What Does BERT Look At? An Analysis of BERT's Attention
[transformer deep-learning bert attention syntax multi-head-attention This is my reading note for What Does BERT Look At? An Analysis of BERT’s Attention. This paper studies the attention map of Bert.it found that the attention map captures information such as syntax and co reference . It also found there is a lot of redundancy in heads of the same layer.

Introduction
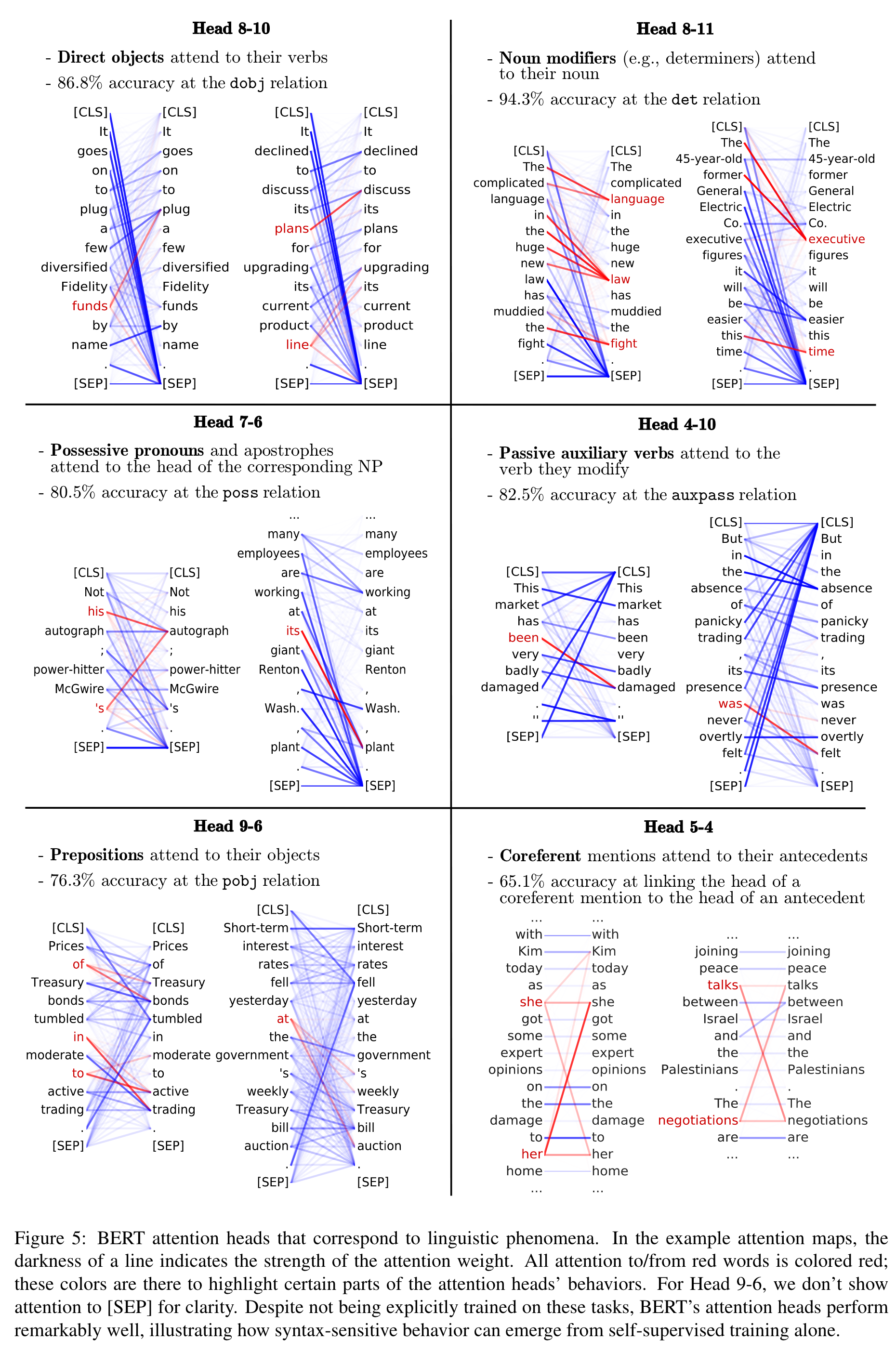
BERT’s attention heads exhibit patterns such as attending to delimiter tokens, specific positional offsets, or broadly attending over the whole sentence, with heads in the same layer often exhibiting similar behaviors. We further show that certain attention heads correspond well to linguistic notions of syntax and coreference. For example, we find heads that attend to the direct objects of verbs, determiners of nouns, objects of prepositions, and coreferent mentions