CVPR 2021 Transformer Paper
[tracker motion image-retrival deep-learning matching transformer This post summarizes the papers on transformers in CVPR 2021. This is from CVPR2021-Papers-with-Code. Given transforms captures the interaction between query (Q) and dictionary (K), transform begins to see applications in tracking (e.g., Transformer Tracking, Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking), local match matching (e.g., LoFTR Detector-Free Local Feature Matching with Transformers) and image retrieval (e.g., Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers, Revamping cross-modal recipe retrieval with hierarchical Transformers and self-supervised learning)
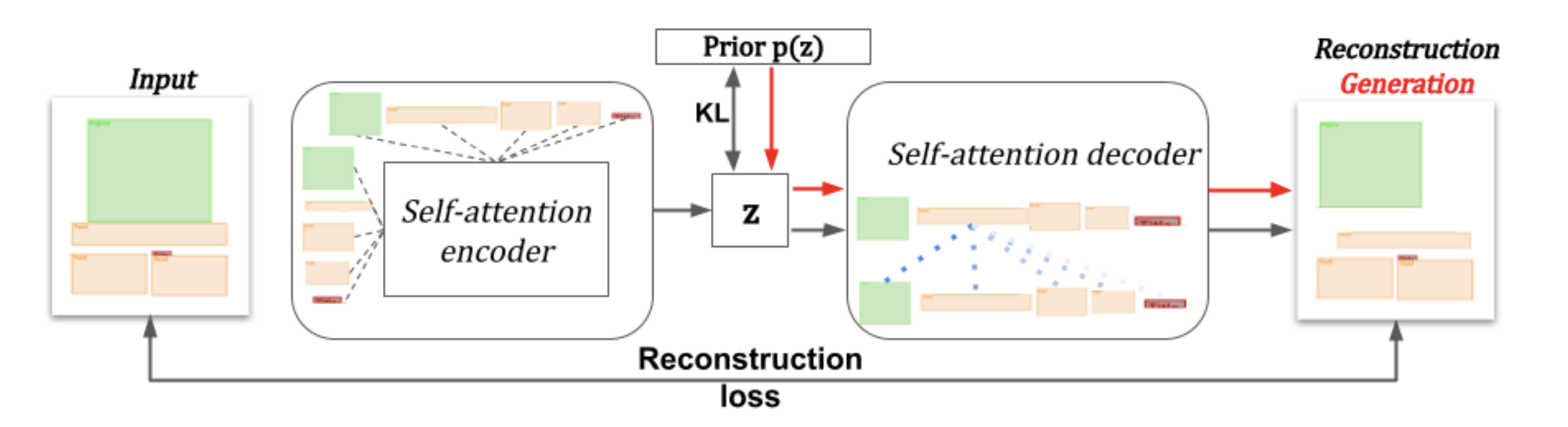
Variational Transformer Networks for Layout Generation
Generative models able to synthesize layouts of different kinds (e.g. documents, user interfaces or furniture arrangements) are a useful tool to aid design processes and as a first step in the generation of synthetic data, among other tasks. We exploit the properties of self-attention layers to capture high level relationships between elements in a layout, and use these as the building blocks of the well-known Variational Autoencoder (VAE) formulation. Our proposed Variational Transformer Network (VTN) is capable of learning margins, alignments and other global design rules without explicit supervision. Layouts sampled from our model have a high degree of resemblance to the training data, while demonstrating appealing diversity. In an extensive evaluation on publicly available benchmarks for different layout types VTNs achieve state-of-the-art diversity and perceptual quality. Additionally, we show the capabilities of this method as part of a document layout detection pipeline.
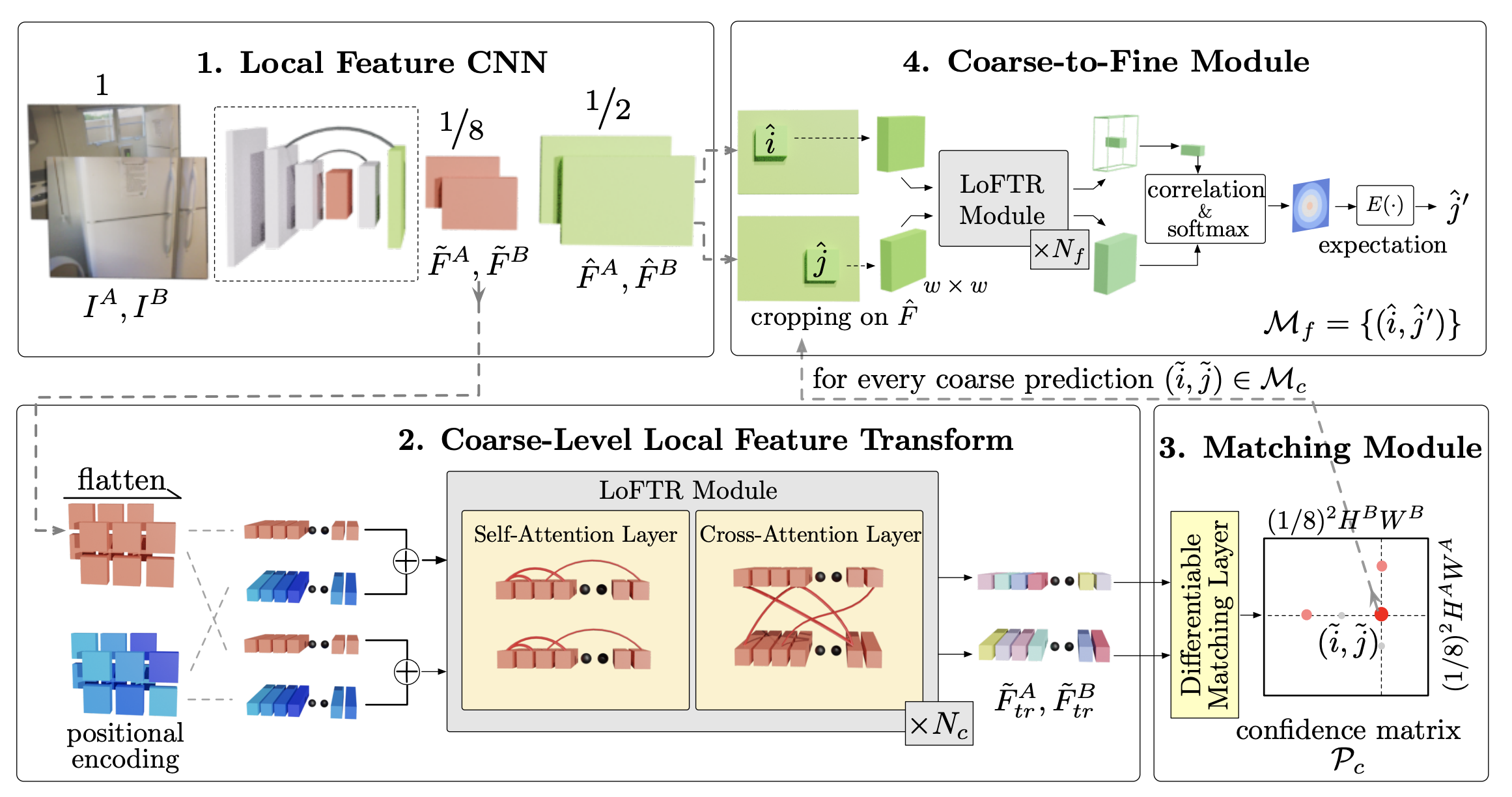
LoFTR Detector-Free Local Feature Matching with Transformers
We present a novel method for local image feature matching. Instead of performing image feature detection, description, and matching sequentially, we propose to first establish pixel-wise dense matches at a coarse level and later refine the good matches at a fine level. In contrast to dense methods that use a cost volume to search correspondences, we use self and cross attention layers in Transformer to obtain feature descriptors that are conditioned on both images. The global receptive field provided by Transformer enables our method to produce dense matches in low-texture areas, where feature detectors usually struggle to produce repeatable interest points. The experiments on indoor and outdoor datasets show that LoFTR outperforms state-of-the-art methods by a large margin. LoFTR also ranks first on two public benchmarks of visual localization among the published methods.
