BLIP Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
[data-cleaning mixture-of-experts noisy-label multimodal pre-training distill contrast-loss masked-lanuage-modeling deep-learning image-text-matching transformer This is my reading note for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. This paper proposed a multi model method. There are two contribution: 1) it utilizes a mixture of text encoder/decoder for different loss where most parameters are shared except self attention: 2) it proposes a caption-filtering process to clean the nous web data.
Introduction
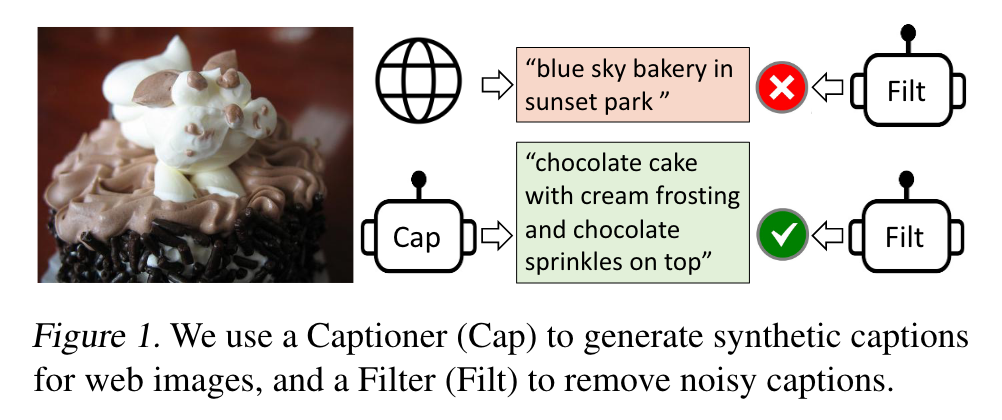
BLIP effectively utilizes the noisy web data by bootstrapping the captions, where a captioner generates synthetic captions and a filter removes the noisy ones. (p. 1)
However, existing pre-training methods have two major limitations:
- Model perspective: most methods either adopt an encoder-based model (Radford et al., 2021; Li et al., 2021a), or an encoder-decoder (Cho et al., 2021; Wang et al., 2021) model. However, encoder-based models are less straightforward to directly transfer to text generation tasks (e.g. image captioning), whereas encoder-decoder models have not been successfully adopted for image-text retrieval tasks. (p. 1)
- Despite the performance gain obtained by scaling up the dataset, our paper shows that the noisy web text is suboptimal for vision-language learning. (p. 1)
Two contributions of this method:
- Multimodal mixture of Encoder-Decoder (MED): a new model architecture for effective multi-task pre-training and flexible transfer learning. An MED can operate either as a unimodal encoder, or an image-grounded text encoder, or an image-grounded text decoder. The model is jointly pre-trained with three vision-language objectives: image-text contrastive learning, image-text matching, and image-conditioned language modeling.