with remarkably high accuracy. Lastly, we propose an attention-based probing classifier and use it to further demonstrate that substantial syntactic information is captured in BERT’s attention. (p. 1)
It is naturally interpretable because an attention weight has a clear meaning: how much a particular word will be weighted when computing the next representation for the current word. (p. 1)
Background: Transformers and BERT
Attention weights can be viewed as governing how “important” every other token is when producing the next representation for the current token. (p. 2)
BERT is pre-trained on 3.3 billion tokens of English text to perform two tasks. In the “masked language modeling” task, the model predicts the identities of words that have been masked-out of the input text. In the “next sentence prediction” task, the model predicts whether the second half of the input follows the first half of the input in the corpus, or is a random paragraph. (p. 2)
An important detail of BERT is the preprocessing used for the input text. A special token [CLS] is added to the beginning of the text and another token [SEP] is added to the end. If the input consists of multiple separate texts (e.g., a reading comprehension example consists of a separate question and context), [SEP] tokens are also used to separate them. As we show in the next section, these special tokens play an important role in BERT’s attention. (p. 2)
Surface-Level Patterns in Attention
Relative Position
We find that most heads put little attention on the current token. However, there are heads that specialize to attending heavily on the next or previous token, especially in earlier layers of the network. (p. 3)
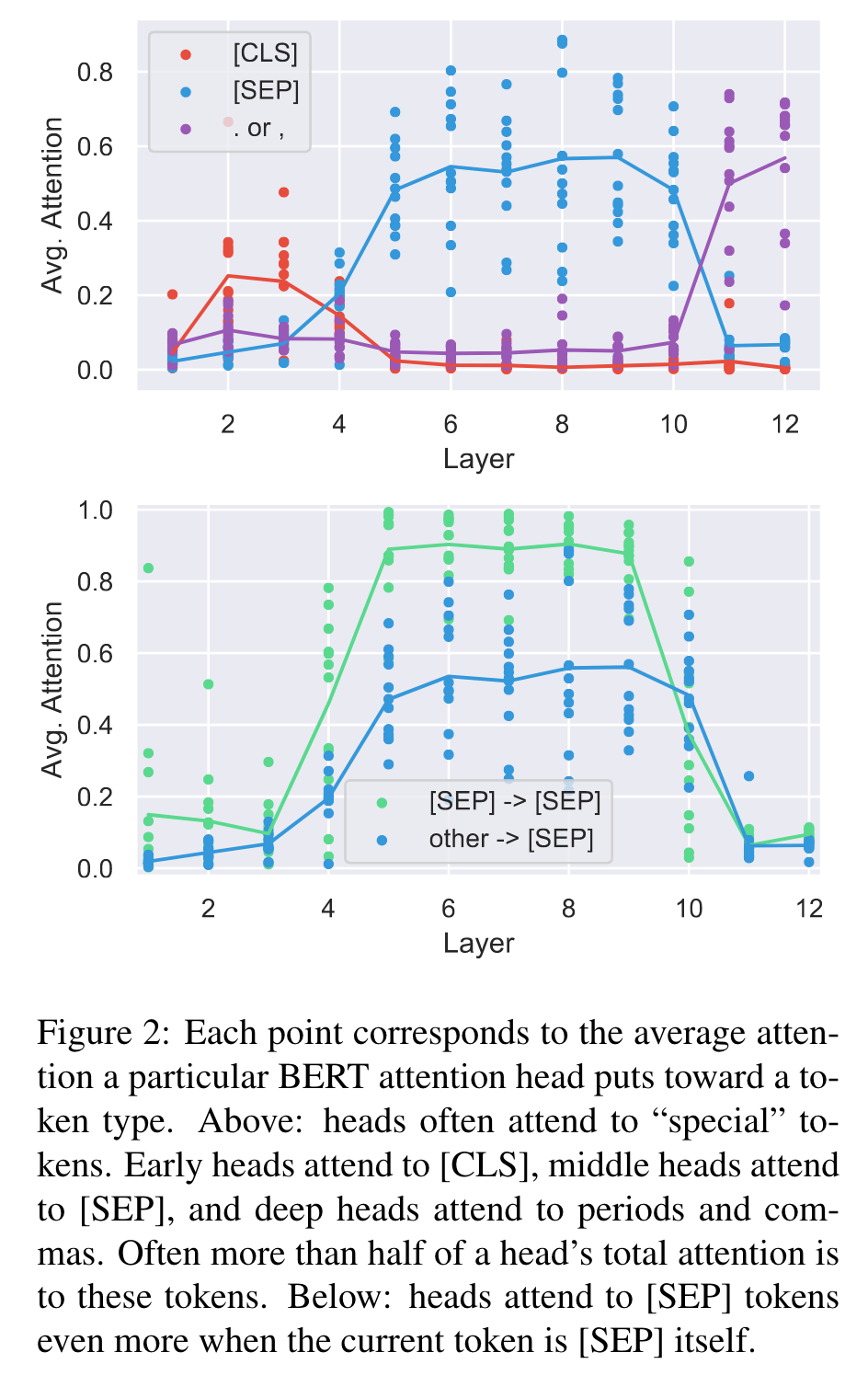
Attending to Separator Tokens
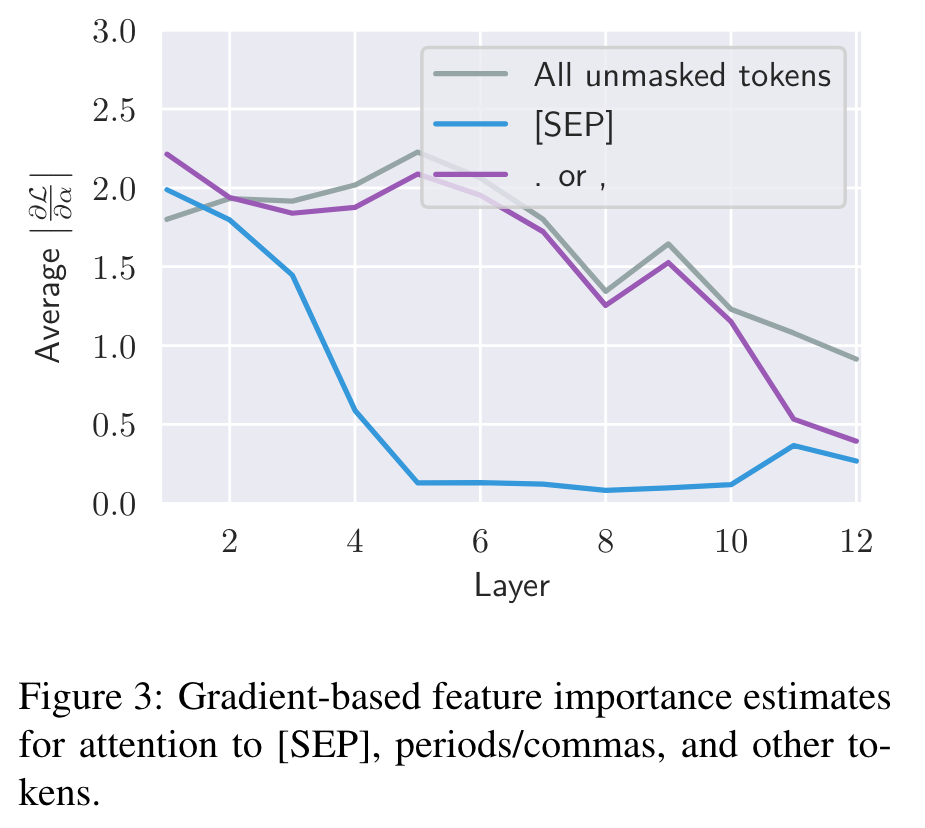
