Object Detection Update (2019/1~2019/3)
[deep-learning object-detection Reference: awesome object detection and 一文看尽21篇目标检测最新论文(腾讯/Google/商汤/旷视/清华/浙大/CMU/华科/中科院等)
Consistent Optimization for Single-Shot Object Detection
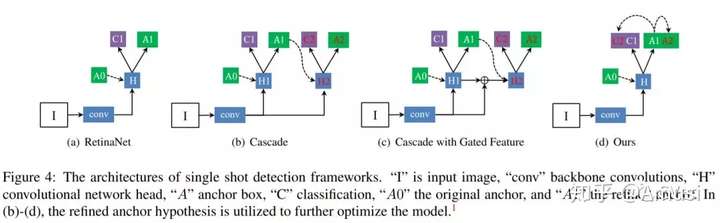
This work observes that in addition to the foreground-background class imbalance challenge, current single shot object detectors also face another challenge: the misalignment between the training targets and inference configurations, where the training target of the classification is to classify the default, regular anchor, while the predicted probability is assigned to the corresponding regressed anchor which is generated by the localization branch.
Thus Consistent optimization, which is an extension of the traditional single stage detector’s optimization strategy, is proposed to improve the performance. Consistent optimization focuses on matching the training hypotheses and the inference quality by utilizing of the refined anchors during training. It is similar to Cascade R-CNN.
SimpleDet: A Simple and Versatile Distributed Framework for Object Detection and Instance Recognition
This paper presents an efficient and open source object detection framework called SimpleDet which enables the training of state-of-the-art detection models on consumer grade hardware at large scale. SimpleDet supports up-to-date detection models with best practice. SimpleDet also supports distributed training with near linear scaling out of box.
- Fast RCNN
- Faster RCNN
- Mask RCNN
- Cascade RCNN
- RetinaNet
- Deformable Convolution Network
- TridentNet
DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection
This paper combines DenseNet and Spatial Pyramid Pooling for YOLO.
Rotated Feature Network for multi-orientation object detection
Convolution is not robust over rotation. To address this issue, we provide an Encoder-Decoder architecture, called Rotated Feature Network (RFN), which produces rotation-sensitive feature maps (RS) for regression and rotation-invariant feature maps (RI) for classification. Specifically, the Encoder unit assigns weights for rotated feature maps. The Decoder unit extracts RS and RI by performing resuming operator on rotated and reweighed feature maps, respectively.
R2-CNN: Fast Tiny Object Detection in Large-scale Remote Sensing Images
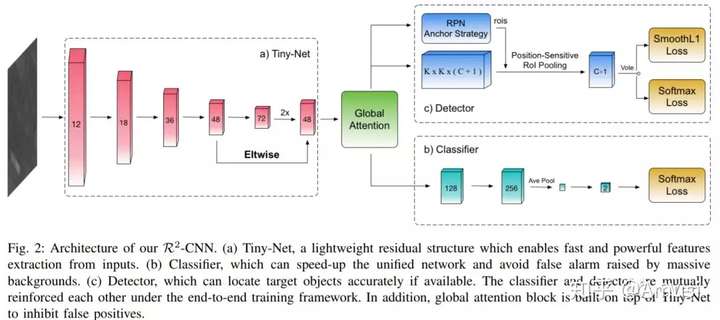
This paper addressing the challenges in detecting tiny objects in large-scale remote sensing images. First, the extreme large input size makes the existing object detection solutions too slow for practical use. Second, the massive and complex backgrounds cause serious false alarms. Moreover, the ultratiny objects increase the difficulty of accurate detection.
To tackle these problems, we propose a unified and self-reinforced network called remote sensing region-based convolutional neural network (R2-CNN), composing of backbone Tiny-Net, intermediate global attention block, and final classifier and detector.
- Tiny-Net is a lightweight residual structure, which enables fast and powerful features extraction from inputs.
- Global attention block is built upon Tiny-Net to inhibit false positives.
