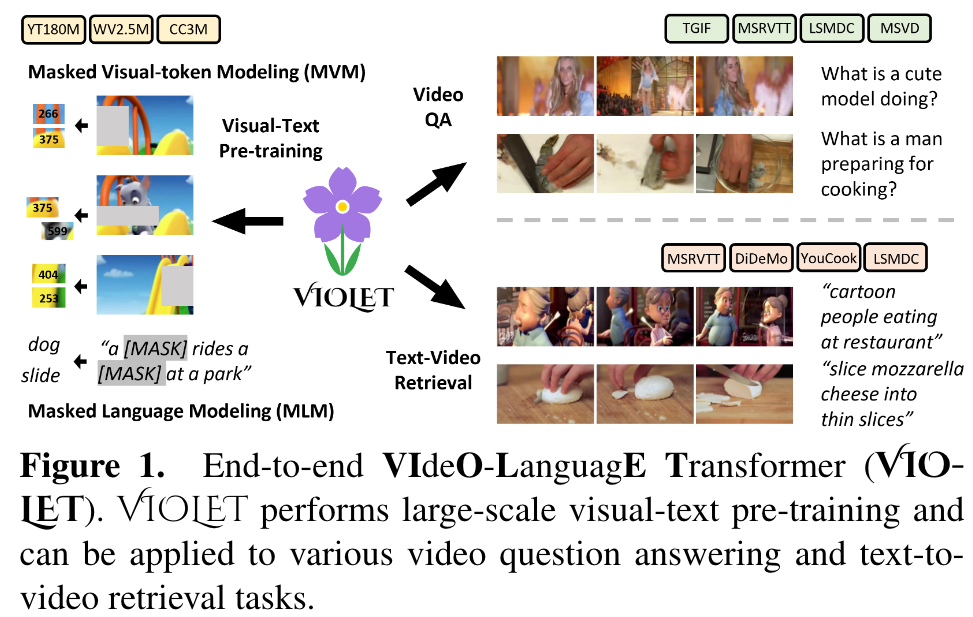
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- Flamingo a Visual Language Model for Few-Shot Learning (26 Oct 2023)
This is my reading note for Flamingo: a Visual Language Model for Few-Shot Learning. This paper proposes to formulate vision language model vs text prediction task given existing text and visual. The model utilizes frozen visual encoder and LLM, and only fine tune the visual adapter (perceiver). The ablation study strongly against fine tune/retrain those components.
- MM-VID Advancing Video Understanding with GPT-4V(ision) (25 Oct 2023)
This is my reading note for MM-VID: Advancing Video Understanding with GPT-4V(ision). The paper proposes a system of understanding long video based on GPT 4V. To this end it first converts long video to short clips and pass every frames of clips to GPT 4V to generate text description. This description, together with audio transcription, is then ted to GPT 4U for final video understand. The analyst is based user ratings between normal vision subjects and vision impaired subjects.
- Florence A New Foundation Model for Computer Vision (24 Oct 2023)
This is my reading note for Florence: A New Foundation Model for Computer Vision. This paper proposes a foundation model for vision (image/video) and text based on UniCL loss. It uses Swin-transformer and Roberta for the encoder.
- Unified Contrastive Learning in Image-Text-Label Space (23 Oct 2023)
This is my reading note for Unified Contrastive Learning in Image-Text-Label Space. This paper proposes to combine label in image-text contrast loss. It treats the image or text from the same labels are from the same class and thus is required to have higher similarity; in contrast loss of CLIP, image/text is required to be similar if they are from the same pair.
- OmniVL One Foundation Model for Image-Language and Video-Language Tasks (22 Oct 2023)
This is my reading note for OmniVL:One Foundation Model for Image-Language and Video-Language Tasks. The paper proposes a vision language pre-training method optimized to linear probe for classification problem. To this end, it modifies the contrast loss by creating positive. samples from the images of same label class.
- VPA Fully Test-Time Visual Prompt Adaptation (21 Oct 2023)
This is my reading note for VPA: Fully Test-Time Visual Prompt Adaptation. VPA introduces a small number of learnable tokens, enabling fully test-time and storage-efficient adaptation without necessitating source-domain information.
- Video Language Planning (20 Oct 2023)
This is my reading note for Video Language Planning. This paper proposes to combine a video-language model and text to video generation model for visual planning: video-language models creates a execution plan given an image as current state and a text as the goal; text-to-video generation model generates a video given the plan; finally video-language models validated the plan via the generated videos.
- Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training (19 Oct 2023)
This is my reading note for Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training. This paper proposes several methods to improve image-text model pre-training: 1) filtering the dataset according complexity, action and text spotting (CAT); 2) concept distillation (object category and attributes); 3) hard negative mining for contrast pairs.
- In-Context Pretraining Language Modeling Beyond Document Boundaries (18 Oct 2023)
This is my reading note for In-Context Pretraining: Language Modeling Beyond Document Boundaries. This paper proposes to group relevant instead of random documents in each batch to improve Long text learning. The relevant docs are found by performs a traveling salesmen problem in a graph of documents. The edges of two documents define whether the two documents are in the top k nearest neighbors.
- InstructBLIP Towards General-purpose Vision-Language Models with Instruction Tuning (17 Oct 2023)
This is my reading note for InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. The paper proposes an extension of blip 2 with institution tuning. This has dramatically improved the performance to unseen tasks. The method is based on query transformer, but adding the tokens from the instruction to guide the feature extraction.
- GIT A Generative Image-to-text Transformer for Vision and Language (16 Oct 2023)
This is my reading note for GIT: A Generative Image-to-text Transformer for Vision and Language. This paper proposes a image-text pre-training model. The model contains visual encoder and text decoder; the text decoder is based on self-attention, which takes concatenated text tokens and visual tokens as input.
- PaLI-3 Vision Language Models Smaller, Faster, Stronger (15 Oct 2023)
This is reading note for PaLI-3 Vision Language Models: Smaller, Faster, Stronger. This paper proposes to use image-text-matching to replace contrast loss. The experiment indicates this method is especially effective in relatively small models.
- Idea2Img Iterative Self-Refinement with GPT-4V(ision) for Automatic Image Design and Generation (14 Oct 2023)
This is my reading note for Idea2Img: Iterative Self-Refinement with GPT-4V(ision) for Automatic Image Design and Generation. This paper proposes a system on how to use GPT4V to generate images from idea by calling an image generation tool. Especially.it generates text prompt based on idea, given the images generated from the prompt, it ranks and selects the best image; it then generate a new promote to guide image generation process.
- Word-As-Image for Semantic Typography (13 Oct 2023)
This is my reading note for Word-As-Image for Semantic Typography. This paper utilized the differential rendering for vector graph to train a diffusion model to generate vector graph for a given text. Check my note for related paper in # VectorFusion Text-to-SVG by Abstracting Pixel-Based Diffusion Models
- VectorFusion Text-to-SVG by Abstracting Pixel-Based Diffusion Models (12 Oct 2023)
This is my reading note for VectorFusion: Text-to-SVG by Abstracting Pixel-Based Diffusion Models. This paper utilized the differential rendering for vector graph to train a diffusion model to generate vector graph for a given text.
- Align before Fuse Vision and Language Representation Learning with Momentum Distillation (11 Oct 2023)
This is my reading note for Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. The paper proposes a multi modality model which is trained base on contrast loss, mask language modeling and image-text match. To handle noisy pairs of text and image, it track moving average of model and distill to the final model.
- Small-scale proxies for large-scale Transformer training instabilities (09 Oct 2023)
This is my reading note for Small-scale proxies for large-scale Transformer training instabilities. This paper discusses the method to improve model training stability related to hyper parameter.
- A Comprehensive Survey on Multimodal Recommender Systems Taxonomy, Evaluation, and Future Directions (08 Oct 2023)
This is my reading note for A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions. This paper provides a review for multimodality recommendation system. However, it doesn’t cover the method based on transformer. It still provides a good review on the metric of recommendation system.
- RoBERTa A Robustly Optimized BERT Pretraining Approach (07 Oct 2023)
This is my reading note for RoBERTa: A Robustly Optimized BERT Pretraining Approach. This paper revisits the design choice of BERT. It provides that 1) adding more data; 2) using larger batch size; 3) training for more iterations could significantly improves the performance. In addition, using longer sentence/context could also improve performance and next sentence prediction is no longer useful.
