Self Attention
[attention deep-learning 
Since Attention Is All You Need, attention has gain more and more attentions from the literature. In that paper, the motivation is that, for sequence to sequence tasks, e.g., machine translation, the output at timestamp t is more related to inputs at a subset of timestamps than others. Those relationships are computed dynamicallys, which is referred as attention. Since the popularity in sequential data, people are also interesting in its applications in image domain.
For attention in image domain, the relationships is computed among different spatial locations or feature channels. This has been movitations from observations in biologic studies in human visual system.
In the sections below, we will cover some representative works.
Squeeze-and-Excitation module
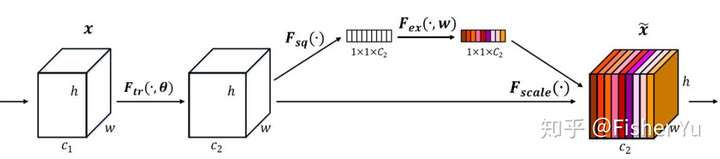
The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ~25%. Models and code are available at https://github.com/hujie-frank/SENet.
The SE module is applied to each block of ResNet and the squeeze ratio is 16.
It’s Written All over Your Face: Full-Face Appearance-Based Gaze Estimation
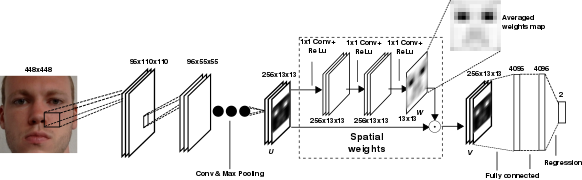
Eye gaze is an important non-verbal cue for human affect analysis. Recent gaze estimation work indicated that information from the full face region can benefit performance. Pushing this idea further, we propose an appearance-based method that, in contrast to a long-standing line of work in computer vision, only takes the full face image as input. Our method encodes the face image using a convolutional neural network with spatial weights applied on the feature maps to flexibly suppress or enhance information in different facial regions. Through extensive evaluation, we show that our full-face method significantly outperforms the state of the art for both 2D and 3D gaze estimation, achieving improvements of up to 14.3% on MPIIGaze and 27.7% on EYEDIAP for person-independent 3D gaze estimation. We further show that this improvement is consistent across different illumination conditions and gaze directions and particularly pronounced for the most challenging extreme head poses.
The attention module is applied after the ResNet.
Dual Attention Network for Scene Segmentation
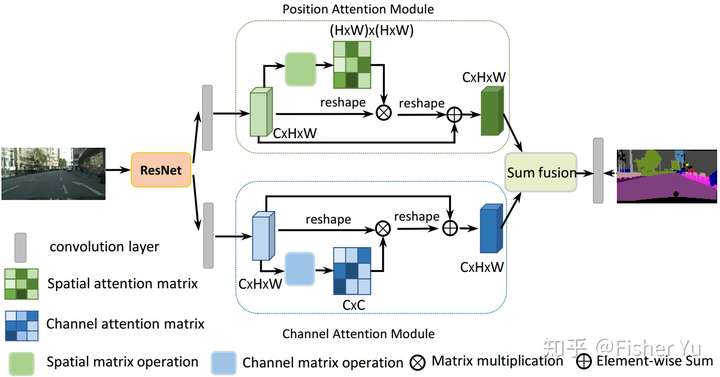
In this paper, we address the scene segmentation task by capturing rich contextual dependencies based on the selfattention mechanism. Unlike previous works that capture contexts by multi-scale features fusion, we propose a Dual Attention Networks (DANet) to adaptively integrate local features with their global dependencies. Specifically, we append two types of attention modules on top of traditional dilated FCN, which model the semantic interdependencies in spatial and channel dimensions respectively. The position attention module selectively aggregates the features at each position by a weighted sum of the features at all positions. Similar features would be related to each other regardless of their distances. Meanwhile, the channel attention module selectively emphasizes interdependent channel maps by integrating associated features among all channel maps. We sum the outputs of the two attention modules to further improve feature representation which contributes to more precise segmentation results. We achieve new state-of-the-art segmentation performance on three challenging scene segmentation datasets, i.e., Cityscapes, PASCAL Context and COCO Stuff dataset. In particular, a Mean IoU score of 81.5% on Cityscapes test set is achieved without using coarse data. We make the code and trained model publicly available at https://github.com/junfu1115/DANet
The attention module is applied after the ResNet. For implementation, please refer to junfu1115/DANet
CBAM: Convolutional Block Attention Module
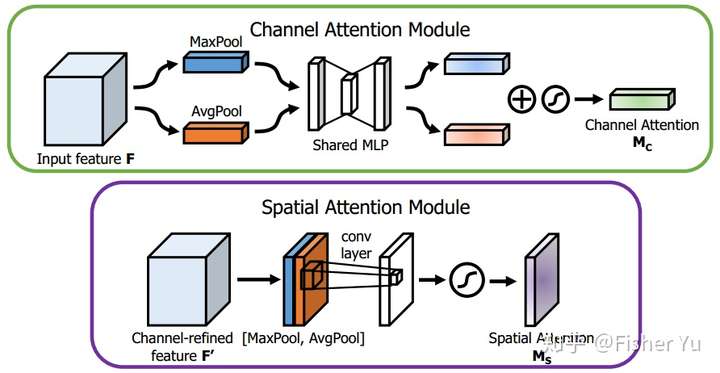
We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feed-forward convolutional neural networks. Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions, channel and spatial, then the attention maps are multiplied to the input feature map for adaptive feature refinement. Because CBAM is a lightweight and general module, it can be integrated into any CNN architectures seamlessly with negligible overheads and is end-to-end trainable along with base CNNs. We validate our CBAM through extensive experiments on ImageNet-1K, MS~COCO detection, and VOC~2007 detection datasets. Our experiments show consistent improvements in classification and detection performances with various models, demonstrating the wide applicability of CBAM. The code and models will be publicly available.