- Classifier is then used to predict the existence of targets in each patch, and detector is followed to locate them accurately if available. The classifier and detector are mutually reinforced with end-to-end training, which further speed up the process and avoid false alarms.
DetNAS: Neural Architecture Search on Object Detection
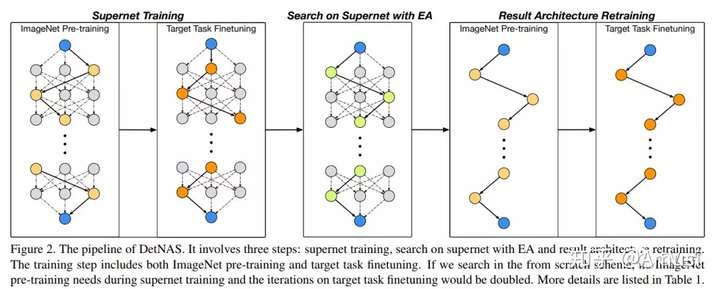
In this paper, we propose DetNAS to automatically search neural architectures for the backbones of object detectors. In DetNAS, the search space is formulated into a supernet and the search method relies on evolution algorithm (EA). In experiments, we show the effectiveness of DetNAS on various detectors, the one-stage detector, RetinaNet, and the two-stage detector, FPN.
TensorMask: A Foundation for Dense Object Segmentation
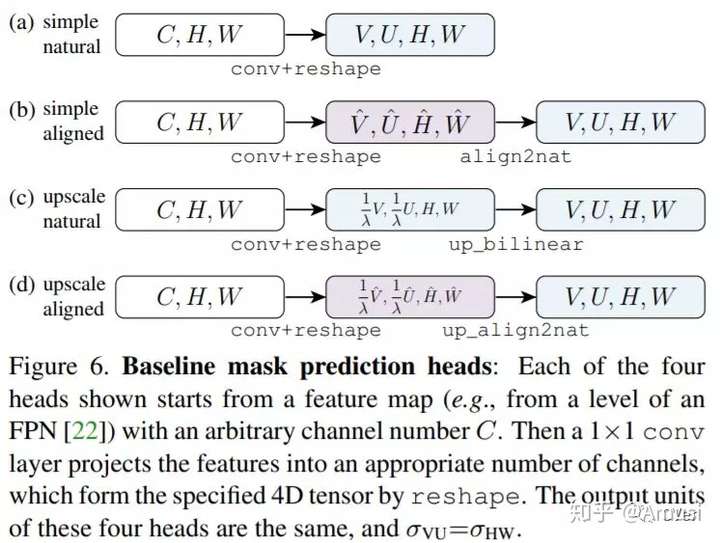
Modern instance segmentation approaches are dominated by methods that first detect object bounding boxes, and then crop and segment these regions, as popularized by Mask R-CNN. In this work, we investigate the paradigm of dense sliding-window instance segmentation, which is surprisingly under-explored. Our core observation is that this task is fundamentally different than other dense prediction tasks such as semantic segmentation or bounding-box object detection, as the output at every spatial location is itself a geometric structure with its own spatial dimensions. To formalize this, we treat dense instance segmentation as a prediction task over 4D tensors and present a general framework called TensorMask that explicitly captures this geometry and enables novel operators on 4D tensors. We demonstrate that the tensor view leads to large gains over baselines that ignore this structure, and leads to results comparable to Mask R-CNN. These promising results suggest that TensorMask can serve as a foundation for novel advances in dense mask prediction and a more complete understanding of the task. Code will be made available.
Feature Intertwiner for Object Detection
Our assumption is that semantic features for one category should be the same as shown in (a) below. Due to the inferior up-sampling design in RoI operation, shown in (b), the reliable set (green) could guide the feature learning of the less reliable set (blue).

Here comes the proposed feature intertwiner:

- PyTorch
0.3 - Code/framework based on Mask-RCNN.
