Object Detection Paper (Oral) in CVPR 2019
[cvpr object-detection Bi-Directional Cascade Network for Perceptual Edge Detection
)
Abstract: Exploiting multi-scale representations is critical to improve edge detection for objects at different scales. To extract edges at dramatically different scales, we propose a Bi-Directional Cascade Network (BDCN) structure, where an individual layer is supervised by labeled edges at its specific scale, rather than directly applying the same supervision to all CNN outputs. Furthermore, to enrich multi-scale representations learned by BDCN, we introduce a Scale Enhancement Module (SEM) which utilizes dilated convolution to generate multi-scale features, instead of using deeper CNNs or explicitly fusing multi-scale edgemaps. These new approaches encourage the learning of multi-scale representations in different layers and detect edges that are well delineated by their scales. Learning scale dedicated layers also results in compact network with a fraction of parameters. We evaluate our method on three datasets, i.e., BSDS500, NYUDv2, and Multicue, and achieve ODS Fmeasure of 0.828, 1.3% higher than current state-of-the art on BSDS500. The code has been available at https://github.com/pkuCactus/BDCN.
Feature Selective Anchor-Free Module for Single-Shot Object Detection

Abstract: We motivate and present feature selective anchor-free (FSAF) module, a simple and effective building block for single-shot object detectors. It can be plugged into single-shot detectors with feature pyramid structure. The FSAF module addresses two limitations brought up by the conventional anchor-based detection: 1) heuristic-guided feature selection; 2) overlap-based anchor sampling. The general concept of the FSAF module is online feature selection applied to the training of multi-level anchor-free branches. Specifically, an anchor-free branch is attached to each level of the feature pyramid, allowing box encoding and decoding in the anchor-free manner at an arbitrary level. During training, we dynamically assign each instance to the most suitable feature level. At the time of inference, the FSAF module can work jointly with anchor-based branches by outputting predictions in parallel. We instantiate this concept with simple implementations of anchor-free branches and online feature selection strategy. Experimental results on the COCO detection track show that our FSAF module performs better than anchor-based counterparts while being faster. When working jointly with anchor-based branches, the FSAF module robustly improves the baseline RetinaNet by a large margin under various settings, while introducing nearly free inference overhead. And the resulting best model can achieve a state-of-the-art 44.6% mAP, outperforming all existing single-shot detectors on COCO.
Region Proposal by Guided Anchoring

Abstract: Region anchors are the cornerstone of modern object detection techniques. State-of-the-art detectors mostly rely on a dense anchoring scheme, where anchors are sampled uniformly over the spatial domain with a predefined set of scales and aspect ratios. In this paper, we revisit this foundational stage. Our study shows that it can be done much more effectively and efficiently. Specifically, we present an alternative scheme, named Guided Anchoring, which leverages semantic features to guide the anchoring. The proposed method jointly predicts the locations where the center of objects of interest are likely to exist as well as the scales and aspect ratios at different locations. On top of predicted anchor shapes, we mitigate the feature inconsistency with a feature adaption module. We also study the use of high-quality proposals to improve detection performance. The anchoring scheme can be seamlessly integrated into proposal methods and detectors. With Guided Anchoring, we achieve 9.1% higher recall on MS COCO with 90% fewer anchors than the RPN baseline. We also adopt Guided Anchoring in Fast R-CNN, Faster R-CNN and RetinaNet, respectively improving the detection mAP by 2.2%, 2.7% and 1.2%. Code will be available at https://github.com/open-mmlab/mmdetection.
Bottom-up Object Detection by Grouping Extreme and Center Points

