CapsFusion Rethinking Image-Text Data at Scale
[multimodal deep-learning dataset laclip veclip chat-gpt coca image-caption caps-fusion llama This is my reading note for CapsFusion: Rethinking Image-Text Data at Scale. The paper studies the quality of caption data in vision language dataset and shown the simple caption limits the performance of the trained model. The caption of those dataset is generated synthetic and filter out a lot of real would knowledge. As a result, the paper proposes to use chatGPT to combine the synthetic caption and raw caption to generates a better caption. It’ then results in a much
Introduction
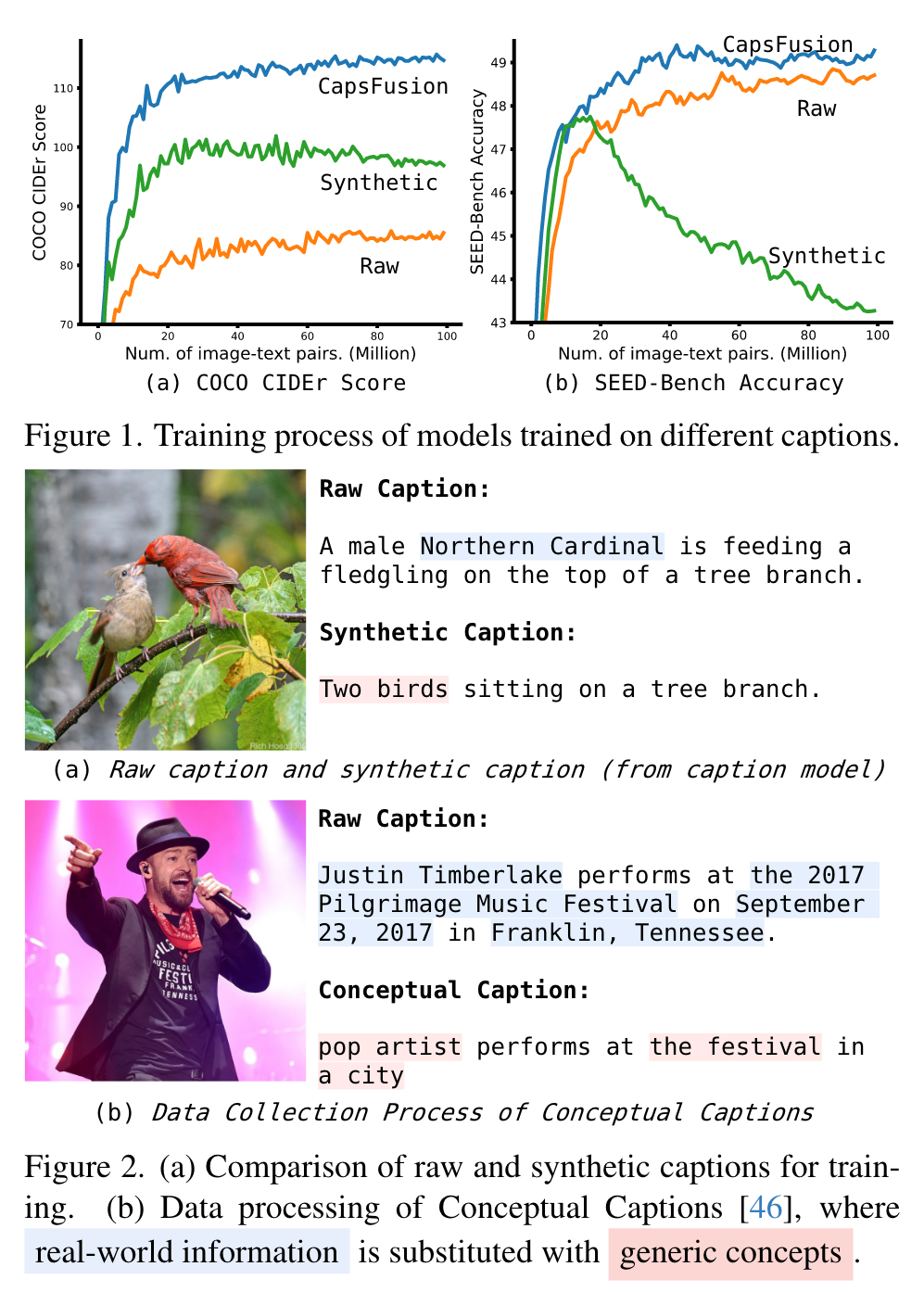
However, our experiments reveal significant Scalability Deficiency and World Knowledge Loss issues in models trained with synthetic captions, which have been largely obscured by their initial benchmark success. Upon closer examination, we identify the root cause as the overly-simplified language structure and lack of knowledge details in existing synthetic captions. To provide higher-quality and more scalable multimodal pretraining data, we propose CAPSFUSION, an advanced framework that leverages large language models to consolidate and refine information from both web-based image-text pairs and synthetic captions. (p. 1)
