Efficient Geometry-aware 3D Generative Adversarial Networks
[face pi-gan gan nerf eg3d giraffe triplane deep-learning 3d This is my reading note on Efficient Geometry-aware 3D Generative Adversarial Networks. EG3D proposes a 20 to 3D generate method base style gan and triplane based nerf. The high level idea is to use style gan to generate triplane, which is then rendered into images. The rendered image is the discriminated to the input images at two resolutions. The camera pose is also required to generate the triplane.
Introduction
Existing 3D GANs are either compute-intensive or make approximations that are not 3D-consistent; (p. 1) We introduce an expressive hybrid explicit-implicit network architecture that, to- gether with other design choices, synthesizes not only high- resolution multi-view-consistent images in real time but also produces high-quality 3D geometry. By decoupling fea- ture generation and neural rendering, our framework is able to leverage state-of-the-art 2D CNN generators, such as StyleGAN2, and inherit their efficiency and expressive- ness. (p. 1)

Second, although we use some image-space approximations that stray from the 3D-grounded rendering, we introduce a dual- discrimination strategy that maintains consistency between the neural rendering and our final output to regularize their undesirable view-inconsistent tendencies. Moreover, we introduce pose-based conditioning to our generator, which decouples pose-correlated attributes (e.g., facial expressions) for a multi-view consistent output during inference while faithfully modeling the joint distributions of pose-correlated attributes inherent in the training data. (p. 2)
Our framework decouples feature generation from neural rendering, enabling it to directly leverage state-of-the-art 2D CNN-based feature generators, such as StyleGAN2, to generalize over spaces of 3D scenes while also benefiting from 3D multi-view-consistent neural volume rendering. (p. 2)
Related Work
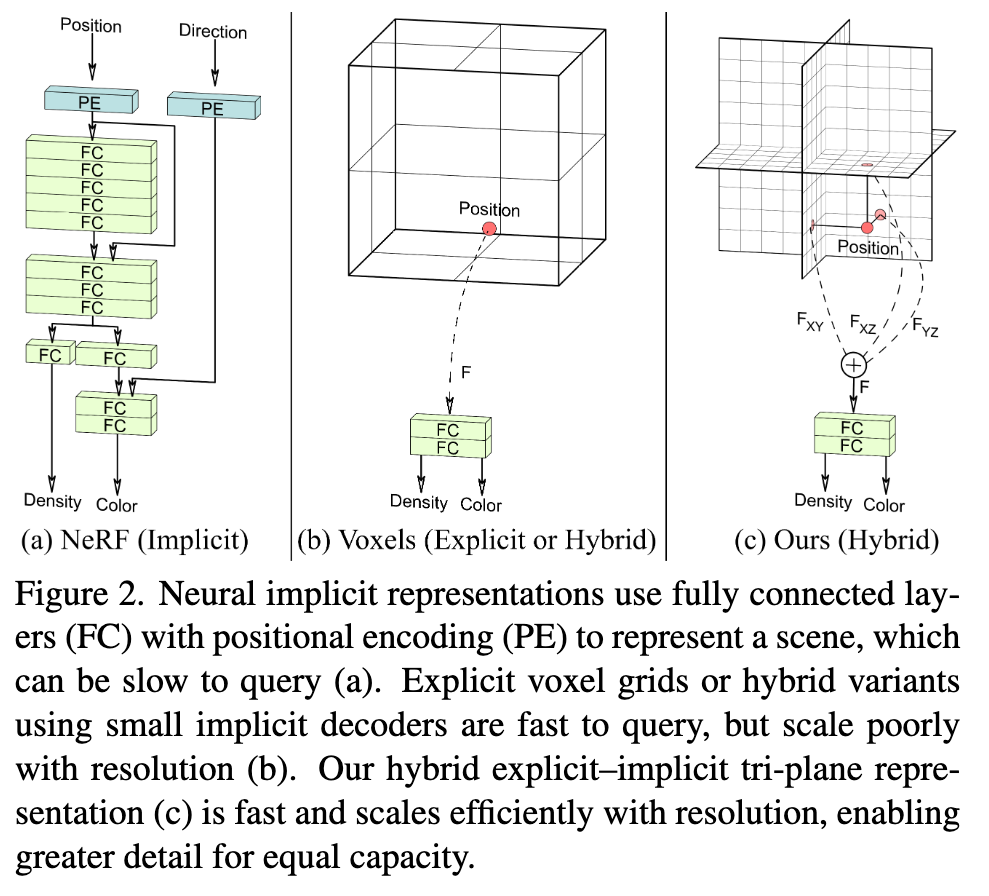
Explicit representations, such as discrete voxel grids (Fig. 2b), are fast to evaluate but often incur heavy memory overheads, making them difficult to scale to high resolutions or complex scenes (p. 2) In practice, these implicit architectures use large fully connected net- works that are slow to evaluate as each query requires a full pass through the network. (p. 2)
