My Paper Reading List For Facial Landmark Detection
[face landmark-detection head-pose deep-learning Facial landmark detection is the task of detecting key landmarks on the face and tracking them (being robust to rigid and non-rigid facial deformations due to head movements and facial expressions).

The follow papers are ordered by year (new to old) and the performanced achieved on the benchmark (high to low).
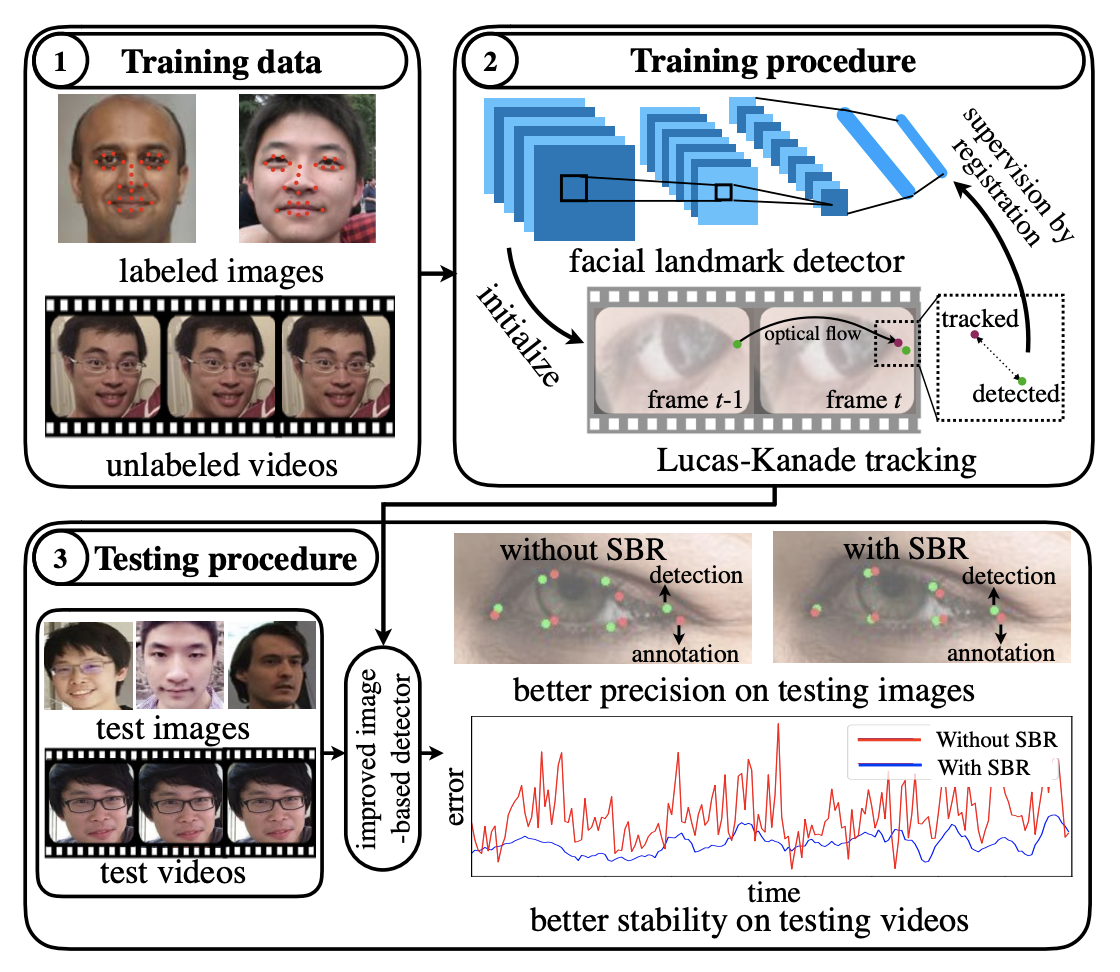
Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors
In this paper, we present supervision-by-registration, an unsupervised approach to improve the precision of facial landmark detectors on both images and video. Our key observation is that the detections of the same landmark in adjacent frames should be coherent with registration, i.e., optical flow. Interestingly, the coherency of optical flow is a source of supervision that does not require manual labeling, and can be leveraged during detector training. For example, we can enforce in the training loss function that a detected landmark at framet−1 followed by optical flow tracking from framet−1 to framet should coincide with the location of the detection at framet. Essentially, supervision-by-registration augments the training loss function with a registration loss, thus training the detector to have output that is not only close to the annotations in labeled images, but also consistent with registration on large amounts of unlabeled videos. End-to-end training with the registration loss is made possible by a differentiable Lucas-Kanade operation, which computes optical flow registration in the forward pass, and back-propagates gradients that encourage temporal coherency in the detector. The output of our method is a more precise image-based facial landmark detector, which can be applied to single images or video. With supervision-by-registration, we demonstrate (1) improvements in facial landmark detection on both images (300W, ALFW) and video (300VW, Youtube-Celebrities), and (2) significant reduction of jittering in video detections.