Abstract: With the advent of deep learning, object detection drifted from a bottom-up to a top-down recognition problem. State of the art algorithms enumerate a near-exhaustive list of object locations and classify each into: object or not. In this paper, we show that bottom-up approaches still perform competitively. We detect four extreme points (top-most, left-most, bottom-most, right-most) and one center point of objects using a standard keypoint estimation network. We group the five keypoints into a bounding box if they are geometrically aligned. Object detection is then a purely appearance-based keypoint estimation problem, without region classification or implicit feature learning. The proposed method performs on-par with the state-of-the-art region based detection methods, with a bounding box AP of 43.2% on COCO test-dev. In addition, our estimated extreme points directly span a coarse octagonal mask, with a COCO Mask AP of 18.9%, much better than the Mask AP of vanilla bounding boxes. Extreme point guided segmentation further improves this to 34.6% Mask AP.
Generalized Intersection over Union A Metric and A Loss for Bounding Box Regression
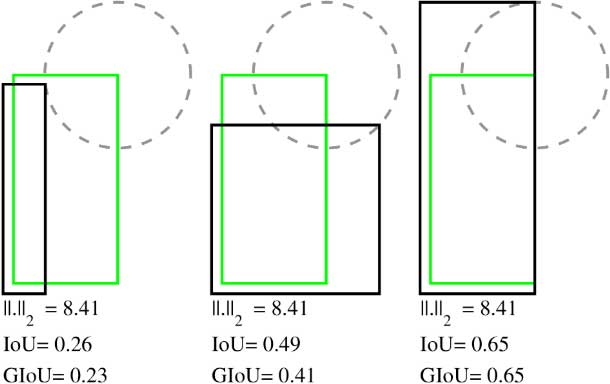
Abstract: Intersection over Union (IoU) is the most popular evaluation metric used in the object detection benchmarks. However, there is a gap between optimizing the commonly used distance losses for regressing the parameters of a bounding box and maximizing this metric value. The optimal objective for a metric is the metric itself. In the case of axis-aligned 2D bounding boxes, it can be shown that IoU can be directly used as a regression loss. However, IoU has a plateau making it infeasible to optimize in the case of non-overlapping bounding boxes. In this paper, we address the weaknesses of IoU by introducing a generalized version as both a new loss and a new metric. By incorporating this generalized IoU (GIoU) as a loss into the state-of-the art object detection frameworks, we show a consistent improvement on their performance using both the standard, IoU based, and new, GIoU based, performance measures on popular object detection benchmarks such as PASCAL VOC and MS COCO.
RepMet- Representative-based metric learning for classification and one-shot object detection

Abstract: Distance metric learning (DML) has been successfully applied to object classification, both in the standard regime of rich training data and in the few-shot scenario, where each category is represented by only a few examples. In this work, we propose a new method for DML that simultaneously learns the backbone network parameters, the embedding space, and the multi-modal distribution of each of the training categories in that space, in a single end-to-end training process. Our approach outperforms state-of-the-art methods for DML-based object classification on a variety of standard fine-grained datasets. Furthermore, we demonstrate the effectiveness of our approach on the problem of few-shot object detection, by incorporating the proposed DML architecture as a classification head into a standard object detection model. We achieve the best results on the ImageNet-LOC dataset compared to strong baselines, when only a few training examples are available. We also offer the community a new episodic benchmark based on the ImageNet dataset for the few-shot object detection task.
COIN- A Large-scale Dataset for Comprehensive Instructional Video Analysis

Abstract: There are substantial instructional videos on the Internet, which enables us to acquire knowledge for completing various tasks. However, most existing datasets for instructional video analysis have the limitations in diversity and scale, which makes them far from many real-world applications where more diverse activities occur. Moreover, it still remains a great challenge to organize and harness such data. To address these problems, we introduce a large-scale dataset called “COIN” for COmprehensive INstructional video analysis. Organized with a hierarchical structure, the COIN dataset contains 11,827 videos of 180 tasks in 12 domains (e.g., vehicles, gadgets, etc.) related to our daily life. With a new developed toolbox, all the videos are annotated effectively with a series of step descriptions and the corresponding temporal boundaries. Furthermore, we propose a simple yet effective method to capture the dependencies among different steps, which can be easily plugged into conventional proposal-based action detection methods for localizing important steps in instructional videos. In order to provide a benchmark for instructional video analysis, we evaluate plenty of approaches on the COIN dataset under different evaluation criteria. We expect the introduction of the COIN dataset will promote the future in-depth research on instructional video analysis for the community.
Gradient Harmonized Single-stage Detector

