Anchor Free Object Detection
[psaf foveabox fcos object-detection ga-rpn densebox deep-learning extremenet cornernet yolo centernet ssd anchor-free unitbox The most sucessfull single stage object detection algorithms, e.g., YOLO, SSD, all relies all some anchor to refine to the final detection location. For those algorithms, the anchor are typically defined as the grid on the image coordinates at all possible locations, with different scale and aspect ratio.
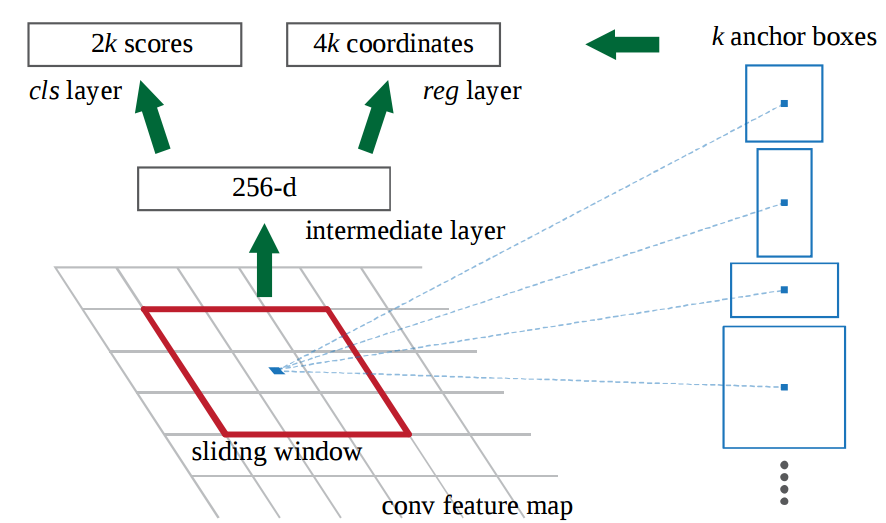
Though much faster than their two-stage counterparts, single stage algorithms’ speed and performance is still limited by the choice of the anchor boxes: fewer than anchor leads better speed but deteroiates the accuracy. As a result, many new works are trying to design anchor free object detection algorithms.
The table summarizes the performance of some of the best anchor free methods:
| Methods | mAP | FPS | Code |
|---|---|---|---|
| FSAF | 42.9 | 5.3 | N.A. |
| FCOS | 43.2 | Nona | tianzhi0549/FCOS |
| CenterNet:Objects as Points | 42.1 | 7.8 | xingyizhou/CenterNet |
| CenterNet: Keypoint Triplets for Object Detection | 44.9 | 3 | Duankaiwen/CenterNet |
| AlignDet | 44.1 | 5.6 | N.A |
UnitBox: An Advanced Object Detection Network
UnitBox uses Intersection over Union (IoU) loss function for bounding box prediction.
DenseBox: Unifying Landmark Localization and Object Detection
DenseBox directly compute the bounding box and its label from the feature map.
CornerNet: Detecting Objects as Paired Keypoints
In CornerNet, the bounding box is uniquely defined by its top-left corner and bottom-right corner, which is detected by each of the two branches. Corner-pooling is applied to detect the corners, which utilizes the ideas of integral image (see below)
ExtremeNet: Bottom-up Object Detection by Grouping Extreme and Center Points
Similar as CornerNet, it formulates the problem of finding bounding box as finding some corner points. But instead of two corners as in CornerNet, it requires four corner points and one center point, which is computed via peaks of heatmaps of each corner points.
FSAF: Feature Selective Anchor-Free
It is based on feature pyramid network, where the final result is dynamically selected from the optimal resolution.
FCOS: Fully Convolutional One-Stage
FCOS is anchor-box free, as well as proposal free. FCOS works by predicting a 4D vector (l, t, r, b) encoding the location of a bounding box at each foreground pixel (supervised by ground-truth bounding box information during training).
This done in a per-pixel prediction way, i.e., for each pixel, the network try to predict a bounding box from it, together with the label of class. To counter for the pixel which are far from the ground truth object (center), a centerness score is also predicted which downweights the prediction for those pixels.
If a location falls into multiple bounding boxes, it is considered as an ambiguous sample. For now, we simply choose the bounding box with minimal area as its regression target.
Feature Pyramid Network is used as the backbone.
FoveaBox: Beyond Anchor-based Object Detector
It is very similar to FCOS.
Region Proposal by Guided Anchoring(GA-RPN)
In GA-RPN, the anchor (defined as a tuple of its location and shape) is learned instead of manually defined. Then feature extraction is then adapted to this computed anchor. CenterNet: Objects as Points
CenterNet: Objects as Points
CenterNet defines the bounding box by its center. After the center is computed, its shape and pose can be further computed.
CenterNet: Object Detection with Keypoint Triplets
It is based on CenterNet but very similar to ExtremeNet or CornerNet, where the bounding box is now defined by a pair of corner points and the label is defined by the response of the center point.
CornerNet-Lite: Efficient Keypoint Based Object Detection
CornerNet-Lite:CornerNet-Saccade(attention mechanism)+ CornerNet-Squeeze
[Center and Scale Prediction: A Box-free Approach for Object Detection]
As GA-RPN, the bounding box is defined by its center and shape, which is computed from two branches of the neural network.
Matrix Nets
Maxtrix Nets addresses different aspect ratio of the objects. Compared with image pyramid, it generates feature across different scales and aspect ratio, like a matrix. Especially, for feature x_{ij} at layer i and j, feature x_{i+1, j+1} is generated via a 3x3 kernel with stride 2x2, feature x_{i+1, j} is generated via a 3x3 kernel with stride 2x1 and feature x_{i, j+1} is generated via a 3x3 kernel with stride 1x2. Note those three convolutions share the same parameter.
To detect objects, it utilizes the similar idea of center net: the location of top left corner and bottom right corner are detected, the centerness is also computed. Then the result for feature x_{i+k, i+[0:k]} and x_{i+[0:k], i+k} is aggreated via nonmax suppression.
FreeAnchor
Modern CNN-based object detectors assign anchors for ground-truth objects under the restriction of object-anchor Intersection-over-Unit (IoU). In this study, we propose a learning-to-match approach to break IoU restriction, allowing objects to match anchors in a flexible manner. Our approach, referred to as FreeAnchor, updates hand-crafted anchor assignment to “free” anchor matching by formulating detector training as a maximum likelihood estimation (MLE) procedure. FreeAnchor targets at learning features which best explain a class of objects in terms of both classification and localization. FreeAnchor is implemented by optimizing detection customized likelihood and can be fused with CNN-based detectors in a plug-and-play manner. Experiments on MS-COCO demonstrate that FreeAnchor consistently outperforms their counterparts with significant margins.
This paper tries to address limitation of manually crafted anchor box for object detection, which is not good at handling crowed objects, occluded objects and objects with very larger/smaller aspect ratio.