- Captioning and Filtering (CapFilt): a new dataset boostrapping method for learning from noisy image-text pairs. We finetune a pre-trained MED into two modules: a captioner to produce synthetic captions given web images, and a filter to remove noisy captions from both the original web texts and the synthetic texts. (p. 1)
The biggest challenge is to design model architectures that can perform both understanding-based tasks (e.g. image-text retrieval) and generation-based tasks (e.g. image captioning) (p. 2)
Method
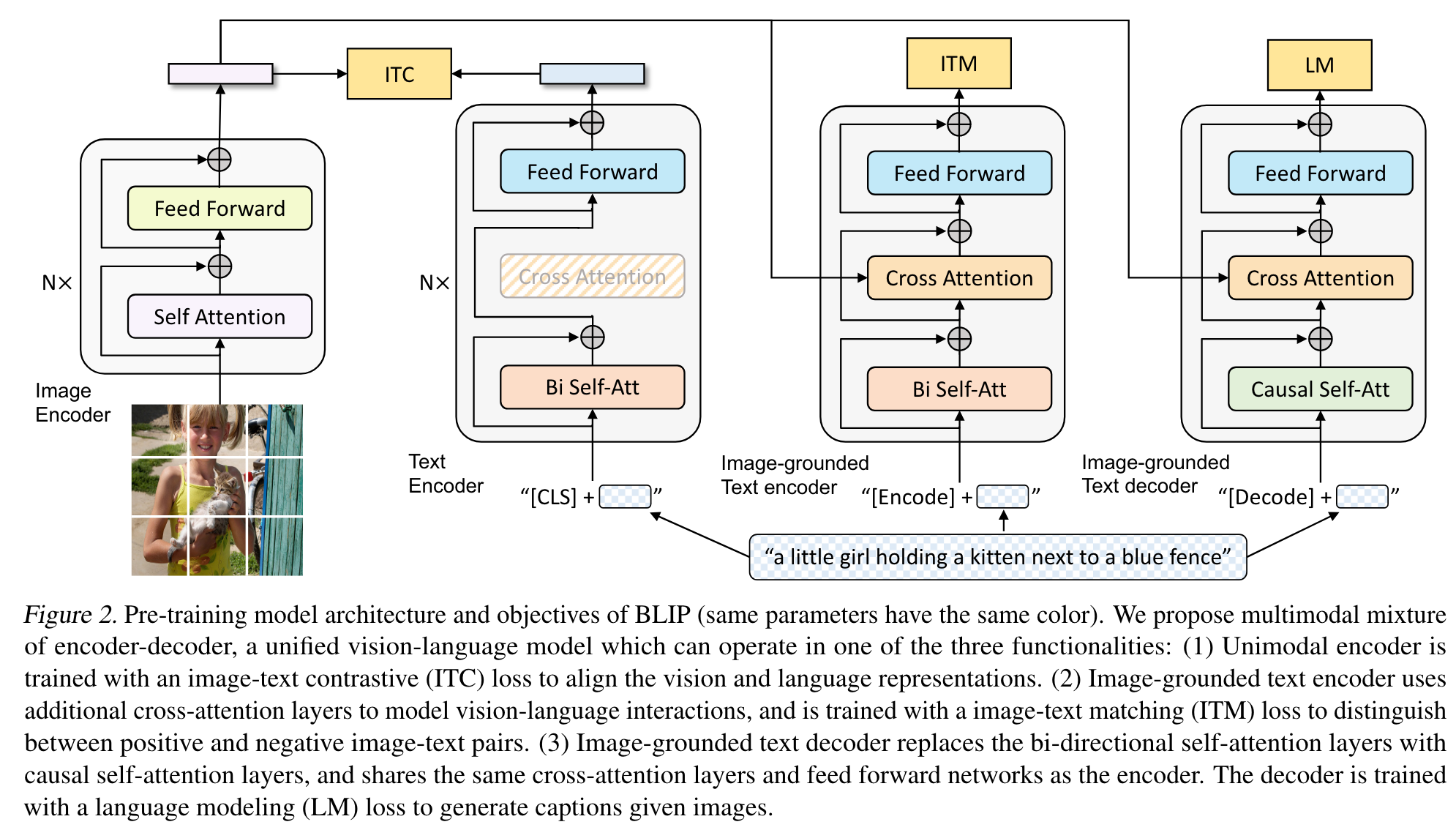
Model Architecture
In order to pre-train a unified model with both understanding and generation capabilities, we propose multimodal mixture of encoder-decoder (MED), a multi-task model which can operate in one of the three functionalities:
- Unimodal encoder, which separately encodes image and text. The text encoder is the same as BERT (Devlin et al., 2019), where a [CLS] token is appended to the beginning of the text input to summarize the sentence.
- Image-grounded text encoder, which injects visual information by inserting one additional cross-attention (CA) layer between the self-attention (SA) layer and the feed forward network (FFN) for each transformer block of the text encoder. A task-specific [Encode] token is appended to the text, and the output embedding of [Encode] is used as the multimodal representation of the image-text pair.