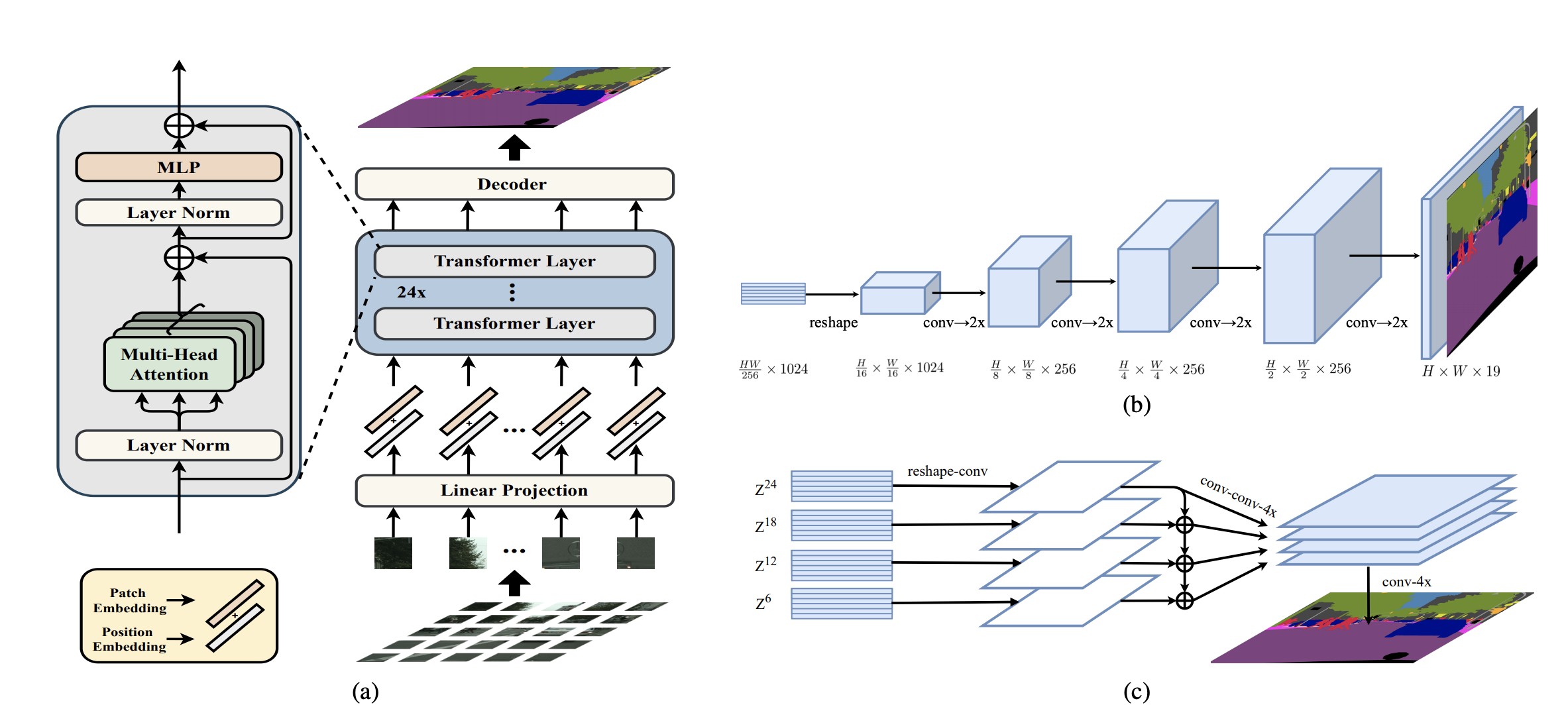
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first position in the highly competitive ADE20K test server leaderboard on the day of submission.
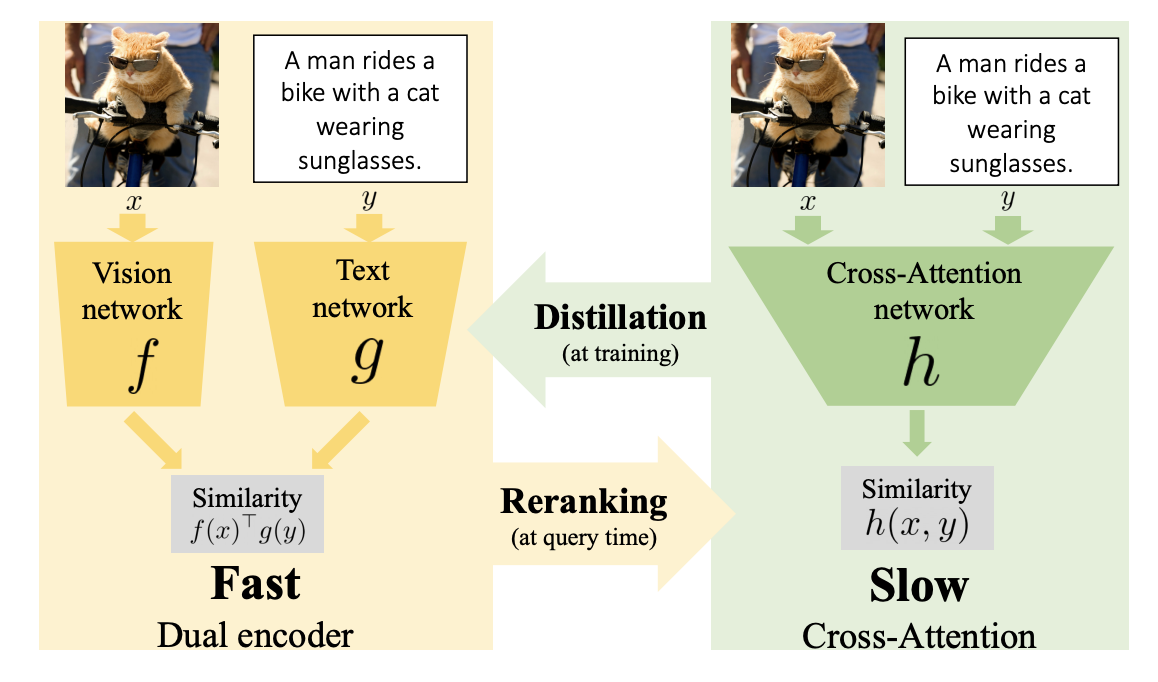
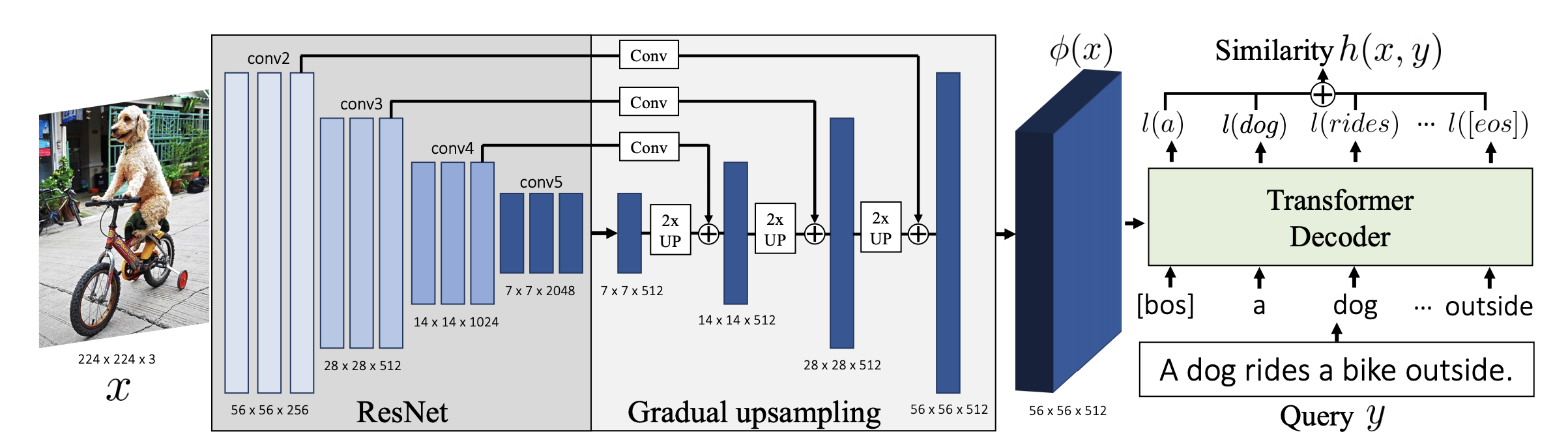
Thinking Fast and Slow Efficient Text-to-Visual Retrieval with Transformers
Our objective is language-based search of large-scale image and video datasets. For this task, the approach that consists of independently mapping text and vision to a joint embedding space, a.k.a. dual encoders, is attractive as retrieval scales and is efficient for billions of images using approximate nearest neighbour search. An alternative approach of using vision-text transformers with cross-attention gives considerable improvements in accuracy over the joint embeddings, but is often inapplicable in practice for large-scale retrieval given the cost of the cross-attention mechanisms required for each sample at test time. This work combines the best of both worlds. We make the following three contributions. First, we equip transformer-based models with a new fine-grained cross-attention architecture, providing significant improvements in retrieval accuracy whilst preserving scalability. Second, we introduce a generic approach for combining a Fast dual encoder model with our Slow but accurate transformer-based model via distillation and re-ranking. Finally, we validate our approach on the Flickr30K image dataset where we show an increase in inference speed by several orders of magnitude while having results competitive to the state of the art. We also extend our method to the video domain, improving the state of the art on the VATEX dataset.