- DiffusionDet Diffusion Model for Object Detection (06 Oct 2023)
This is my reading note for DiffusionDet: Diffusion Model for Object Detection. This paper formulates the object detection problem as a diffusion process: recover object bounding box from noisy estimation. The initial estimation could be from purely random Gaussian noise. One benefit of this method is that it could automatically handle different number of bounding boxes
- Efficient Streaming Language Models with Attention Sinks (05 Oct 2023)
This is my reading note for Efficient Streaming Language Models with Attention Sinks. This paper proposes a method to extend a LLM to infinite length text. This method is based on sliding attention plus prepending four sink tokens to aggregate global information. This paper shares similar idea as Vision Transformers Need Registers, which adds addition token to capture global information in attention.
- Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency (04 Oct 2023)
This is my reading note for Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency. The papers proposes a method to train a multi modality model between text and image. Especially, the paper propose cycle consistency loss to leverage unpaired text and image: use image to generate text and use text to recover image and vice verse. It reminds me cycle-GAN paper.
- An Early Evaluation of GPT-4V(ision) (03 Oct 2023)
This is my reading note for An Early Evaluation of GPT-4V(ision). The highlights of our findings are as follows:
- GPT-4V exhibits impressive performance on English visual-centric benchmarks but fails to recognize simple Chinese texts in the images;
- GPT-4V shows inconsistent refusal behavior when answering questions related to sensitive traits such as gender, race, and age;
- GPT-4V obtains worse results than GPT-4 (API) on language understanding tasks including general language understanding benchmarks and visual commonsense knowledge evaluation benchmarks;
- Few-shot prompting can improve GPT-4V’s performance on both visual understanding and language understanding;
- GPT-4V struggles to find the nuances between two similar images and solve the easy math picture puzzles;
- GPT-4V shows non-trivial performance on the tasks of similar modalities to image, such as video and thermal. O (p. 1)
- Raising the Cost of Malicious AI-Powered Image Editing (03 Oct 2023)
This is my reading note for Raising the Cost of Malicious AI-Powered Image Editing. This paper proposes a method to stop an image being edited by on diffusion model. The method is based on adverbial attack: learn a perturbation to the target image such that the model (encoder or diffusion) will generate noise or degraded image. However this method may not always work or may fall when the model changes.
- Aligning Large Multimodal Models with Factually Augmented RLHF (02 Oct 2023)
This is my reading note for Aligning Large Multimodal Models with Factually Augmented RLHF. This paper discusses how to mitigate hallucination for large multimodal model.it proposes two methods, 1) add additional human labeled data to train a reward model to guide the fine tune of the final model: 2) add additional factual data to the reward model besides model’s response.
- DeepSpeed-VisualChat Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention (01 Oct 2023)
This is my reading note for DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention. This paper proposes a method for multi round multi-image multi modality model. The paper utilizes a frozen LLM and visual encoder. The contribution of the paper includes: 1. Casual cross attention method to combine image and multiround text; 2. A new dataset.
- Demystifying CLIP Data (30 Sep 2023)
This is my reading note for Demystifying CLIP Data. This paper reverse engineered the data of CLIP and replicated even outperformed the CLIP.
- Vision Transformers Need Registers (29 Sep 2023)
This is my reading note for Vision Transformers Need Registers. This paper analyzes the attention map of transformer and find too large scale transformer and trained after a long iteration, some token show exceptionally high norm. Those tokens usually correspond to patches in uniform background. Analysis indicates that those tokens are used to store global information. Thus at would heart dense prediction tasks like image segmentation. To tackle this, the paper proposes add additional tokens during trains and inference, but rejecting for outputs.
- LongLoRA Efficient Fine-tuning of Long-Context Large Language Models (27 Sep 2023)
This is my reading note on LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models. The paper proposes a method to fine tune a pretrained LLM to handle long context. To this end, it divide the data into different groups and performed attention within group; for half of heads, it shift the groups by half to enable attention across the groups.
- Video-ChatGPT Towards Detailed Video Understanding via Large Vision and Language Models (26 Sep 2023)
This is my reading note for ideo-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. The paper extends chatGPT to understand the video. It’s based on LLAVA and CLIP. One of the key contribution is that is spatially and temporal pool the per frame visual feature from the clip visual encoder and finally concatenate them as features a video.
- VideoChat Chat-Centric Video Understanding (25 Sep 2023)
This is my reading note for VideoChat: Chat-Centric Video Understanding. The papers extends chatGPT to understand the video. To this end.it develops a video backbone based on BLIP2
- MaMMUT A Simple Architecture for Joint Learning for MultiModal Tasks (24 Sep 2023)
This is my reading note for MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks. The paper proposes an efficient multi modality model. it proposes to unify generative loss (masked language modeling) and contrast loss via a two pass training process. One pass is for generate loss which utilizes casual attention model in text decoder and the other pass is bidirectional text decoding. The order of two passes are shuffled during the training.
- Scaling Vision Transformers (23 Sep 2023)
This is my reading note for Scaling Vision Transformers. This paper provides a detailed comparison and study of designing vision transformer.
- Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone (22 Sep 2023)
This is my reading note for Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone. This papers propose a two-stage pre-training strategy: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data.
- An Empirical Study of Training End-to-End Vision-and-Language Transformers (21 Sep 2023)
This is my reading note for An Empirical Study of Training End-to-End Vision-and-Language Transformers. This paper provides a good review and comparison of multi modality (video and text) model’s design choice.
- FreeU Free Lunch in Diffusion U-Net (20 Sep 2023)
This is my reading note for FreeU: Free Lunch in Diffusion U-Net. The paper analyzed the cause of artifact from diffusion model. The paper should that the backbone (U-Net) captures the global or low frequency information and skip connection capture the fine detail or high frequency information.it also shows that the high frequency information causes artifacts. As a results, this paper proposes increasing weight of half channel of U-Net and suppress the low frequency information from the skip connection
- 360 Reconstruction From a Single Image Using Space Carved Outpainting (19 Sep 2023)
This is my reading note for 360 Reconstruction From a Single Image Using Space Carved Outpainting. This paper proposes a method of 3D reconstruction from a single image. To the it represents the 3D object by NERF and iteratively update the NERF by rendering new view using Dream booth.
- Rerender A Video Zero-Shot Text-Guided Video-to-Video Translation (18 Sep 2023)
This is my reading note on Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation. The paper proposes a method to edit a video given style mentioned in prompt. The method performed diffusion to edit key frames and then propagate the edited key frames to other frames using optical flow. For key frame editing, several attention based constraint is applied to reserve details and consistency, including shape aware, style aware, pixel aware and fidelity aware.
- OmnimatteRF Robust Omnimatte with 3D Background Modeling (17 Sep 2023)
This is my reading note on OmnimatteRF: Robust Omnimatte with 3D Background Modeling. The paper proposes a method for video matting. It models the background as a 3D nerf and each foreground object as 2D image
- NExT-GPT Any-to-Any Multimodal LLM (16 Sep 2023)
This is my reading note for NExT-GPT: Any-to-Any Multimodal LLM. This paper proposes a multiple modality model which could takes multiple modalities as input and output in multiple modalities as well. The paper leverage existing large language model, multiple modality encoder image bind) and multiple modality diffusion model. To Amish the spice of those components, a simple linear projection is used for input and transformer to the output.
- Towards Practical Capture of High-Fidelity Relightable Avatars (15 Sep 2023)
This is my reading note for Towards Practical Capture of High-Fidelity Relightable Avatars. This paper proposes a method to relight mixture volume representation for the face. The major contribution is to explicitly to enforce linearity of light to the network.
- Mobile V-MoEs Scaling Down Vision Transformers via Sparse Mixture-of-Experts (14 Sep 2023)
This is my reading note for Mobile V-MoEs Scaling Down Vision Transformers via Sparse Mixture-of-Experts. This paper proposes a new mixture of experts to reduce the cost of vision transformer. There are two contributions, I) use image level instead of patch level mixture to reduce cost; 2) use super class based router to select experts so each expert could focus on a few related class.