- Image-grounded text decoder, which replaces the bidirectional self-attention layers in the image-grounded text encoder with causal self-attention layers. A [Decode] token is used to signal the beginning of a sequence, and an end-of-sequence token is used to signal its end. (p. 3)
Pre-training Objectives
We jointly optimize three objectives during pre-training, with two understanding-based objectives and one generationbased objective. Each image-text pair only requires one forward pass through the computational-heavier visual transformer, and three forward passes through the text transformer, where different functionalities are activated to compute the three losses as delineated below. (p. 3)
- Image-Text Contrastive Loss (ITC)
- Image-Text Matching Loss (ITM). ITM is a binary classification task, where the model uses an ITM head (a linear layer) to predict whether an image-text pair is positive (matched) or negative (unmatched) given their multimodal feature. (p. 3)
- Language Modeling Loss (LM). It optimizes a cross entropy loss which trains the model to maximize the likelihood of the text in an autoregressive manner. We apply a label smoothing of 0.1 when computing the loss. Compared to the MLM loss that has been widely-used for VLP, LM enables the model with the generalization capability to convert visual information into coherent captions. (p. 3)
the text encoder and text decoder share all parameters except for the SA layers. The reason is that the differences between the encoding and decoding tasks are best captured by the SA layers. In particular, the encoder employs bi-directional self-attention to build representations for the current input tokens, while the decoder employs causal self-attention to predict next tokens. (p. 3)
CapFilt
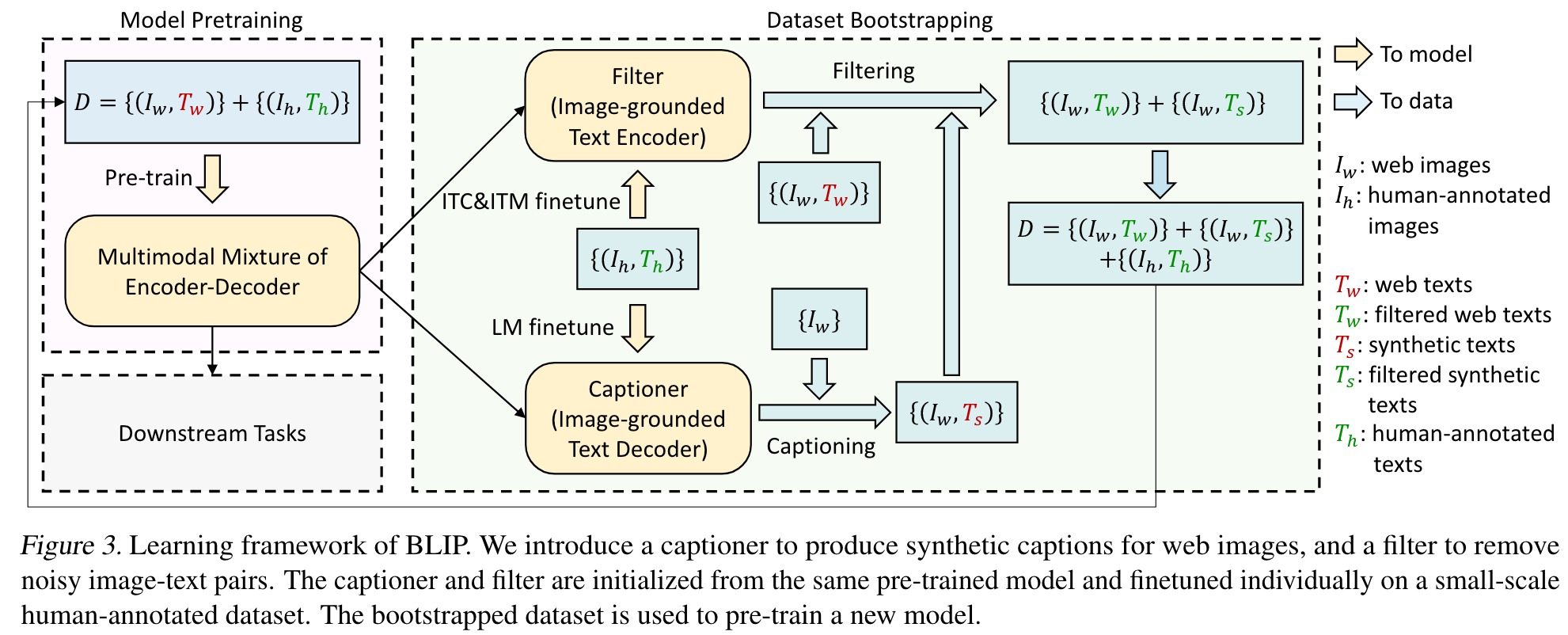
Figure 3 gives an illustration of CapFilt. It introduces two modules: a captioner to generate captions given web images, and a filter to remove noisy image-text pairs. Both the captioner and the filter are initialized from the same pre-trained MED model, and finetuned individually on the COCO dataset. The finetuning is a lightweight procedure. (p. 4)
Specifically, the captioner is an image-grounded text decoder. It is finetuned with the LM objective to decode texts given images. Given the web images Iw, the captioner generates synthetic captions Ts with one caption per image. The filter is an image-grounded text encoder. It is finetuned with the ITC and