Abstract: Despite the great success of two-stage detectors, single-stage detector is still a more elegant and efficient way, yet suffers from the two well-known disharmonies during training, i.e. the huge difference in quantity between positive and negative examples as well as between easy and hard examples. In this work, we first point out that the essential effect of the two disharmonies can be summarized in term of the gradient. Further, we propose a novel gradient harmonizing mechanism (GHM) to be a hedging for the disharmonies. The philosophy behind GHM can be easily embedded into both classification loss function like cross-entropy (CE) and regression loss function like smooth-L1 (SL1) loss. To this end, two novel loss functions called GHM-C and GHM-R are designed to balancing the gradient flow for anchor classification and bounding box refinement, respectively. Ablation study on MS COCO demonstrates that without laborious hyper-parameter tuning, both GHM-C and GHM-R can bring substantial improvement for single-stage detector. Without any whistles and bells, our model achieves 41.6 mAP on COCO test-dev set which surpasses the state-of-the-art method, Focal Loss (FL) + SL1, by 0.8.
Scale-Aware Trident Networks for Object Detection

Abstract: Scale variation is one of the key challenges in object detection. In this work, we first present a controlled experiment to investigate the effect of receptive fields on the detection of different scale objects. Based on the findings from the exploration experiments, we propose a novel Trident Network (TridentNet) aiming to generate scale-specific feature maps with a uniform representational power. We construct a parallel multi-branch architecture in which each branch shares the same transformation parameters but with different receptive fields. Then, we propose a scale-aware training scheme to specialize each branch by sampling object instances of proper scales for training. As a bonus, a fast approximation version of TridentNet could achieve significant improvements without any additional parameters and computational cost. On the COCO dataset, our TridentNet with ResNet-101 backbone achieves state-of-the-art single-model results by obtaining an mAP of 48.4. Code will be made publicly available.
CenterNet- Keypoint Triplets for Object Detection
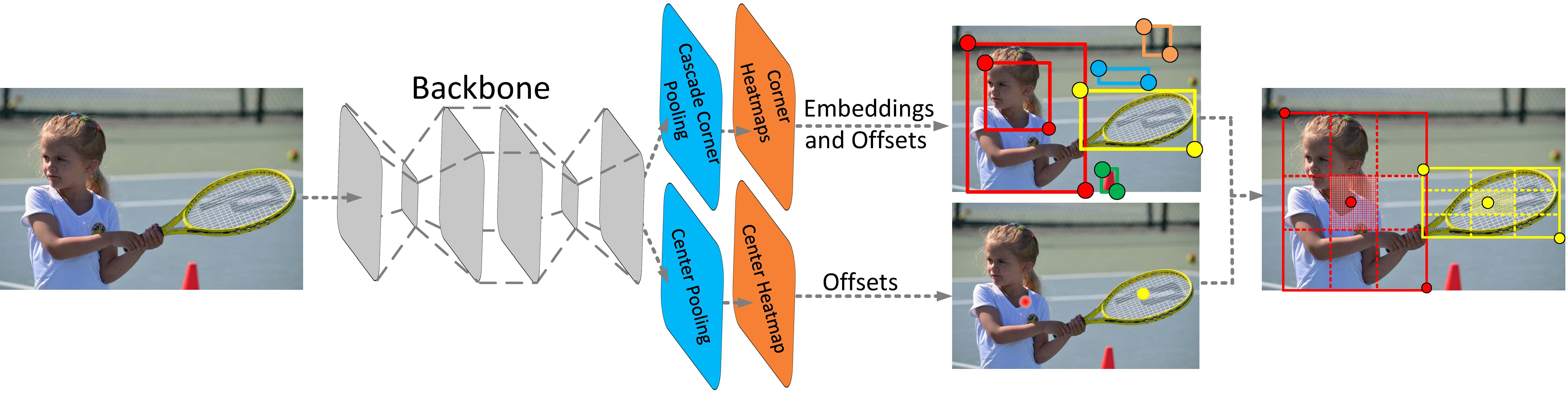
Abstract: In object detection, keypoint-based approaches often suffer a large number of incorrect object bounding boxes, arguably due to the lack of an additional look into the cropped regions. This paper presents an efficient solution which explores the visual patterns within each cropped region with minimal costs. We build our framework upon a representative one-stage keypoint-based detector named CornerNet. Our approach, named CenterNet, detects each object as a triplet, rather than a pair, of keypoints, which improves both precision and recall. Accordingly, we design two customized modules named **cascade corner pooling and center pooling, which play the roles of enriching information collected by both top-left and bottom-right corners **and providing more recognizable information at the central regions, respectively. On the MS-COCO dataset, CenterNet achieves an AP of 47.0%, which outperforms all existing one-stage detectors by at least 4.9%. Meanwhile, with a faster inference speed, CenterNet demonstrates quite comparable performance to the top-ranked two-stage detectors. Code is available at https://github.com/Duankaiwen/CenterNet.
Each object is represented by a triplet: one center point and two corner points, where the corner pair defines the location and shape of the bounding box; and the center point defines the objectiveness of the bounding box.
Less is More- An Exploration of Data Redundancy with Active Dataset Subsampling

