Face and Body Paper (Oral) in CVPR 2019
[tracking face cvpr body High-Quality Face Capture Using Anatomical Muscles

Abstract: Muscle-based systems have the potential to provide both anatomical accuracy and semantic interpretability as compared to blendshape models; however, a lack of expressivity and differentiability has limited their impact. Thus, we propose modifying a recently developed rather expressive muscle-based system in order to make it fully-differentiable; in fact, our proposed modifications allow this physically robust and anatomically accurate muscle model to conveniently be driven by an underlying blendshape basis. Our formulation is intuitive, natural, as well as monolithically and fully coupled such that one can differentiate the model from end to end, which makes it viable for both optimization and learning-based approaches for a variety of applications. We illustrate this with a number of examples including both shape matching of three-dimensional geometry as as well as the automatic determination of a three-dimensional facial pose from a single two-dimensional RGB image without using markers or depth information.
FML: Face Model Learning From Videos

Abstract: Monocular image-based 3D reconstruction of faces is a long-standing problem in computer vision. Since image data is a 2D projection of a 3D face, the resulting depth ambiguity makes the problem ill-posed. Most existing methods rely on data-driven priors that are built from limited 3D face scans. In contrast, we propose multi-frame video-based self-supervised training of a deep network that (i) learns a face identity model both in shape and appearance while (ii) jointly learning to reconstruct 3D faces. Our face model is learned using only corpora of in-the-wild video clips collected from the Internet. This virtually endless source of training data enables learning of a highly general 3D face model. In order to achieve this, we propose a novel multi-frame consistency loss that ensures consistent shape and appearance across multiple frames of a subject’s face, thus minimizing depth ambiguity. At test time we can use an arbitrary number of frames, so that we can perform both monocular as well as multi-frame reconstruction.
AdaCos: Adaptively Scaling Cosine Logits for Effectively Learning Deep Face Representations

Abstract: The cosine-based softmax losses and their variants achieve great success in deep learning based face recognition. However, hyperparameter settings in these losses have significant influences on the optimization path as well as the final recognition performance. Manually tuning those hyperparameters heavily relies on user experience and requires many training tricks. In this paper, we investigate in depth the effects of two important hyperparameters of cosine-based softmax losses, the scale parameter and angular margin parameter, by analyzing how they modulate the predicted classification probability. Based on these analysis, **we propose a novel cosine-based softmax loss, AdaCos, which is hyperparameter-free and leverages an adaptive scale parameter to automatically strengthen the training supervisions during the training process. **We apply the proposed AdaCos loss to large-scale face verification and identification datasets, including LFW, MegaFace, and IJB-C 1:1 Verification. Our results show that training deep neural networks with the AdaCos loss is stable and able to achieve high face recognition accuracy. Our method outperforms state-of-the-art softmax losses on all the three datasets.
3D Hand Shape and Pose Estimation From a Single RGB Image
[Image: Screen Shot 2019-06-13 at 6.29.25 PM.png]Abstract: **This work addresses a novel and challenging problem of estimating the full 3D hand shape and pose from a single RGB image. Most current methods in 3D hand analysis from monocular RGB images only focus on estimating the 3D locations of hand keypoints, which cannot fully express the 3D shape of hand. In contrast, **we propose a Graph Convolutional Neural Network (Graph CNN) based method to reconstruct a full 3D mesh of hand surface that contains richer information of both 3D hand shape and pose. To train networks with full supervision, we create a large-scale synthetic dataset containing both ground truth 3D meshes and 3D poses. When fine-tuning the networks on real-world datasets without 3D ground truth, we propose a weakly-supervised approach by leveraging the depth map as a weak supervision in training. Through extensive evaluations on our proposed new datasets and two public datasets, we show that our proposed method can produce accurate and reasonable 3D hand mesh, and can achieve superior 3D hand pose estimation accuracy when compared with state-of-the-art methods.
Very interesting work and wanna take a trial.