- PhotoVerse Tuning-Free Image Customization with Text-to-Image Diffusion Models (13 Sep 2023)
This is my reading note for PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion. This paper proposes a fine tune free personalized image edit method bases on diffusion. To this end it proposes dual branch to encode text and image feature. Lora is used to update the existing model. it also proposed to use a random fusion injection to condition the attention with image and text embedding. However the paper fails to describe why this random fusion injection is needed.
- Large Language Models as Optimizers (12 Sep 2023)
This is my reading note for Large Language Models as Optimizers. This paper discusses how to prompt larger language model to solve optimization problem, especially how to engineer the prompt to solve the optimization problem. The experiments indicate LLM is capable of solve optimization problem reasonable well, especially when problem is small and starting problem is not far from the final solution.
- MagiCapture High-Resolution Multi-Concept Portrait Customization (11 Sep 2023)
This is my reading note on MagiCapture High-Resolution Multi-Concept Portrait Customization. This paper proposes a diffusion method to apply a style to a specific face image. Both the style and face are given as images. To do this, this paper fine tune existing model with LORA given several new loss functions: one is face identity loss for the face region given a face recognition model; another one is background similarity for the style. The two loss are applied to the latent vector.
- InstructDiffusion A Generalist Modeling Interface for Vision Tasks (10 Sep 2023)
This is my reading note for InstructDiffusion: A Generalist Modeling Interface for Vision Tasks. This paper formulated many vision tasks like segmentation and key point detection as text guided image edit task, and thus can be modeled by diffusion based image edit model. To to that, this paper collects a dataset of different vision tasks, each item contains source image, vision task as text prompt and target image as vision results.
- InstaFlow One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation (09 Sep 2023)
This is my reading note on InstaFlow One Step is Enough for High-Quality Diffusion-Based Text-to-Image. This paper proposes a way to speed up diffusion based method, by achieving high fidelity with one step of diffusion. The key to this method is to use rectified how to straighten the probability flow from model to the final image. After that the model could be distilled to one step diffusion.
- Dynamic Mesh-Aware Radiance Fields (08 Sep 2023)
This is my reading note on Dynamic Mesh-Aware Radiance Fields. This paper proposes a method of rendering NERF with mesh simultaneously. To do that, it modifies the ray trace. To handle occlusion and shadow, SDF is used to represent the surface of NERF and light source is estimated from NERF.
- Key-Locked Rank One Editing for Text-to-Image Personalization (07 Sep 2023)
This is my reading note on Key-Locked Rank One Editing for Text-to-Image Personalization. This paper proposes a personalized image generation method base on controlling attention module of the diffusion model. Especially key captures the layout of concept and value captures the identity of the new concept. A rank one update is applied to the attention weight to this purpose.
- DiffBIR Towards Blind Image Restoration with Generative Diffusion Prior (06 Sep 2023)
This is my reading note on DiffBIR Towards Blind Image Restoration with Generative Diffusion Prior. This paper proposes a two stage method for restore degraded images: stage 1 is trained neural network to recover image degradation; stage 2 is a pretrained diffusion model to restore the details in the image recovered from stage 1.
- Neuralangelo High-Fidelity Neural Surface Reconstruction (03 Sep 2023)
This is my reading note on Neuralangelo: High-Fidelity Neural Surface Reconstruction. This paper proposes a method to reconstruct 3D surface at very high details. The proposed method is based on two improvements: 1) use numerical gradient instead of analytical one to remove non locality 2) use multi resolution instant NGP improve details from coarse to fine.
- Multimodal Learning with Transformers A Survey (02 Sep 2023)
This is my reading note on Multimodal Learning with Transformers A Survey. This a paper provides a very nice overview of the transformer based multimodality learning techniques.
- DreamFusion Text-to-3D using 2D Diffusion (01 Sep 2023)
This is my reading note on DreamFusion: Text-to-3D using 2D Diffusion. This paper proposes a method (score distillation sampling or SDS) to distill a pre-trained text to image diffusion model to a 3D model. The 3D model, which is based on NERF, is trained per text prompt.
- DreamBooth Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation (31 Aug 2023)
This is my reading note on DreamBooth. Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model (Imagen, although our method is not limited to a specific model) such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images.
- MovieChat From Dense Token to Sparse Memory for Long Video Understanding (30 Aug 2023)
This is my reading note on MovieChat: From Dense Token to Sparse Memory for Long Video Understanding. This paper proposes a method for long video understands it utilizes existing image encoder to extract tokens form the video via sliding window. A short term memory is a FIFO of those tokens, a long term memory is to merge the similar tokens. Those short term memory and long term memory are then appended after the question and feed to the LLM. The alignment of visual features to LLM purely depends on the existing image encoder.
- TokenFlow Consistent Diffusion Features for Consistent Video Editing (29 Aug 2023)
This is my reading note on TokenFlow Consistent Diffusion Features for Consistent Video Editing, which is diffusion based on video editing method. This paper proposes a method to edit a video given text prompt. To do this, the paper relies on two things. First, it extracts bey lames from video and perform image on those key frames jointly. In addition, the paper found that the feature in diffusion has strong correspondence to the pixels. As a results it propose to propagate the features of edited key frames to other frames, accord to the correspondence in the original video.
- Diff-Instruct A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models (28 Aug 2023)
This is my reading note on Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models. The paper explains the theory of using a pre-trained diffusion model to guide the training of a generator model.it shows that both DreamFusion and GAN are a special case of it: score distillation sampling (SDS) from DreamFusion uses Dirac distribution to represent the generator while GAN learns a discriminator to represents the distribution of data. To this end, it proposes IKL, which is tailored for DMs by calculating the integral of the KL divergence along a diffusion process (instead of a single step), which we show to be more robust in comparing distributions with misaligned supports.
- Efficient Geometry-aware 3D Generative Adversarial Networks (27 Aug 2023)
This is my reading note on Efficient Geometry-aware 3D Generative Adversarial Networks. EG3D proposes a 20 to 3D generate method base style gan and triplane based nerf. The high level idea is to use style gan to generate triplane, which is then rendered into images. The rendered image is the discriminated to the input images at two resolutions. The camera pose is also required to generate the triplane.
- Tool Learning with Foundation Models (26 Aug 2023)
This is my read note on Tool Learning with Foundation Models This is a nice review paper on how to use LLM with external tool to perform different tasks.
- Knowledge Distillation A Survey (25 Aug 2023)
This is my reading note on Knowledge Distillation: A Survey. As a representative type of model compression and acceleration, knowledge distillation effectively learns a small student model from a large teacher model (p. 1)
- 3D Gaussian Splatting for Real-Time Radiance Field Rendering (24 Aug 2023)
This is my reading note on 3D Gaussian Splatting for Real-Time Radiance Field Rendering(best paper of SIGGRAPH 2023) and its extension Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis, which enables it to track dynamic objects/scenes.
- ProlificDreamer High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation (20 Aug 2023)
This is my reading note on ProlificDreamer High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. This method proposes variational score sampling to replace score distillation sampling to improve the details of text to image or text to 3D models. Project page: https://ml.cs.tsinghua.edu.cn/prolificdreamer/
- Elucidating the Design Space of Diffusion-Based Generative Models (19 Aug 2023)
This is my reading note for Elucidating the Design Space of Diffusion-Based Generative Models. This paper checks the varying design of diffusion method and proposed a unify frame work to incorporate them. Finally the author proposes optimal choice of diffusion method under this frame work.
- Scalable Adaptive Computation for Iterative Generation (18 Aug 2023)
This is my reading note on Scalable Adaptive Computation for Iterative Generation The major innovation here is to map the input token to latents, which is shorter. The latents could be initialized from previous iterations (of diffusion process). As a result, the new method could achieve similar visual fidelity as regular diffusion method but with 1/10 of cost.
Introduction
- NeuralField-LDM Scene Generation with Hierarchical Latent Diffusion Models (17 Aug 2023)
This is my reading note on NeuralField-LDM Scene Generation with Hierarchical Latent Diffusion Models. It trains auto-encoder to project RGB images of scene with camera pose into the latent space (voxel-nerf). It uses three levels of latent to represent the scene and then uses hierarchical latent diffusion model to represent it.
- Unified Model for Image, Video, Audio and Language Tasks (16 Aug 2023)
This is my reading note on Unified Model for Image, Video, Audio and Language Tasks. This paper proposes a data and compute efficient method to train multi modality model. It’s based on multi-stage and multi task learning: in each stage new modality will be added and the model will be initialized from previous stage.