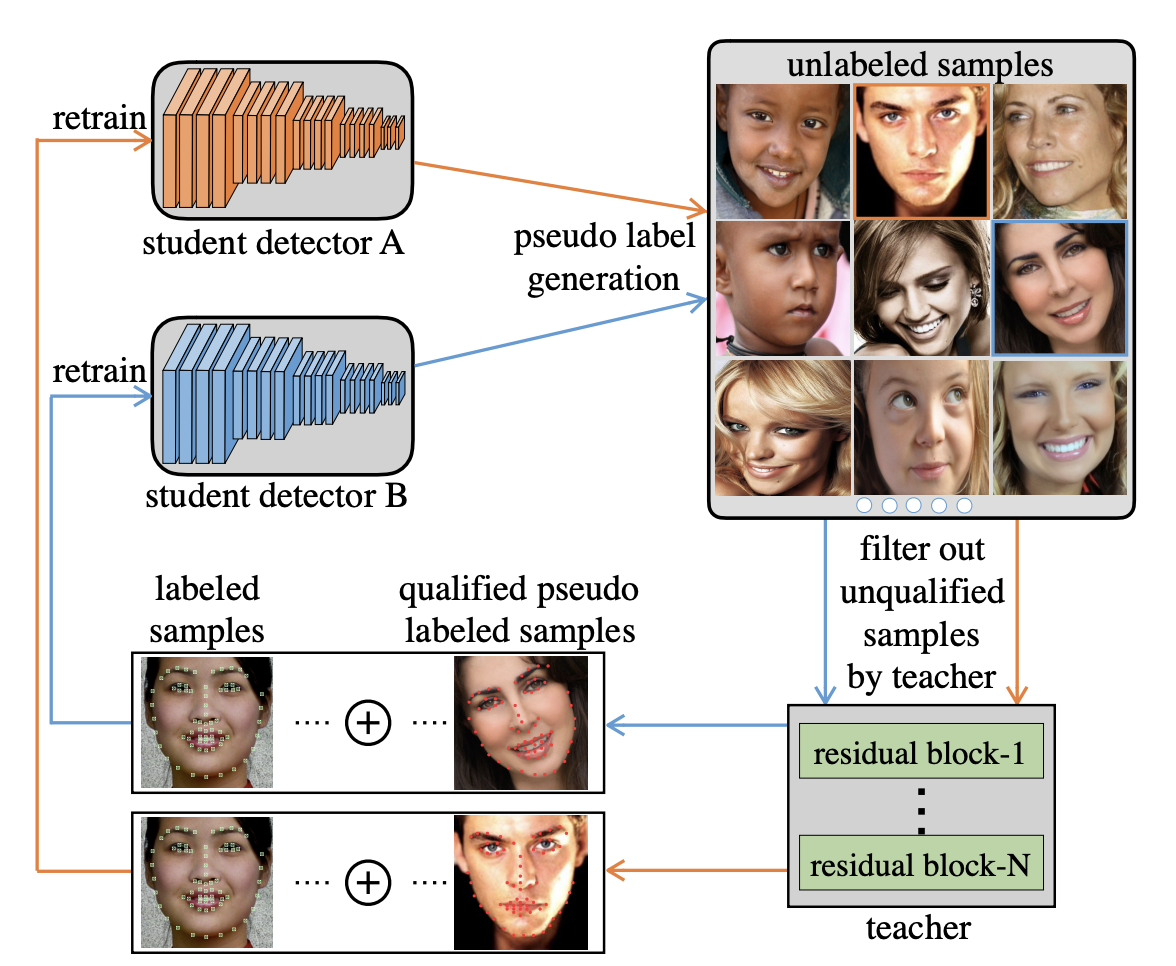
Teacher Supervises Students How to Learn From Partially Labeled Images for Facial Landmark Detection
Facial landmark detection aims to localize the anatomically defined points of human faces. In this paper, we study facial landmark detection from partially labeled facial images. A typical approach is to (1) train a detector on the labeled images; (2) generate new training samples using this detector’s prediction as pseudo labels of unlabeled images; (3) retrain the detector on the labeled samples and partial pseudo labeled samples. In this way, the detector can learn from both labeled and unlabeled data to become robust. In this paper, we propose an interaction mechanism between a teacher and two students to generate more reliable pseudo labels for unlabeled data, which are beneficial to semi-supervised facial landmark detection. Specifically, the two students are instantiated as dual detectors. The teacher learns to judge the quality of the pseudo labels generated by the students and filter out unqualified samples before the retraining stage. In this way, the student detectors get feedback from their teacher and are retrained by premium data generated by itself. Since the two students are trained by different samples, a combination of their predictions will be more robust as the final prediction compared to either prediction. Extensive experiments on 300-W and AFLW benchmarks show that the interactions between teacher and students contribute to better utilization of the unlabeled data and achieves state-of-the-art performance.
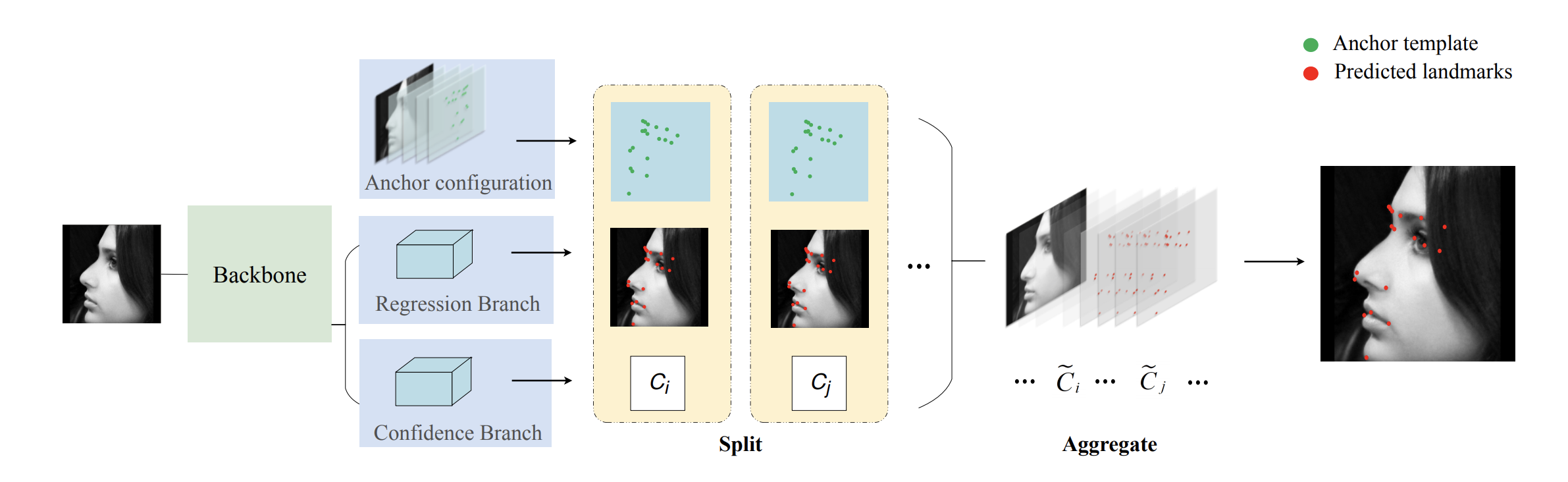
AnchorFace: An Anchor-based Facial Landmark Detector Across Large Poses
Facial landmark localization aims to detect the predefined points of human faces, and the topic has been rapidly improved with the recent development of neural network based methods. However, it remains a challenging task when dealing with faces in unconstrained scenarios, especially with large pose variations. In this paper, we target the problem of facial landmark localization across large poses and address this task based on a split-and-aggregate strategy. To split the search space, we propose a set of anchor templates as references for regression, which well addresses the large variations of face poses. Based on the prediction of each anchor template, we propose to aggregate the results, which can reduce the landmark uncertainty due to the large poses. Overall, our proposed approach, named AnchorFace, obtains state-of-the-art results with extremely efficient inference speed on four challenging benchmarks, i.e. AFLW, 300W, Menpo, and WFLW dataset. Code will be available at https://github.com/nothingelse92/AnchorFace.