Although achieving promising performance on classic benchmarks such as COCO Caption [12], further evaluations on more recent benchmarks such as SEED-Bench [32] reveal that training LMMs with synthetic captions alone is inadequate. (p. 1)
We conduct a closer examination of the large-scale training process of LMMs and observe that model training on synthetic captions rapidly reaches a saturation point, beyond which the model performance may even degrade (as illustrated by the green lines in Fig. 1). (p. 2)
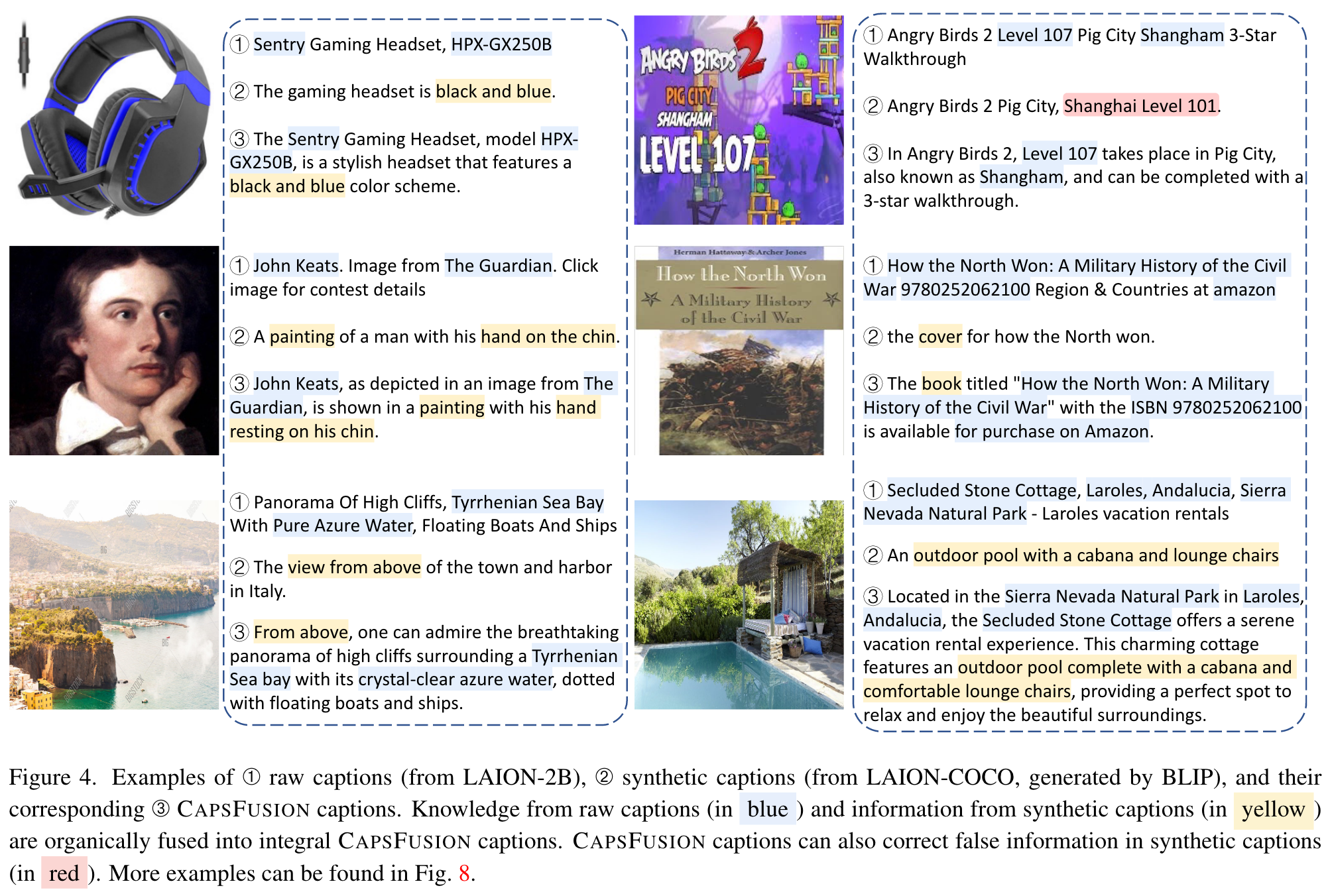
These examples demonstrate that the outputs from M2, in particular, suffer from severe World Knowledge Loss, constituting only high-level concepts while missing all the details about well-known people, locations, events, etc. (p. 2)
Through examining the differences between raw caption data and synthetic data used in training, we observe that the simplistic syntactic and semantic structures in synthetic captions (Fig. 2-a) may have potentially attributed to the Scalability Deficiency and World Knowledge Loss issues, which so far have been obscured