Abstract: Deep Neural Networks (DNNs) often rely on very large datasets for training. Given the large size of such datasets, it is conceivable that they contain certain samples that either do not contribute or negatively impact the DNN’s performance. If there is a large number of such samples, subsampling the training dataset in a way that removes them could provide an effective solution to both improve performance and reduce training time. In this paper, we propose an approach called Active Dataset Subsampling (ADS), to identify favorable subsets within a dataset for training using ensemble based uncertainty estimation. When applied to three image classification benchmarks (CIFAR-10, CIFAR-100 and ImageNet) we find that there are low uncertainty subsets, which can be as large as 50% of the full dataset, that negatively impact performance. These subsets are identified and removed with ADS. We demonstrate that datasets obtained using ADS with a lightweight ResNet-18 ensemble remain effective when used to train deeper models like ResNet-101. Our results provide strong empirical evidence that using all the available data for training can hurt performance on large scale vision tasks.
The experiment result on ImageNet indicates there is not that much redundancy there, as the whole training set of ImageNet is 1M. So this paper may not be very useful in practice.
ScratchDet- Training Single-Shot Object Detectors from Scratch

Abstract: Current state-of-the-art object objectors are fine-tuned from the off-the-shelf networks pretrained on large-scale classification dataset ImageNet, which incurs some additional problems: 1) The classification and detection have different degrees of sensitivity to translation, resulting in the learning objective bias; 2) The architecture is limited by the classification network, leading to the inconvenience of modification. To cope with these problems, training detectors from scratch is a feasible solution. However, the detectors trained from scratch generally perform worse than the pretrained ones, even suffer from the convergence issue in training. In this paper, we explore to train object detectors from scratch robustly. By analysing the previous work on optimization landscape, we find that one of the overlooked points in current trained-from-scratch detector is the BatchNorm. Resorting to the stable and predictable gradient brought by BatchNorm, detectors can be trained from scratch stably while keeping the favourable performance independent to the network architecture. Taking this advantage, we are able to explore various types of networks for object detection, without suffering from the poor convergence. By extensive experiments and analyses on downsampling factor, we propose the Root-ResNet backbone network, which makes full use of the information from original images. Our ScratchDet achieves the state-of-the-art accuracy on PASCAL VOC 2007, 2012 and MS COCO among all the train-from-scratch detectors and even performs better than several one-stage pretrained methods. Codes will be made publicly available at https://github.com/KimSoybean/ScratchDet.
CornerNet- Detecting Objects as Paired Keypoints