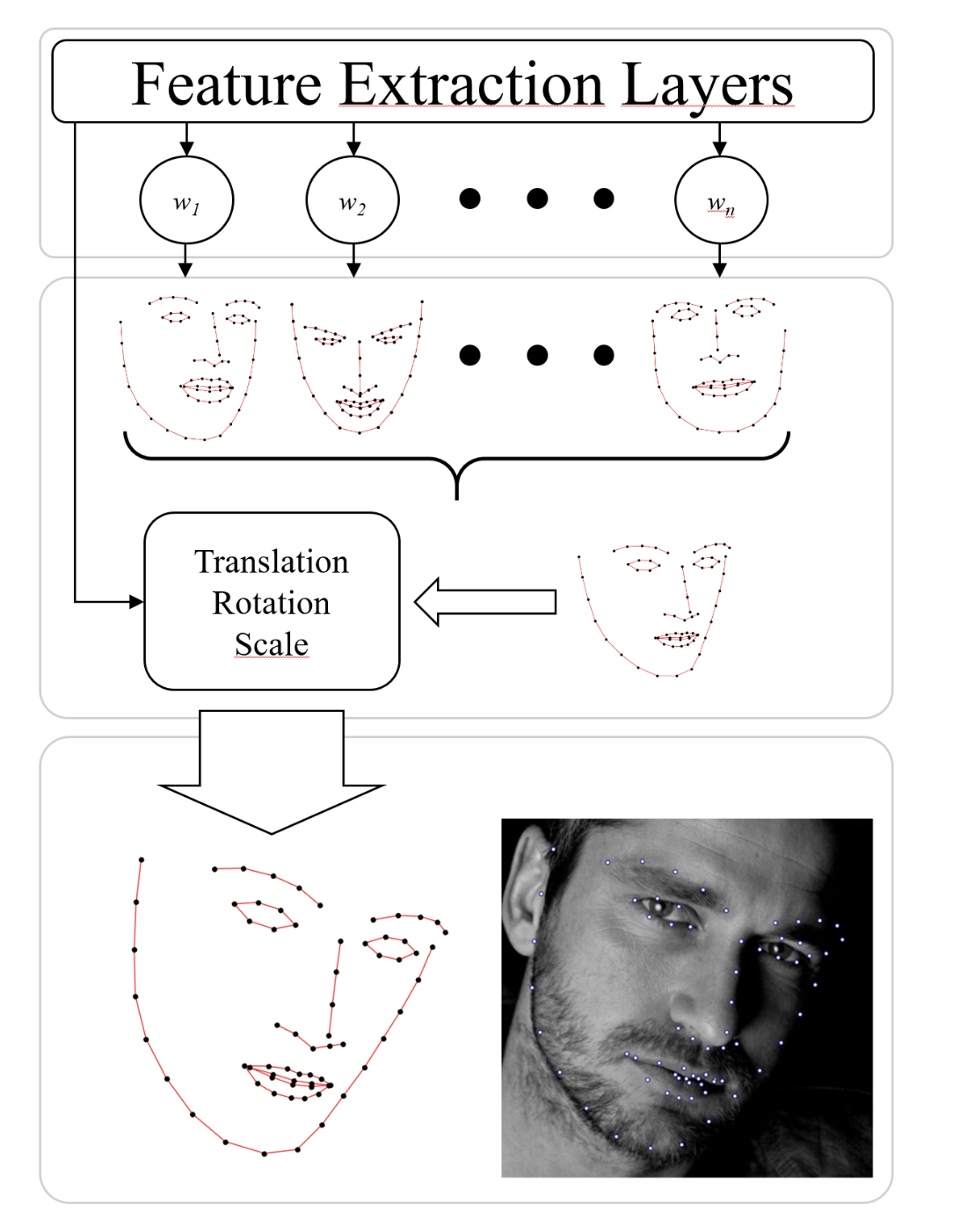
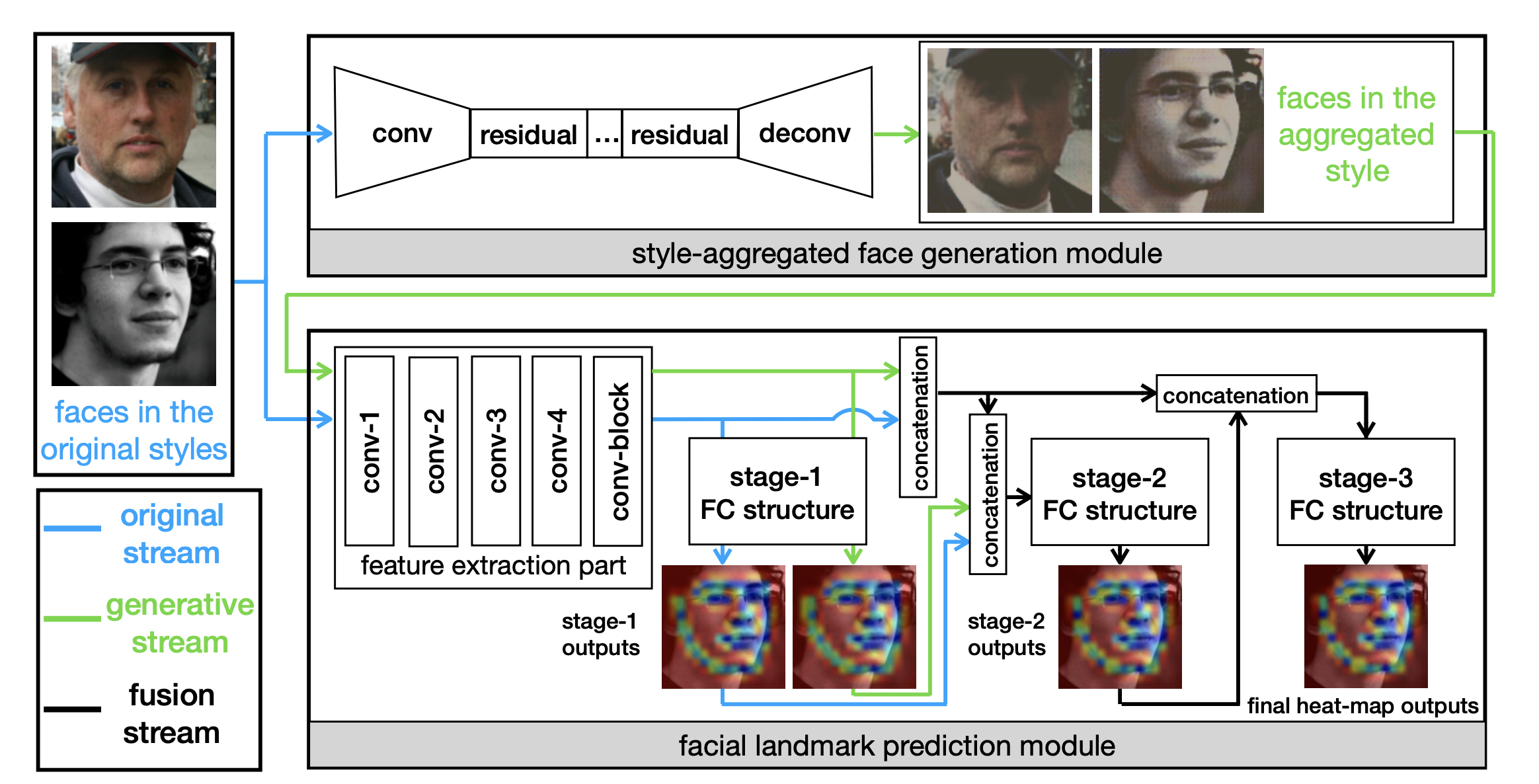
Style Aggregated Network for Facial Landmark Detection
Recent advances in facial landmark detection achieve success by learning discriminative features from rich deformation of face shapes and poses. Besides the variance of faces themselves, the intrinsic variance of image styles, e.g., grayscale vs. color images, light vs. dark, intense vs. dull, and so on, has constantly been overlooked. This issue becomes inevitable as increasing web images are collected from various sources for training neural networks. In this work, we propose a style-aggregated approach to deal with the large intrinsic variance of image styles for facial landmark detection. Our method transforms original face images to style-aggregated images by a generative adversarial module. The proposed scheme uses the style-aggregated image to maintain face images that are more robust to environmental changes. Then the original face images accompanying with style-aggregated ones play a duet to train a landmark detector which is complementary to each other. In this way, for each face, our method takes two images as input, i.e., one in its original style and the other in the aggregated style. In experiments, we observe that the large variance of image styles would degenerate the