Mesh-based approaches build on the most popular primitives used in computer graphics, but lack the expressiveness needed for high-fidelity image generation (p. 3) Voxel-based GANs directly extend the CNN generators used in 2D settings to 3D [14, 21, 47, 48, 68, 74]. The high memory requirements of voxel grids and the computational burden of 3D convolutions, however, make high- resolution 3D GAN training difficult. (p. 3) As an alternative, fully implicit representation networks have been proposed for 3D scene generation [4, 58], but these architectures are slow to query, which makes the GAN training inefficient, limiting the quality and resolution of generated images. (p. 3)
The central distinction between these and ours is that while StyleNeRF and CIPS-3D operate primarily in image-space, with less emphasis on the 3D representation, our method operates primarily in 3D. (p. 3)

Triplane Representation
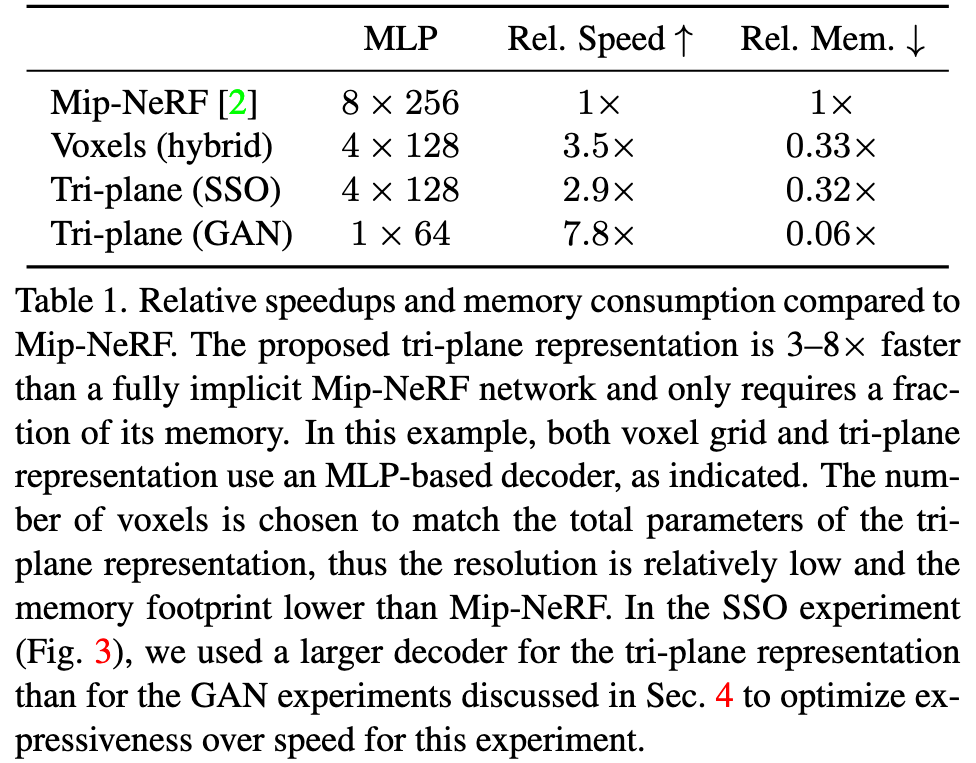
In the tri-plane formulation, we align our explicit features along three axis-aligned orthogonal feature planes, each with a resolution of N × N × C (Fig. 2c) with N being spatial resolution and C the number of channels. We query any 3D position x ∈ R3 by projecting it onto each of the three feature planes, retrieving the corresponding feature vector (Fxy, Fxz, Fyz) via bilinear interpolation, and aggregating the three feature vectors via summation. An additional lightweight decoder network, implemented as a small MLP, interprets the aggregated 3D features F as color and density. These quantities are rendered into RGB images using (neural) volume rendering (p. 3)
Computation cost is reduced by keeping the decoder small and shifting the bulk of the expressive power into the explicit features (p. 3)
3D GAN
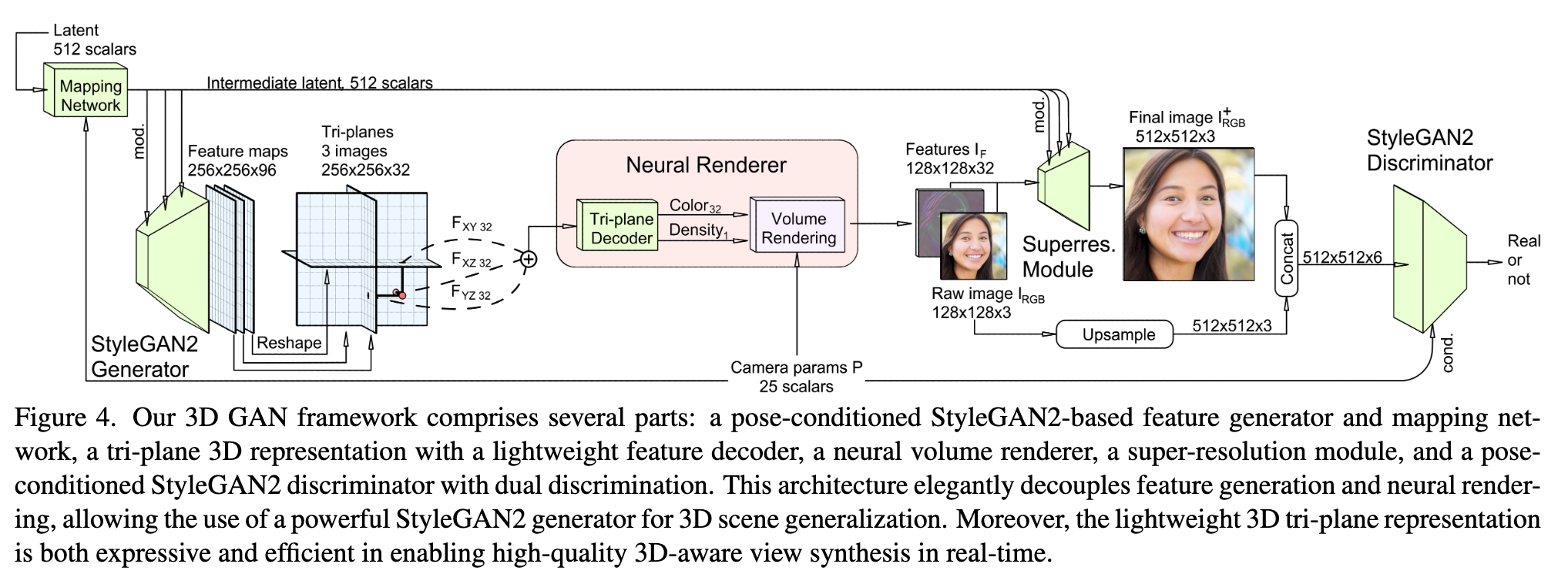
We associate each training image with a set of camera intrinsics and extrinsics using off-the-shelf pose detectors (p. 4)
The MLP does not use a positional encoding, coordinate inputs, or view- direction inputs. (p. 5). Volume rendering [41] is implemented using two-pass importance sampling as in [45]. Following [49], volume rendering in our GAN framework produces feature images, rather than RGB images, because feature images contain more information that can be effectively utilized for the image-space refinement described next. (p. 5). We use 96 total depth samples per ray (p. 5)