- Datasets: COCO and Pascal VOC (not in this repo)
Training Tricks
Bag of Freebies for Training Object Detection Neural Networks
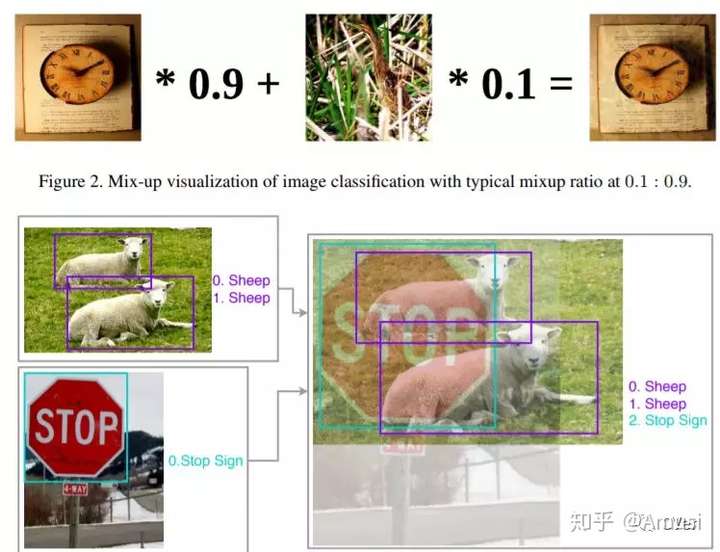
This paper introduces some trciks in training object detection network:
- Visually Coherent Image Mixup for Object Detection: weighted average sum of two images, where the weight is drawn from beta distribution with a=0.2 and b=0.2.
- Classification Head Label Smoothing: the ground truth label is smoothed by adding a small constant $p_i = (1-\epsilon)q_i + \frac{\epsilon}{K}$ and K is the total number of classes.
- Data Pre-processing:
- Random geometry transformation. Including random cropping (with constraints), random expansion, random horizontal flip and random resize (with random interpolation).
- Random color jittering including brightness, hue, saturation, and contrast.
- Training Scheduler Revamping: Cosine schedule scales the learning rate according to the value of cosine function on 0 to pi. It starts with slowly reducing large learning rate, then reduces the learning rate quickly halfway, and finally ends up with tiny slope reducing small learning rate until it reaches 0.
- Synchronized Batch Normalization
- Random shapes training for single-stage object detection networks: a mini-batch ofNtrainingimagesisresizedtoN×3×H× W, where H and W are multipliers of common divisor D = randint(1,k). For example, we use H = W ∈ {320, 352, 384, 416, 448, 480, 512, 544, 576, 608} for YOLOv3 training.
Video Object Detection
AdaScale: Towards Real-time Video Object Detection Using Adaptive Scaling
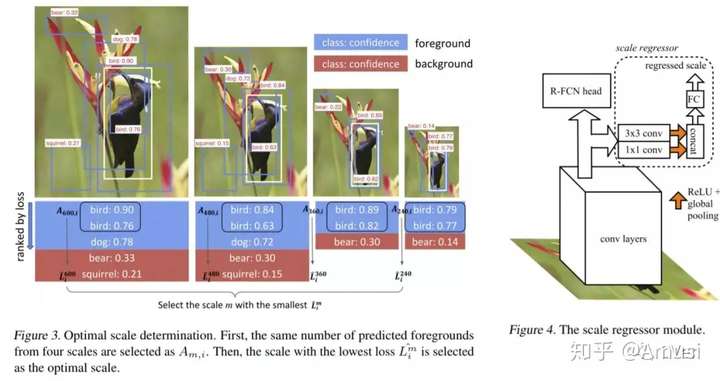
Our results show that re-scaling the image to a lower resolution will sometimes produce better accuracy. Based on this observation, we propose a novel approach, dubbed AdaScale, which adaptively selects the input image scale that improves both accuracy and speed for video object detection.