by their initial benchmark success. The root cause is that currently used captioning models (e.g. BLIP [34] used in LAION-COCO [1]) for generating synthetic captions heavily rely on academic datasets such as COCO and Conceptual Captions [46] for training. These datasets replace specific details (e.g. people’s names, locations, landmarks) with more generic conceptual placeholders (e.g. ‘person’, ‘city’) in the data collection process (Fig. 2-b). (p. 2)
Therefore, to train a scalable LMM with abundant real-world knowledge, it is crucial to develop an effective strategy to better synthesize caption data while distilling real-world knowledge from raw web-based image-text pairs. (p. 2)
There have been some recent attempts to leverage both raw and synthetic captions straightforwardly, by simply mixing them with a fixed hand-tuned ratio [16, 19, 39]. (p. 2)
CAPSFUSION first uses a captioning model [34] (following [1, 34]) to generate synthetic captions for images. Then, it utilizes ChatGPT [45] that follows instructions to organically integrate raw and synthetic captions, by extracting real-world knowledge from the structure-flawed raw captions while merging with structured but syntactically simplified synthetic captions. (p. 2)
Refined captions from CAPSFUSION require 11-16 times less computation to achieve high performance similar to synthetic captions. (p. 3)
Related Work
LaCLIP [16] utilizes LLM to rewrite raw captions, whose performance can be limited due to severe hallucination, because of limited visual information and low-quality raw captions. [19, 39] investigate how to filter and then mix raw and synthetic captions to induce a better CLIP model [43]. Our concurrent work VeCLIP [31] proposes to use LLM to combine information from raw and synthetic captions. (p. 3)
Proposed Method
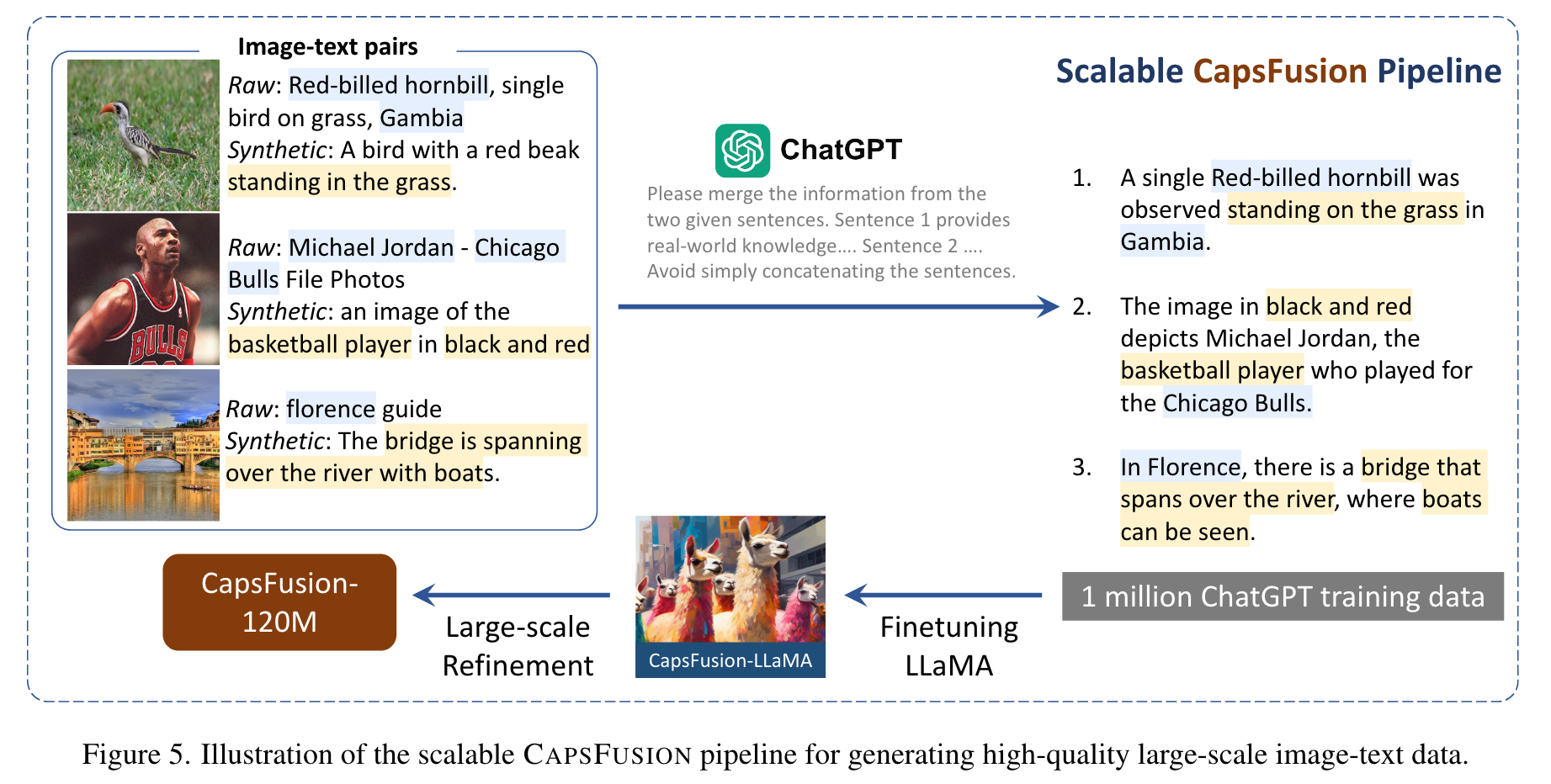
Caption Generation: we find that raw captions contain a wealth of real-world knowledge but are noisy, while synthetic captions have clean structures but lack in-depth real-world knowledge, which exhibits severe scalability issues. (p. 4)
Caption Fusion via ChatGPT: In CAPSFUSION, we use ChatGPT to fuse raw and synthetic captions given a prompt. Each prompt comprises three components: the task instruction, a raw caption, and a synthetic caption. (p. 4)
The prompt for ChatGPT and CAPSFUS-LLaMA to integrate raw and synthetic captions is shown below.