For example, over half of BERT’s attention in layers 6-10 focuses on [SEP]. [SEP] and [CLS] are guaranteed to be present and are never masked out, while periods and commas are the most common tokens in the data excluding “the,” which might be why the model treats these tokens differently. A similar pattern occurs for the uncased BERT model, suggesting there is a systematic reason for the attention to special tokens rather than it being an artifact of stochastic training. (p. 3)
Therefore, we speculate that attention over these special tokens might be used as a sort of “no-op” when the attention head’s function is not applicable. (p. 4)
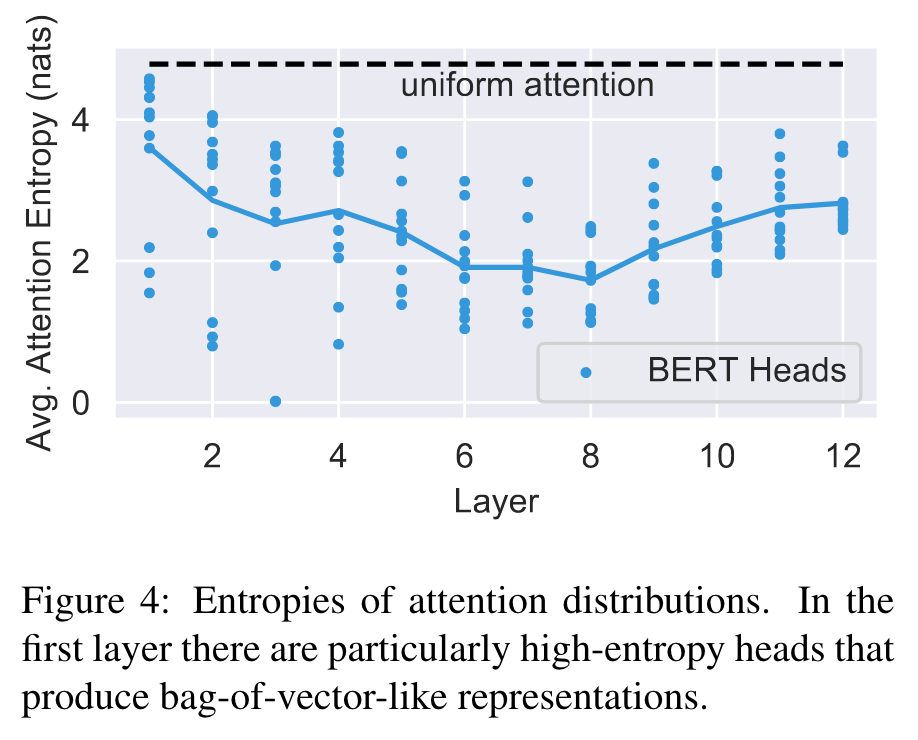
Focused vs Broad Attention
We find that some attention heads, especially in lower layers, have very broad attention. These high-entropy attention heads typically spend at most 10% of their attention mass on any single word. The output of these heads is roughly a bag-of-vectors representation of the sentence. (p. 4)