SCNN: A General Distribution based Statistical Convolutional Neural Network with Application to Video Object Detection
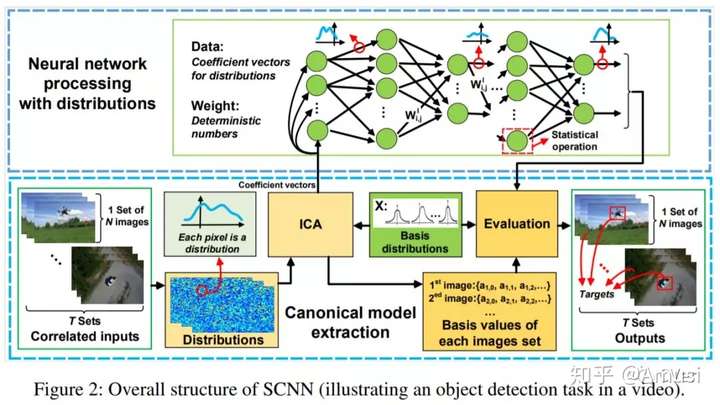
This paper argues that most of existing networks, process one single frame of image at a time, and may not fully utilize the temporal and contextual correlation typically present in multiple channels of the same image or adjacent frames from a video, thus limiting the achievable throughput. This limitation stems from the fact that existing CNNs operate on deterministic numbers. In this paper, we propose a novel statistical convolutional neural network (SCNN), which extends existing CNN architectures but operates directly on correlated distributions rather than deterministic numbers.
Progressive Sparse Local Attention for Video object detection
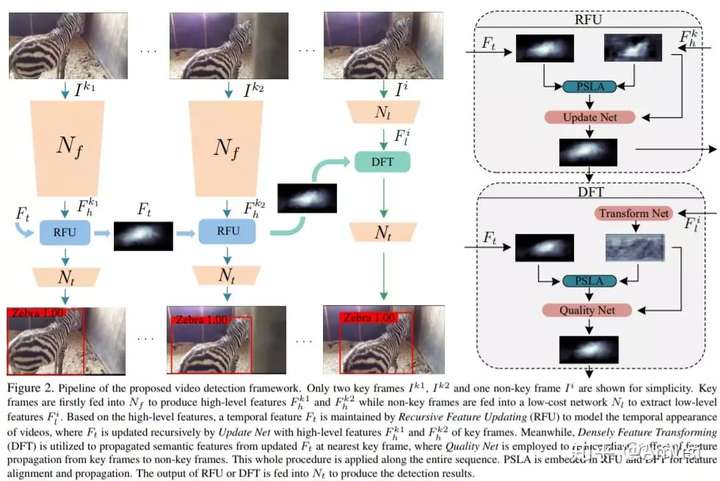
Transferring image-based object detectors to the domain of videos remains a challenging problem. Previous efforts mostly exploit optical flow to propagate features across frames, aiming to achieve a good trade-off between accuracy and efficiency. However, introducing an extra model to estimate optical flow would significantly increase the overall model size. The gap between optical flow and high-level features can also hinder it from establishing spatial correspondence accurately.
Instead of relying on optical flow, this paper proposes a novel module called Progressive Sparse Local Attention (PSLA), which establishes the spatial correspondence between features across frames in a local region with progressive sparser stride and uses the correspondence to propagate features. Based on PSLA, Recursive Feature Updating (RFU) and Dense Feature Transforming (DFT) are proposed to model temporal appearance and enrich feature representation respectively in a novel video object detection framework.