Please merge and refine the information from the two given sentences. Sentence 1 provides detailed real-world knowledge, yet it suffers from flaws in sentence structure and grammar. Sentence 2 exhibits nice sentence structure, but lacking in-depth real-world details and may contain false information. Please combine them into a new sentence, ensuring a well-structured sentence while retaining the detailed real-world information provided in Sentence 1. Avoid simply concatenating the sentences. Sentence 1: <raw caption> Sentence 2: <synthetic caption>
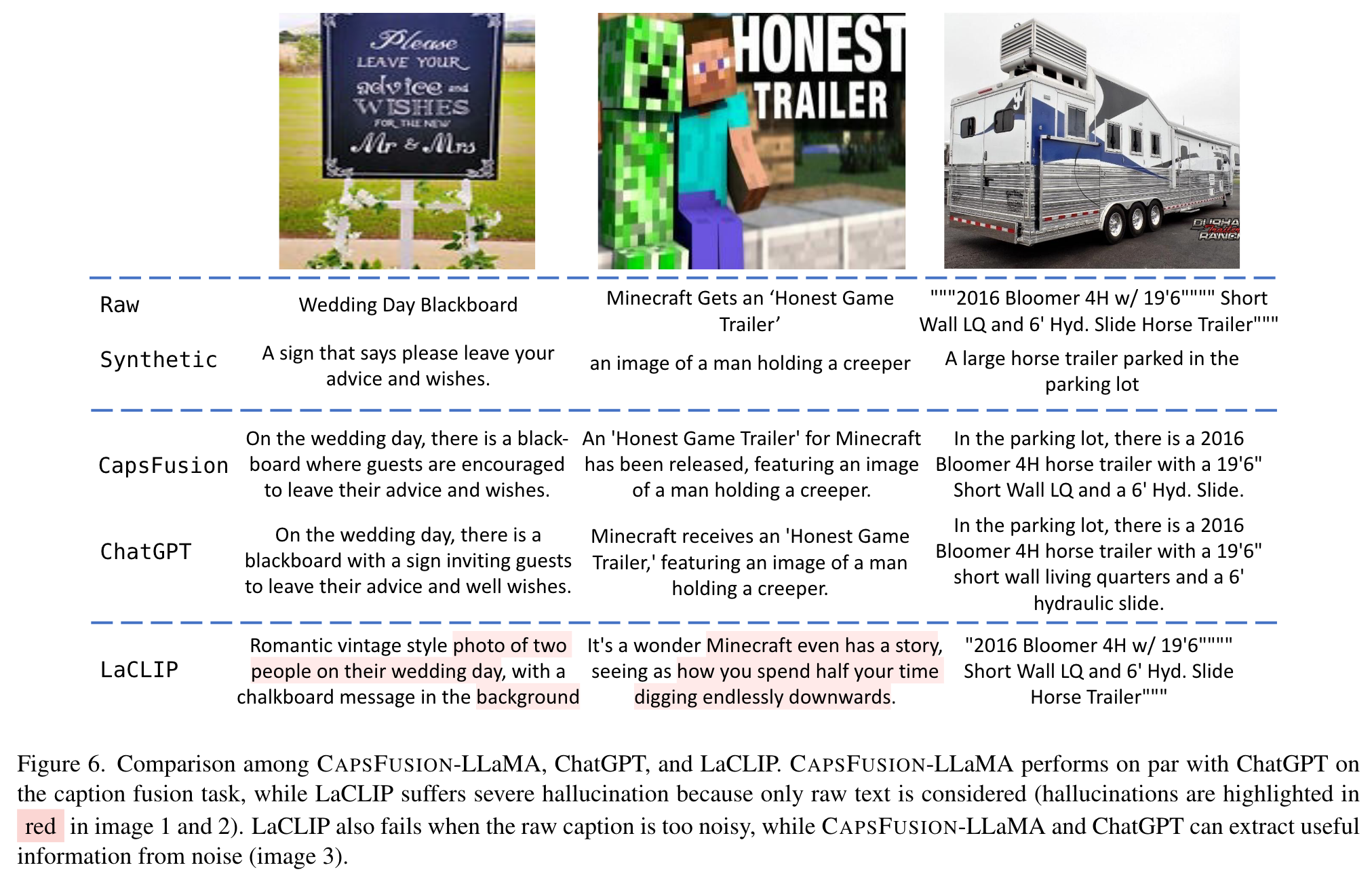
Refinement Model with Fused Caption: We finetune the 13B version of LLaMA-2 specifically for the task of caption fusion, using triplets obtained from ChatGPT. These triplets consist of raw and synthetic captions as inputs, with CAPSFUSION captions as the target outputs. LaCLIP [16] also leverages LLM for enhancing image-text captions, but simply asks LLM to rewrite raw captions. Notably, LaCLIP tends to hallucinate information not present in the associated image, due to the absence of detailed visual information represented in the raw captions. On the other hand, CAPSFUS-LLaMA exhibits outputs similar to ChatGPT and delivers exceptional performance. (p. 6)