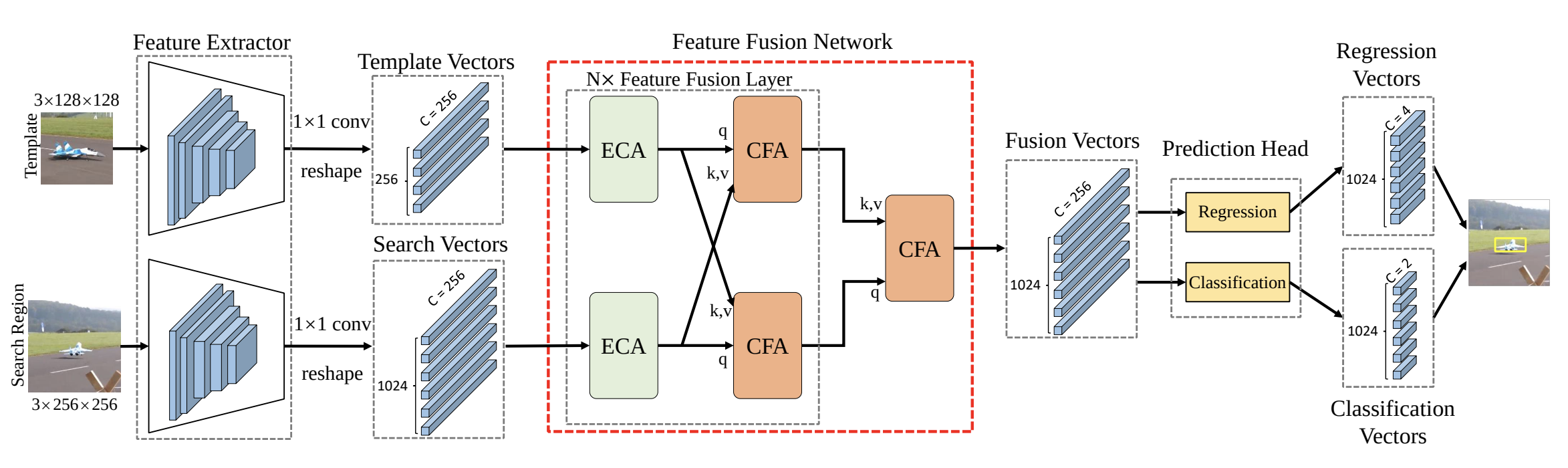
Transformer Tracking
Correlation acts as a critical role in the tracking field, especially in recent popular Siamese-based trackers. The correlation operation is a simple fusion manner to consider the similarity between the template and the search region. However, the correlation operation itself is a local linear matching process, leading to lose semantic information and fall into local optimum easily, which may be the bottleneck of designing high-accuracy tracking algorithms. Is there any better feature fusion method than correlation? To address this issue, inspired by Transformer, this work presents a novel attention-based feature fusion network, which effectively combines the template and search region features solely using attention. Specifically, the proposed method includes an ego-context augment module based on self-attention and a cross-feature augment module based on cross-attention. Finally, we present a Transformer tracking (named TransT) method based on the Siamese-like feature extraction backbone, the designed attention-based fusion mechanism, and the classification and regression head. Experiments show that our TransT achieves very promising results on six challenging datasets, especially on large-scale LaSOT, TrackingNet, and GOT-10k benchmarks. Our tracker runs at approximatively 50 fps on GPU. Code and models are available at this https URL.