- Teach LLMs to Personalize -An Approach inspired by Writing Education (15 Aug 2023)
This is my reading note on Teach LLMs to Personalize -An Approach inspired by Writing Education. The paper proposes a method to generate personalized answer given a question. The method is based on finds relevant sentences from user’s previous documents given the question.
- FineRecon Depth-aware Feed-forward Network for Detailed 3D Reconstruction (14 Aug 2023)
This is my reading note for FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction. It proposes a high detail surface reconstruction algorithm based voxel volume and multi-view geometry. Two major novelties: improve reconstruction accuracy using a novel MVS depth-guidance strategy and enable the reconstruction of sub-voxel detail with a novel TSDF prediction architecture that can be queriedat any 3D point, using point back-projected fine-grained image features.
- Link-Context Learning for Multimodal LLMs (13 Aug 2023)
This is my meeting note for Link-Context Learning for Multimodal LLMs. It presents a demo of how to use positive and negative example to tell L L m to recognize novel concept.
- AVIS Autonomous Visual Information Seeking with Large Language Models (12 Aug 2023)
This is my reading note on AVIS Autonomous Visual Information Seeking with Large Language Models. The paper proposes a method on how to use L lm to use tools or APIs to solve different visual questions. The biggest contribution is this page collect how seal human uses the same set of tools and APIs to solve different visual question. The collected data generates a translation graph between states and action to take.
- ProPainter Improving Propagation and Transformer for Video Inpainting (10 Aug 2023)
This is my reading note for ProPainter: Improving Propagation and Transformer for Video Inpainting. This paper proposes a video inpainting method which remove object from video while reserving spatial temporal consistency. The paper is based on flow based transformer. Two contributions are made, 1) the consistency to improve flow performance which is applied to both image and feature; 2) reduce the # of tokens of than Horner both spatially and temporally.
- MusicLM Generating Music From Text (09 Aug 2023)
This is my reading note on MusicLM: Generating Music From Text. The paper is mostly extended AudioLM to generate the music from text. To do this it utilizes two off shelf models to provide semantic information of audio and to project text to embed ding of the some space of audio
- MVSNeRF Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo (08 Aug 2023)
This is my reading note for MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo. It first build a cost volume at the reference view (we refer to the view i = 1 as the reference view) by warping 2D neural features onto multiple sweeping planes (Sec. 3.1). It then leverage a 3D CNN to reconstruct the neural encoding volume, and use an MLP to regress volume rendering properties, expressing a radiance field (Sec. 3.2). It leverage differentiable ray marching to regress images at novel viewpoints using the radiance field modeled by the network; this enables end-to-end training of our entire framework with a rendering loss (Sec. 3.3)
- SimVLM Simple Visual Language Model Pretraining with Weak Supervision (07 Aug 2023)
This is my reading note for SimVLM: Simple Visual Language Model Pretraining with Weak Supervision. SimVLM reduces the training complexity by exploiting large-scale weak supervision, and is trained end-to-end with a single prefix language modeling objective
- InternVideo General Video Foundation Models via Generative and Discriminative Learning (06 Aug 2023)
This is my reading note for InternVideo: General Video Foundation Models via Generative and Discriminative Learning. This paper propose to train a multi-modality model for video by utilizes both masked video prediction and contrast loss. However, this paper uses a encoder-decoder for masked video prediction and the other video encoder for contrast loss
- Image as a Foreign Language BEiT Pretraining for All Vision and Vision-Language Tasks (05 Aug 2023)
This is my reading note for Image as a Foreign Language BEiT Pretraining for All Vision and Vision-Language Tasks. The paper proposes a multi modality model which models image data as foreign language and propose only to use masked language models as the pre-train tasks.
- BLIP-2 Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models (04 Aug 2023)
This is my reading note for BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. The paper propose Q former to align the visual feature to text feature. Both visual feature and text feature are extracted from fixed models. Q former learned query and output the visual embeds to the text space.
- DualToken-ViT Position-aware Efficient Vision Transformer with Dual Token Fusion (03 Aug 2023)
This is my reading note for DualToken-ViT Position-aware Efficient Vision Transformer with Dual Token Fusion. The paper discuss efficient transformer, which is based on combining convolution with attention: where convolution extracts local information and then fused with global information via attention.
- Visual Instruction Tuning (02 Aug 2023)
This is my reading note for Visual Instruction Tuning. The paper exposes a method to train a multi-modality model - that woks like chat GPT. This is achieved by building an instruction following dataset that’s paired with images. The model is then trained on this dataset.
- CoCa Contrastive Captioners are Image-Text Foundation Models (31 Jul 2023)
This is my reading note for CoCa: Contrastive Captioners are Image-Text Foundation Models. The paper proposes a multi modality model, especially it models the problem as image caption as well as text alignment problem. The model contains three component: a vision encoder, a text decoder (which generates text embedding ) and a multi modality decoder , which generate caption given image and text embedding.
- FLAVA A Foundational Language And Vision Alignment Model (30 Jul 2023)
This is my reading note for FLAVA: A Foundational Language And Vision Alignment Model. This paper proposes a multi modality model. Especially, the model not only work across modality, but also on each modality and joint modality. To do that, it contains loss functions for both within modality but also across modality. It also proposes to use the same architecture for vision encoder, Text encoder as well as multi -modality encoder.
- AutoCLIP Auto-tuning Zero-Shot Classifiers for Vision-Language Models (29 Jul 2023)
This is my reading note for AutoCLIP: Auto-tuning Zero-Shot Classifiers for Vision-Language Models. This paper proposes a method to use clip for zero shot image classification, to do that, it first generates several prompt to convert class label to text embedding by average. Then the image is processed by visual encoder. The label of image is the one has slowest distance between label embody and image embedding. This paper propose to use soft Max instead of average for label embedding.
- Jointly Training Large Autoregressive Multimodal Models (28 Jul 2023)
This is my reading note for Jointly Training Large Autoregressive Multimodal Models. This paper proposes a multimodality model for generating images. The paper is not just dilution based method but instead auto regressive method.it argues to initialize the model from the weight of frozen models.
- HyperDreamBooth HyperNetworks for Fast Personalization of Text-to-Image Models (27 Jul 2023)
This is my reading note for HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models. This paper improves DreamBooth by applying LORA to improve speed.
- Subject-Diffusion Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning (26 Jul 2023)
This is my reading note for Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning. This paper propose a diffusion method to generate images with given visual concepts and text prompt. Especially the paper is able to hand multiple visual concert jointly. To handle that, the paper detect the visual concepts from the input images, then the segmented images and bounding box are encoded feed into latent diffusion model. To enhance the consistency, the visual embedding is inserted into the text encode of the prompt.
- Efficient Geometry-aware 3D Generative Adversarial Networks (25 Jul 2023)
This is my reading note for Efficient Geometry-aware 3D Generative Adversarial Networks. The paper proposes a 2Dto 3D generate method base style GAN and triplane based NERF. The high level idea is to use style GAN to generate triplane, which is then rendered into images. The rendered image is the discriminated to the input images at two resolutions. The camera pose is also required to generate the triplane.
- AudioGen Textually Guided Audio Generation (24 Jul 2023)
This is my reading note for AudioGen: Textually Guided Audio Generation. This paper propose to use auto regressive model to generate audio condition on text. The audio presentation is based on sound stream on neural sound.
- Make-An-Audio Text-To-Audio Generation with Prompt-Enhanced Diffusion Models (23 Jul 2023)
This is my reading note for Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models. This paper proposes a diffusion model for audio, which uses an auto encoder to convert audio signal to a spectrum which could be natively handled by latent diffusion method.
- Improved Baselines with Visual Instruction Tuning (22 Jul 2023)
This is my reading note for Improved Baselines with Visual Instruction Tuning. This paper shows how to improve the performance of LLAVA with simple methods.
- Large-scale Multi-Modal Pre-trained Models A Comprehensive Survey (21 Jul 2023)
This is my reading note for Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey. It provides an OK review for multimodality pre-trained models without diving too much into details.