3D Hand Shape and Pose From Images in the Wild, Adnane Boukhayma

Abstract: We present in this work the first end-to-end deep learning based method that predicts both 3D hand shape and pose from RGB images in the wild. Our network consists of the concatenation of a deep convolutional encoder, and a fixed model-based decoder. Given an input image, and optionally 2D joint detections obtained from an independent CNN, the encoder predicts a set of hand and view parameters. The decoder has two components: A pre-computed articulated mesh deformation hand model that generates a 3D mesh from the hand parameters, and a re-projection module controlled by the view parameters that projects the generated hand into the image domain. **We show that using the shape and pose prior knowledge encoded in the hand model within a deep learning framework yields state-of-the-art performance in 3D pose prediction from images on standard benchmarks, and produces geometrically valid and plausible 3D reconstructions. Additionally, **we show that training with weak supervision in the form of 2D joint annotations on datasets of images in the wild, in conjunction with full supervision in the form of 3D joint annotations on limited available datasets allows for good generalization to 3D shape and pose predictions on images in the wild.
Self-Supervised 3D Hand Pose Estimation Through Training by Fitting
Abstract: We present a self-supervision method for 3D hand pose estimation from depth maps. We begin with a neural network initialized with synthesized data and fine-tune it on real but unlabelled depth maps by minimizing a set of data fitting terms. By approximating the hand surface with a set of spheres, we design a differentiable hand renderer to align estimates by comparing the rendered and input depth maps. In addition, we place a set of priors including a data-driven term to further regulate the estimate’s kinematic feasibility. Our method makes highly accurate estimates comparable to current supervised methods which require large amounts of labelled training samples, thereby advancing state-of-the art in unsupervised learning for hand pose estimation.
CrowdPose: Efficient Crowded Scenes Pose Estimation and a New Benchmark

Abstract: Multi-person pose estimation is fundamental to many computer vision tasks and has made significant progress in recent years. However, few previous methods explored the problem of pose estimation in crowded scenes while it remains challenging and inevitable in many scenarios. Moreover, current benchmarks cannot provide an appropriate evaluation for such cases. In this paper, we propose a novel and efficient method to tackle the problem of pose estimation in the crowd and a new dataset to better evaluate algorithms. Our model consists of two key components: joint-candidate single person pose estimation (SPPE) and global maximum joints association. With multi-peak prediction for each joint and global association using graph model, our method is robust to inevitable interference in crowded scenes and very efficient in inference. The proposed method surpasses the state-of-the-art methods on CrowdPose dataset by 5.2 mAP and results on MSCOCO dataset demonstrate the generalization ability of our method. Source code and dataset will be made publicly available.
Towards Social Artificial Intelligence: Nonverbal Social Signal Prediction in a Triadic Interaction
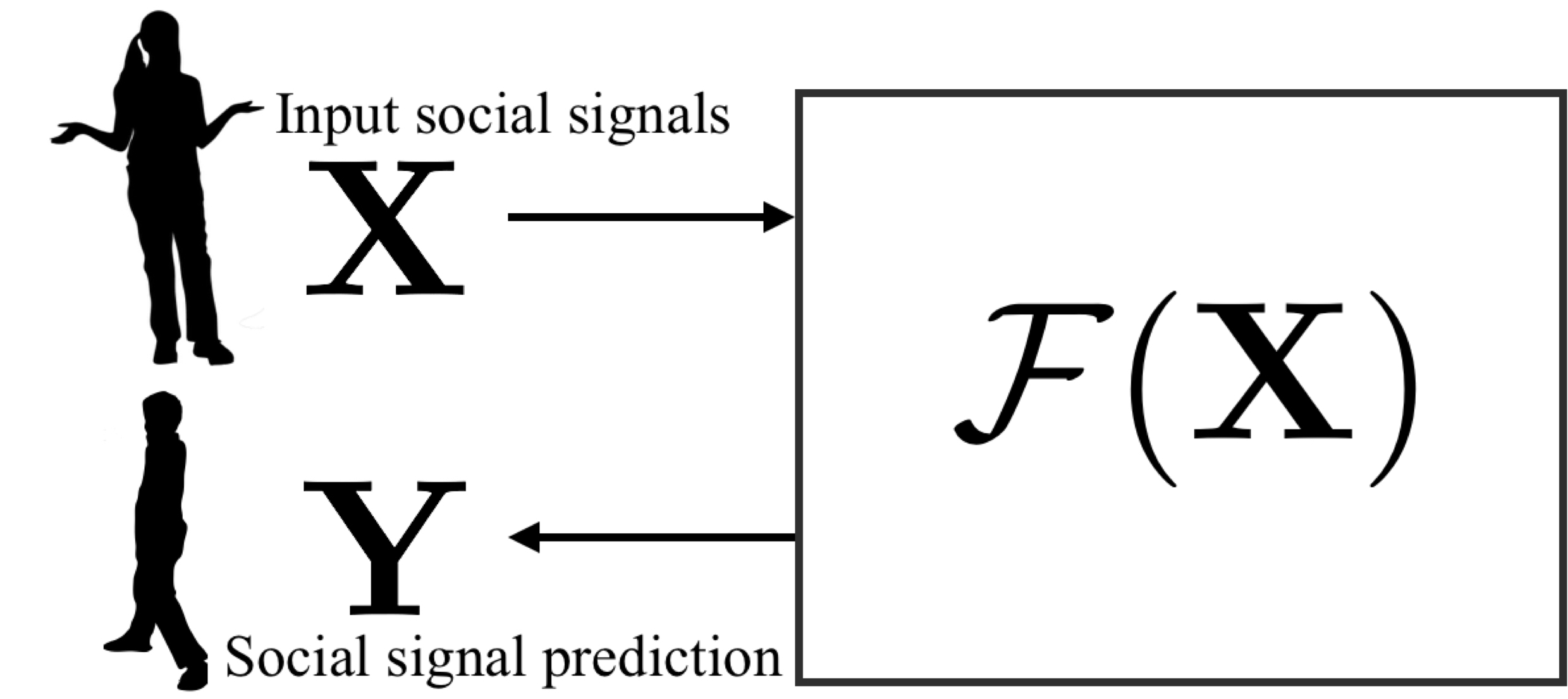
