Chatting Makes Perfect Chat-based Image Retrieval
[deep-learning multimodal read chat blip2 chatgpt image-retrieval dialog conversation alpaca llama flan chat-ir This is my reading note for [Chatting Makes Perfect: Chat-based Image Retrieval]. This paper proposes a method on using dialog (questions and answer pairs) to improve text based image retrieval. It experimented with different questioners (human, chatGPT and other LLM) and different answers (human, BLIP2). It showed that, dialog could significantly improves the retrieval performance. However, only chatGPT and human questioners could improve performance with more rounds of conversation.
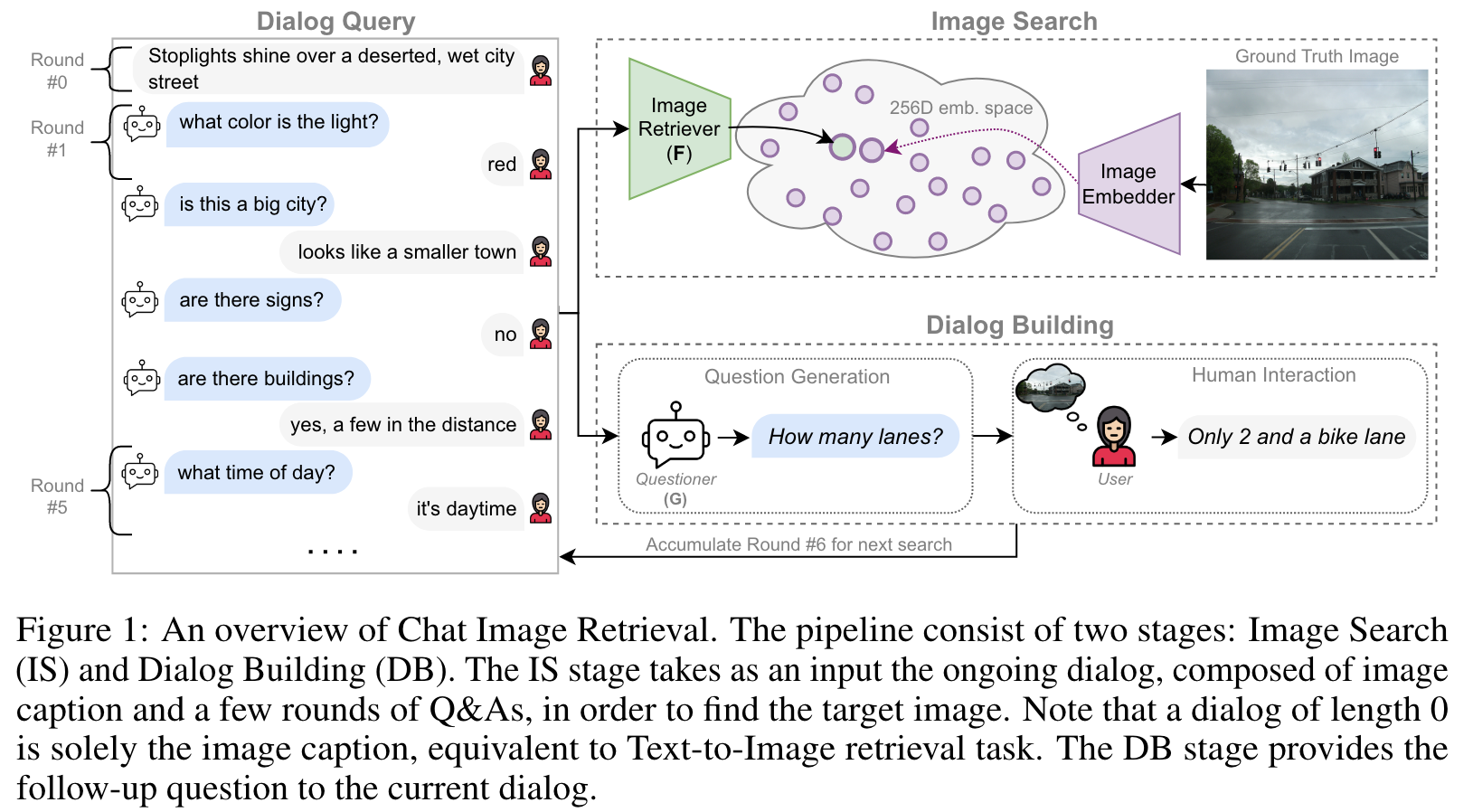
Introduction
However, existing image retrieval approaches typically address the case of a single query-to-image round, and the use of chats for image retrieval has been mostly overlooked. In this work, we introduce ChatIR: a chat-based image retrieval system that engages in a conversation with the user to elicit information, in addition to an initial query, in order to clarify the user’s search intent. Motivated by the capabilities of today’s foundation models, we leverage Large Language Models to generate follow-up questions to an initial image description. (p. 1)