Experiments
Setup
Model Architecture We adopt the most prevalent LMM architecture, which consists of three components: an LLM, a vision encoder, and a vision-language bridging module. We use LLaMA-2-7B [52] and EVA-01-CLIP-g [17, 49] to initialize the LLM and vision encoder modules, respectively. For the bridging module, we follow Emu [50] to use a randomly initialized Causal Transformer to bridge the vision and language modalities. (p. 7)
Training Schedule. we train the model for 1 epoch The peak learning rate is 3e4, with the initial 2,000 (100M) / 1,000 (50M) / 500 (10M) steps as warm-up, after which the learning rate decreases to 3e-5 with a cosine learning rate decay schedule. Batch size is set to 8192 for all scales. (p. 7)
Model Performance
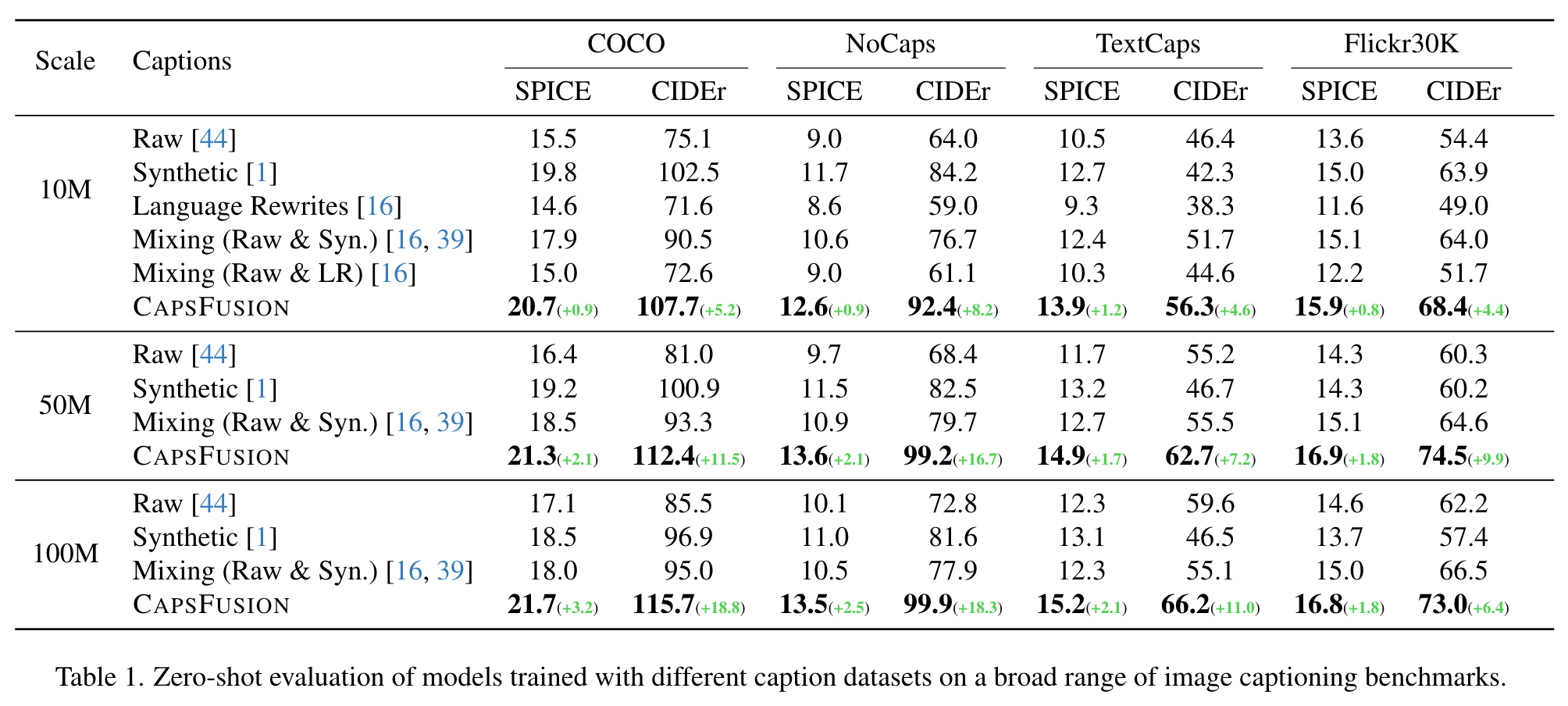


Rewriting Captions Fails at Image Captioning
On the 10M scale, our examination reveals that Language Rewrites captions [16], generated through the process of rewriting raw captions, fail to achieve decent performance. This can be attributed to the severe hallucination issue we observed in the rewrites captions (Fig. 6), which introduces extraneous text that is irrelevant to the content depicted in the accompanying