Looking Fast and Slow: Memory-Guided Mobile Video Object Detection
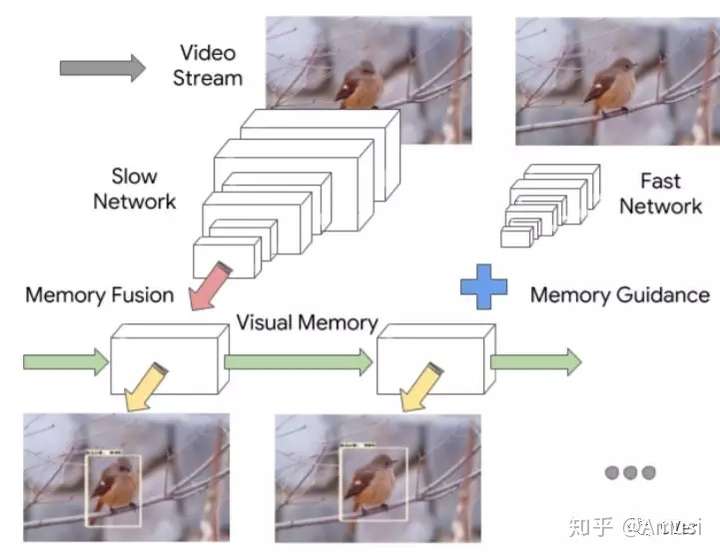
By introducing a temporal dimension to the problem, humans can rely on contextual cues and memory to supplement their understanding of the image. Based on this observation we introduce a novel interleaved framework where two feature extractors with drastically dif- ferent speeds and recognition capacities are run on different frames. The features from these extractors are used to main- tain a common visual memory of the scene in the form of a convolutional LSTM (ConvLSTM) layer, and detections are generated by fusing context from previous frames with the gist from the current frame. Furthermore, we show that the combination of memory and gist contains within itself the information necessary to decide when the memory must be updated. We learn an interleaving policy of when to run each feature extractor by formulating the task as a reinforce- ment learning problem.
3D Object Detection
The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes

Honda Research Institute 3D Dataset (H3D) is a large-scale full-surround 3D multi-object detection and tracking dataset collected using a 3D LiDAR scanner. H3D comprises of 160 crowded and highly interactive traffic scenes with a total of 1 million labeled instances in 27,721 frames.
3D Backbone Network for 3D Object Detection
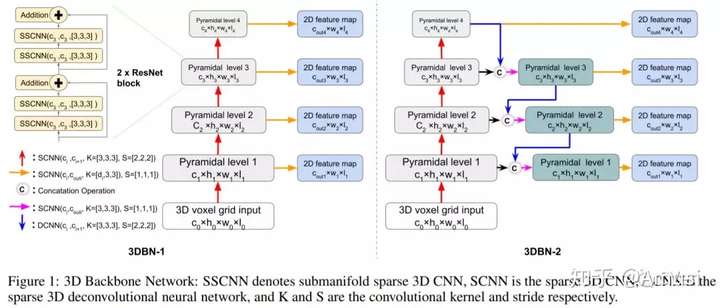
This paper proposed to build a 3D backbone network to learn rich 3D feature maps by using sparse 3D CNN operations for 3D object detection in point cloud. The 3D backbone network can inherently learn 3D features from almost raw data without compressing point cloud into multiple 2D images and generate rich feature maps for object detection. The sparse 3D CNN takes full advantages of the sparsity in the 3D point cloud to accelerate computation and save memory, which makes the 3D backbone network achievable.
The network utilize the idea of Feature Pyramid Networks for Object Detection and uses ResNet as the backbone of each pyramid level.
Monocular 3D Object Detection with Pseudo-LiDAR Point Cloud
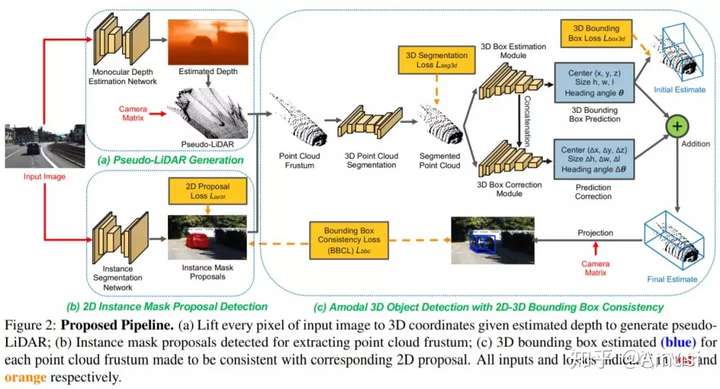
In this work, we aim at bridging the performance gap between 3D sensing and 2D sensing for 3D object detection by enhancing LiDAR-based algorithms to work with single image input. Specifically, we perform monocular depth estimation and lift the input image to a point cloud representation, which we call pseudo-LiDAR point cloud. Then we can train a LiDAR-based 3D detection network with our pseudo-LiDAR end-to-end. Following the pipeline of two-stage 3D detection algorithms, we detect 2D object proposals in the input image and extract a point cloud frustum from the pseudo-LiDAR for each proposal. Then an oriented 3D bounding box is detected for each frustum.