Abstract: We propose CornerNet, a new approach to object detection where we detect an object bounding box as a pair of keypoints, the top-left corner and the bottom-right corner, using a single convolution neural network. By detecting objects as paired keypoints, we eliminate the need for designing a set of anchor boxes commonly used in prior single-stage detectors. In addition to our novel formulation, we introduce corner pooling, a new type of pooling layer that helps the network better localize corners. Experiments show that CornerNet achieves a 42.2% AP on MS COCO, outperforming all existing one-stage detectors.
Libra R-CNN- Towards Balanced Learning for Object Detection

Abstract: Compared with model architectures, the training process, which is also crucial to the success of detectors, has received relatively less attention in object detection. In this work, we carefully revisit the standard training practice of detectors, and find that the detection performance is often limited by the imbalance during the training process, which generally consists in three levels - sample level, feature level, and objective level. To mitigate the adverse effects caused thereby, we propose Libra R-CNN, a simple but effective framework towards balanced learning for object detection. It integrates three novel components: IoU-balanced sampling, balanced feature pyramid, and balanced L1 loss, respectively for reducing the imbalance at sample, feature, and objective level. Benefitted from the overall balanced design, Libra R-CNN significantly improves the detection performance. Without bells and whistles, it achieves 2.5 points and 2.0 points higher Average Precision (AP) than FPN Faster R-CNN and RetinaNet respectively on MSCOCO.
SimpleDet- A Simple and Versatile Distributed Framework for Object Detection and Instance Recognition
Abstract: Object detection and instance recognition play a central role in many AI applications like autonomous driving, video surveillance and medical image analysis. However, training object detection models on large scale datasets remains computationally expensive and time consuming. This paper presents an efficient and open source object detection framework called SimpleDet which enables the training of state-of-the-art detection models on consumer grade hardware at large scale. SimpleDet supports up-to-date detection models with best practice. SimpleDet also supports distributed training with near linear scaling out of box. Codes, examples and documents of SimpleDet can be found at https://github.com/tusimple/simpledet
CornerNet-Lite- Efficient Keypoint Based Object Detection

Abstract: Keypoint-based methods are a relatively new paradigm in object detection, eliminating the need for anchor boxes and offering a simplified detection framework. Keypoint-based CornerNet achieves state of the art accuracy among single-stage detectors. However, this accuracy comes at high processing cost. In this work, we tackle the problem of efficient keypoint-based object detection and introduce CornerNet-Lite. CornerNet-Lite is a combination of two efficient variants of CornerNet: CornerNet-Saccade, which uses an attention mechanism to eliminate the need for exhaustively processing all pixels of the image, and **CornerNet-Squeeze, which introduces a new compact backbone architecture. **Together these two variants address the two critical use cases in efficient object detection: improving efficiency without sacrificing accuracy, and improving accuracy at real-time efficiency. CornerNet-Saccade is suitable for offline processing, improving the efficiency of CornerNet by 6.0x and the AP by 1.0% on COCO. CornerNet-Squeeze is suitable for real-time detection, improving both the efficiency and accuracy of the popular real-time detector YOLOv3 (34.4% AP at 34ms for CornerNet-Squeeze compared to 33.0% AP at 39ms for YOLOv3 on COCO). Together these contributions for the first time reveal the potential of keypoint-based detection to be useful for applications requiring processing efficiency.
M2Det- A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network