- Vision-Language Intelligence Tasks, Representation Learning, and Large Models (20 Jul 2023)
This is my reading note for Vision-Language Intelligence: Tasks, Representation Learning, and Large Models. It is yet another review paper for pre-trained vision-language model. Check my reading note for another review paper in Large-scale Multi-Modal Pre-trained Models A Comprehensive Survey
- The Victim and The Beneficiary Exploiting a Poisoned Model to Train a Clean Model on Poisoned Data (19 Jul 2023)
This is my reading note for The Victim and The Beneficiary: Exploiting a Poisoned Model to Train a Clean Model on Poisoned Data. This paper proposes a method to train a model which is oust to poison data attack.it contains three components: 1) use entropy to filter out poison data; 2) train a network on clean data and improve is robustness by using attention mix; 3) combine both prison data and clean data using semi-supervised learning.
- When Noisy Labels Meet Long Tail Dilemmas A Representation Calibration Method (18 Jul 2023)
This is my reading note for When Noisy Labels Meet Long Tail Dilemmas: A Representation Calibration Method. The paper proposes a method to train model from a dataset contains long tail and noisy labels . It’s based on contrast learning to learn a robust representation of data; then clustering process is applied to recover the true labels.
- Advancing Example Exploitation Can Alleviate Critical Challenges in Adversarial Training (17 Jul 2023)
This is my reading note for Advancing Example Exploitation Can Alleviate Critical Challenges in Adversarial Training. The paper proposes a simple method to improve performance of adversarial learning. It’s based on the observation that some samples has impacts to robustness but not accuracy; Vice verse. Thus it propose a method to adjust the weight of samples according.
- MUGEN A Playground for Video-Audio-Text Multimodal Understanding and GENeration (16 Jul 2023)
This is my reading note for MUGEN: A Playground for Video-Audio-Text Multimodal Understanding and GENeration. In this paper, we introduce MUGEN, a large-scale controllable video-audio- text dataset with rich annotations for multimodal understanding and generation.
- MDETR -Modulated Detection for End-to-End Multi-Modal Understanding (16 Jul 2023)
This is my reading note for MDETR -Modulated Detection for End-to-End Multi-Modal Understanding. This paper proposes a method to learn object detection model from pairs of image and tree form text. The trained model is found to be capable of localizing unseen / long tail category.
- AnyMAL An Efficient and Scalable Any-Modality Augmented Language Model (15 Jul 2023)
This is my reading note for AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model. The papa proposes a multi modality model which uses a projection layer to align the features of frozen modality encoder to the space of frozen LLM
- DreamBooth Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation (14 Jul 2023)
This is my reading note for DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. This paper proposes a personalized method for text to image based on diffusion. To achieve this, it firsts learn to align the visual content to be personalized to a rarely used text embedding, then this text embedding will be insert to the text to control the image generation.
- Teach LLMs to Personalize -An Approach inspired by Writing Education (13 Jul 2023)
This is my reading note for Teach LLMs to Personalize -An Approach inspired by Writing Education. The paper proposes a method to generate personalized answer given a question. The method is based on finds relevant sentences from user’s previous documents given the question.
- BLIP Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (12 Jul 2023)
This is my reading note for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. This paper proposed a multi model method. There are two contribution: 1) it utilizes a mixture of text encoder/decoder for different loss where most parameters are shared except self attention: 2) it proposes a caption-filtering process to clean the nous web data.
- Octopus Embodied Vision-Language Programmer from Environmental Feedback (11 Jul 2023)
This is my reading note for Octopus: Embodied Vision-Language Programmer from Environmental Feedback. The paper proposes a method on how to leverage large language model and vision encoder to perform action in game to complete varying tasks.
- Aligning Text-to-Image Diffusion Models with Reward Backpropagation (10 Jul 2023)
This is my reading note for Aligning Text-to-Image Diffusion Models with Reward Backpropagation. This paper proposes a method how to train diffusion model for a given reward function in a memory efficient way, especially it utilities Lora and checkpoints . To avoid model collapse, it also proposes to randomly truncate number of steps.
- Qwen-VL A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond (09 Jul 2023)
This is my reading note for Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. This paper proposes a vision-language model capable of vision grounding and image text reading. To do that, it considers visual grounding and OCR tasks in pre-training. In architecture, the paper uses Qformer from BLIP2.
- ELECTRA Pre-training Text Encoders as Discriminators Rather Than Generators (09 Jul 2023)
This is my reading note ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. This paper proposes to replace masked language modeling with the discriminator task of whether the token is from the authentic data distribution or fixed by the generator model. Especially the model contains a generator that’s trained with masked language modeling objects and discriminator to classify whether a token is filled by the generator or not.
- PaLI A Jointly-Scaled Multilingual Language-Image Model (08 Jul 2023)
This is my reading note for PaLI: A Jointly-Scaled Multilingual Language-Image Model. This paper formulates all the image-text pretraining tasks as visual question answering. The major contributions of this paper includes 1) shows balanced size of vision model and language model improves performances; 2) training with mixture of 8 tasks is important.
- Segment Anything Meets Point Tracking (07 Jul 2023)
This is my reading note for Segment Anything Meets Point Tracking. This paper combines SAM with point tracker to perform object segment and tracking in video. To to that it use point tracker to track points through the frames.for points of each frame SAM generate masks from the points promote. After every 8 frames, new points will be sampled from the mask.for best performance, 8 positive points and l negative points is recommended.
- Otter A Multi-Modal Model with In-Context Instruction Tuning (05 Jul 2023)
This is my reading note for Otter: A Multi-Modal Model with In-Context Instruction Tuning. It is a replication of Flamingo model trained on MIMIC-IT: Multi-Modal In-Context Instruction Tuning.
- X-CLIP End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval (04 Jul 2023)
This is my reading note for X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. This paper proposes a method on extending clip to video data. it mostly studied how to aggregate the similarity score from the frame level to video level.
- AutoMix Automatically Mixing Language Models (03 Jul 2023)
This is my reading note for AutoMix: Automatically Mixing Language Models. Thy paper posses a verifier to verity the correctness of answer of small model and decide whether need to redirect the question to a larger model.
- MeshDiffusion Score-based Generative 3D Mesh Modeling (02 Jul 2023)
This is my reading note for MeshDiffusion: Score-based Generative 3D Mesh Modeling. This paper represents the 3D mesh as a reformed tetrahedral which is defined on a regular 3D grid with 4 channel features: 3D positional deformation of the vertex and signed distance function values to define the surface.
- Llemma An Open Language Model For Mathematics (02 Jul 2023)
This is my reading note for Llemma: An Open Language Model For Mathematics. This paper proposes to continue the training of code llama on math dataset to improve its performance on math problem.
- Scaling Autoregressive Multi-Modal Models Pretraining and Instruction Tuning (01 Jul 2023)
This is my reading note for Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning. This paper proposes a method for text to image generation which is NOT based on diffusion. It utilizes auto-regressive model on tokens.
- Multi-head or Single-head? An Empirical Comparison for Transformer Training (30 Jun 2023)
This is my reading note for Multi-head or Single-head? An Empirical Comparison for Transformer Training. This paper shows that multi head attention is the same as deeper single head attention, but the later is more direct to train and need special care to initialize.
- Grounding Visual Illusions in Language Do Vision-Language Models Perceive Illusions Like Humans? (29 Jun 2023)
This is my reading note for Grounding Visual Illusions in Language: Do Vision-Language Models Perceive Illusions Like Humans?. This paper shows that larger model though more powerful, also more vulnerable to vision illusion as human does.
- What Does BERT Look At? An Analysis of BERT's Attention (28 Jun 2023)
This is my reading note for What Does BERT Look At? An Analysis of BERT’s Attention. This paper studies the attention map of Bert.it found that the attention map captures information such as syntax and co reference . It also found there is a lot of redundancy in heads of the same layer.
- Localizing and Editing Knowledge in Text-to-Image Generative Models (27 Jun 2023)
This is my reading note for Localizing and Editing Knowledge in Text-to-Image Generative Models. This paper studied how each component of diffusion model contribute to the final result: only that self attention layer of last tokens contribute to the final result. Then it proposes a simple method to perform image editing by modifying that layer.
- Language Is Not All You Need Aligning Perception with Language Models (25 Jun 2023)
This is my reading note for Language Is Not All You Need: Aligning Perception with Language Models. This paper proposes a multimodal LLM which feeds the visual signal as a sequence of embedding, then combines with text embedding and trains in a GPT like way.