Abstract: We present a new research task and a dataset to understand human social interactions via computational methods, to ultimately endow machines with the ability to encode and decode a broad channel of social signals humans use. This research direction is essential to make a machine that genuinely communicates with humans, which we call Social Artificial Intelligence. We first formulate the “social signal prediction” problem as a way to model the dynamics of social signals exchanged among interacting individuals in a data-driven way. We then present a new 3D motion capture dataset to explore this problem, where the broad spectrum of social signals (3D body, face, and hand motions) are captured in a triadic social interaction scenario. Baseline approaches to predict speaking status, social formation, and body gestures of interacting individuals are presented in the defined social prediction framework.
HoloPose: Holistic 3D Human Reconstruction In-The-Wild
Abstract: We introduce HoloPose, a method for holistic monocular 3D human body reconstruction. We first introduce a part-based model for 3D model parameter regression that allows our method to operate in-the-wild, gracefully handling severe occlusions and large pose variation. We further train a multi-task network comprising 2D, 3D and Dense Pose estimation to drive the 3D reconstruction task. For this we introduce an iterative refinement method that aligns the model-based 3D estimates of 2D/3D joint positions and DensePose with their image-based counterparts delivered by CNNs, achieving both model-based, global consistency and high spatial accuracy thanks to the bottom-up CNN processing. We validate our contributions on challenging benchmarks, showing that our method allows us to get both accurate joint and 3D surface estimates, while operating at more than 10fps in-the-wild. More information about our approach, including videos and demos is available at http://arielai.com/holopose.
Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation
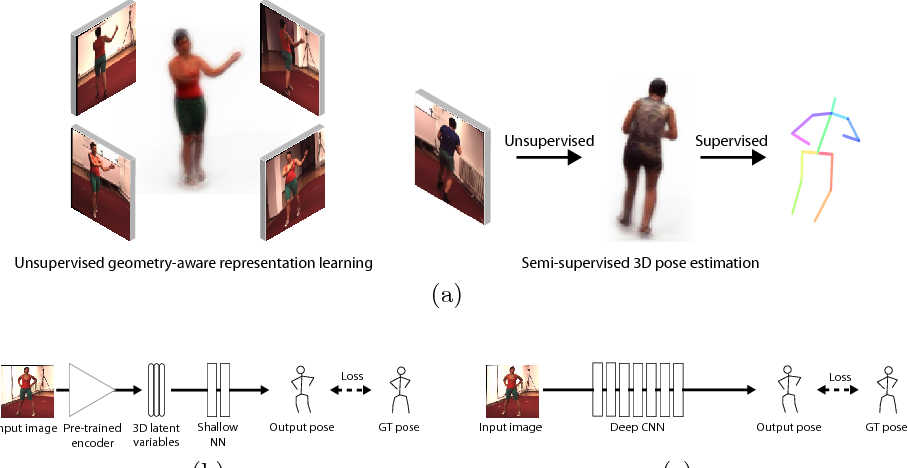
Abstract: Recent studies have shown remarkable advances in 3D human pose estimation from monocular images, with the help of large-scale in-door 3D datasets and sophisticated network architectures. However, the generalizability to different environments remains an elusive goal. In this work, we propose a geometry-aware 3D representation for the human pose to address this limitation by using multiple views in a simple auto-encoder model at the training stage and only 2D keypoint information as supervision. A view synthesis framework is proposed to learn the shared 3D representation between viewpoints with synthesizing the human pose from one viewpoint to the other one. Instead of performing a direct transfer in the raw image-level, we propose a skeleton-based encoder-decoder mechanism to distil only pose-related representation in the latent space. A learning-based representation consistency constraint is further introduced to facilitate the robustness of latent 3D representation. Since the learnt representation encodes 3D geometry information, mapping it to 3D pose will be much easier than conventional frameworks that use an image or 2D coordinates as the input of 3D pose estimator. We demonstrate our approach on the task of 3D human pose estimation. Comprehensive experiments on three popular benchmarks show that our model can significantly improve the performance of state-of-the-art methods with simply injecting the representation as a robust 3D prior.