Abstract: Feature pyramids are widely exploited by both the state-of-the-art one-stage object detectors (e.g., DSSD, RetinaNet, RefineDet) and the two-stage object detectors (e.g., Mask R-CNN, DetNet) to alleviate the problem arising from scale variation across object instances. Although these object detectors with feature pyramids achieve encouraging results, they have some limitations due to that they only simply construct the feature pyramid according to the inherent multi-scale, pyramidal architecture of the backbones which are actually designed for object classification task. Newly, in this work, we present a method called Multi-Level Feature Pyramid Network (MLFPN) to construct more effective feature pyramids for detecting objects of different scales. First, we fuse multi-level features (i.e. multiple layers) extracted by backbone as the base feature. Second, we feed the base feature into a block of alternating joint Thinned U-shape Modules and Feature Fusion Modules and exploit the decoder layers of each u-shape module as the features for detecting objects. Finally, we gather up the decoder layers with equivalent scales (sizes) to develop a feature pyramid for object detection, in which every feature map consists of the layers (features) from multiple levels. To evaluate the effectiveness of the proposed MLFPN, we design and train a powerful end-to-end one-stage object detector we call M2Det by integrating it into the architecture of SSD, which gets better detection performance than state-of-the-art one-stage detectors. Specifically, on MS-COCO benchmark, M2Det achieves AP of 41.0 at speed of 11.8 FPS with single-scale inference strategy and AP of 44.2 with multi-scale inference strategy, which is the new state-of-the-art results among one-stage detectors. The code will be made available on \url{https://github.com/qijiezhao/M2Det.
bounding box regression with uncertainty for accurate object detection
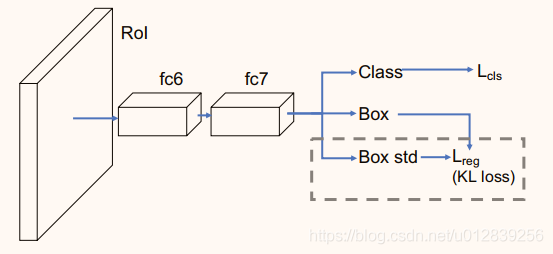
Abstract: Large-scale object detection datasets (e.g., MS-COCO) try to define the ground truth bounding boxes as clear as possible. However, we observe that ambiguities are still introduced when labeling the bounding boxes. In this paper, we propose a novel bounding box regression loss for learning bounding box transformation and localization variance together. Our loss greatly improves the localization accuracies of various architectures with nearly no additional computation. The learned localization variance allows us to merge neighboring bounding boxes during non-maximum suppression (NMS), which further improves the localization performance. On MS-COCO, we boost the Average Precision (AP) of VGG-16 Faster R-CNN from 23.6% to 29.1%. More importantly, for ResNet-50-FPN Mask R-CNN, our method improves the AP and AP90 by 1.8% and 6.2% respectively, which significantly outperforms previous state-of-the-art bounding box refinement methods. Our code and models are available at: github.com/yihui-he/KL-Loss
Deep High-Resolution Representation Learning for Human Pose Estimation
Abstract: This is an official pytorch implementation of Deep High-Resolution Representation Learning for Human Pose Estimation. In this work, we are interested in the human pose estimation problem with a focus on learning reliable high-resolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process. We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutli-resolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich high-resolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection dataset and the MPII Human Pose dataset. The code and models have been publicly available at \url{https://github.com/leoxiaobin/deep-high-resolution-net.pytorch}
RePr- Improved Training of Convolutional Filters

Abstract: A well-trained Convolutional Neural Network can easily be pruned without significant loss of performance. This is because of unnecessary overlap in the features captured by the network’s filters.** Innovations in network architecture such as skip/dense connections and Inception units have mitigated this problem to some extent, but these improvements come with increased computation and memory requirements at run-time. We attempt to address this problem from another angle - not by changing the network structure but by altering the training method. We show that by temporarily pruning and then restoring a subset of the model’s filters, and repeating this process cyclically, overlap in the learned features is reduced, producing improved generalization. We show that the existing model-pruning criteria are not optimal for selecting filters to prune in this context and introduce inter-filter orthogonality as the ranking criteria to determine under-expressive filters. Our method is applicable both to vanilla convolutional networks and more complex modern architectures, and improves the performance across a variety of tasks, especially when applied to smaller networks.