images. The underlying cause of the hallucination phenomenon can be traced back to the input data, which consists solely of noisy raw captions, providing a suboptimal starting point for the rewriting process. (p. 7)
Mixing Captions does not Bring Consistent Gains
Another notable observation is that mixing captions cannot yield better performance. (p. 7)
Synthetic Captions Shout at Small Scale
A noteworthy observation is that synthetic caption demonstrates exceptional results on the 10M dataset (102.5 COCO CIDEr), while exhibiting inferior performance (96.93 COCO CIDEr) on the larger-scale 100M dataset. This aligns with our earlier observation of the scalability deficiency issue in synthetic captions, a potential threat to the effective training of LMMs. (p. 8)
Sample Efficiency
we find that with only 10M imagetext pairs, CAPSFUSION captions outperform other captions with much larger scale (50M and 100M), demonstrating exceptional sample efficiency. (p. 8)
Scalability Analysis
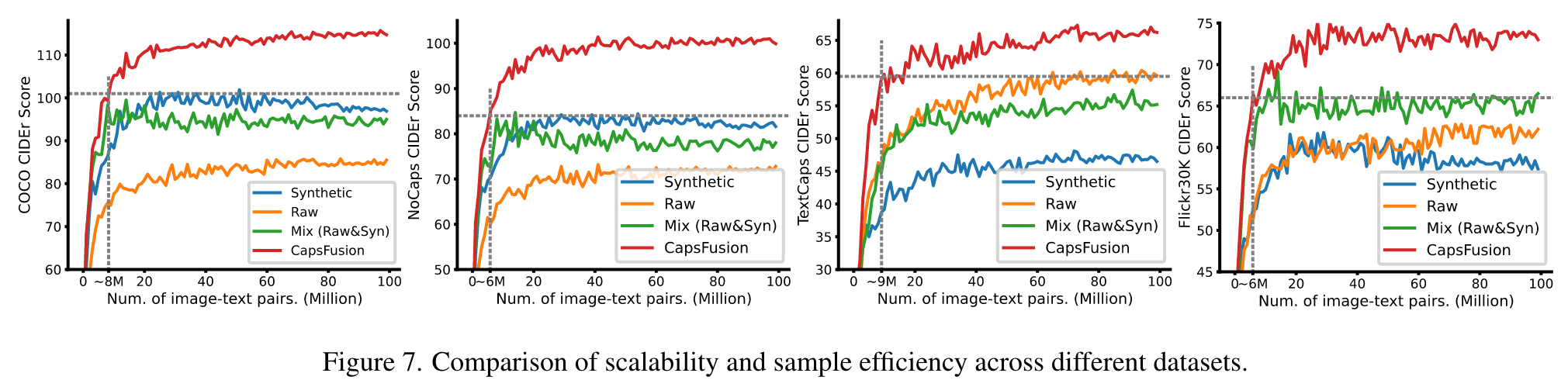
This can be observed from Fig. 7 (a), (b), and (d), wherein the blue lines exhibit early saturation with a mere 30 million image-text pairs. Subsequently, their performance gradually deteriorates. In contrast, raw