Battle of the Backbones A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks
[transformer multimodal review deep-learning clip convnext resnet vit swin-transformer mae This is my reading note for Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks. This paper benchmarks different vision backbones and found that supervised ConvNext may show best performance. After it, supervised swin-transformer and clip based transformer is also very competitive. Different vision tasks shows highly correlated performance for different backbones.
TLDR
While vision transformers (ViTs) and self-supervised learning (SSL) are increasingly popular, we find that convolutional neural networks pretrained in a supervised fashion on large training sets still perform best on most tasks among the models we consider. More- over, in apples-to-apples comparisons on the same architectures and similarly sized pretraining datasets, we find that SSL backbones are highly competitive, indicating that future works should perform SSL pretraining with advanced architectures and larger pretraining datasets (p. 1)
- supervised ConvNeXt-Base, supervised SwinV2-Base trained using ImageNet-21k, and CLIP ViT-Base come out on top. The same winners also win at smaller scales. Among smaller backbones, ConvNeXt-Tiny and SwinV2-Tiny emerge victorious, followed by DINO ViT-Small. (p. 2)
- Despite the recent attention paid to transformer-based architectures and self-supervised learning, high-performance convolutional networks pretrained via supervised learning outperform transformers on the majority of tasks we consider.
- The observed superiority of supervised pretraining occurs because such models are available trained on larger datasets. In apples-to-apples comparisons on the same dataset scale, SSL models outperform their supervised counterparts.
- ViTs are more sensitive to the amount of pretraining data and the number of parameters than CNNs.
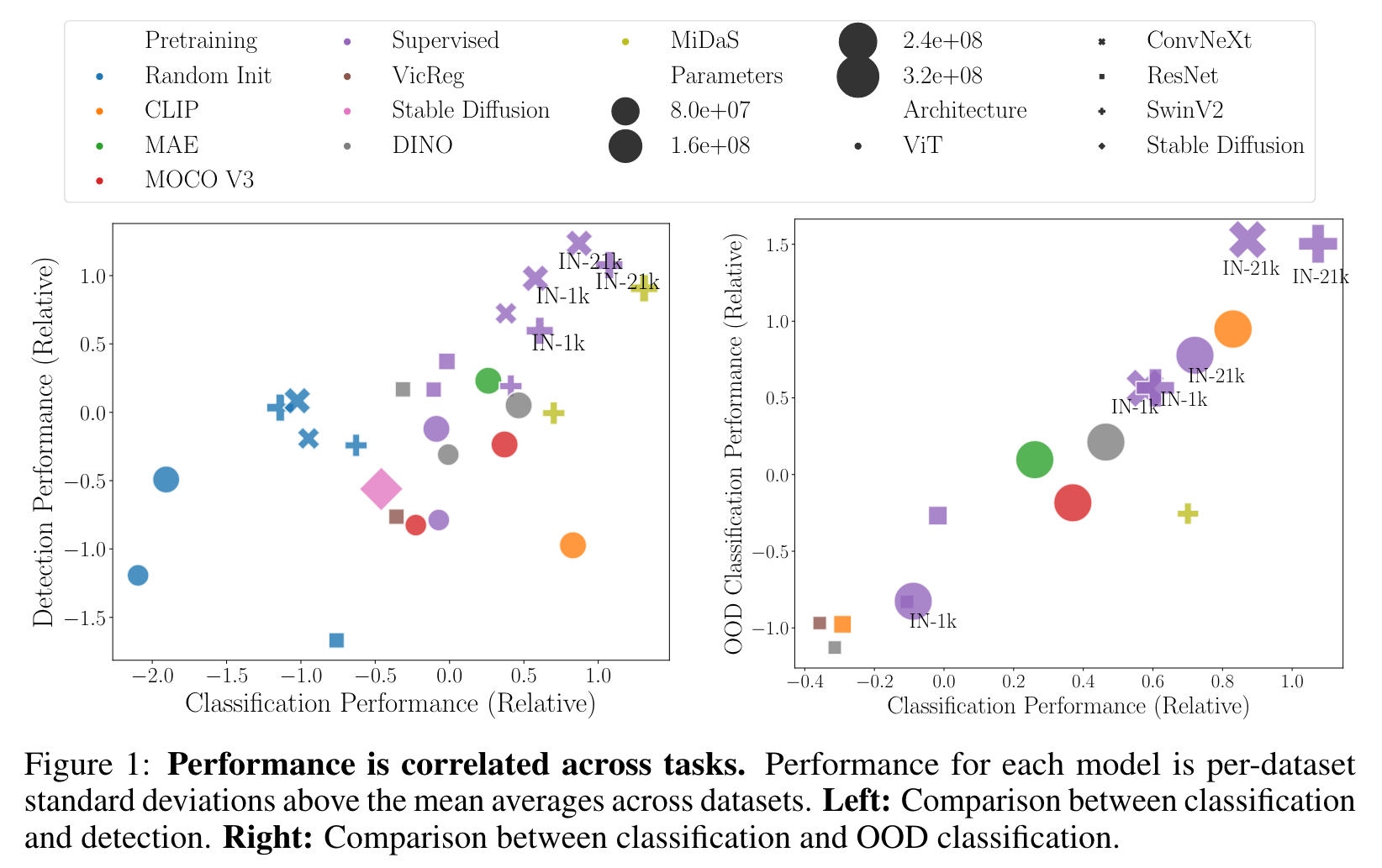
- Performance across tasks is strongly correlated – the top-performing backbones in BoB tend to be universally good across tasks and settings. See Figure 1. (p. 3)
A Guide to BoB
The Tasks
- Classification: We measure both fine-tuned and linear probe performance of backbones on various downstream classification tasks including natural, medical, or satellite image datasets in Section 3.1. (p. 4)
- Object detection and segmentation (p. 4)
- Out-of-distribution generalization (p. 4)
- Image retrieval (p. 4)
I’m a Practitioner. Which Backbone Should I Choose?

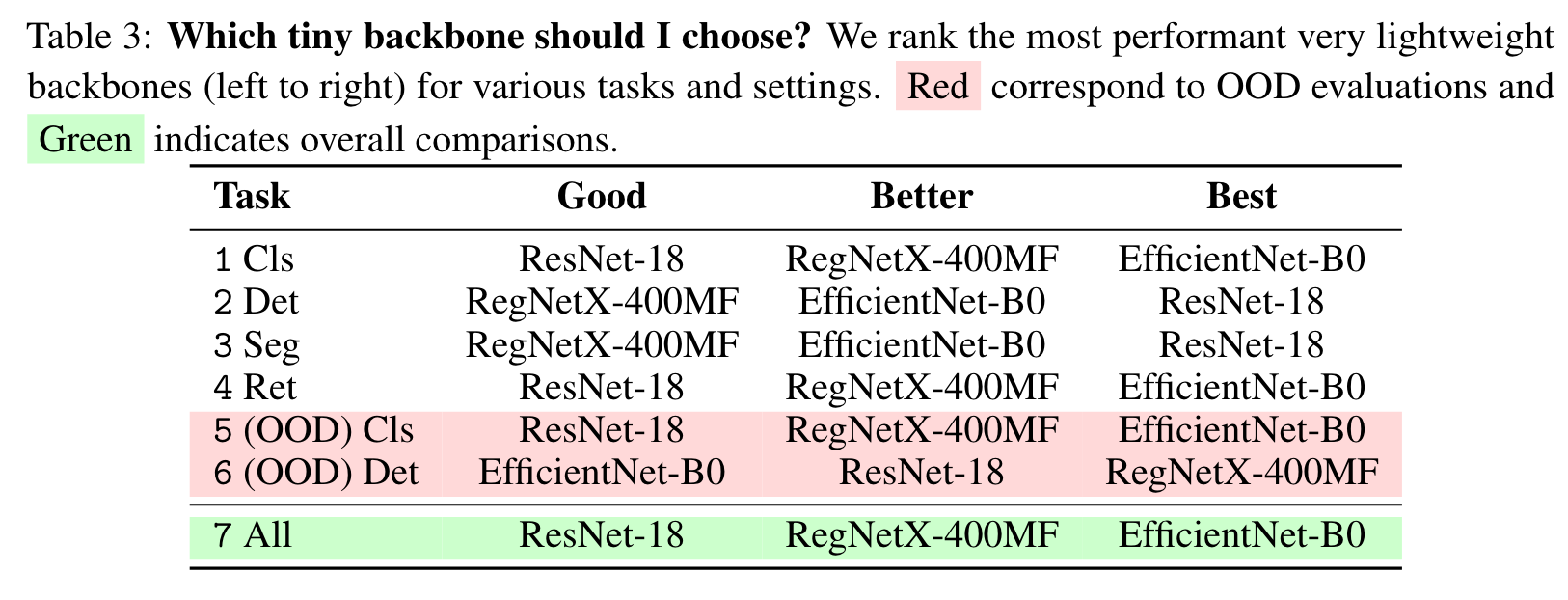
Observations and Trends
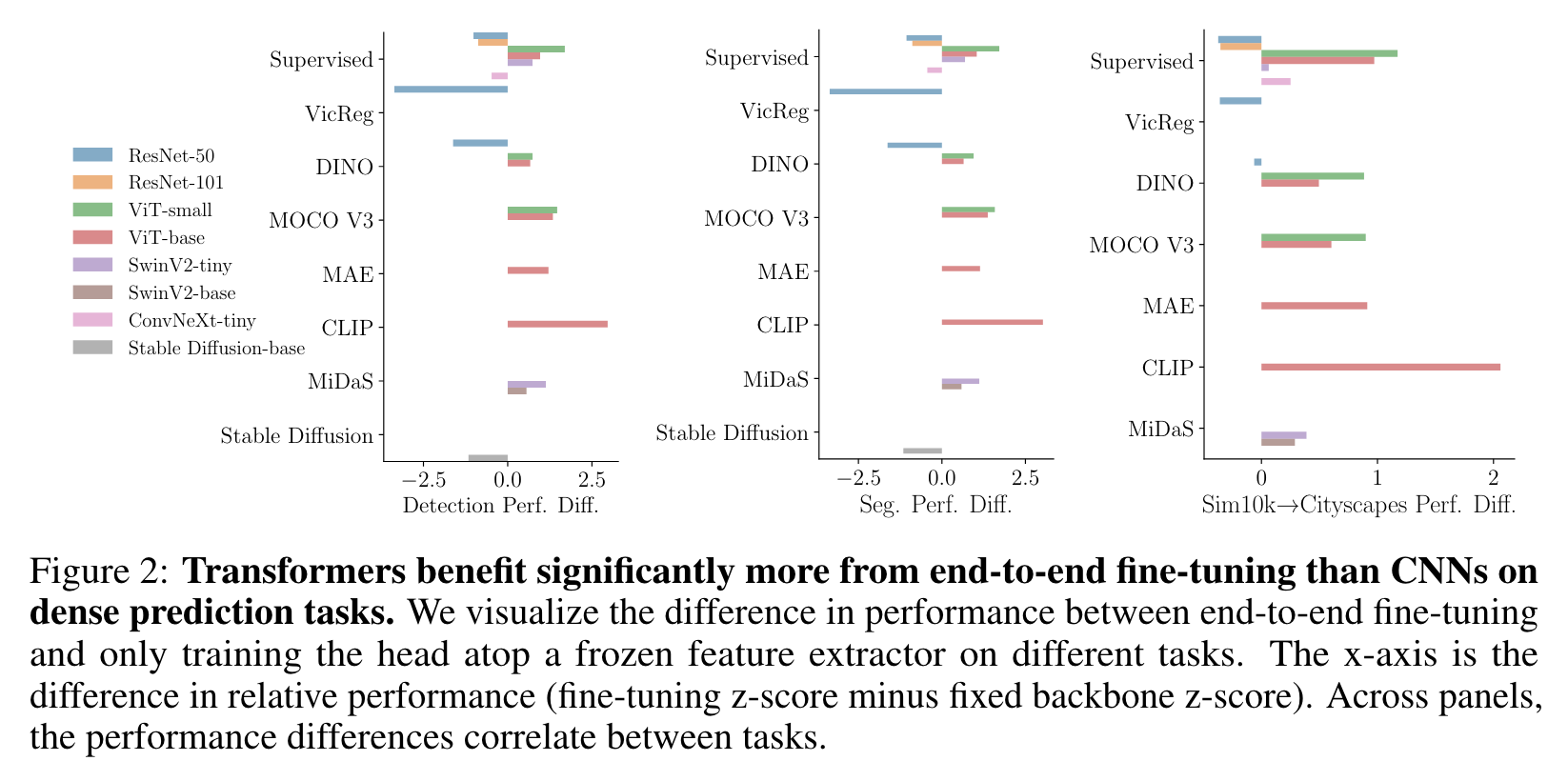