- UNITER UNiversal Image-TExt Representation Learning (24 Jun 2023)
This is my reading note for UNITER: UNiversal Image-TExt Representation Learning. This paper proposes a vision language pre training model. The major innovation here is it studies the work region alignment loss as well as different mask region models task.
- SEED-Bench Benchmarking Multimodal LLMs with Generative Comprehension (23 Jun 2023)
This is my reading note for SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension. This paper proposes a benchmark suite of modality LLM. It introduces how is the data created and how is the task derived. For evaluation, it utilizes the model’s output of likelihood of answers instead of directly on text answers.
- Scaling Laws for Generative Mixed-Modal Language Models (22 Jun 2023)
This is my reading note for Scaling Laws for Generative Mixed-Modal Language Models. This paper provides a study of scaling raw on dataset size and model size in multimodality settings.
- Tag2Text Guiding Vision-Language Model via Image Tagging (21 Jun 2023)
This is my reading note for Tag2Text: Guiding Vision-Language Model via Image Tagging. This paper proposes to add tag recognition to vision language model and shows improved performance.
- MEGAVERSE Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks (20 Jun 2023)
This is my reading note for MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks. This paper proposes a new multilingual benchmark to test LLM and provides very limited dataset for multimodality. The language distribution is also strange which houses to much on south, Asia. Overall GPT and Palm get the best performance.
- DALL-E, DALL-E2 and StoryDALL-E (30 Sep 2022)
This my reading note on Zero-Shot Text-to-Image Generation (aka, DALL-E), its extension Hierarchical Text-Conditional Image Generation with CLIP Latents (aka, DALLE-2 or unCLIP) and StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation. DALL-E is a transformer generating image given captions, by autoregressively modeling the text and image tokens as a single stream of data. StoryDALL-E extends DALL-E by generating a sequence of images for a sequence of caption to complete a story.
- Pix2seq A Language Modeling Framework for Object Detection (28 Sep 2022)
Pix2seq: A Language Modeling Framework for Object Detection casts object detection as a language modeling task conditioned on the observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are expressed as sequences of discrete tokens, and we train a neural network to perceive the image and generate the desired sequence. Our approach is based mainly on the intuition that if a neural network knows about where and what the objects are, we just need to teach it how to read them out. Experiment results are shown in Table 1, which indicates Pix2seq achieves state of art result on coco.
- DreamBooth Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation (28 Sep 2022)
This is my reading note on DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. Given as input just a few (3~5) images of a subject, DreamBooth fine-tune a pretrained text-to-image model such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, DreamBooth enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images. (check Figure 1 as an example)
- HeadNeRF A Real-time NeRF-based Parametric Head Model (27 Sep 2022)
HeadNeRF: A Real-time NeRF-based Parametric Head Model provides a parametric head model which could generates photorealistic face images conditioned on identity, expression, head pose and appearance (lighting). Compared with traditional mesh and texture, it provides higher fidelity, inherently differetiable and doesn’t required a 3D dataset; compared with GAN, it provides rendering at different head pose with accurate 3D information. This is achived with NeRF. In addition, it could render in real time (5ms) with a model GPU.
- CLIP Learning Transferable Visual Models From Natural Language Supervision (27 Sep 2022)
This my reading note on Learning Transferable Visual Models From Natural Language Supervision. The proposed method is called Contrastive Language-Image Pre-training or CLIP. State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. We demonstrate that the simple pre-training task of predicting which caption (freeform text instead of strict labeling) goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks.
- pixelNeRF Neural Radiance Fields from One or Few Images (26 Sep 2022)
pixelNeRF: Neural Radiance Fields from One or Few Images tries to learn a discontinuous neutral scene representation from one or few input images. To this end, pixelNeRF introduced an architecture that conditions a NeRF on image inputs in a fully convolutional manner. This allows the network to be trained across multiple scenes to learn a scene prior, enabling it to perform novel view synthesis in a feed-forward manner from a sparse set of views (as few as one).
- NeuMan Neural Human Radiance Field from a Single Video (26 Sep 2022)
NeuMan: Neural Human Radiance Field from a Single Video proposes a novel framework to reconstruct the human and the scene that can be ren- dered with novel human poses and views from just a single in-the-wild video. Given a video captured by a moving camera, we train two NeRF models: a human NeRF model (condition on SMPL) and a scene NeRF model. Our method is able to learn subject specific details, including cloth wrinkles and ac- cessories, from just a 10 seconds video clip, and to provide high quality renderings of the human under novel poses, from novel views, together with the background.
- Nerfies Deformable Neural Radiance Fields (26 Sep 2022)
Nerfies: Deformable Neural Radiance Fields present the first method capable ofphotorealistically reconstructing deformable scenes using photos/videos cap- tured casually from mobile phones. Our approach augments neural radiance fields (NeRF) by optimizing an additional continuous volumetric deformation field that warps each observed point into a canonical 5D NeRF. To avoid local minima, we propose a coarse-to-fine optimization method for coordinate-based models that allows for more robust optimization. To avoid overfit, we propose an elastic regularization ofthe deformation field that further improves robustness.
- NeRF in the Wild (25 Sep 2022)
This note discusses NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. NeRF-W addresses the central limitation of NeRF that we address here is its assumption that the world is geometrically, materially, and photometrically static — that the density and radiance of the world is constant. NeRF-W instead models per-image appearance variations (such as exposure, lighting, weather) as well as model the scene as the union of shared and image-dependent elements, thereby enabling the unsuper- vised decomposition of scene content into “static” and “transient” components.
- GIRAFFE Representing Scenes as Compositional Generative Neural Feature Fields (25 Sep 2022)
This is my reading note for GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields. The paper aims to provide more control to 3D object rendering NeRF. For example moving the objects in the 3D scene, adding/deleting objects and so on. To acheive this, GIRAFFE proposed to model the objects and background in the scene separately and then composite together for the rendering. In addition, different from NeRF, GIRAFFE uses a learned discriminator instead of L2 or L1 loss as loss function, thus it is a GAN.
- Encoding Method for NERF (24 Sep 2022)
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding tries to reduce inference cost with a versatile new input encoding that permits the use of a smaller network without sacrificing quality. This is achieved via a small neural network is augmented by a multiresolution hash table of trainable feature vectors whose values are op- timized through stochastic gradient descent.
- Recent Adavances of Diffusion Models (24 Sep 2022)
This is my 4th note in Diffusion models. For the previous notes, please refer to diffusion and stable diffusion. My contents are based on paper listed in Diffusion Explained and Diffusion Models: A Comprehensive Survey of Methods and Applications.
- unCLIP-Hierarchical Text-Conditional Image Generation with CLIP Latents (23 Sep 2022)
This is my reading note on Hierarchical Text-Conditional Image Generation with CLIP Latents. This paper proposes a two-stage model (unCLIP): a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding, for generating images from text.
- Stable Diffusion (23 Sep 2022)
This is my 2nd reading note on diffusion model, which will focus on the
stabe diffusion, aka High-Resolution Image Synthesis with Latent Diffusion Models. By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. However, as mentioned in diffusion, DM sufferes high computational cost. The proposed Latent Diffusion Models (LDM) reduces the computational cost via latent space and introduces cross-attention to enable multi-modality conditioning. - Diffusion Model (22 Sep 2022)
This is my 1st reading note of on recent progress of difussion model. It is based on Diffusion Models: A Comprehensive Survey of Methods and Applications. Diffusion probabilistic models were originally proposed as a latent variable generative model inspired by non- equilibrium thermodynamics. The essential idea of diffusion models is to systematically perturb the structure in a data distribution through a forward diffusion process, and then recover the structure by learning a reverse diffusion process, resulting in a highly flexible and tractable generative model.
- Neural Radiance Field (15 Apr 2022)
Neural Radiance Field (NeRF), you may have heard words many times for the past few months. Yes, this is the latest progress of neutral work and computer graphics. NeRF represents a scene with learned, continuous volumetric radiance field \(F_{\theta}\) defined over a bounded 3D volume. In Nerf, \(F_{\theta}\) is a multilayer perceptron (MLP) that takes as input a 3D position \(x=(x,y,z)\) and unit-norm viewing direction \(d=(d_x,d_y,d_z)\), and produces as output a density \(\sigma\) and color \(c=(r,g,b)\). By enumerating all most position and direction for a bounded 3D volumne, we could obtain the 3D scene.