In contrast, ChatIR proactively obtains the information from the user and is able to process it in a unified and continuous manner in order to retrieve the target image within a few question answering (Q&A) rounds. (p. 2)
Specifically, the ChatIR system that we propose in this work consists of two stages, Image Search (IS) and Dialog Building (DB), as depicted in Figure 1. Image search is performed by an image retriever model F , which is a text encoder that was trained to project dialogues sequences (of various lengths) into a visual embeddings space. The DB stage employs a question generator G, whose task is to generate the next question for the user, taking into account the entire dialog up to that point. The two components of ChatIR are built upon the strong capabilities of instructional LLMs (where the model is instructed about the nature of the task) and foundation Vision and Language (V&L) models. (p. 2)
Composed Image Retrieval (CoIR) [19, 27, 49, 52]. The CoIR task involves finding a target image using a multi-modal query, composed of an image and a text that describes a relative change from the source image. (p. 4)
Method
Let us denote the ongoing dialog as D_i := (C, Q_1, A_1, …, Q_i, A_i), where C is the initial text description (caption) of the target image, with {Q_k}_i^{k=1} denoting the questions and {A_k }_i^{k=1} their corresponding answers at round i. (p. 4)
Dialog Builder Model
In our case G is an LLM that generates the next question Q_{i+1} based on the dialog history D_i, i.e. G : D_i → Q_{i+1}. Thus, in these experiments, all of the questions are answered using the same off-the-shelf model (BLIP2 [21]). (p. 4)
Image Retriever Model
As our F we use BLIP [22] pre-trained image/text encoders, fine-tuned for dialog-based retrieval with contrastive learning. We leverage the text encoder self-attention layers to allow efficient aggregation of different parts of the dialog (caption, questions, and answers), and for high level perception of the chat history. Motivated by previous work [20, 29, 33], we concatenate Di’s elements with a special separating token [SEP], and an added [CLS] token to represent the whole sequence. (p. 4)
Implementation details
Following previous retrieval methods [19, 41], we use the Recall@K surrogate loss as the differentiable version of the Recall@K metric. (p. 4)