HR-NAS Searching Efficient High-Resolution Neural Architectures with Transformers
- Paper(Oral)None
- Code
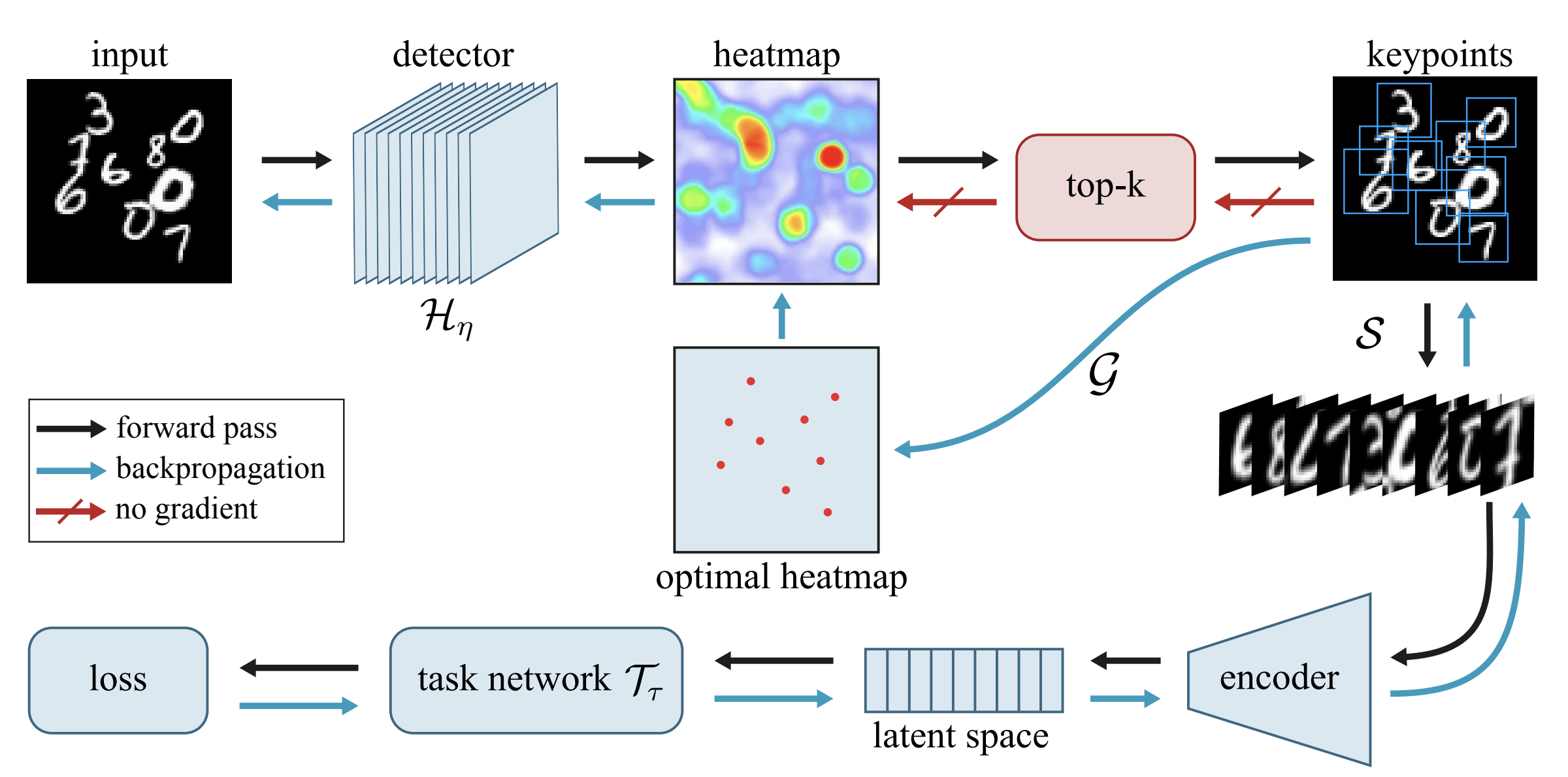
MIST Multiple Instance Spatial Transformer Network
We propose a deep network that can be trained to tackle image reconstruction and classification problems that involve detection of multiple object instances, without any supervision regarding their whereabouts. The network learns to extract the most significant top-K patches, and feeds these patches to a task-specific network – e.g., auto-encoder or classifier – to solve a domain specific problem. The challenge in training such a network is the non-differentiable top-K selection process. To address this issue, we lift the training optimization problem by treating the result of top-K selection as a slack variable, resulting in a simple, yet effective, multi-stage training. Our method is able to learn to detect recurrent structures in the training dataset by learning to reconstruct images. It can also learn to localize structures when only knowledge on the occurrence of the object is provided, and in doing so it outperforms the state-of-the-art.
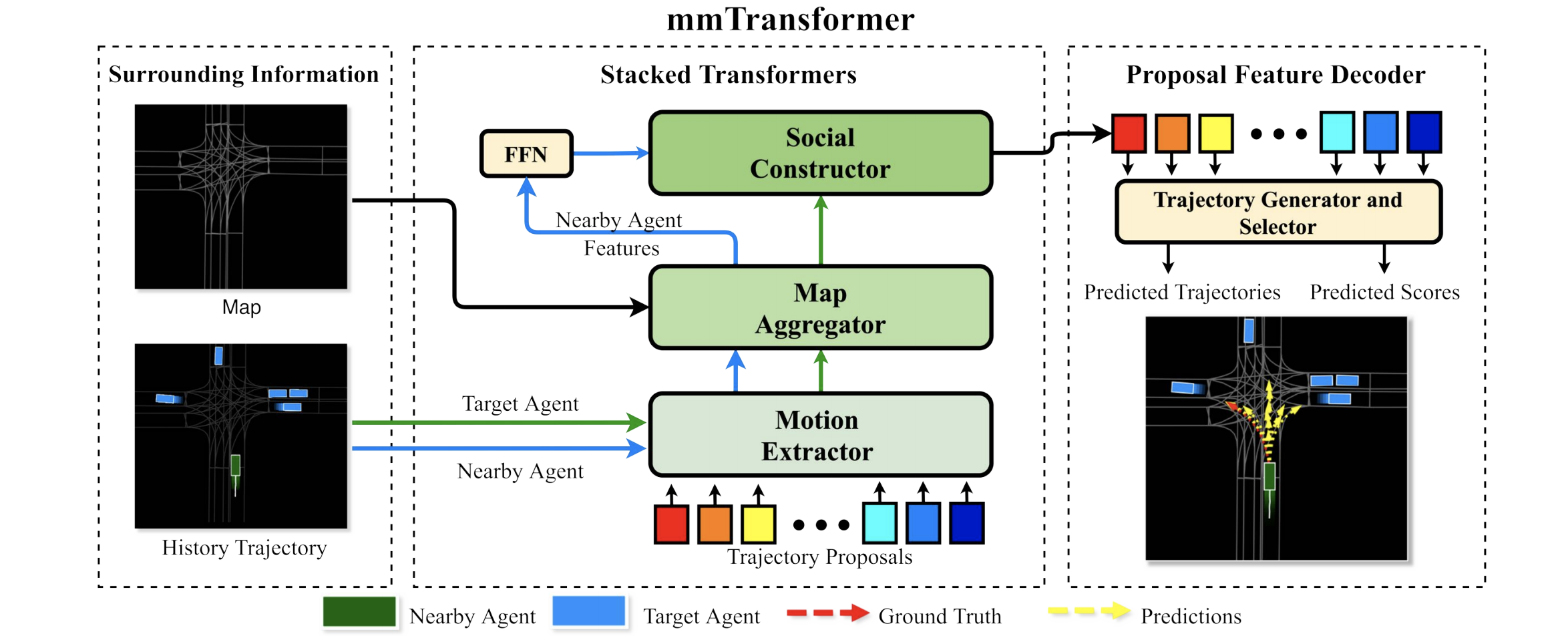
Multimodal Motion Prediction with Stacked Transformers
Predicting multiple plausible future trajectories of the nearby vehicles is crucial for the safety of autonomous driving. Recent motion prediction approaches attempt to achieve such multimodal motion prediction by implicitly regularizing the feature or explicitly generating multiple candidate proposals. However, it remains challenging since the latent features may concentrate on the most frequent mode of the data while the proposal-based methods depend largely on the prior knowledge to generate and select the proposals. In this work, we propose a novel transformer framework for multimodal motion prediction, termed as mmTransformer. A novel network architecture based on stacked transformers is designed to model the multimodality at feature level with a set of fixed independent proposals. A region-based training strategy is then developed to induce the multimodality of the generated proposals. Experiments on Argoverse dataset show that the proposed model achieves the state-of-the-art performance on motion prediction, substantially improving the diversity and the accuracy of the predicted trajectories. Demo video and code are available at this https URL.