performance of facial landmark detectors. Moreover, we show the robustness of our method to the large variance of image styles by comparing to a variant of our approach, in which the generative adversarial module is removed, and no style-aggregated images are used. Our approach is demonstrated to perform well when compared with state-of-the-art algorithms on benchmark datasets AFLW and 300-W. Code is publicly available on GitHub: https://github.com/D-X-Y/SAN
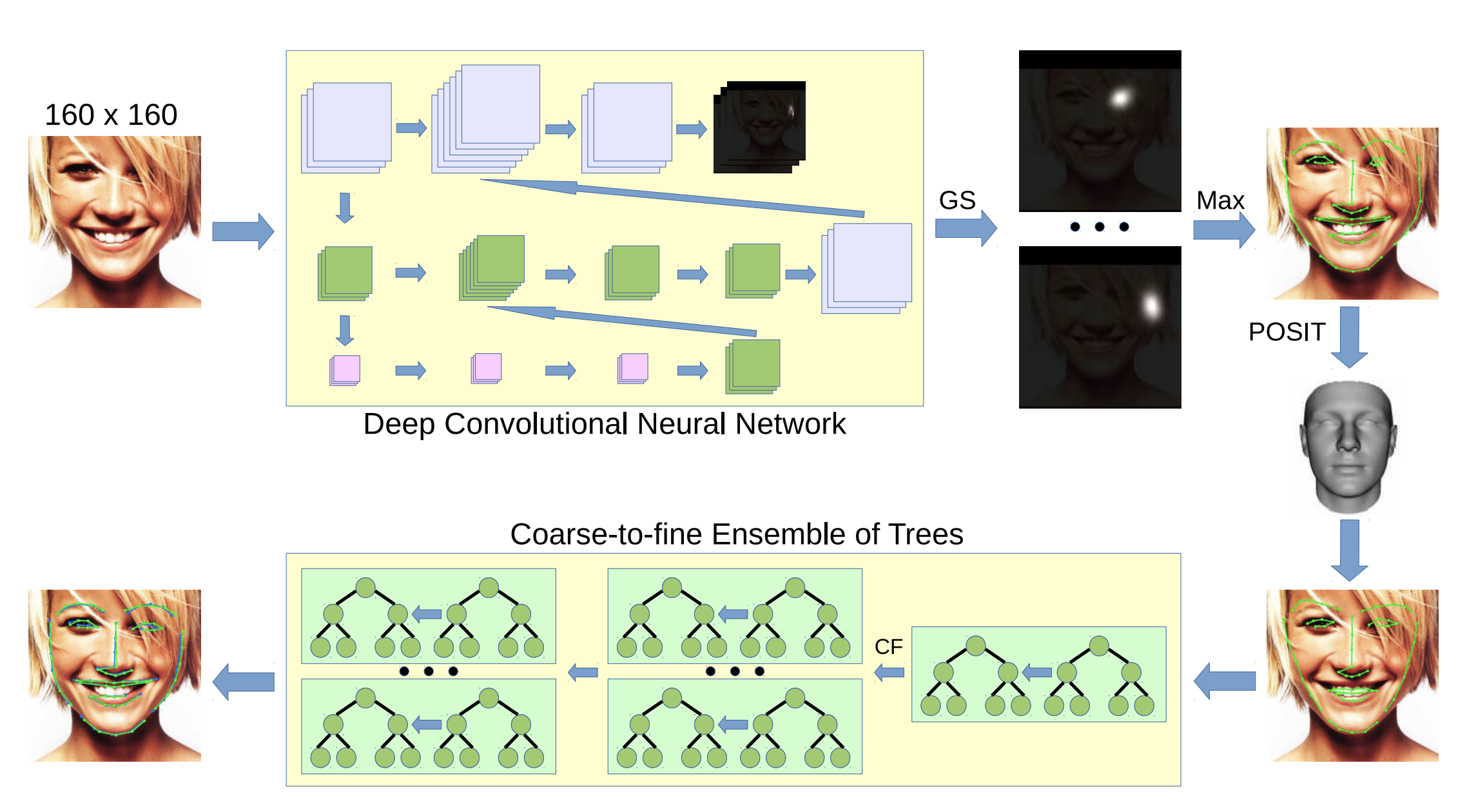
A Deeply-initialized Coarse-to-fine Ensemble of Regression Trees for Face Alignment
In this paper we present DCFE, a real-time facial landmark regression method based on a coarse-to-fine Ensemble of Regression Trees (ERT). **We use a simple Convolutional Neural Network (CNN) to generate probability maps of landmarks location. These are further refined with the ERT regressor, which is initialized by fitting a 3D face model to the landmark maps. **The coarse-to-fine structure of the ERT lets us address the combinatorial explosion of parts deformation. With the 3D model we also tackle other key problems such as robust regressor initialization, self occlusions, and simultaneous frontal and profile face analysis. In the experiments DCFE achieves the best reported result in AFLW, COFW, and 300W private and common public data sets.