- Modern Convolution Neutral Network (20 Mar 2022)
Convolutional Neural Networks (ConvNets or CNNs) are a class of neural networks algorithms that are mostly used in visual recognition tasks such as image classification, object detection, and image segmentation. The use of ConvNets in visual recognition is inarguably one of the biggest inventions of decade 2010s in deep learning community.
- Self Supervised Learning Reading Note (02 Aug 2021)
This is my reading note on CVPR 2021 tutorial on self supervised learning: Leave Those Nets Alone: Advances in Self-Supervised Learning and Data- and Label-Efficient Learning in An Imperfect World.
- Unsupervised Domain Adaption (30 Jul 2021)
This is my reading note on CVPR 2021 Tutorial: Data- and Label-Efficient Learning in An Imperfect World. The original slides and videos are available online. Unsupervised domain adaption methods could be divided into the following groups:
- Neural Lumigraph Rendering (24 Jun 2021)
Neural Lumigraph Rendering was accepted for CVPR 2021 Oral and best paper candidate. This paper proposes a method which performs on par with NeRF on view interpolation tasks while providing a high-quality 3D surface that can be directly exported for real-time rendering at test time. code is publically available.
- NeX Real-time View Synthesis with Neural Basis Expansion (23 Jun 2021)
NeX: Real-time View Synthesis with Neural Basis Expansion is paper from a group from Thailand and was accepted for CVPR 2021 Oral and best paper candidate. This paper proposes a method of synthesizing views from multiplane images, which is real time with view-dependent effects such as the reflection. The code is published is as well.
- GeoSim Realistic Video Simulation via Geometry-Aware Composition for Self-Driving (23 Jun 2021)
GeoSim: Realistic Video Simulation via Geometry-Aware Composition for Self-Driving is paper from Uber ATG and was accepted for CVPR 2021 Oral and best paper candidate. This paper proposes a method of rendering videos which is realistic not in image quality but also in physical feasibilty.
- CVPR 2021 Best Papers Candidates (23 Jun 2021)
This is the list of CVPR 2021 best paper candidates. Quite some of them are related to differental rendering or synthetic data.
- Landmark Detection for Animal Face and 3D Reconstructions (01 Jun 2021)
This is my literature survey of landmark detection and 3D reconstruction for cat and dog’s face.
- Residual Parameter Transfer for Deep Domain Adaptation (23 May 2021)
This is my reading note for Residual Parameter Transfer for Deep Domain Adaptation, which is for domain adaption. Different from existing methods, which mostly aims to learn a network to adpat the (feature) of target domain to the source domain, this paper learns a transform on the parameters of network trained on source domain to the network for the target domain.
- Domain Adaption Paper Reading List (10 May 2021)
This is the my reading list of papers on domain adaption. This list is based on paperswithcode
- MLP-Mixer An all-MLP Architecture for Vision (08 May 2021)
Google Brain proposed MLP-Mixer (code is available in google-research/vision_transformer official) which solely used multi-perceptron network (MLP) for computer vision tasks. This is different most commonly used convolution neural network (CNN) or more recently transformer based approaches. The experiment on image classification indicates that, given sufficient amount of data (e.g., 100M images) for pre-training then fine-tuned for target task (ImageNet 2012), MLP-Mixer is able to achieve competitive result as CNN and transformer. However, the performance drops far belower than CNN when insufficient amount of data are available for pre-training, especially for its larger variation. It is also found at similar accuracy, MLP-Mixer and transformer are faster than CNN (ResNet) for inference and training by 2~3 times.
- GANFIT Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction (01 May 2021)
This is my reading note for GANFIT: Generative Adversarial Network Fitting for High Fidelity 3D Face Reconstruction. The code is available in GANFit. GANFit reconstructs high quality texture and geometry from a single image with precise identity recovery. To do this, it utilizes GANs to train a very powerful generator of facial texture in UV space. Then, it revisits the original 3D Morphable Models (3DMMs) fitting approaches making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. It optimizes the parameters with the supervision of pretrained deep identity features through our end-to-end differentiable framework.
- Avatarme Realistically renderable 3d facial reconstruction in-The-wild (28 Apr 2021)
This is reading note for Avatarme: Realistically renderable 3d facial reconstruction ‘in-The-wild’, which was published in CVPR 2020 and code is available in github. Avatarme aims to reconstruct photorealistic 3D faces from a single “in-the-wild” image with an increasing level of detail. It could generate 4K by 6K-resolution 3D faces from a single low-resolution image that, for the first time, bridges the uncanny valley.
- RingNet-Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision (23 Apr 2021)
This is my reading note for Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision (code). The paper is also called RingNet and was published in CVPR 2019. The paper solves the problems of 3D face reconstruction from a single 2D image and the training requires no 3D ground truth. To this end, RingNet leverages multiple images of a person and automatically detected 2D face features. It uses a novel loss that encourages the face shape to be similar when the identity is the same and different for different people. This is based on observation that an individual’s face shape is constant across images, regardless of expres- sion, pose, lighting, etc.
- Learning an Animatable Detailed 3D Face Model from In-The-Wild Images (18 Apr 2021)
This is my reading note for paper Learning an Animatable Detailed 3D Face Model from In-The-Wild Images and code is available in DECA. The paper proposed method for producing animatable detailed 3D face model from uncontrolled image datasets. For uncontrolled, it means no control light settings and camera view angles are required; however it does require the dataset contains multiple images for each subjets.
- AlphaPose--Multip Personal Human Pose Estimation (17 Apr 2021)
This is my reading note for RMPE: Regional Multi-person Pose Estimation and the code is available at MVIG-SJTU/AlphaPose. This paper is a novel regional multi-person pose estimation (RMPE) framework to facilitate pose estimation in the presence of inaccurate human bounding boxes. The framework consists of three components: Symmetric Spatial Transformer Network (SSTN), Parametric Pose Non-Maximum-Suppression (NMS), and Pose-Guided Proposals Generator (PGPG).
- Transformer Introduction (14 Apr 2021)
This is my reading note for Transformers in Vision: A Survey. Transformers enable modeling long dependencies between input sequence elements and support parallel processing of sequence as compared to recurrent networks e.g., Long short-term memory (LSTM). Different from convolutional networks, Transformers require minimal inductive biases for their design and are naturally suited as set-functions. Furthermore, the straightforward design of Transformers allows processing multiple modalities (e.g., images, videos, text and speech) using similar processing blocks and demonstrates excellent scalability to very large capacity networks and huge datasets.
- Swin Transformer (11 Apr 2021)
ViT provides the possibilities of using transformers along as a backbone for vision tasks. However, due to transformer conduct global self attention, where the relationships of a token and all other tokens are computed, its complexity grows exponentially with image resolution. This makes it inefficient for image segmentation or semantic segmentation task. To this end, twin transformer is proposed in Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, which addresses the computation issue by conducting self attention in a local window and has multi-layers for windows at different resolution.
- CVPR 2021 Transformer Paper (11 Apr 2021)
This post summarizes the papers on transformers in CVPR 2021. This is from CVPR2021-Papers-with-Code. Given transforms captures the interaction between query (Q) and dictionary (K), transform begins to see applications in tracking (e.g., Transformer Tracking, Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking), local match matching (e.g., LoFTR Detector-Free Local Feature Matching with Transformers) and image retrieval (e.g., Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers, Revamping cross-modal recipe retrieval with hierarchical Transformers and self-supervised learning)
- My Paper Reading List For Facial Landmark Detection (01 Apr 2021)
Facial landmark detection is the task of detecting key landmarks on the face and tracking them (being robust to rigid and non-rigid facial deformations due to head movements and facial expressions).
- ViT AN IMAGE IS WORTH 16X16 WORDS TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (28 Mar 2021)
Vision Transformer (ViT) is a pure transformer architecture (no CNN is required) applied directly to a sequence of image patches for classification tasks. The order of patches in sequence capture the spatial information of those patches, similar to words in sentences.