In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations
Abstract: Convolutional Neural Network based approaches for monocular 3D human pose estimation usually require a large amount of training images with 3D pose annotations. While it is feasible to provide 2D joint annotations for large corpora of in-the-wild images with humans, providing accurate 3D annotations to such in-the-wild corpora is hardly feasible in practice. Most existing 3D labelled data sets are either synthetically created or feature in-studio images. 3D pose estimation algorithms trained on such data often have limited ability to generalize to real world scene diversity. We therefore propose a new deep learning based method for monocular 3D human pose estimation that shows high accuracy and generalizes better to in-the-wild scenes. **It has a network architecture that comprises a new disentangled hidden space encoding of explicit 2D and 3D features, and uses supervision by a new learned projection model from predicted 3D pose. **Our algorithm can be jointly trained on image data with 3D labels and image data with only 2D labels. It achieves state-of-the-art accuracy on challenging in-the-wild data.
Slim DensePose: Thrifty Learning From Sparse Annotations and Motion Cues

Abstract: DensePose supersedes traditional landmark detectors by densely mapping image pixels to body surface coordinates. This power, however, comes at a greatly increased annotation time, as supervising the model requires to manually label hundreds of points per pose instance. In this work, we thus seek methods to significantly slim down the DensePose annotations, proposing more efficient data collection strategies. In particular, we demonstrate that if annotations are collected in video frames, their efficacy can be multiplied for free by using motion cues. To explore this idea, we introduce DensePose-Track, a dataset of videos where selected frames are annotated in the traditional DensePose manner. Then, building on geometric properties of the DensePose mapping, we use the video dynamic to propagate ground-truth annotations in time as well as to learn from Siamese equivariance constraints. Having performed exhaustive empirical evaluation of various data annotation and learning strategies, we demonstrate that doing so can deliver significantly improved pose estimation results over strong baselines. However, despite what is suggested by some recent works, we show that merely synthesizing motion patterns by applying geometric transformations to isolated frames is significantly less effective, and that motion cues help much more when they are extracted from videos.
Self-Supervised Representation Learning From Videos for Facial Action Unit Detection
Abstract: In this paper, we aim to learn discriminative representation for facial action unit (AU) detection from large amount of videos without manual annotations. Inspired by the fact that facial actions are the movements of facial muscles, we depict the movements as the transformation between two face images in different frames and use it as the self-supervisory signal to learn the representations. However, under the uncontrolled condition, the transformation is caused by both facial actions and head motions. **To remove the influence by head motions, we propose a TwinCycle Autoencoder (TCAE) that can disentangle the facial action related movements and the head motion related ones. **Specifically, TCAE is trained to respectively change the facial actions and head poses of the source face to those of the target face. Our experiments validate TCAE’s capability of decoupling the movements. Experimental results also demonstrate that the learned representation is discriminative for AU detection, where TCAE outperforms or is comparable with the state-of-the-art self-supervised learning methods and supervised AU detection methods.
Combining 3D Morphable Models: A Large Scale FaceAnd-Head Model

Abstract: Three-dimensional Morphable Models (3DMMs) are powerful statistical tools for representing the 3D surfaces of an object class. In this context, we identify an interesting question that has previously not received research attention: is it possible to combine two or more 3DMMs that (a) are built using different templates that perhaps only partly overlap, (b) have different representation capabilities and (c) are built from different datasets that may not be publicly available? In answering this question, we make two contributions. First, we propose two methods for solving this problem: i. use a regressor to complete missing parts of one model using the other, ii. use the Gaussian Process framework to blend covariance matrices from multiple models. Second, as an example application of our approach, we build a new face-and-head shape model that combines the variability and facial detail of the LSFM with the full head modelling of the LYHM. The resulting combined shape model achieves state-of-the-art performance and outperforms existing head models by a large margin. Finally, as an application experiment, we reconstruct full head representations from single, unconstrained images by utilizing our proposed large-scale model in conjunction with the FaceWarehouse blend shapes for handling expressions.