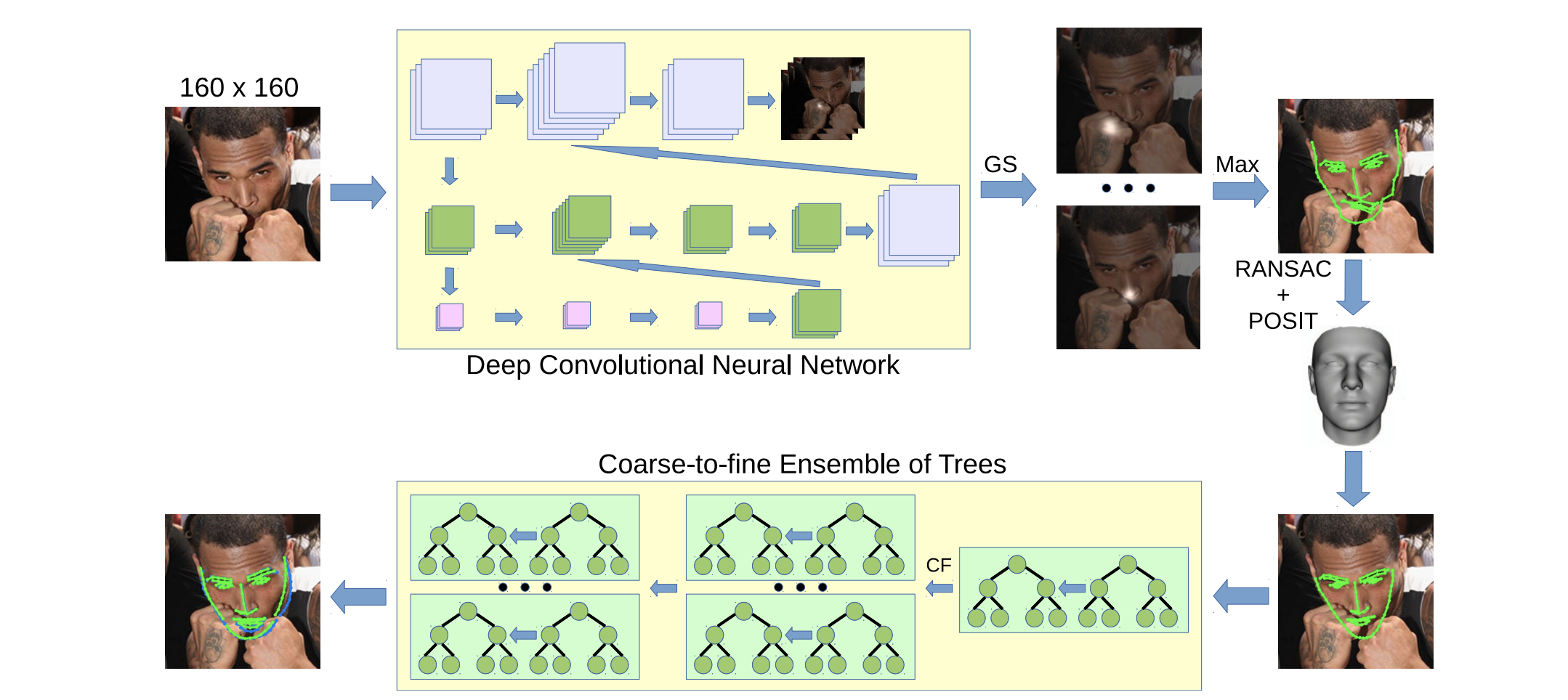
A follow up paper:
Face Alignment using a 3D Deeply-initialized Ensemble of Regression Trees
Face alignment algorithms locate a set of landmark points in images of faces taken in unrestricted situations. State-of-the-art approaches typically fail or lose accuracy in the presence of occlusions, strong deformations, large pose variations and ambiguous configurations. In this paper we present 3DDE, a robust and efficient face alignment algorithm based on a coarse-to-fine cascade of ensembles of regression trees. It is initialized by robustly fitting a 3D face model to the probability maps produced by a convolutional neural network. With this initialization we address self-occlusions and large face rotations. Further, the regressor implicitly imposes a prior face shape on the solution, addressing occlusions and ambiguous face configurations. Its coarse-to-fine structure tackles the combinatorial explosion of parts deformation. In the experiments performed, 3DDE improves the state-of-the-art in 300W, COFW, AFLW and WFLW data sets. Finally, we perform cross-dataset experiments that reveal the existence of a significant data set bias in these benchmarks.
Cascade of Encoder-Decoder CNNs with Learned Coordinates Regressor for Robust Facial Landmarks Detection
Convolutional Neural Nets (CNNs) have become the reference technology for many computer vision problems. Although CNNs for facial landmark detection are very robust, they still lack accuracy when processing images acquired in unrestricted conditions. In this paper we investigate the use of a cascade of Neural Net regressors to increase the accuracy of the estimated facial landmarks. To this end we append two encoder-decoder CNNs with the same architecture. The first net produces a set of heatmaps with a rough estimation of landmark locations. The second, trained with synthetically generated occlusions, refines the location of ambiguous and occluded landmarks. Finally, a densely connected layer with shared weights among all heatmaps, accurately regresses the landmark coordinates. The proposed approach achieves state-of-the-art results in 300W, COFW and WFLW that are widely considered the most challenging public data sets.
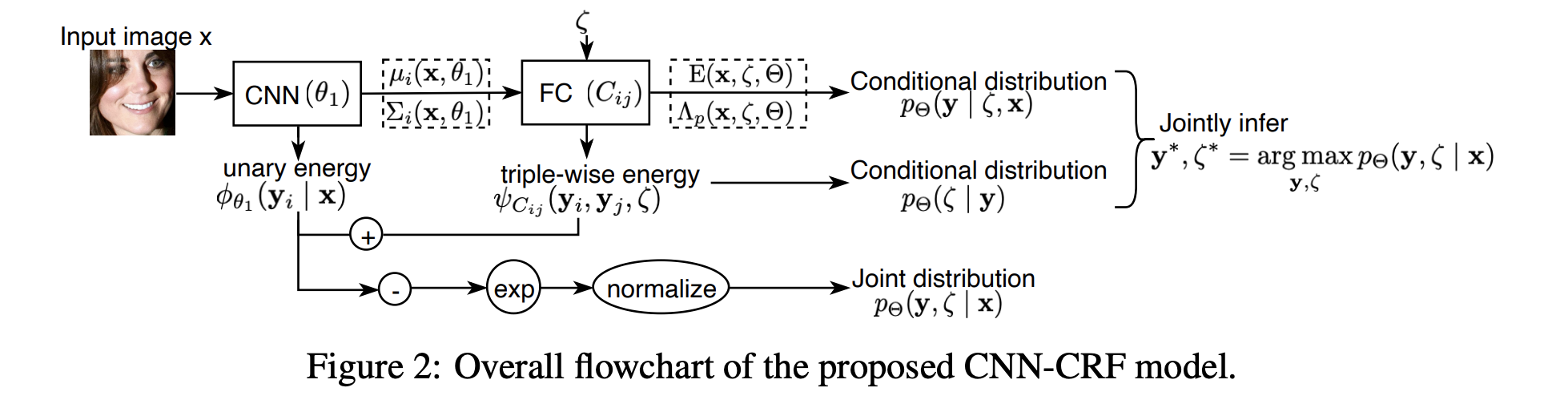
Deep Structured Prediction for Facial Landmark Detection
Existing deep learning based facial landmark detection methods have achieved excellent performance. These methods, however, do not explicitly embed the structural dependencies among landmark points. They hence cannot preserve the geometric relationships between landmark points or generalize well to challenging conditions or unseen data. This paper proposes a method for deep structured facial landmark detection based on combining a deep Convolutional Network with a Conditional Random Field. We demonstrate its superior performance to existing state-of-the-art techniques in facial landmark detection, especially a better generalization ability on challenging datasets that include large pose and occlusion.