- My Paper Reading List for 3D Face Reconstructions (20 Mar 2021)
Here is my paper reading lsit for 3D face reconstructions based on Papers with Code. 3D face reconstruction is the task of reconstructing a face from an image into a 3D form (or mesh). Most of the papers on the list are between 2017~2020.
- End-to-End Object Detection with Transformers (07 Mar 2021)
DETR still uses CNN for feature extration and then use transformer to capture context of objects (boxes) in images. Compared with previous object detection model, e.g., MaskRCNN, YOLO, it doesn’t need to have anchor and nonmaximal suppression, which is achived by transformer. Besides DETR could be directly applied for panoptic segmentation (joint semantic segmentation and instance segmentation).
- Must-read AI Papers (16 Feb 2021)
I will create a new reading note series based on Must-read AI Papers from Crossminds.ai.
- Transformer in Computer Vision (03 Feb 2021)
Transformer architecture has achieved state-of-the-art results in many NLP (Natural Language Processing) tasks. Though CNN has been the domiant models for CV tasks, using Transformers for vision tasks became a new research direction for the sake of reducing architecture complexity, and exploring scalability and training efficiency.
- 61 Interesting Paper from NeurIPS 2019 (10 Nov 2019)
- 7 Interesting Papers from ACM MM 2019 (10 Nov 2019)
This is translated from 新智元导读
- Low Light Enhancement (22 Sep 2019)
- Anchor Free Object Detection (15 Sep 2019)
The most sucessfull single stage object detection algorithms, e.g., YOLO, SSD, all relies all some anchor to refine to the final detection location. For those algorithms, the anchor are typically defined as the grid on the image coordinates at all possible locations, with different scale and aspect ratio.
- 3D Reconstruction (15 Sep 2019)
- GAN Roadmap (07 Sep 2019)
This post is baesd on AlphaTree
- Text Detection (20 Aug 2019)
In this post, we will introduce some of the most recent text detection methods. Text detection methods are highly related to object detection methods, thus could be categorized into one-stage methods and two-stage methods. Currently, two-stage methods could easily outperforms one-stage methods, e.g., using Mask-RCNN directly could give you 76% mAP on icdar2017mlt, while the current state of art methods psenet achieves 72%.
- CVPR 45 Paper into Best Paper Finals (12 Aug 2019)
极市平台 has created a list of 45 CVPR best papers into the best paper finals. Let’s check out:
- Image Alignment (10 Aug 2019)
- Optical Flow (05 Aug 2019)

- Self Attention (01 Aug 2019)

- 3D Object Detection (01 Aug 2019)

- Video Object Segmentation (31 Jul 2019)

- Siamese Network (21 Jul 2019)
- Face Reconstruction in CVPR 2019 (18 Jul 2019)

- Face Detection, Landmark Detection in CVPR 2019 (17 Jul 2019)
- Face Attribute in CVPR 2019 (17 Jul 2019)

- Anti Face Spoofing (16 Jul 2019)

- Graph Convolutional Neural Network (08 Jul 2019)
Many important real-world datasets come in the form of graphs or networks: e.g., social networks. Graph Convolutional Neural Network (GCN) is a generalization of convolution neural network over the graph, where filter parameters are typically shared over all locations in the graph.
- Network Compression Updates in 2019 (30 Jun 2019)
This is my reading note on 网络压缩最新进展:2019年最新文章概览, which covers recent advances in more efficient network architecturem, including quantization, pruning and network architecture search. Those works are published in CVPR 2019, ICLR 2019 and ICML 2019.
- Graph Embedding (29 Jun 2019)
- Install PyTorch for Nvidia Jetson Nano (25 Jun 2019)
This is the step required for installing PyTorch on Nvidia Jetson Nano.
- Pyramid in Neural Network (24 Jun 2019)
Pyramid is a widely used technique in vision tasks. It applied when you want to obtain features from different scales. There are generally two types of pyramids available:
- image pyramid: where image pyramid is generated first and then feature extract is applied on each level of pyramid. Image pyramid is a very effective way but has high computational cost.
- feature pyramid: feature is extract on the original image and next level of feature is built on the feature of previous level. Feature pyramid may reduce the computational cost by reusing the feature from lower level.
- Deep Learning based Semantic Segmentation Algorithm (22 Jun 2019)

- ICML 2019 Best Papers and Honourable of Mention (11 Jun 2019)
International Conference on Machine Learning (ICML) 2019 has got 3424 submissions and 744 accepted (accpetance rate is 22.6%). The result can be found here
- Neural Architecture Search A Survey (30 May 2019)
Deep Learning has enabled remarkable progress over the last years on a variety of tasks, such as image recognition, speech recognition, and machine translation. One crucial aspect for this progress are novel neural architectures. Currently employed architectures have mostly been developed manually by human experts, which is a time-consuming and error-prone process. Because of this, there is growing interest in automated neural architecture search methods. We provide an overview of existing work in this field of research and categorize them according to three dimensions: search space, search strategy, and performance estimation strategy.
- Object Detection Update (2019/1~2019/3) (22 May 2019)
- SKNet, GCNet, GloRe, Octave (16 May 2019)
- Siamese Network Based Single Object Tracking (15 May 2019)
Siamese network is an artificial neural network that use the same weights while working in tandem on two different input vectors to compute comparable output vectors.
- Setting Up Jetson Nano (10 May 2019)
- IJCAI Best Papers (10 May 2019)
International Joint Conference on Artificial Intelligence (IJCAI) is one of the best conferences in AI. It used to happen every two years and now is every one year.
- Single Object Tracking (08 May 2019)

- Human Pose Estimation with Deep Learning (05 May 2019)
- A Recipe for Training Neural Networks (29 Apr 2019)
This is my study note on A Recipe for Training Neural Networks by Andrej Karpathy. It lists some common mistakes and tips when training your own neural network.
- Neural Architecture Search (24 Apr 2019)
There has been a lot of recent interest in automatically learning good neural net architectures.
- Face Recognition (18 Apr 2019)
Face recognition (FR) has been the prominent biometric technique for identity authentication and has been widely used in many areas, such as military, finance, public security and daily life.
- Loss Functions (15 Apr 2019)
Loss functions are frequently used in supervised machine learning to minimize the differences between the predicted output of the model and the ground truth labels. In other words, it is used to measure how good our model can predict the true class of a sample from the dataset. Here I would like to list some frequently-used loss functions and give my intuitive explanation.
- Face Landmark Detection (15 Apr 2019)

- Convolution Nerual Network Backbone (15 Apr 2019)
Convolution Nerual Network (CNN) has been used in many visual tasks. You may find the networks for varying types of visual tasks share similar set of feature extraction layer, which is referred as backbone. Researchers typically use backbone which has been succesful in ImageNet competion and combine them with different loss functions to solve different type of visual tasks.
- Pose Estimation (14 Apr 2019)

- Deep Learning Hardware for Embedded (13 Apr 2019)
If you want to run deep learning inference for some embedded system, there are several possiblities now, e.g., Rapberry Pi.
- Visual Localization via Deep Learning (13 Apr 2019)
Visual localization aims to estimate the localization, which is usually the the coordinate (orientation and localization) in the world coordindately, given one or multiple images.
- An Overview of Normalization Methods in Deep Learning (10 Apr 2019)

- ResNet and Its Variations (08 Apr 2019)
ResNet
- Effcient Deep Neural Network (07 Apr 2019)
In this post, we will introduce some neural networks which are suitable for running on mobile devices.
- Generative adversarial network (05 Apr 2019)
- Transfer Learning (04 Apr 2019)

- Network Compression (03 Apr 2019)
The trained network is typically too large to run efficiently on mobile device. For example, VGG16 used for image classification has more 130 Million parameter (about 600 MB on model size) and requires about 31 billion operations to classify an image, which is way to expensive to be done on mobile.
- Different Types of Convolutions in Deep Learning (02 Apr 2019)
Besides the convolution operator we already found in AlexNet or VGG16, there are few variations, which will be introduced below. The content of this article is based on reading of An Introduction to different Types of Convolutions in Deep Learning
- Object Detections (02 Apr 2019)
Here is the comparison of the most popular object detection frameworks.
- Image Segmentation (02 Apr 2019)
There are two types of image segmentation:
- semantic segmentation: assign labels to each pixel
- instance segmentation: extract the bounary/mask for each instance in the image