ITM objectives to learn whether a text matches an image. The filter removes noisy texts in both the original web texts Tw and the synthetic texts Ts, where a text is considered to be noisy if the ITM head predicts it as unmatched to the image. Finally, we combine the filtered image-text pairs with the human-annotated pairs to form a new dataset, which we use to pre-train a new model. (p. 4)
Experiments and Discussions
Pre-training Details
We pre-train the model for 20 epochs using a batch size of 2880 (ViT-B) /2400 (ViT-L). We use AdamW (Loshchilov & Hutter, 2017) optimizer with a weight decay of 0.05. The learning rate is warmed-up to 3e-4 (ViT-B) / 2e-4 (ViT-L) and decayed linearly with a rate of 0.85. We take random image crops of resolution 224 × 224 during pre-training, and increase the image resolution to 384 × 384 during finetuning. (p. 4)
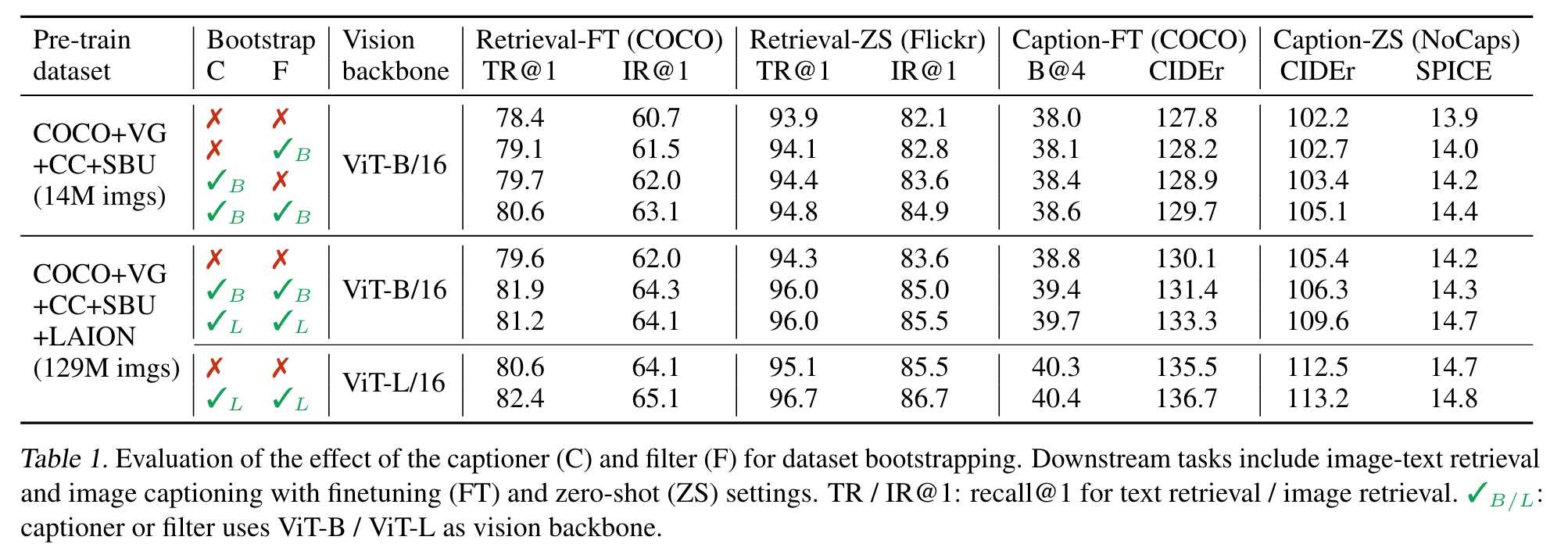
Effect of CapFilt
When only the captioner or the filter is applied to the dataset with 14M images, performance improvement can be observed. When applied together, their effects compliment each other, leading to substantial improvements compared to using the original noisy web texts. (p. 4)

Diversity is Key for Synthetic Captions