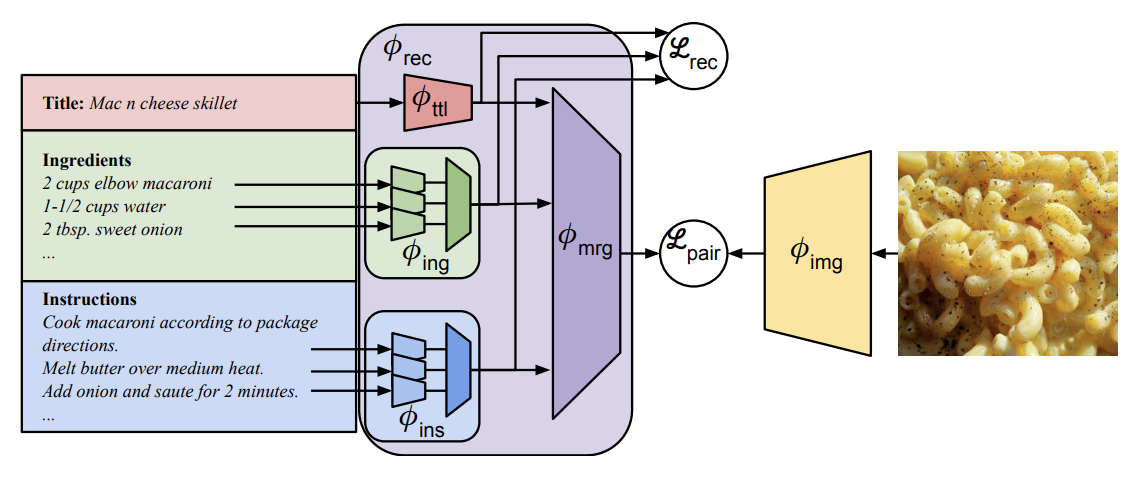
Revamping cross-modal recipe retrieval with hierarchical Transformers and self-supervised learning
Cross-modal recipe retrieval has recently gained substantial attention due to the importance of food in people’s lives, as well as the availability of vast amounts of digital cooking recipes and food images to train machine learning models. In this work, we revisit existing approaches for cross-modal recipe retrieval and propose a simplified end-to-end model based on well established and high performing encoders for text and images. We introduce a hierarchical recipe Transformer which attentively encodes individual recipe components (titles, ingredients and instructions). Further, we propose a self-supervised loss function computed on top of pairs of individual recipe components, which is able to leverage semantic relationships within recipes, and enables training using both image-recipe and recipe-only samples. We conduct a thorough analysis and ablation studies to validate our design choices. As a result, our proposed method achieves state-of-the-art performance in the cross-modal recipe retrieval task on the Recipe1M dataset. We make code and models publicly available.
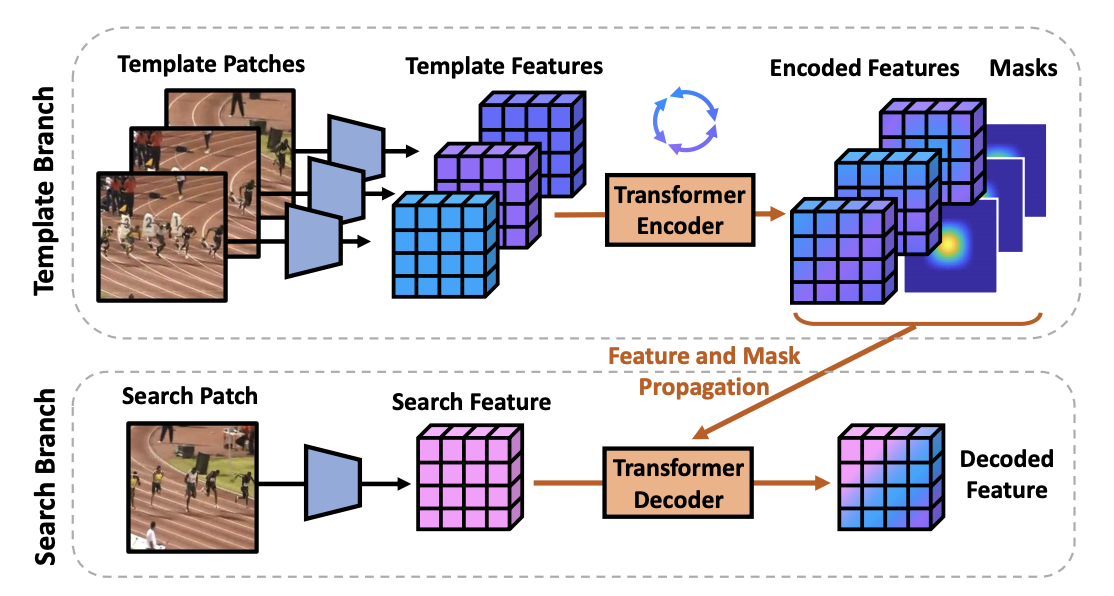
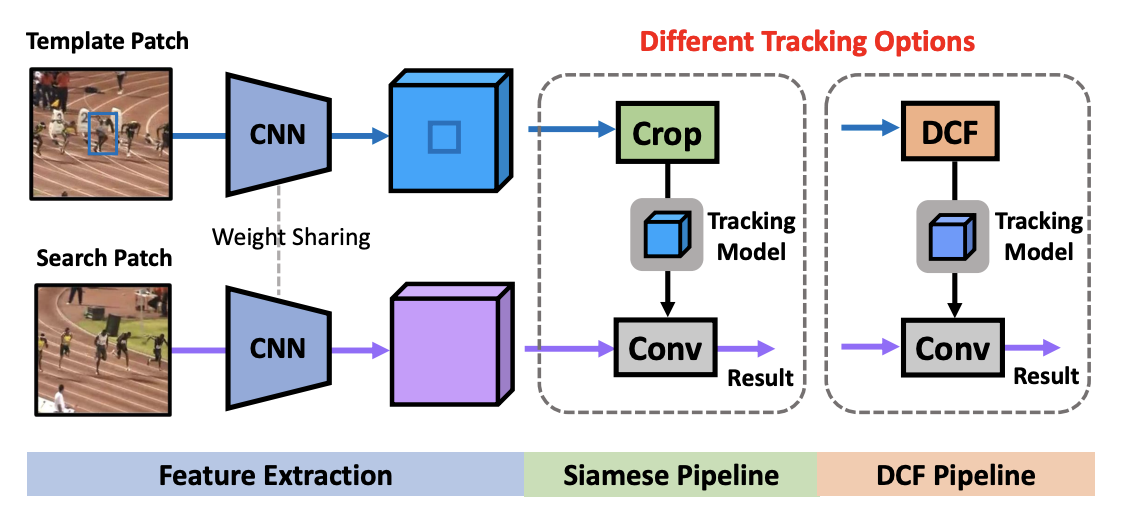
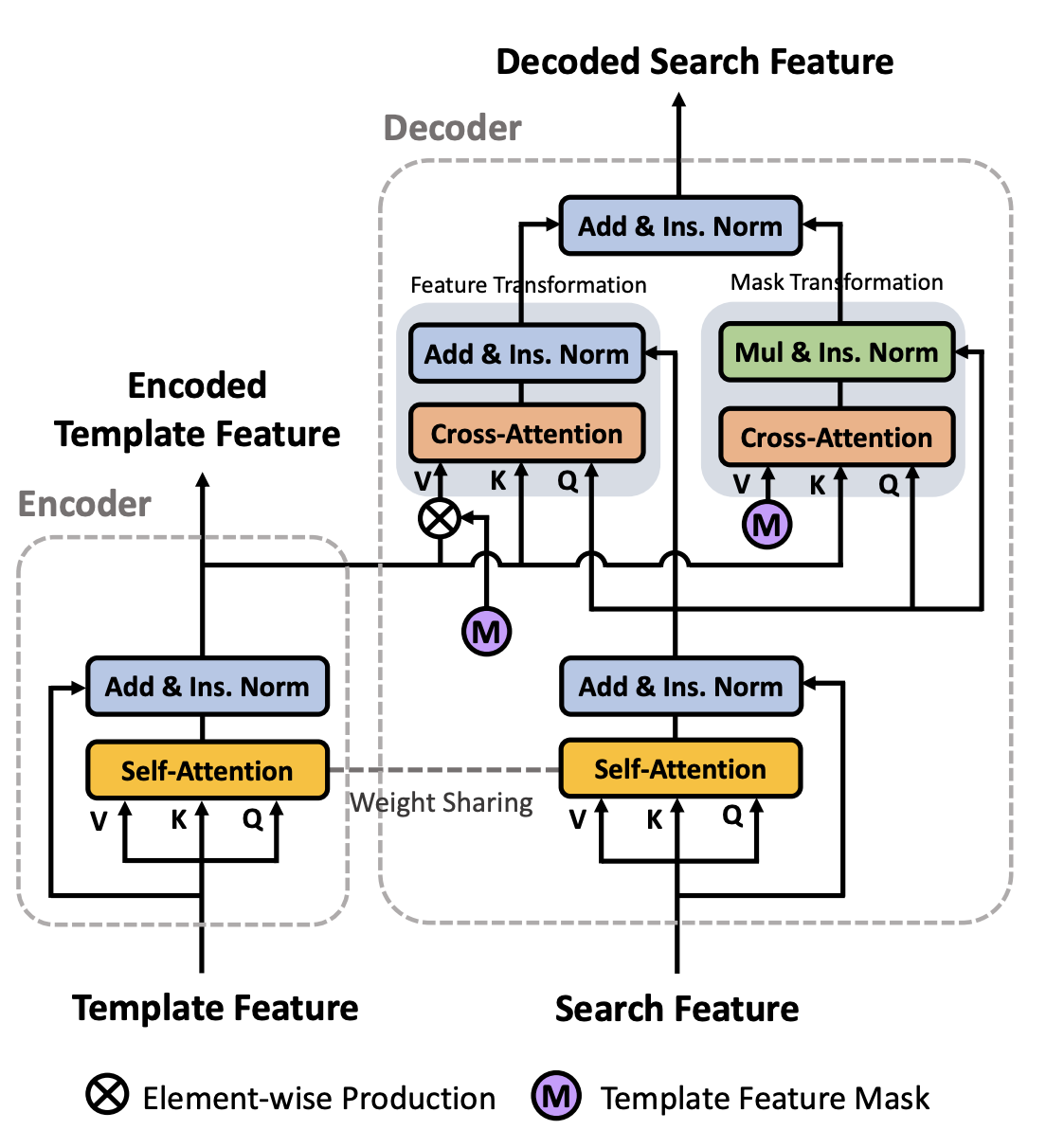
Transformer Meets Tracker Exploiting Temporal Context for Robust Visual Tracking
In video object tracking, there exist rich temporal contexts among successive frames, which have been largely overlooked in existing trackers. In this work, we bridge the individual video frames and explore the temporal contexts across them via a transformer architecture for robust object tracking. Different from classic usage of the transformer in natural language processing tasks, we separate its encoder and decoder into two parallel branches and carefully