caption (orange lines) displays commendable scalability, with its performance showing a consistent upward trajectory as more training samples are involved. However, the inherent high noise level in raw caption hampers its ability to achieve strong performance. CAPSFUSION caption (red lines) exhibits remarkable scalability on all datasets, outperforming both synthetic and raw captions by a substantial margin throughout the entire scale. (p. 8)
Qualitative Evaluation on World Knowledge

We observe that models trained on raw and CAPSFUSION captions exhibit rich real-world knowledge, able to identify celebrities (Fig. 3 image 1 and 2), recognize famous artworks (Fig. 9 image 2), attribute literature works to their authors (Fig. 3 image 2), and pinpoint the location where the specific event in the image occurred (Fig. 3 image 3). Models trained on synthetic captions totally lost such capabilities. (p. 9)
Effects when Firing LLM
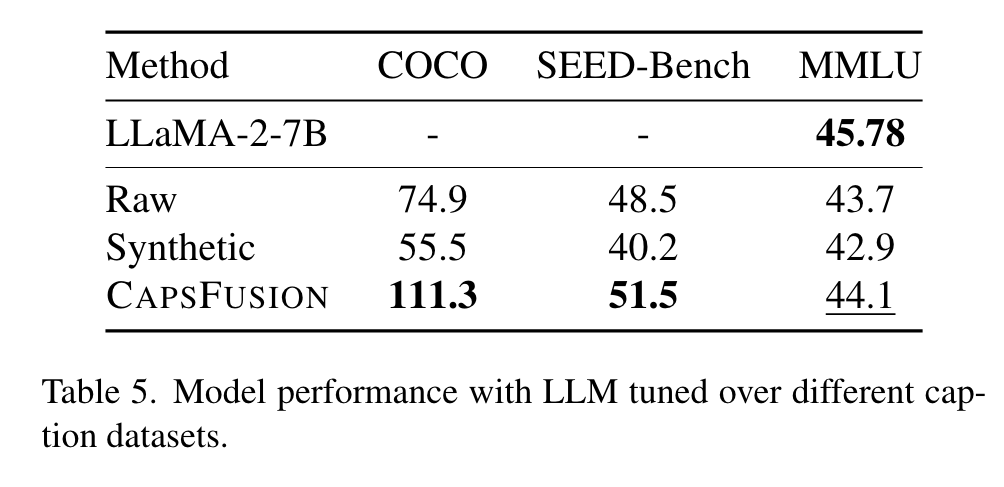
Notably, we observe a significant decline in the performance of synthetic captions on the COCO Captions dataset. This stark drop indicates a potential deterioration in the LLM’s capabilities when it is trained on the simplified language of synthetic captions. (p. 9)