In CapFilt, we employ nucleus sampling (Holtzman et al., 2020) to generate synthetic captions. Nucleus sampling is a stochastic decoding method, where each token is sampled from a set of tokens whose cumulative probability mass exceeds a threshold p (p = 0.9 in our experiments). In Table 2, we compare it with beam search, a deterministic decoding method which aims to generate captions with the highest probability. Nucleus sampling leads to evidently better performance, despite being more noisy as suggested by a higher noise ratio from the filter. We hypothesis that the reason is that nucleus sampling generates more diverse and surprising captions, which contain more new information that the model could benefit from. On the other hand, beam search tends to generate safe captions that are common in the dataset, hence offering less extra knowledge. (p. 5)
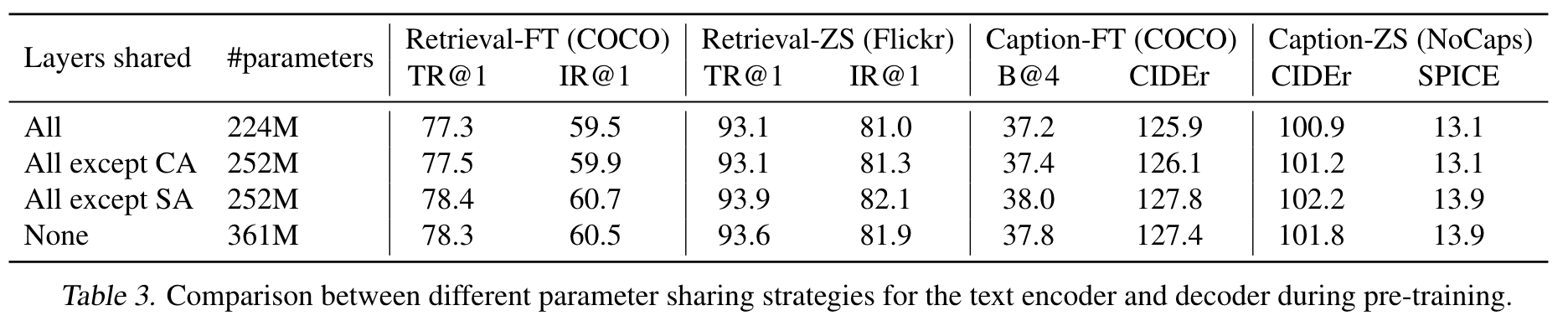
Parameter Sharing and Decoupling

If the SA layers are shared, the model’s performance would degrade due to the conflict between the encoding task and the decoding task. (p. 6)