Super resolution: We thus perform volume rendering at a moderate resolution (e.g., 1282) and rely upon image-space convolutions to upsample the neural rendering to the final image size of 2562 or 5122 . Our super resolution module is composed of two blocks of StyleGAN2-modulated convolutional layers that upsam- ple and refine the 32-channel feature image IF into the final RGB image I+ RGB. (p. 5)
Dual discrimination
The real images fed into the discriminator are also processed by concatenating each of them with an appropriately blurred copy of itself. We discriminate over these six- channel images instead of the three-channel images traditionally seen in GAN discriminators. (p. 5). Dual discrimination not only encourages the final output to match the distribution of real images, but also offers additional effects: it encourages the neural rendering to match the distribution of downsampled real images; and it encourages the super-resolved images to be consistent with the neural rendering (p. 5)

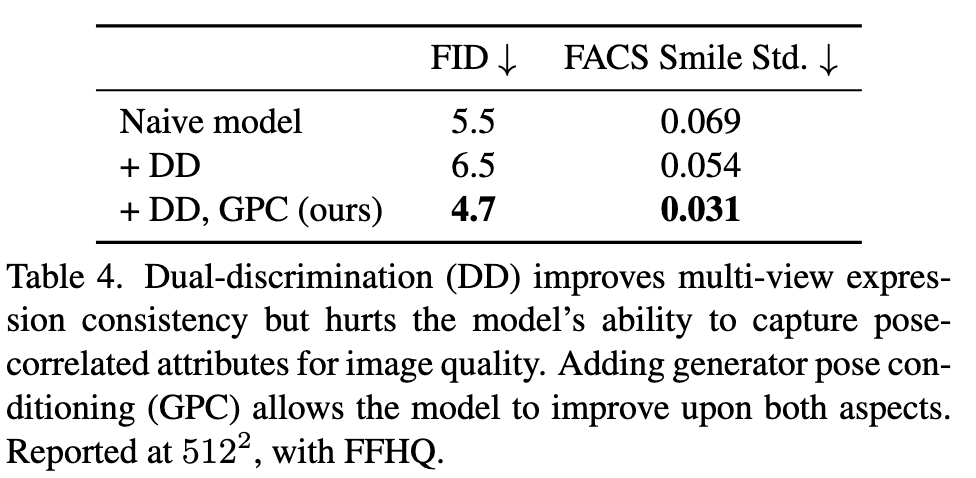
Without dual discrimination, generated images can include multi-view inconsistencies due to the unconstrained image-space super-resolution layers. We measure this effect quantitatively by extracting smile-related Facial ActionCoding System (FACS) [12] coefficients from videos produced by models with and without dual discrimination, using a proprietary facial tracker. We measure the standard deviation of smile coefficients for the same scene across video frames. A view-consistent scene should exhibit little expression shift and thus produce little variation in smile coefficients. This is validated in Table 4 showing that introducing dual discrimination (second row) reduces the smile coefficient variation versus the naive model (first row), indicating improved expression consistency. However, dual discrimination also reduces image quality as seen by the slightly worse FID score, perhaps because the model is restricted from reproducing the pose-correlated attribute biases in the FFHQ dataset. By adding generator pose conditioning (third row), we allow the generator to faithfully model pose-correlated attributes while decoupling them at inference, leading to both the best FID score and view-consistent results. (p. 7)
Pose
We introduce generator pose conditioning as a means to model and decouple correlations between pose and other (p. 5). To this end, we provide the backbone mapping network not only a latent code vector z, but also the camera parameters P as input, following the conditional generation strategy (p. 6)