design them within the Siamese-like tracking pipelines. The transformer encoder promotes the target templates via attention-based feature reinforcement, which benefits the high-quality tracking model generation. The transformer decoder propagates the tracking cues from previous templates to the current frame, which facilitates the object searching process. Our transformer-assisted tracking framework is neat and trained in an end-to-end manner. With the proposed transformer, a simple Siamese matching approach is able to outperform the current top-performing trackers. By combining our transformer with the recent discriminative tracking pipeline, our method sets several new state-of-the-art records on prevalent tracking benchmarks.
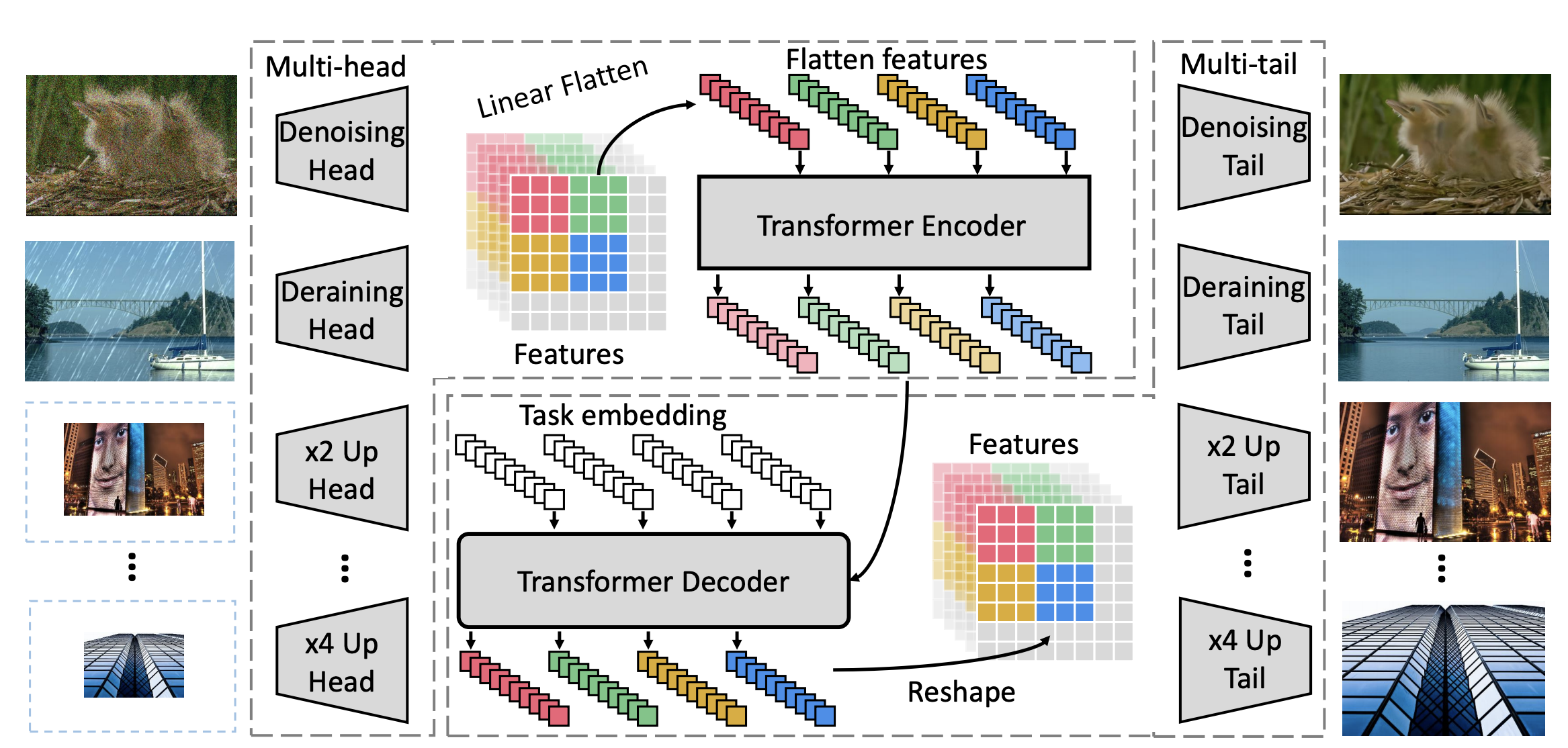
Pre-Trained Image Processing Transformer
As the computing power of modern hardware is increasing strongly, pre-trained deep learning models (e.g., BERT, GPT-3) learned on large-scale datasets have shown their effectiveness over conventional methods. The big progress is mainly contributed to the representation ability of transformer and its variant architectures. In this paper, we study the low-level computer vision task (e.g., denoising, super-resolution and deraining) and develop a new pre-trained model, namely, image processing transformer (IPT). To maximally excavate the capability of transformer, we present to utilize the well-known ImageNet benchmark for generating a large amount of corrupted image pairs. The IPT model is trained on these images with multi-heads and multi-tails. In addition, the contrastive learning is introduced for well adapting to different image processing tasks. The pre-trained model can therefore efficiently employed on desired task after fine-tuning. With only one pre-trained model, IPT outperforms the current state-of-the-art methods on various low-level benchmarks.