Adaloss: Adaptive Loss Function for Landmark Localization
Landmark localization is a challenging problem in computer vision with a multitude of applications. Recent deep learning based methods have shown improved results by regressing likelihood maps instead of regressing the coordinates directly. However, setting the precision of these regression targets during the training is a cumbersome process since it creates a trade-off between trainability vs localization accuracy. Using precise targets introduces a significant sampling bias and hence makes the training more difficult, whereas using imprecise targets results in inaccurate landmark detectors. In this paper, we introduce “Adaloss”, an objective function that adapts itself during the training by updating the target precision based on the training statistics. This approach does not require setting problem-specific parameters and shows improved stability in training and better localization accuracy during inference. We demonstrate the effectiveness of our proposed method in three different applications of landmark localization: 1) the challenging task of precisely detecting catheter tips in medical X-ray images, 2) localizing surgical instruments in endoscopic images, and 3) localizing facial features on in-the-wild images where we show state-of-the-art results on the 300-W benchmark dataset.
Face Alignment Across Large Poses: A 3D Solution
Face alignment, which fits a face model to an image and extracts the semantic meanings of facial pixels, has been an important topic in CV community. However, most algorithms are designed for faces in small to medium poses (below 45 degree), lacking the ability to align faces in large poses up to 90 degree. The challenges are three-fold: Firstly, the commonly used landmark-based face model assumes that all the landmarks are visible and is therefore not suitable for profile views. Secondly, the face appearance varies more dramatically across large poses, ranging from frontal view to profile view. Thirdly, labelling landmarks in large poses is extremely challenging since the invisible landmarks have to be guessed. In this paper, we propose a solution to the three problems in an new alignment framework, called 3D Dense Face Alignment (3DDFA), in which a dense 3D face model is fitted to the image via convolutional neutral network (CNN). We also propose a method to synthesize large-scale training samples in profile views to solve the third problem of data labelling. Experiments on the challenging AFLW database show that our approach achieves significant improvements over state-of-the-art methods.
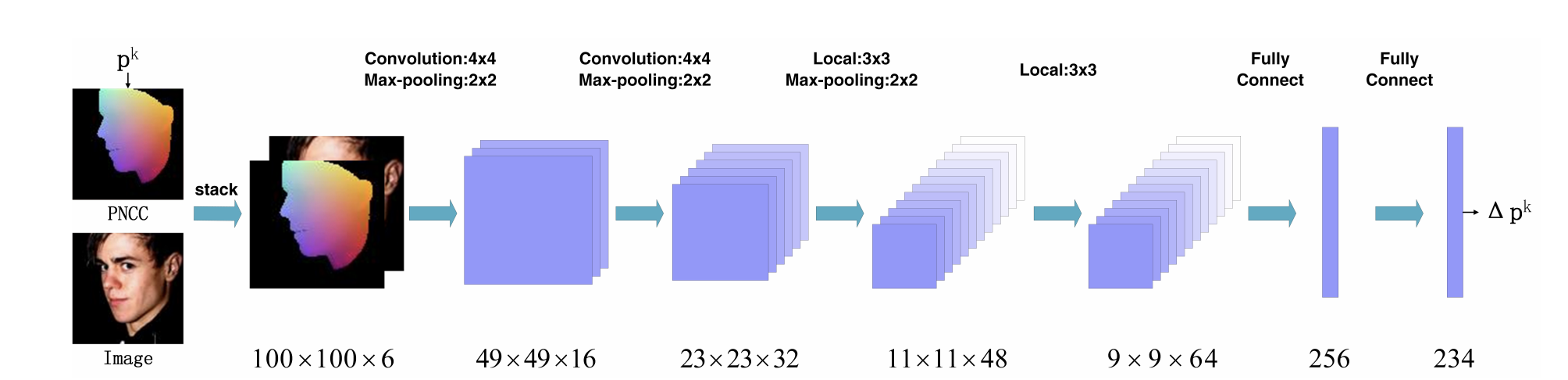
Pose-Invariant Face Alignment with a Single CNN
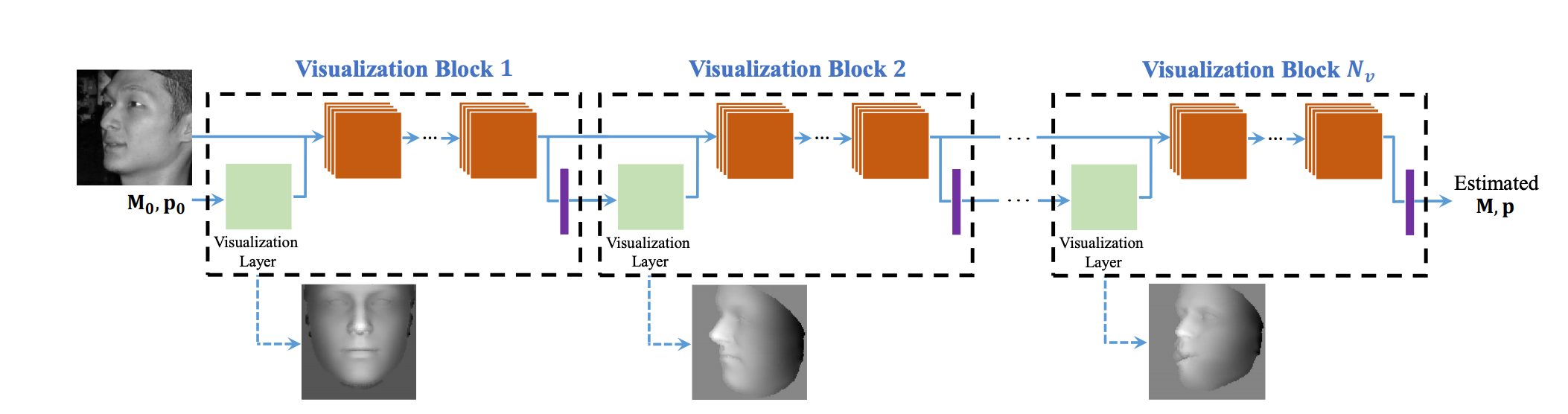
Face alignment has witnessed substantial progress in the last decade. One of the recent focuses has been aligning a dense 3D face shape to face images with large head poses. The dominant technology used is based on the cascade of regressors, e.g., CNN, which has shown promising results. Nonetheless, the cascade of CNNs suffers from several drawbacks, e.g., lack of end-to-end training, hand-crafted features and slow training speed. To address these issues, we propose a new layer, named visualization layer, that can be integrated into the CNN architecture and enables joint optimization with different loss functions. Extensive evaluation of the proposed method on multiple datasets demonstrates state-of-the-art accuracy, while reducing the training time by more than half compared to the typical cascade of CNNs. In addition, we compare multiple CNN architectures with the visualization layer to further demonstrate the advantage of its utilization.