Evaluation


Comparison With Existing Text-to-Image Retrieval Methods
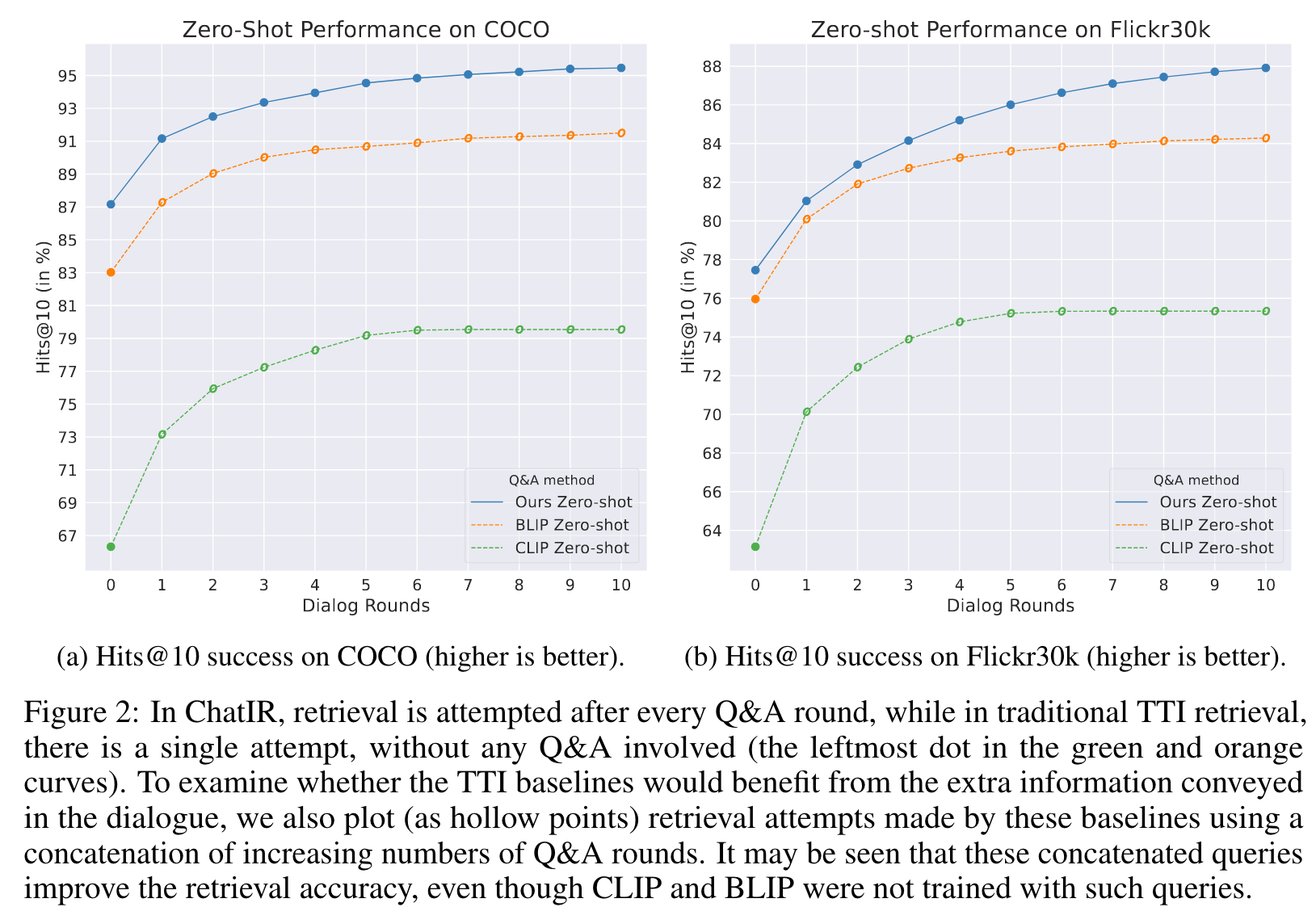
Furthermore, when we provide the baselines with the concatenated text of the dialogues, instead of just a caption, they exhibit a significant improvement over the single-hop TTI attempt. These zero-shot results show that: 1) dialogues improve retrieval results for off-the-shelf TTI models. Although the CLIP and BLIP baselines have only been trained for retrieval with relatively short (single-hop) text queries, they are still capable of leveraging the added information in the concatenated Q&A text. Note that CLIP becomes saturated at a certain point due to the 77 token limit on the input. 2) Our strategy of training an Image Retriever model with dialogues (as described in Sec. 3) further improves the retrieval over the compared methods (p. 5)
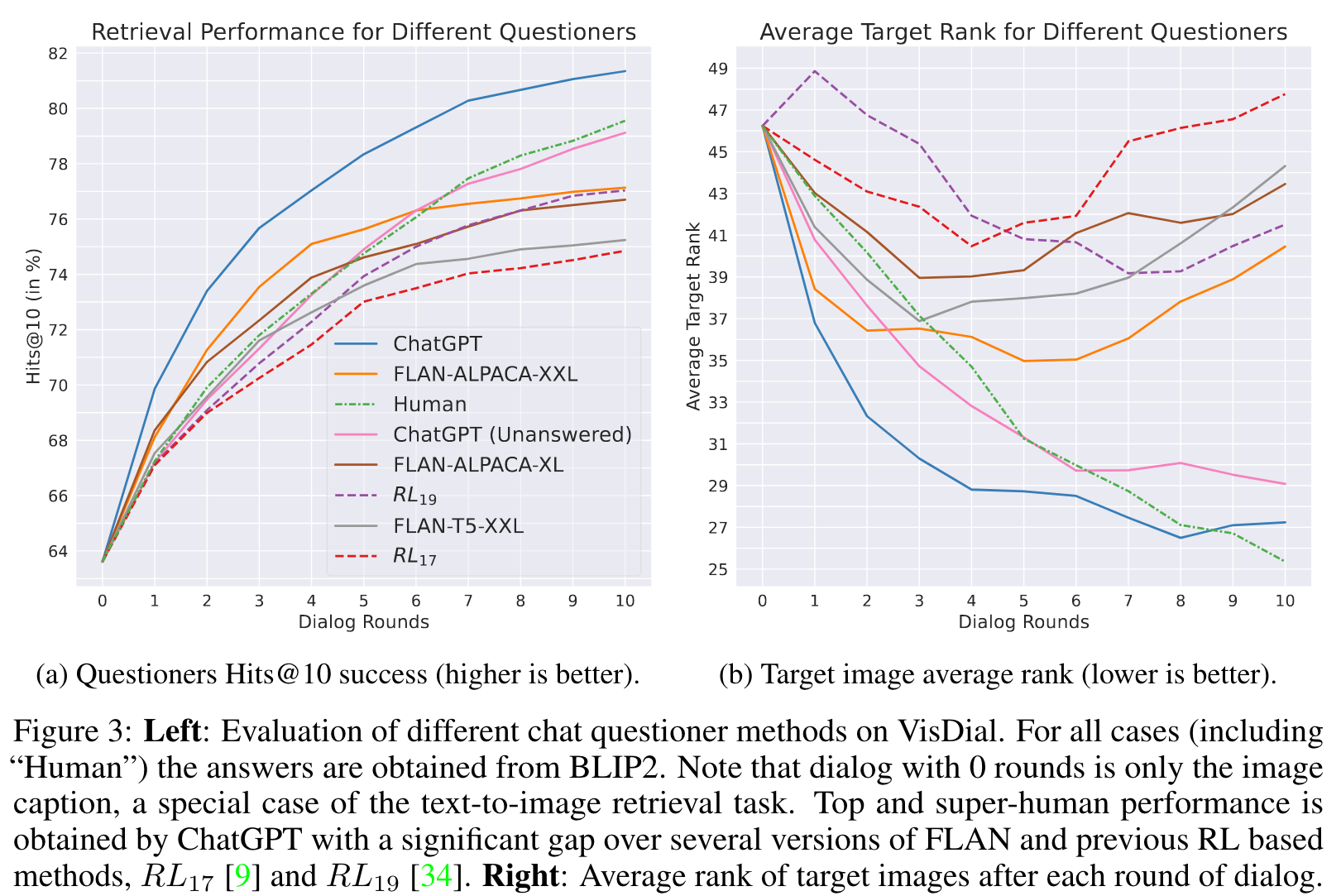
Comparison Between Questioners
The first observation shows a consistent improvement of retrievals with the length of the dialog, demonstrating the positive impact of the dialog on the retrieval task. Looking at the top-performing model, we already reach a high performance of 73.5% Hit rate in a