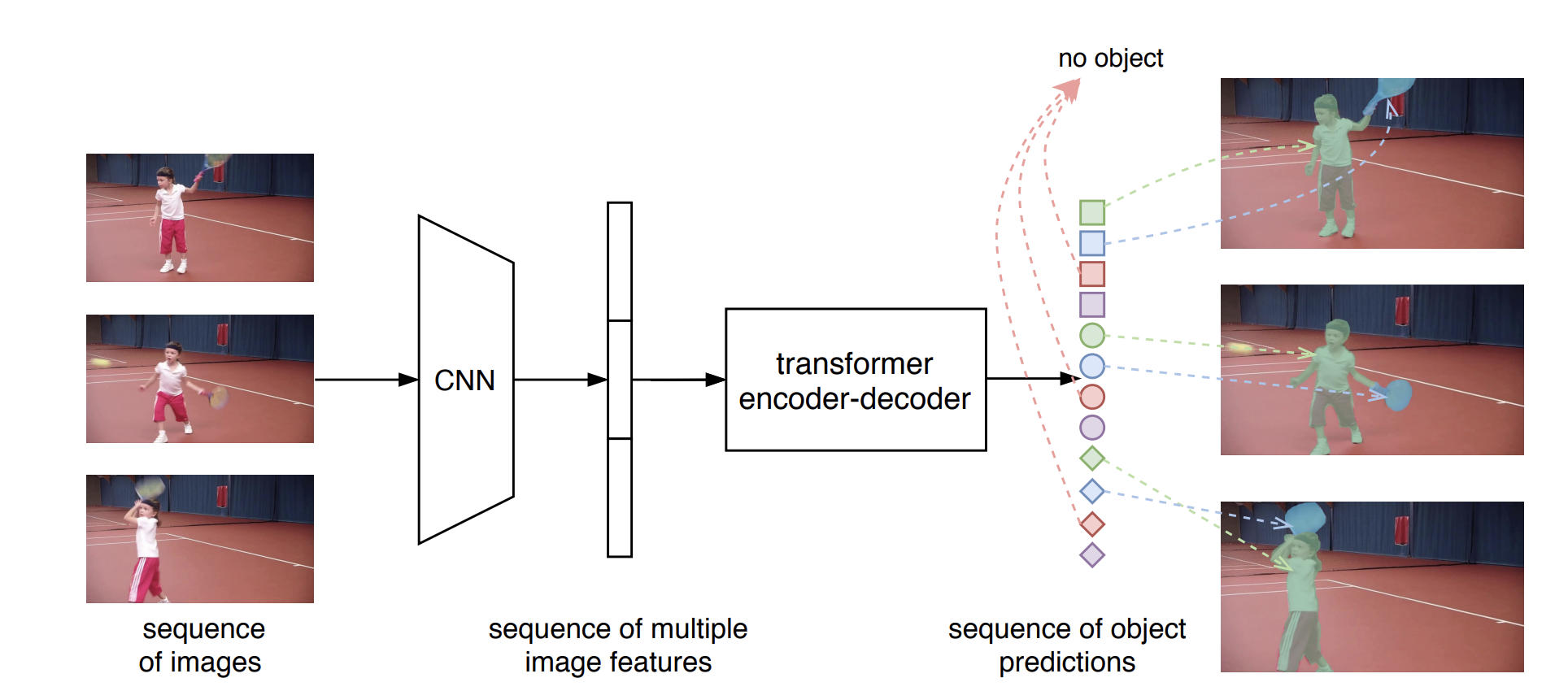
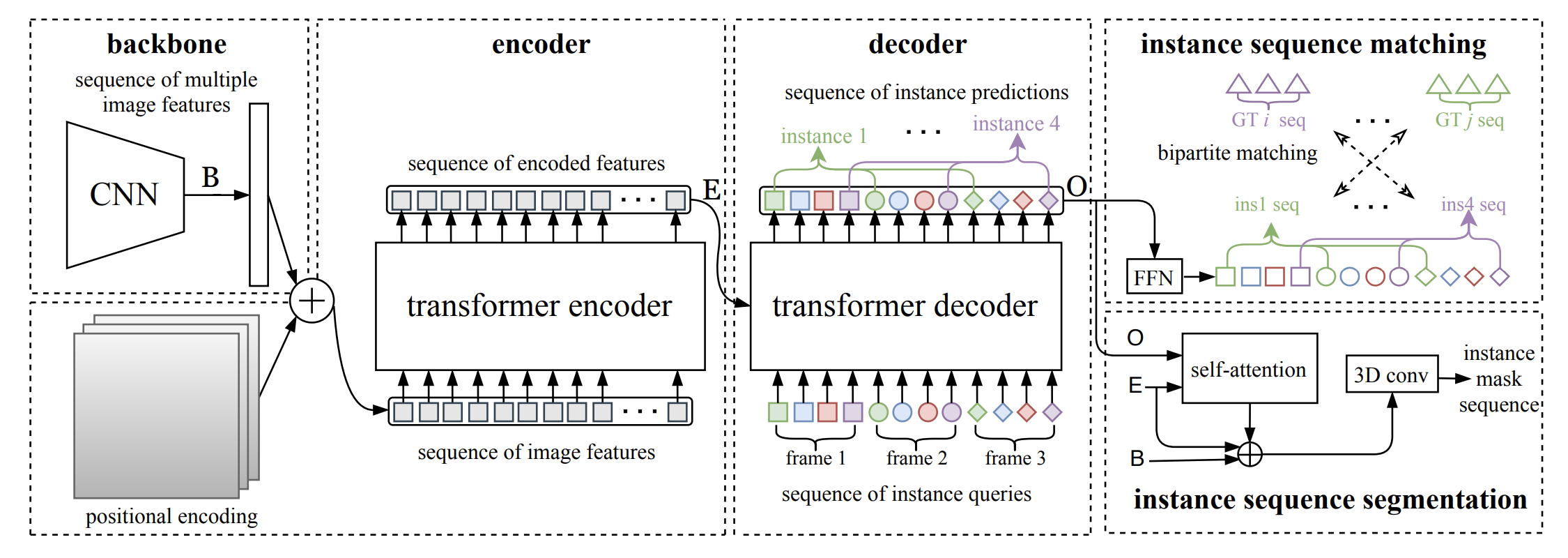
End-to-End Video Instance Segmentation with Transformers
Video instance segmentation (VIS) is the task that requires simultaneously classifying, segmenting and tracking object instances of interest in video. Recent methods typically develop sophisticated pipelines to tackle this task. Here, we propose a new video instance segmentation framework built upon Transformers, termed VisTR, which views the VIS task as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches. Without bells and whistles, VisTR achieves the highest speed among all existing VIS models, and achieves the best result among methods using single model on the YouTube-VIS dataset. For the first time, we demonstrate a much simpler and faster video instance segmentation framework built upon Transformers, achieving competitive accuracy. We hope that VisTR can motivate future research for more video understanding tasks.