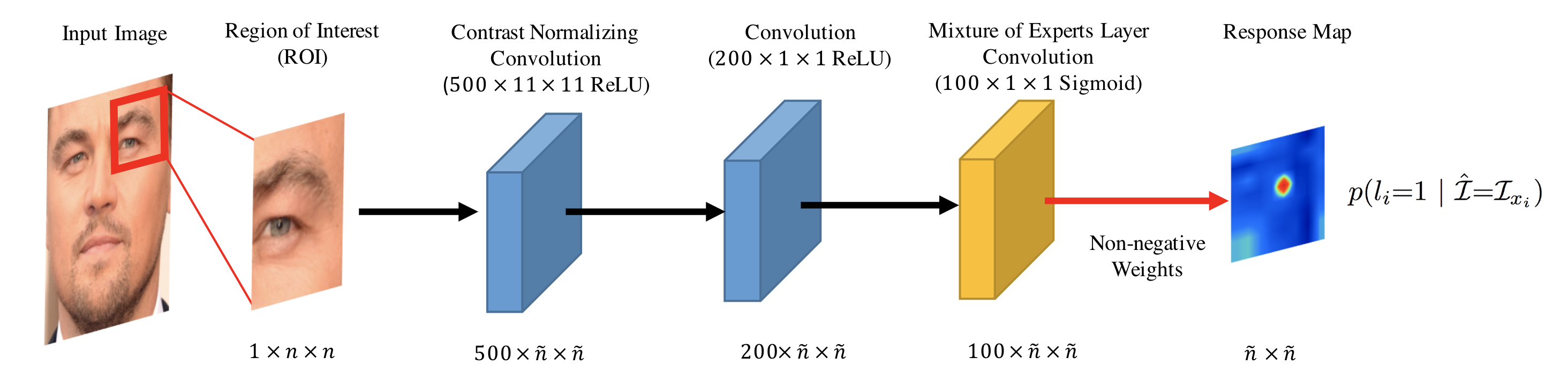
Convolutional Experts Constrained Local Model for Facial Landmark Detection
Constrained Local Models (CLMs) are a well-established family of methods for facial landmark detection. However, they have recently fallen out of favor to cascaded regression-based approaches. This is in part due to the inability of existing CLM local detectors to model the very complex individual landmark appearance that is affected by expression, illumination, facial hair, makeup, and accessories. In our work, we present a novel local detector – Convolutional Experts Network (CEN) – that brings together the advantages of neural architectures and mixtures of experts in an end-to-end framework. We further propose a Convolutional Experts Constrained Local Model (CE-CLM) algorithm that uses CEN as local detectors. We demonstrate that our proposed CE-CLM algorithm outperforms competitive state-of-the-art baselines for facial landmark detection by a large margin on four publicly-available datasets. Our approach is especially accurate and robust on challenging profile images.
Fast Localization of Facial Landmark Points
Localization of salient facial landmark points, such as eye corners or the tip of the nose, is still considered a challenging computer vision problem despite recent efforts. This is especially evident in unconstrained environments, i.e., in the presence of background clutter and large head pose variations. Most methods that achieve state-of-the-art accuracy are slow, and, thus, have limited applications. We describe a method that can accurately estimate the positions of relevant facial landmarks in real-time even on hardware with limited processing power, such as mobile devices. This is achieved with a sequence of estimators based on ensembles of regression trees. The trees use simple pixel intensity comparisons in their internal nodes and this makes them able to process image regions very fast. We test the developed system on several publicly available datasets and analyse its processing speed on various devices. Experimental results show that our method has practical value.
PFLD: A Practical Facial Landmark Detector
Being accurate, efficient, and compact is essential to a facial landmark detector for practical use. To simultaneously consider the three concerns, this paper investigates a neat model with promising detection accuracy under wild environments e.g., unconstrained pose, expression, lighting, and occlusion conditions) and super real-time speed on a mobile device. More concretely, we customize an end-to-end single stage network associated with acceleration techniques. During the training phase, for each sample, rotation information is estimated for geometrically regularizing landmark localization, which is then NOT involved in the testing phase. A novel loss is designed to, besides considering the geometrical regularization, mitigate the issue of data imbalance by adjusting weights of samples to different states, such as large pose, extreme lighting, and occlusion, in the training set. Extensive experiments are conducted