Boosting Local Shape Matching for Dense 3D Face Correspondence
Abstract: Dense 3D face correspondence is a fundamental and challenging issue in the literature of 3D face analysis. Correspondence between two 3D faces can be viewed as a nonrigid registration problem that one deforms into the other, which is commonly guided by a few facial landmarks in many existing works. However, the current works seldom consider the problem of incoherent deformation caused by landmarks. In this paper, we explicitly formulate the deformation as locally rigid motions guided by some seed points, and the formulated deformation satisfies coherent local motions everywhere on a face. The seed points are initialized by a few landmarks, and are then augmented to boost shape matching between the template and the target face step by step, to finally achieve dense correspondence. In each step, we employ a hierarchical scheme for local shape registration, together with a Gaussian reweighting strategy for accurate matching of local features around the seed points. In our experiments, we evaluate the proposed method extensively on several datasets, including two publicly available ones: FRGC v2.0 and BU-3DFE. The experimental results demonstrate that our method can achieve accurate feature correspondence, coherent local shape motion, and compact data representation. These merits actually settle some important issues for practical applications, such as expressions, noise, and partial data.
Unsupervised Part-Based Disentangling of Object Shape and Appearance
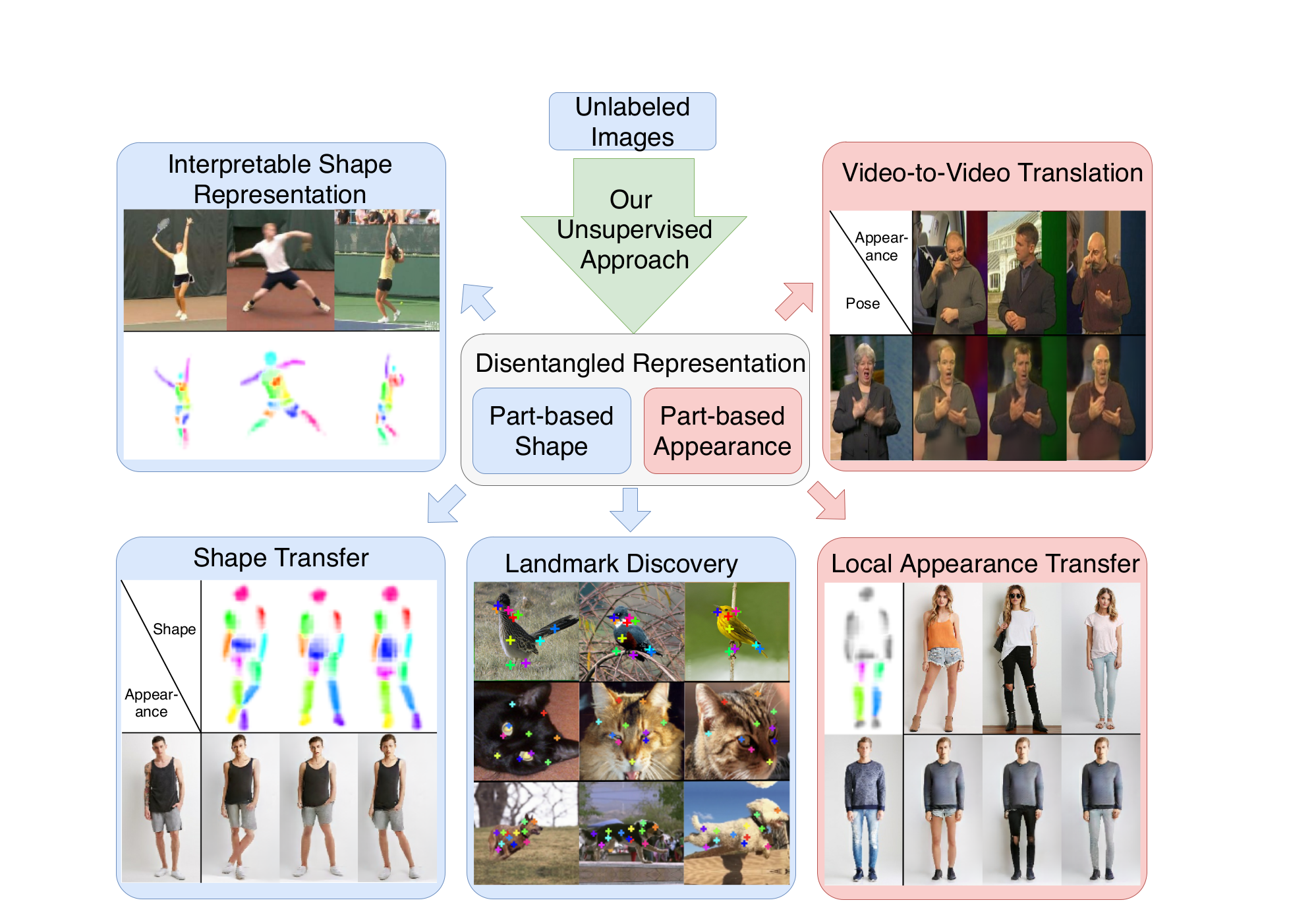
Abstract: Large intra-class variation is the result of changes in multiple object characteristics. Images, however, only show the superposition of different variable factors such as appearance or shape. Therefore, learning to disentangle and represent these different characteristics poses a great challenge, especially in the unsupervised case. Moreover, large object articulation calls for a flexible part-based model. We present an unsupervised approach for disentangling appearance and shape by learning parts consistently over all instances of a category. Our model for learning an object representation is trained by simultaneously **exploiting invariance and equivariance constraints between synthetically transformed images. **Since no part annotation or prior information on an object class is required, the approach is applicable to arbitrary classes. We evaluate our approach on a wide range of object categories and diverse tasks including pose prediction, disentangled image synthesis, and video-to-video translation. The approach outperforms the state-of-the-art on unsupervised keypoint prediction and compares favorably even against supervised approaches on the task of shape and appearance transfer.
Monocular Total Capture: Posing Face, Body, and Hands in the Wild