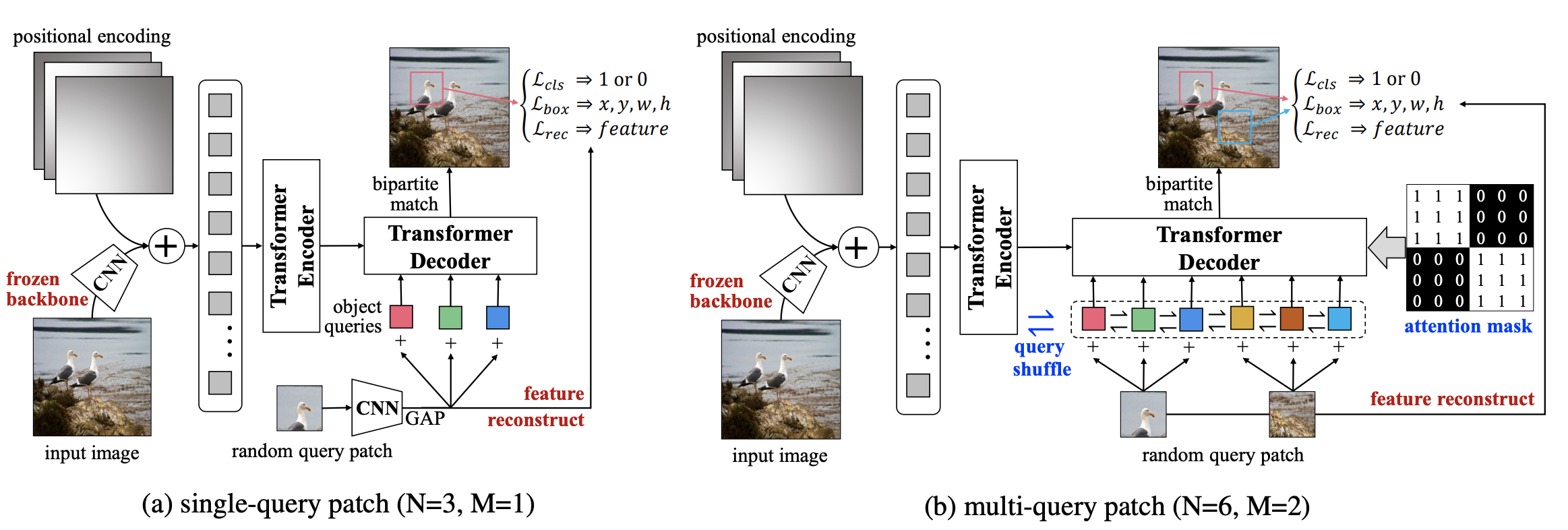
UP-DETR Unsupervised Pre-training for Object Detection with Transformers
Object detection with transformers (DETR) reaches competitive performance with Faster R-CNN via a transformer encoder-decoder architecture. Inspired by the great success of pre-training transformers in natural language processing, we propose a pretext task named random query patch detection to Unsupervisedly Pre-train DETR (UP-DETR) for object detection. Specifically, we randomly crop patches from the given image and then feed them as queries to the decoder. The model is pre-trained to detect these query patches from the original image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade off classification and localization preferences in the pretext task, we freeze the CNN backbone and propose a patch feature reconstruction branch which is jointly optimized with patch detection. (2) To perform multi-query localization, we introduce UP-DETR from single-query patch and extend it to multi-query patches with object query shuffle and attention mask. In our experiments, UP-DETR significantly boosts the performance of DETR with faster convergence and higher average precision on object detection, one-shot detection and panoptic segmentation. Code and pre-training models: this https URL.
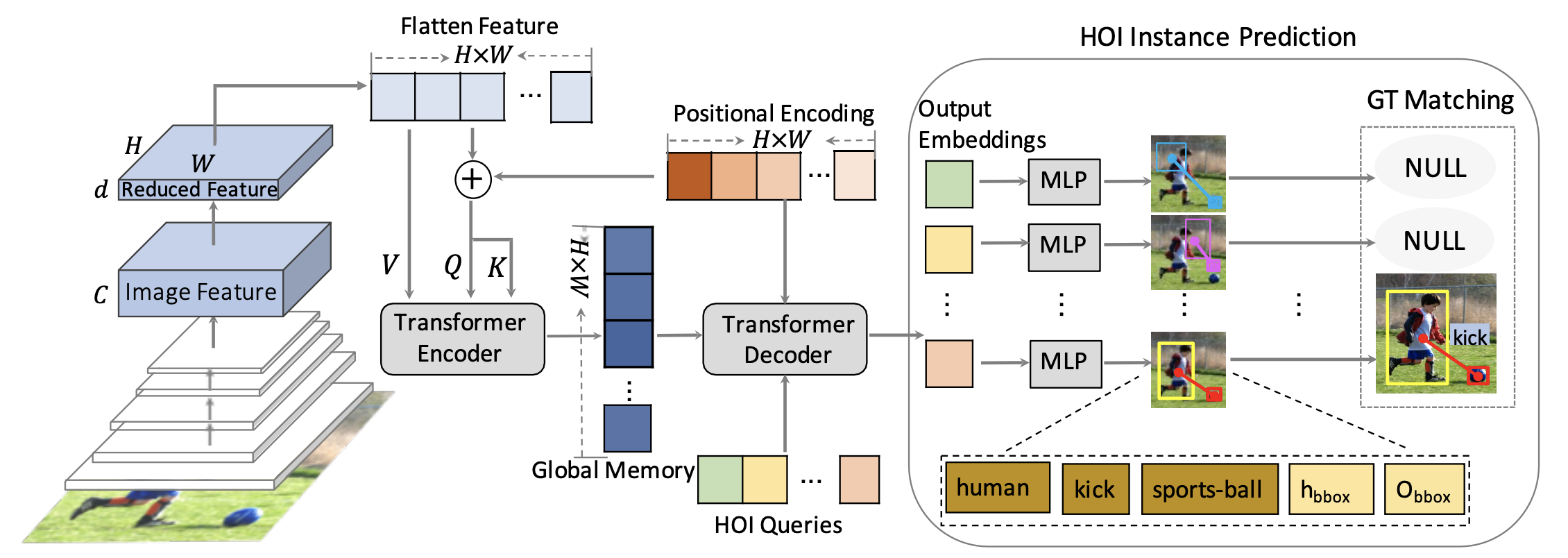
End-to-End Human Object Interaction Detection with HOI Transformer
We propose HOI Transformer to tackle human object interaction (HOI) detection in an end-to-end manner. Current approaches either decouple HOI task into separated stages of object detection and interaction classification or introduce surrogate interaction problem. In contrast, our method, named HOI Transformer, streamlines the HOI pipeline by eliminating the need for many hand-designed components. HOI Transformer reasons about the relations of objects and humans from global image context and directly predicts HOI instances in parallel. A quintuple matching loss is introduced to force HOI predictions in a unified way. Our method is conceptually much simpler and demonstrates improved accuracy. Without bells and whistles, HOI Transformer achieves 26.61% AP on HICO-DET and 52.9% AProle on V-COCO, surpassing previous methods with the advantage of being much simpler. We hope our approach will serve as a simple and effective alternative for HOI tasks. Code is available at this https URL .
Transformer Interpretability Beyond Attention Visualization
Self-attention techniques, and specifically Transformers, are dominating the field of text processing and are becoming increasingly popular in computer vision classification tasks. In order to visualize the parts of the image that led to a certain classification, existing methods either rely on the obtained attention maps or employ heuristic propagation along the attention graph. In this work, we propose a novel way to compute relevancy for Transformer networks. The method assigns local relevance based on the Deep Taylor Decomposition principle and then propagates these relevancy scores through the layers. This propagation involves attention layers and skip connections, which challenge existing methods. Our solution is based on a specific formulation that is shown to maintain the total relevancy across layers. We benchmark our method on very recent visual Transformer networks, as well as on a text classification problem, and demonstrate a clear advantage over the existing explainability methods.