corpus of 50K unseen images, after just 2 rounds of dialog, a 10% improvement over TTI (from ∼ 63%, round 0 in the plot). We also observe that questioners from the previous work of [9, 34] based on RL training are among the low performing methods. (p. 6)
Next, we see a wide performance range for FLAN models with FLAN-ALPACA surpassing human questioners in early rounds, while their success rate diminishes as the dialog rounds progress, causing them to underperform compared to humans. However, the success rate the ChatGPT (Unanswered) questioner (pink line), that excludes answer history, is comparable to that of humans, with less than ∼ 0.5% gap. By allowing a full access to the chat history, the ChatGPT questioner (blue line) surpasses all other methods, mostly by a large margin (with ∼2% over Human). Perhaps more importantly, in both ChatGPT questioners we see a strong and almost monotonic decrease in Average Target Rank (Fig. 3b) as the dialog progresses (blue and pink lines), similarly to the Human case (green dashed line). (p. 6)
While the average number of repetitions is nearly 0 for either human or ChatGPT questioners, the other methods exhibit an average of 1.85 − 3.44 repeated questions per dialog. (p. 6)
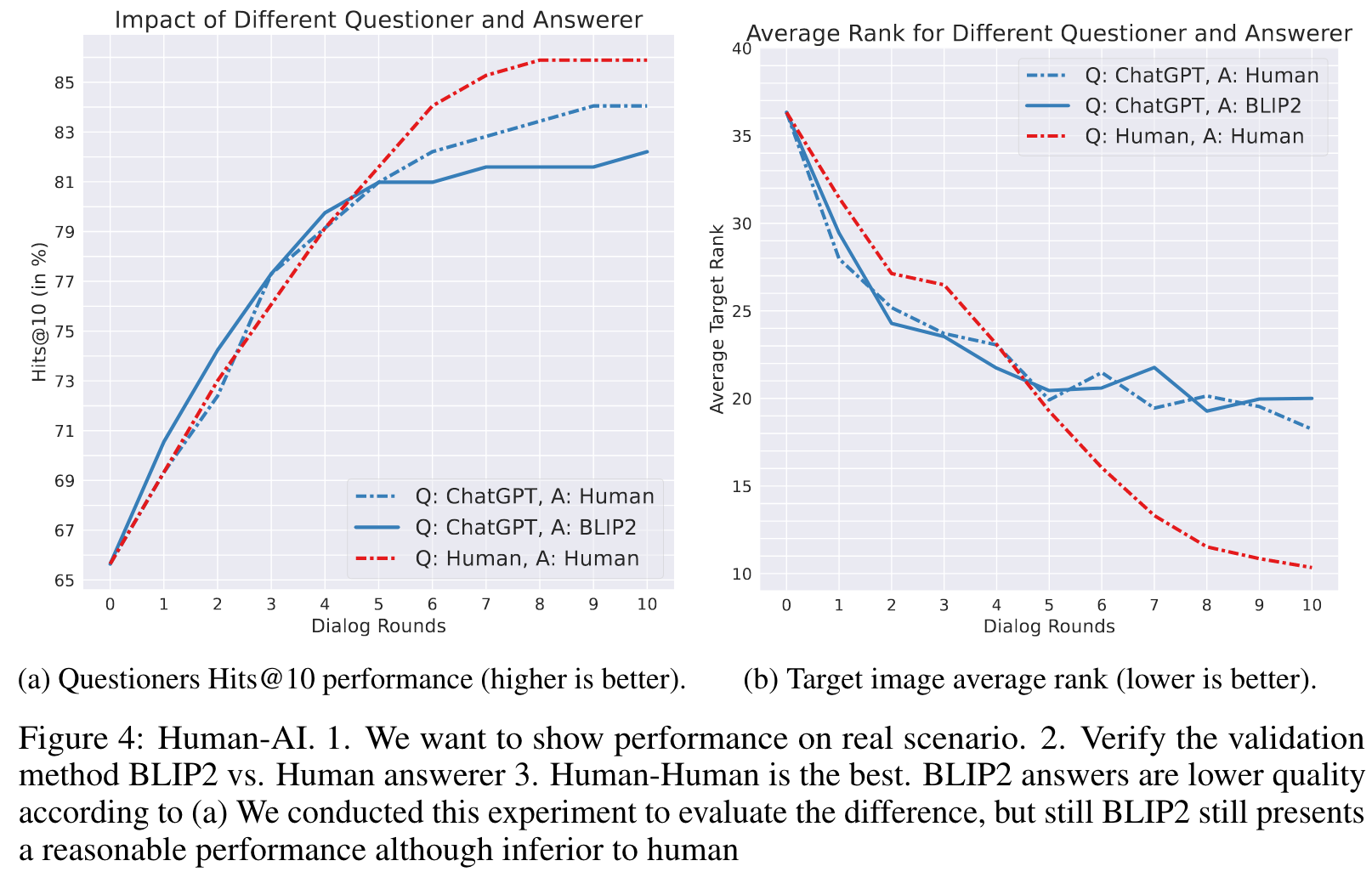
Comparison to Human In The Loop
Considering the previous experiment in Figure 3, showing the advantage of ChatGPT over Human as questioner, we observe that Human generated answers are of better quality than BLIP2 (in terms of final retrieval results). This advantage boosts the Human full loop to become more effective than ChatGPT. The results imply a small domain gap between BLIP2 and Human answerer (but with similar trend), justifying the usage of BLIP2 in our evaluations. (p. 7)
Ablation
Masking strategy
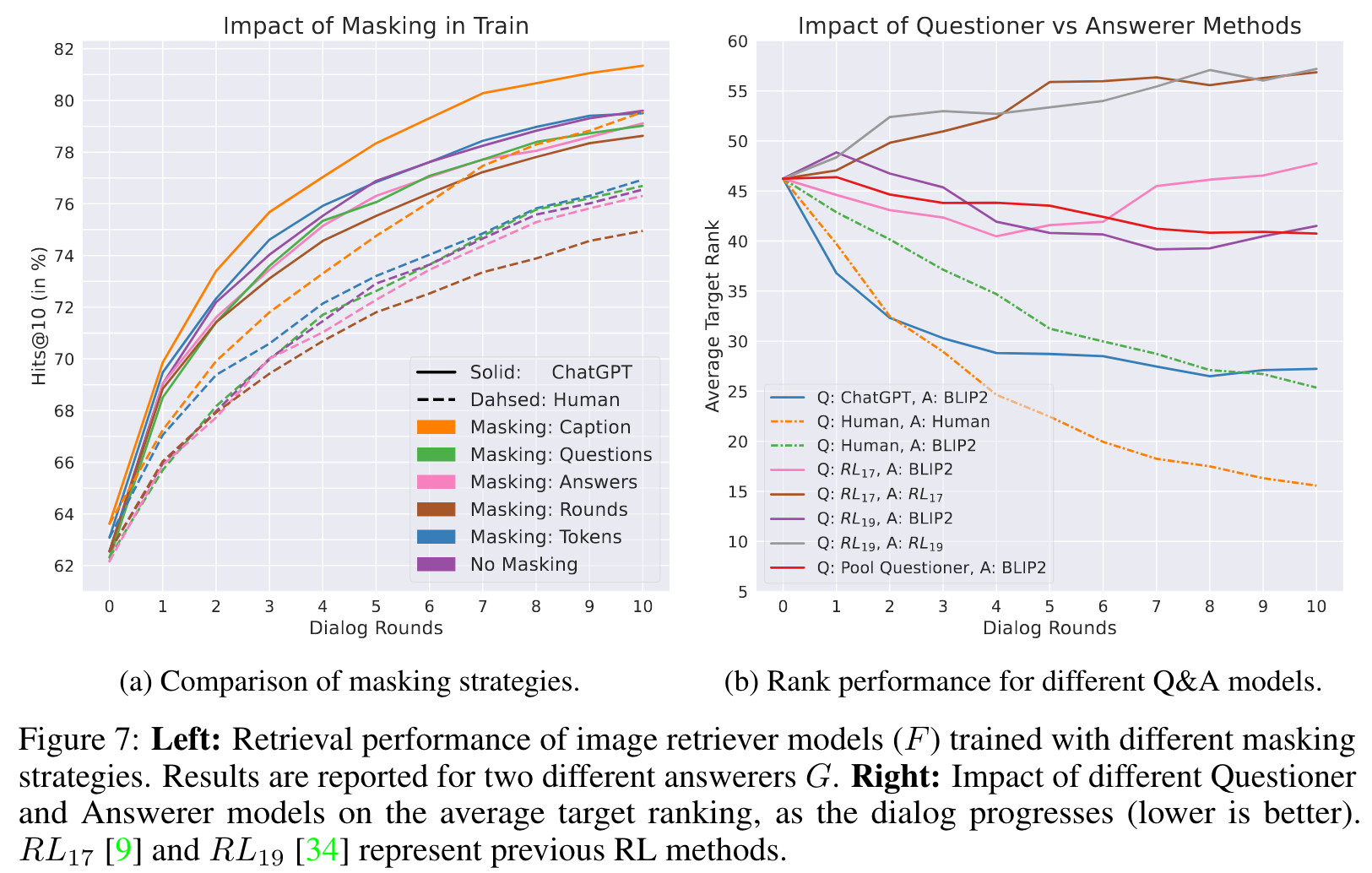
masking the captions improves the performance by 2 − 3% regardless of the questioner type. By hiding the image caption during training, F is forced to pay more attention to the rest of the dialogue in order to extract information about the target image. Thus, F is able to learn even from training examples where retrieval succeeds based on the caption alone. (p. 10)
Question Answering methods
We observe that Human and ChatGPT questioners are the only cases that improve along the dialog. As expected, Human answerer generates higher quality answers resulting in lower ATR. (p. 10)