The attention module is attached to each block of ResNet. For implementation, please refer to Jongchan/attention-module
Interaction-aware Spatio-temporal Pyramid Attention Networks for Action Classification
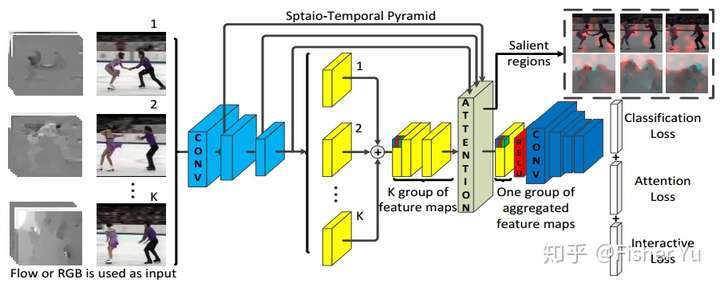
Local features at neighboring spatial positions in feature maps have high correlation since their receptive fields are often overlapped. Self-attention usually uses the weighted sum (or other functions) with internal elements of each local feature to obtain its weight score, which ignores interactions among local features. To address this, we propose an effective interaction-aware self-attention model inspired by PCA to learn attention maps. Furthermore, since different layers in a deep network capture feature maps of different scales, we use these feature maps to construct a spatial pyramid and then utilize multi-scale information to obtain more accurate attention scores, which are used to weight the local features in all spatial positions of feature maps to calculate attention maps. Moreover, our spatial pyramid attention is unrestricted to the number of its input feature maps so it is easily extended to a spatio-temporal version. Finally, our model is embedded in general CNNs to form end-to-end attention networks for action classification. Experimental results show that our method achieves the state-of-the-art results on the UCF101, HMDB51 and untrimmed Charades.
The attention module can be viewed as an extension of Dual Attention Network for Scene Segmentation that it fuses the feature map of a spatial pyramid for compute the attention. The attention module is also applied after the ResNet.
Non-local Neural Networks
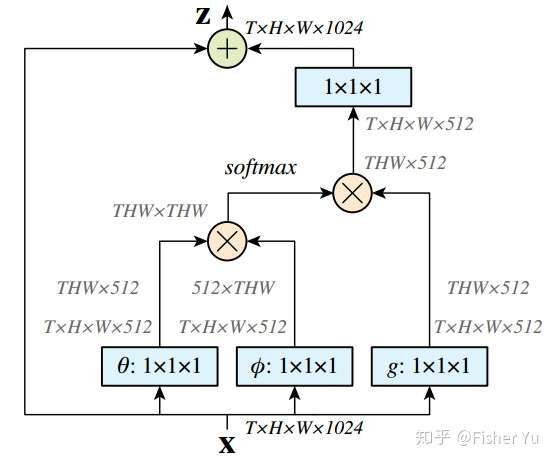
Both convolutional and recurrent operations are building blocks that process one local neighborhood at a time. In this paper, we present non-local operations as a generic family of building blocks for capturing long-range dependencies. Inspired by the classical non-local means method in computer vision, our non-local operation computes the response at a position as a weighted sum of the features at all positions. This building block can be plugged into many computer vision architectures. On the task of video classification, even without any bells and whistles, our non-local models can compete or outperform current competition winners on both Kinetics and Charades datasets. In static image recognition, our non-local models improve object detection/segmentation and pose estimation on the COCO suite of tasks. Code is available at https://github.com/facebookresearch/video-nonlocal-net .
The attention module is similar to spatial part of Dual Attention Network for Scene Segmentation and is also applied after the ResNet. For implementation, please refer to facebookresearch/video-nonlocal-net
Learn to Pay Attention
In Learn to Pay Attention, the attention map is computed between the final feature map and the feature map under compute. The motivation is that, the final feature map (referred as global feature) is more close to the actual task, thus reflects the importance of each feature. More specifically, Learn to Pay Attention modify from VGG-16 network, where attention maps are computed for Layer 7, 10 and 13. The attention weighted feature maps are combined together as the final feature vector.
Assume the global feature (g) is a tensor of N x C_g, the feature map under compute (l) is a tensor of N x C_l x H x W, then the attention will be computed as:
- project the local feature map to N x C_g x H x W via a 1x1 convolution;
- compute the attention map N x 1 x H x W via a 1x1 convolution on l + g;
- normalize the attention map via softmax
- apply the normalize attention map to l
- reduce the spatial dimension for the final vector