In Table 4, we study the effect if the captioner and filter share parameters in the same way as pre-training. The performance on the downstream tasks decreases, which we mainly attribute to confirmation bias. Due to parameter sharing, noisy captions produced by the captioner are less likely to be filtered out by the filter, as indicated by the lower noise ratio (8% compared to 25%). (p. 6)
Visual Question Answering (VQA)
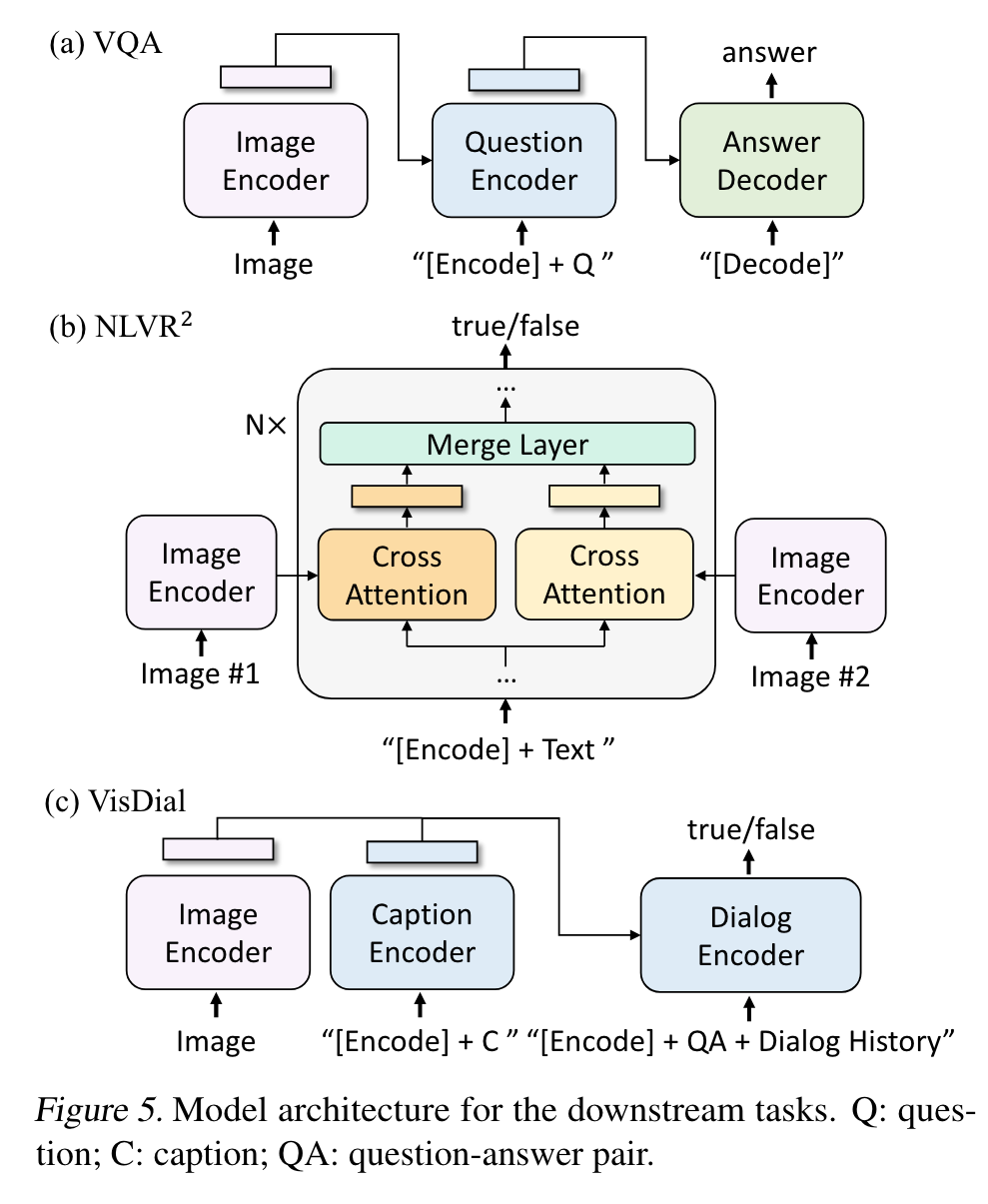
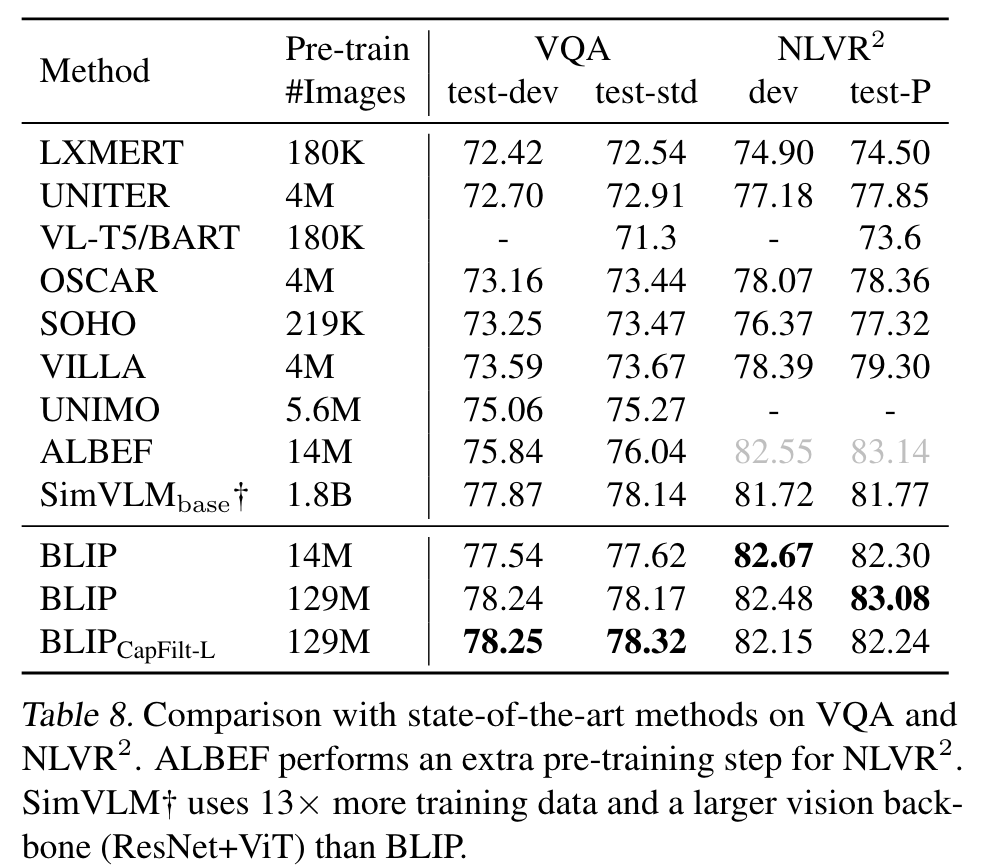
during finetuning, we rearrange the pre-trained model, where an image-question is first encoded into multimodal embeddings and then given to an answer decoder. The VQA model is finetuned with the LM loss using ground-truth answers as targets. (p. 7)
Natural Language Visual Reasoning (NLVR2)
NLVR2 (Suhr et al., 2019) asks the model to predict whether a sentence describes a pair of images. (p. 7)
As shown in Figure 5(b), for each transformer block in the image-grounded text encoder, there exist two cross-attention layers to process the two input images, and their outputs are merged and fed to the FFN. The two CA layers are intialized from the same pre-trained weights. The merge layer performs simple average pooling in the first 6 layers of the encoder, and performs concatenation followed by a linear projection in layer 6-12. (p. 8)
Visual Dialog (VisDial)