to demonstrate the efficacy of our design and reveal its superior performance over state-of-the-art alternatives on widely-adopted challenging benchmarks, i.e., 300W (including iBUG, LFPW, AFW, HELEN, and XM2VTS) and AFLW. Our model can be merely 2.1Mb of size and reach over 140 fps per face on a mobile phone (Qualcomm ARM 845 processor) with high precision, making it attractive for large-scale or real-time applications. We have made our practical system based on PFLD 0.25X model publicly available at \url{http://sites.google.com/view/xjguo/fld} for encouraging comparisons and improvements from the community.\
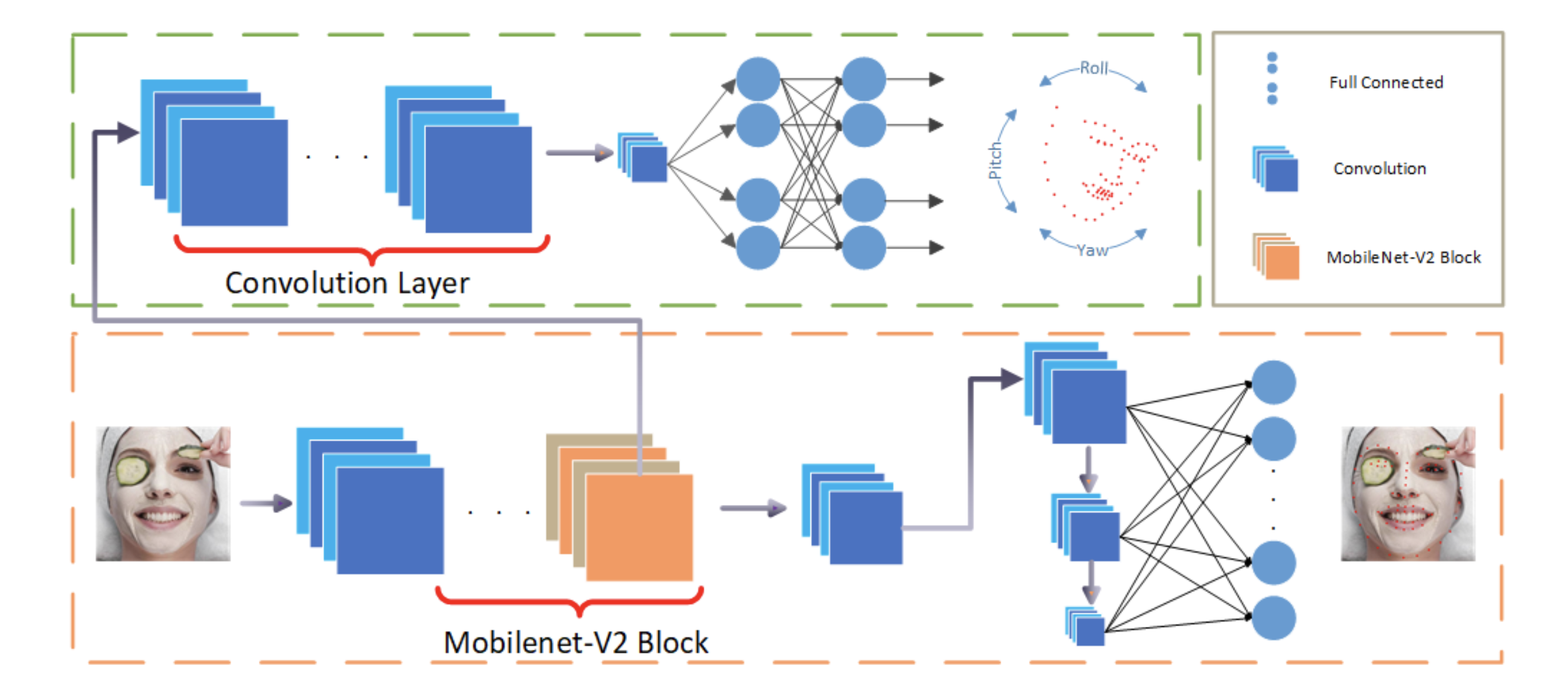
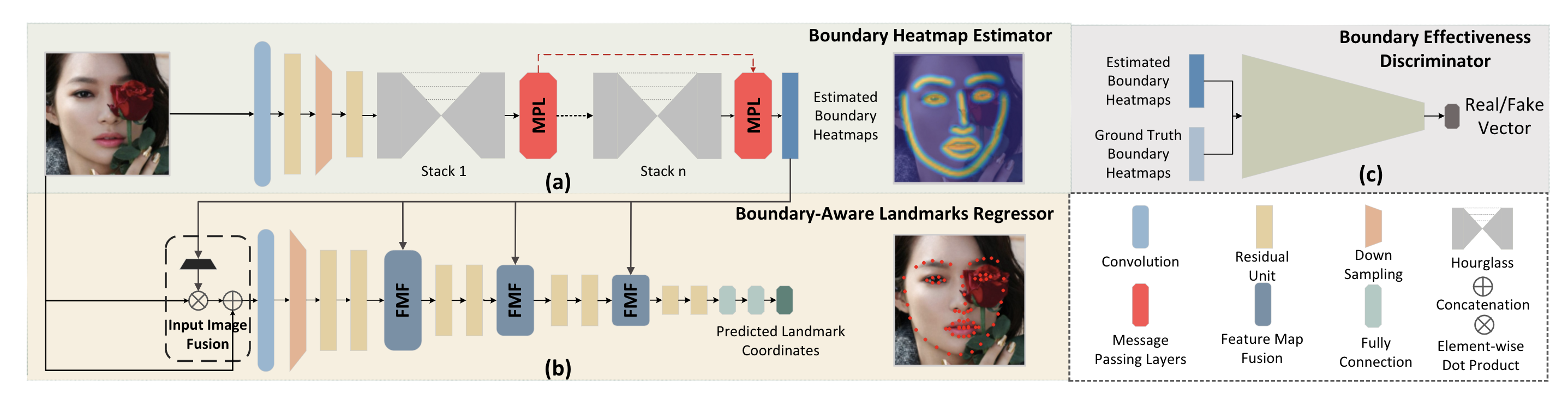
Look at Boundary: A Boundary-Aware Face Alignment Algorithm
We present a novel boundary-aware face alignment algorithm by utilising boundary lines as the geometric structure of a human face to help facial landmark localisation. Unlike the conventional heatmap based method and regression based method, our approach derives face landmarks from boundary lines which remove the ambiguities in the landmark definition. Three questions are explored and answered by this work: 1. Why using boundary? 2. How to use boundary? 3. What is the relationship between boundary estimation and landmarks localisation? Our boundary- aware face alignment algorithm achieves 3.49% mean error on 300-W Fullset, which outperforms state-of-the-art methods by a large margin. Our method can also easily integrate information from other datasets. By utilising boundary information of 300-W dataset, our method achieves 3.92% mean error with 0.39% failure rate on COFW dataset, and 1.25% mean error on AFLW-Full dataset. Moreover, we propose a new dataset WFLW to unify training and testing across different factors, including poses, expressions, illuminations, makeups, occlusions, and blurriness. Dataset and model will be publicly available at https://wywu.github.io/projects/LAB/LAB.html
Super-realtime facial landmark detection and shape fitting by deep regression of shape model parameters
We present a method for highly efficient landmark detection that combines deep convolutional neural networks with well established model-based fitting algorithms. Motivated by established model-based fitting methods such as active shapes, we use a PCA of the landmark positions to allow generative modeling of facial landmarks. Instead of computing the model parameters using iterative optimization, the PCA is included in a deep neural network using a novel layer type. The network predicts model parameters in a single forward pass, thereby allowing facial landmark detection at several hundreds of frames per second. Our architecture allows direct end-to-end training of a model-based landmark detection method and shows that deep neural networks can be used to reliably predict model parameters directly without the need for an iterative optimization. The method is evaluated on different datasets for facial landmark detection and medical image segmentation. PyTorch code is freely available at https://github.com/justusschock/shapenet