Abstract: We present the first method to capture the 3D total motion of a target person from a monocular view input. Given an image or a monocular video, our method reconstructs the motion from body, face, and fingers represented by a 3D deformable mesh model. We use an efficient representation called 3D Part Orientation Fields (POFs), to encode the 3D orientations of all body parts in the common 2D image space. POFs are predicted by a Fully Convolutional Network (FCN), along with the joint confidence maps. To train our network, we collect a new 3D human motion dataset capturing diverse total body motion of 40 subjects in a multiview system. We leverage a 3D deformable human model to reconstruct total body pose from the CNN outputs by exploiting the pose and shape prior in the model. We also present a texture-based tracking method to obtain temporally coherent motion capture output. We perform thorough quantitative evaluations including comparison with the existing body-specific and hand-specific methods, and performance analysis on camera viewpoint and human pose changes. Finally, we demonstrate the results of our total body motion capture on various challenging in-the-wild videos. Our code and newly collected human motion dataset will be publicly shared.
Expressive Body Capture: 3D Hands, Face, and Body From a Single Image

Abstract: To facilitate the analysis of human actions, interactions and emotions, we compute a 3D model of human body pose, hand pose, and facial expression from a single monocular image. To achieve this, we use thousands of 3D scans to train a new, unified, 3D model of the human body, SMPL-X, that extends SMPL with fully articulated hands and an expressive face. Learning to regress the parameters of SMPL-X directly from images is challenging without paired images and 3D ground truth. Consequently,** we follow the approach of SMPLify, which estimates 2D features and then optimizes model parameters to fit the features. We improve on SMPLify in several significant ways: (1) we detect 2D features corresponding to the face, hands, and feet and fit the full SMPL-X model to these; (2) **we train a new neural network pose prior using a large MoCap dataset; (3) we define a new interpenetration penalty that is both fast and accurate; (4) we automatically detect gender and the appropriate body models (male, female, or neutral); (5) our PyTorch implementation achieves a speedup of more than 8x over Chumpy. We use the new method, SMPLify-X, to fit SMPL-X to both controlled images and images in the wild. We evaluate 3D accuracy on a new curated dataset comprising 100 images with pseudo ground-truth. This is a step towards automatic expressive human capture from monocular RGB data. The models, code, and data are available for research purposes at https://smpl-x.is.tue.mpg.de.