While the average entropies from [CLS] for most layers are very close to the ones shown in Figure 4, the last layer has a high entropy from [CLS] of 3.89 nats, indicating very broad attention. This finding makes sense given that the representation for the [CLS] token is used as input for the “next sentence prediction” task during pre-training, so it attends broadly to aggregate a representation for the whole input in the last layer (p. 4)
Probing Individual Attention Heads
Dependency Syntax
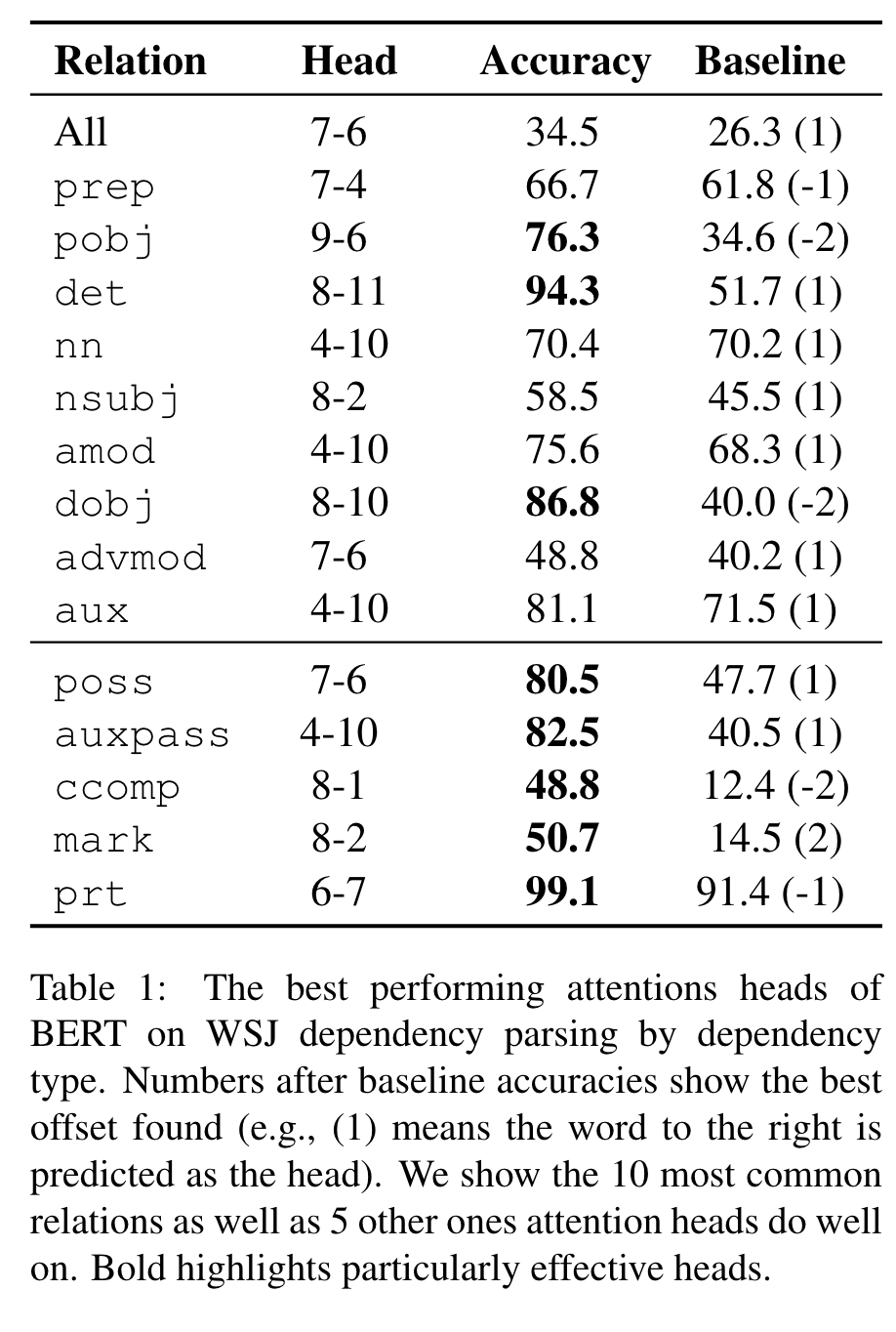
Table 1 shows that there is no single attention head that does well at syntax “overall”; However, we do find that certain attention heads specialize to specific dependency relations, sometimes achieving high accuracy and substantially outperforming the fixed-offset baseline. Such disagreements highlight how these syntactic behaviors in BERT are learned as a by-product of self-supervised training, not by copying a human design. (p. 6)