Lifting StyleGAN [34], which represents scenes as a textured mesh, demonstrates consistent rendering quality.However the steep camera angles reveal inaccurate 3D geometry (e.g. foreshortened faces) learned by the method.π-GAN [5], reasonably extrapolates to steep angles but exhibits visible quality degradation at the edges of the pose distribution. GIRAFFE [29], being highly reliant on view-inconsistent convolutions, has difficulty reproducing angles that are rarely seen in the dataset. If we force GIRAFFE to extrapolate beyond the camera poses sampled at train-ing (e.g. the leftmost and rightmost images of Fig. 5b), we receive degraded, view-inconsistent images rather than renderings from steeper angles. (p. 3)
Our method, despite also using 2D convolutions, is less reliant on view-inconsistent convolutions for considering the placement of features in the final image. By utilizing an expressive 3D representation as a “scaffold”, our method provides more reasonable extrapolation to rare views in both pitch and yaw than methods that more strongly depend on image-space convolutions for image synthesis, such asGIRAFFE [29]. (p. 3)
Experiment Results


Limitations and future work.
Although our shapes show significant improvements over those generated by previous3D-aware GANs, they may still contain artifacts and lack finer details, such as individual teeth. To further improve the quality of the learned shapes, we could instill a stronger geometry prior or regularize the density component of the radiance field following methods proposed by [51, 67, 69].Our model requires knowledge of the camera pose distribution of the dataset. Although prior work has proposed learning the pose distribution on the fly [49], others have noticed such methods can diverge [18], so it would be fruitful to explore this direction further. Pose conditioning aids the generator in decoupling appearance from pose, but still does not fully disentangle the two. Furthermore, ambiguities that can be explained by geometry remain unresolved.For example, by creating concave eye sockets, the generator creates the illusion of eyes that “follow” the camera, an incorrect interpretation, though the renderings are view-consistent and reflect the underlying geometry. (p. 8)