- A performance comparison of ViTs and CNNs. Modern architectures strongly outperform vanilla ViTs. We see in Table 2 that the best performing backbone (ConvNeXt-Base) is convolutional, with a hierarchical transformer (SwinV2-Base) being a close second. The latter transformer architec- ture incorporates a strong spatial inductive bias. These findings suggest that the community should move past vanilla ViTs which are still used frequently. As a caveat, we do not evaluate very large models, and it is possible that ViTs might outperform their more advanced variants or convolutional networks at larger scales. (p. 8)
- ViTs benefit more from scale than CNNs. For the suite of backbones considered in BoB, we find that relative performance (z-scores) for both CNNs and ViTs correlates positively with parameter count but more so for ViTs (spearman ρ = 0.58) than for CNNs (spearman ρ = 0.35). Similarly, while overall relative performance correlates with the size of pretraining data, the correlation is again significantly higher for ViTs (ρ = 0.72) than for CNNs (ρ = 0.33). (p. 8)
- Supervised or not? Supervised learning backbones dominate, but primarily because they are available pretrained on larger datasets. SSL backbones can outperform supervised pre- training with similar sized pre-training datasets. When comparing models pretrained on similarly sized datasets, SSL or vision-language pretraining methods achieve better performance on classification (both in- and out-of-distribution) and retrieval tasks, which heavily rely on the learned representations. However, supervised learning backbones maintain a decisive edge for detection and segmentation. (p. 8)
- Performance across tasks is highly correlated. Across tasks examined, we find a strong positive Spearman correlation between performance on task pairs (typically ρ > 0.8). This finding supports the current trend of general purpose foundation models for computer vision. (p. 8)
- Transformers excel under end-to-end fine-tuning while convolutional networks excel under linear probing. (p. 9)
- CLIP models and the promise of advanced architectures in vision-language modeling. For almost all the tasks (except OOD detection), CLIP pretraining is the best among the vanilla vision transformers, even compared to ImageNet-21k supervised trained backbones. (p. 9)
- backbones trained with a generative objective, such as MAE or Stable Diffusion, had comparatively inferior performance. (p. 9)
- Monocular depth-estimation as a general purpose pretraining strategy. (p. 9)
- Calibration and test likelihood are correlated with accuracy. (p. 9)
- CNNs and SSL are more adversarially robust. Moreover, ViTs are more vulnerable to adversarial examples than convolutional networks. Notably, ConvNeXt is more adversarially robust even when trained in a supervised fashion. (p. 10)