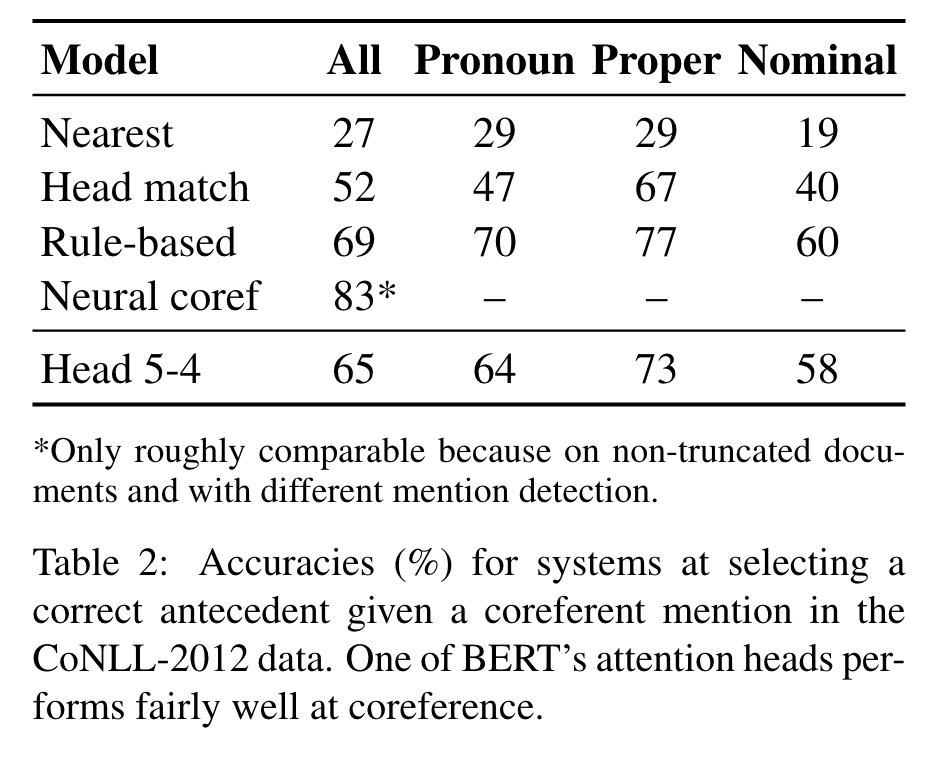
Coreference Resolution
Coreference links are usually longer than syntactic dependencies and state-of-the-art systems generally perform much worse at coreference compared to parsing. (p. 6)
Probing Attention Head Combinations
Attention-Only Probe. Our first probe learns a simple linear combination of attention weights. (p. 7)
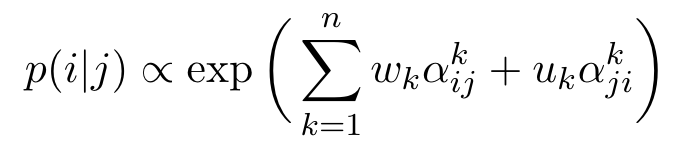
Attention-and-Words Probe. In particular, we build a model that sets the weights of the attention heads based on the GloVe (Pennington et al., 2014) embeddings for the input words. (p. 7)
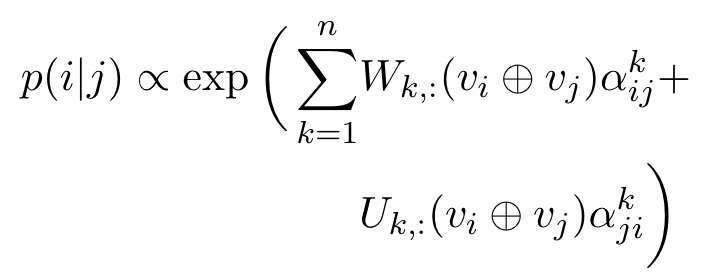
Where v denotes GloVe embeddings and ⊕ denotes concatenation. (p. 7)
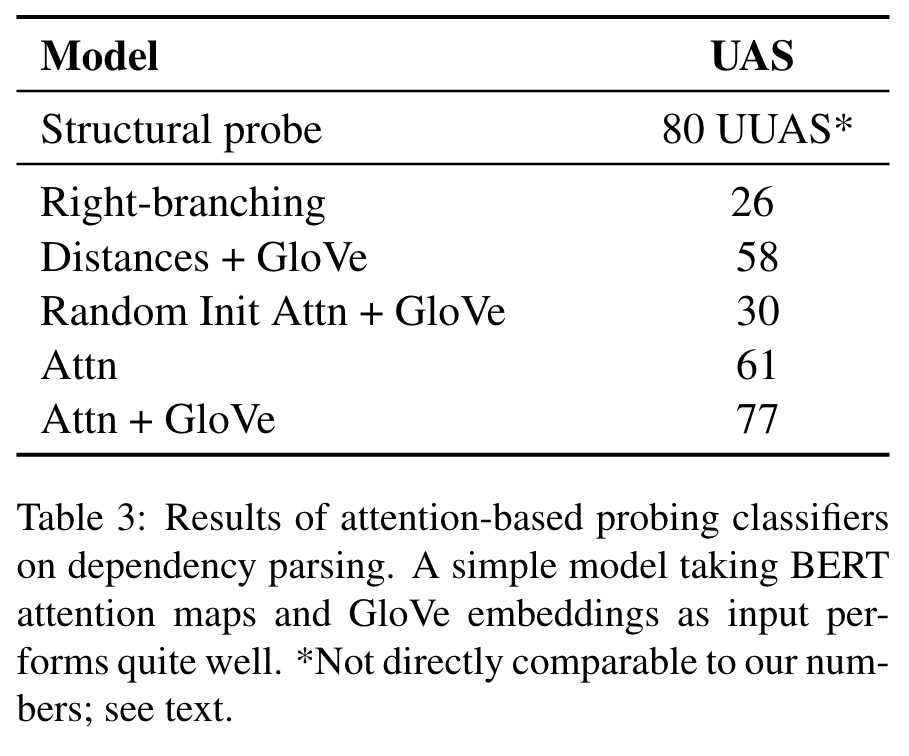
Overall, our results from probing both individual and combinations of attention heads suggest that BERT learns some aspects syntax purely as a by-product of self-supervised training. (p. 8)
