An Early Evaluation of GPT-4V(ision)
[multimodal deep-learning dataset gpt-4v image-caption vqa This is my reading note for An Early Evaluation of GPT-4V(ision). The highlights of our findings are as follows:
- GPT-4V exhibits impressive performance on English visual-centric benchmarks but fails to recognize simple Chinese texts in the images;
- GPT-4V shows inconsistent refusal behavior when answering questions related to sensitive traits such as gender, race, and age;
- GPT-4V obtains worse results than GPT-4 (API) on language understanding tasks including general language understanding benchmarks and visual commonsense knowledge evaluation benchmarks;
- Few-shot prompting can improve GPT-4V’s performance on both visual understanding and language understanding;
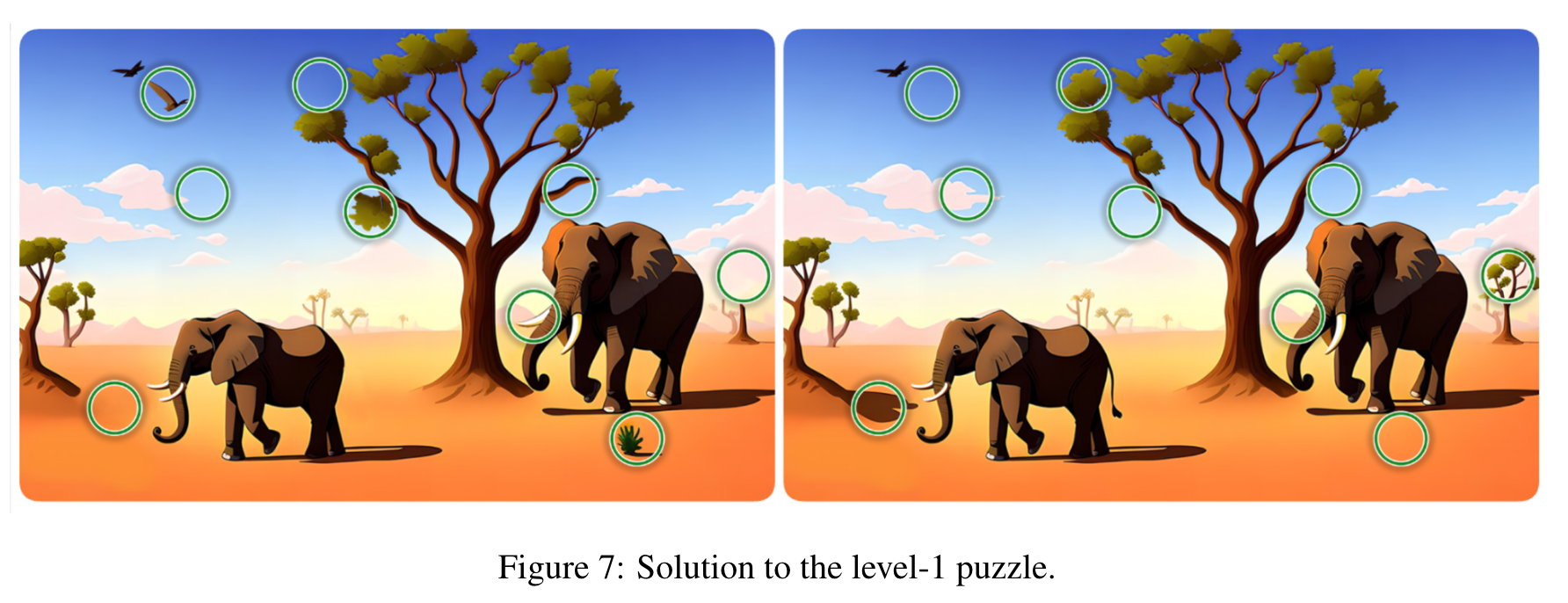
- GPT-4V struggles to find the nuances between two similar images and solve the easy math picture puzzles;
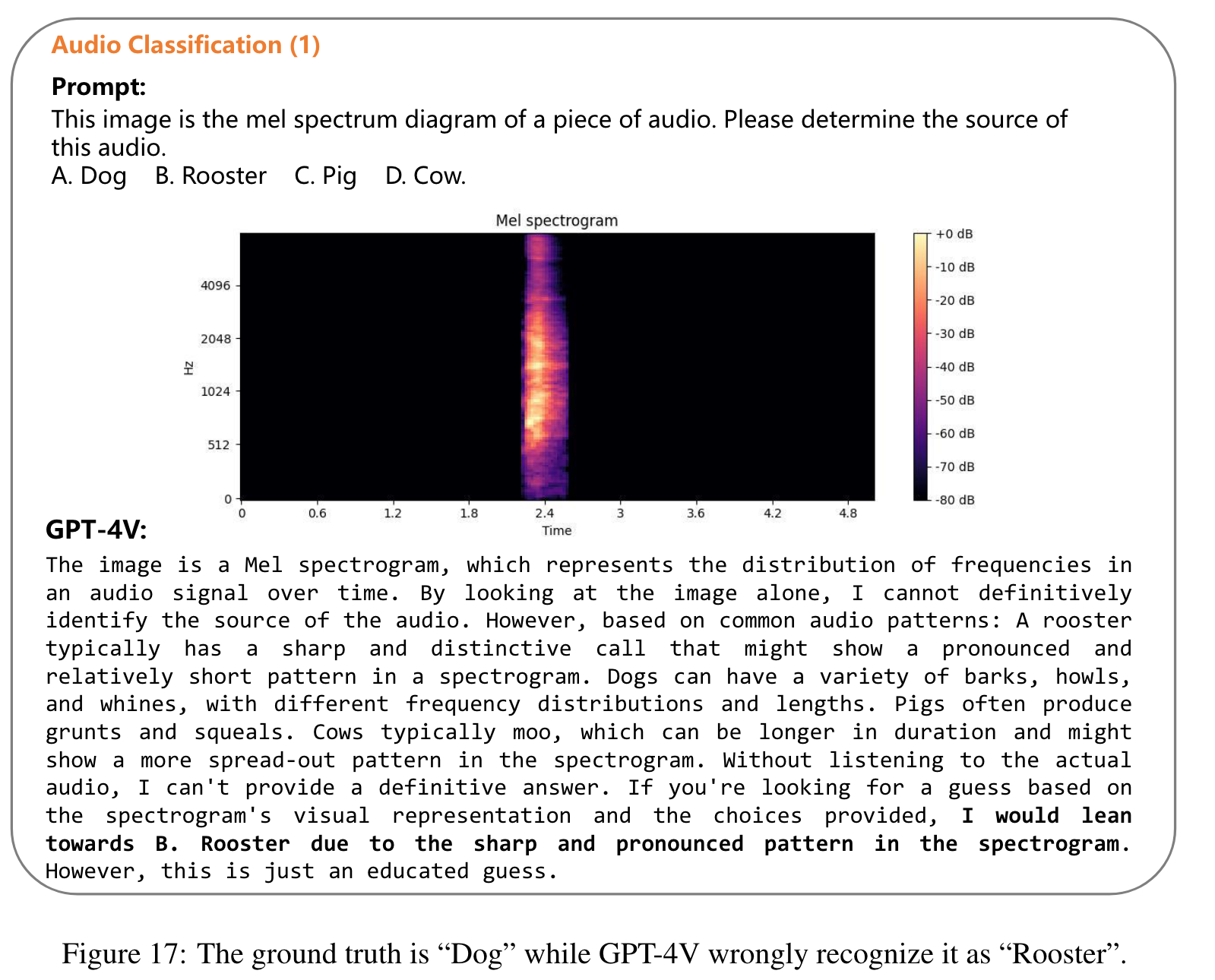
- GPT-4V shows non-trivial performance on the tasks of similar modalities to image, such as video and thermal. O (p. 1)
The current version of GPT-4V does not support interleaved images and texts and can only accept a maximum of four images. These constraints limit the design space of prompts. (p. 2)








Written on October 3, 2023