VisDial (Das et al., 2017) extends VQA in a natural conversational setting, where the model needs to predict an answer not only based on the image-question pair, but also considering the dialog history and the image’s caption. (p. 8)
we concatenate image and caption embeddings, and pass them to the dialog encoder through cross-attention. The dialog encoder is trained with the ITM loss to discriminate whether the answer is true or false for a question, given the entire dialog history and the image-caption embeddings (p. 8)
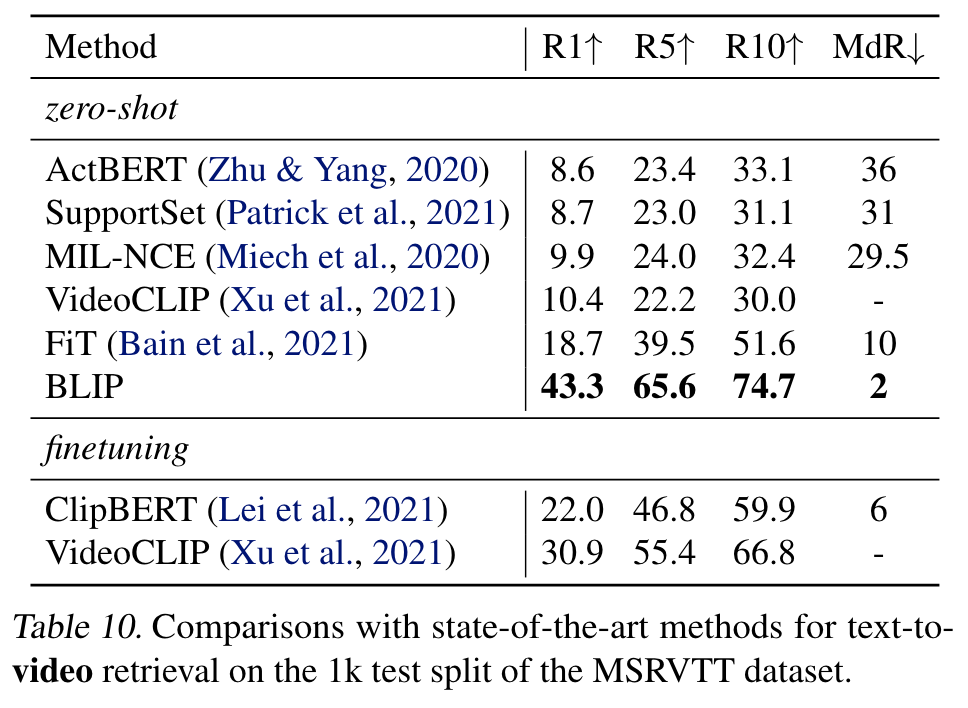
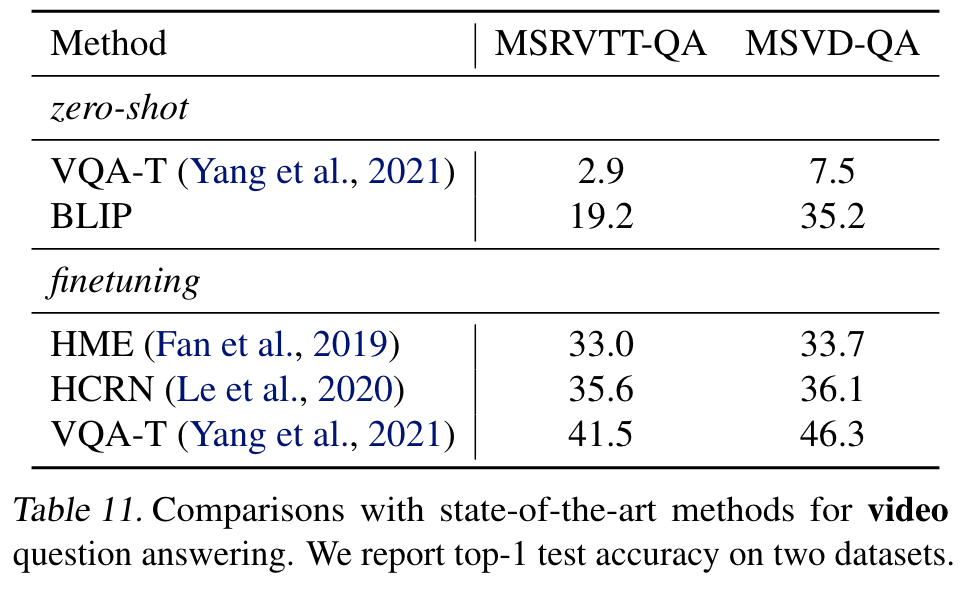
Zero-shot Transfer to Video-Language Tasks
To process video input, we uniformly sample n frames per video (n = 8 for retrieval and n = 16 for QA), and concatenate the frame features into a single sequence. (p. 8)


Additional Ablation Study
Improvement with CapFilt is not due to longer training
As shown in Table 12, longer training using the noisy web texts does not improve performance. (p. 8)
A new model should be trained on the bootstrapped dataset
Table 13 hows that continue training does not help. This observation agrees with the common practice in knowledge distillation, where the student model cannot be initialized from the teacher. (p. 9)