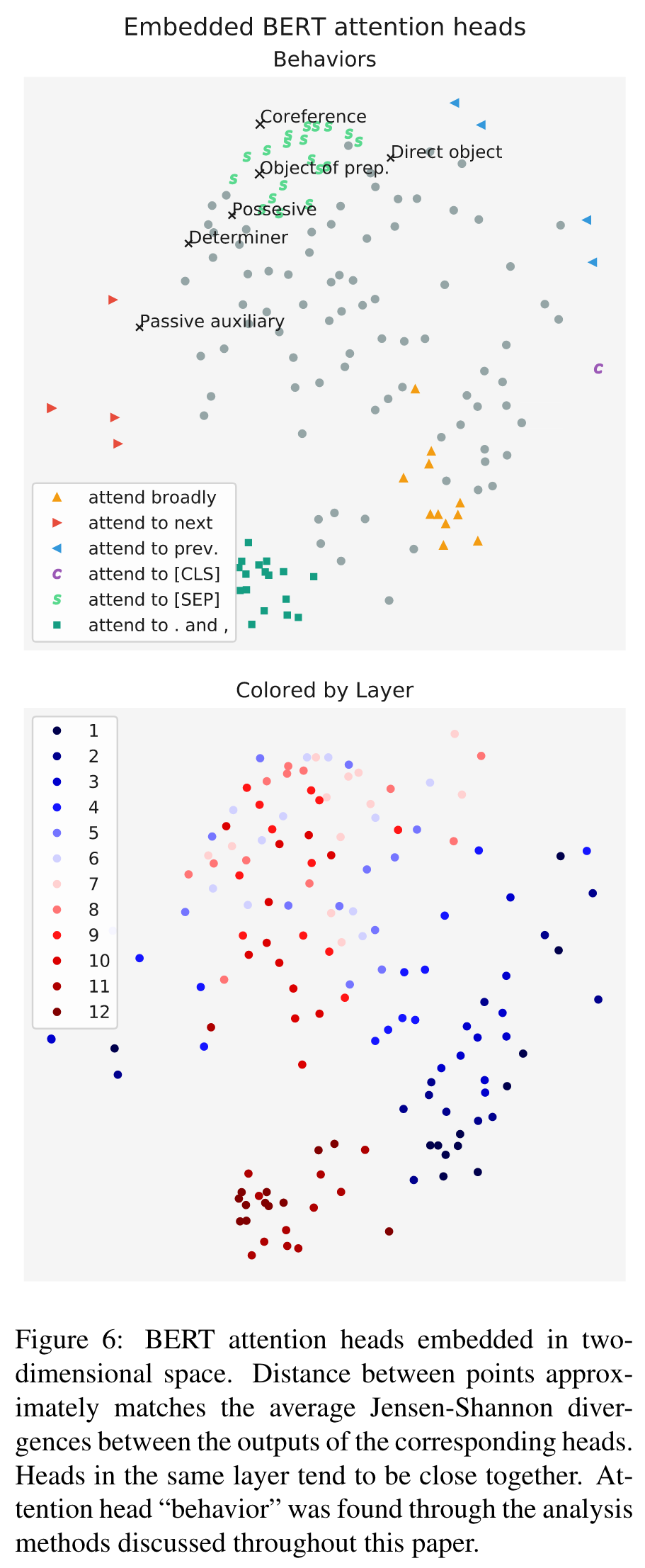
Clustering Attention Heads
Formally, we measure the distance between two heads Hi and Hj as: (p. 8)
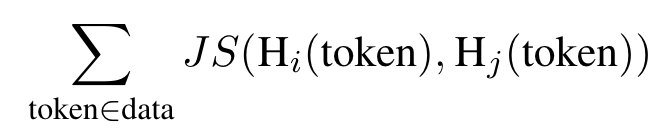
Where JS is the Jensen-Shannon Divergence between attention distributions. (p. 8)
We find that there are several clear clusters of heads that be have similarly, often corresponding to behaviors we have already discussed in this paper. Heads within the same layer are often fairly close to each other, meaning that heads within the layer have similar attention distributions. This finding is a bit surprising given that Tu et al. (2018) show that encouraging attention heads to have different behaviors can improve Transformer performance at machine translation. One possibility for the apparent redundancy in BERT’s attention heads is the use of attention dropout, which causes some attention weights to be zeroed-out during training. (p. 9)