FVNet: 3D Front-View Proposal Generation for Real-Time Object Detection from Point Clouds
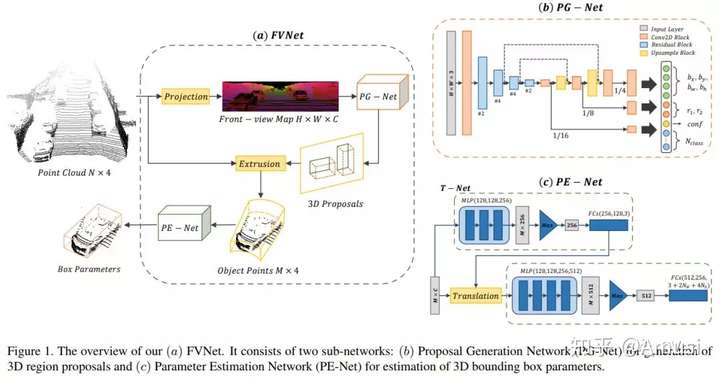
this paper, we propose a novel framework called FVNet for 3D front-view proposal generation and object detection from point clouds. It consists of two stages:
- generation of front-view proposals
- estimation of 3D bounding box parameters.
The proposed method contains the follow steps:
- Instead of generating proposals from camera images or bird’s-eye-view maps, we first project point clouds onto a cylindrical surface to generate front-view feature maps which retains rich information.
- We then introduce a proposal generation network to predict 3D region proposals from the generated maps and further extrude objects of interest from the whole point cloud.
- Finally, we present another network to extract the point-wise features from the extruded object points and regress the final 3D bounding box parameters in the canonical coordinates.
Accurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving
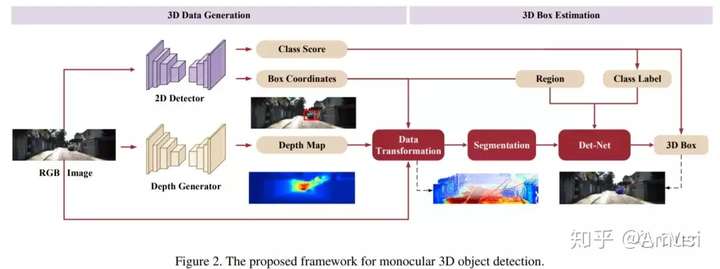
In this paper, we propose a monocular 3D object detection framework in the domain of autonomous driving. Unlike previous image-based methods which focus on RGB feature extracted from 2D images, our method solves this problem in the reconstructed 3D space in order to exploit 3D contexts explicitly.
The proposed method contains the following steps:
- we first leverage a stand-alone module to transform the input data from 2D image plane to 3D point clouds space for a better input representation,
- then we perform the 3D detection using PointNet backbone net to obtain objects 3D locations, dimensions and orientations.
- To enhance the discriminative capability of point clouds, we propose a multi-modal feature fusion module to embed the complementary RGB cue into the generated point clouds representation.
We argue that it is more effective to infer the 3D bounding boxes from the generated 3D scene space (i.e., X,Y, Z space) compared to the image plane (i.e., R,G,B image plane).
Data Augmentation
Augmentation for small object detection

We thus propose to oversample those images with small objects and augment each of those images by copy-pasting small objects many times. It allows us to trade off the quality of the detector on large objects with that on small objects.
Improve Object Detection by Data Enhancement based on Generative Adversarial Nets

We propose a data enhancement method based on the foreground-background separation model. While this model uses a binary image of object target random perturb original dataset image. Perturbation methods include changing the color channel of the object, adding salt noise to the object, and enhancing contrast. The main contribution of this paper is to propose a data enhancement method based on GAN and improve detection accuracy of DSSD.