FineRecon Depth-aware Feed-forward Network for Detailed 3D Reconstruction
[signed-distance-function sfm struction-from-motion nerf sdf deep-learning voxel 3d This is my reading note for FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction. It proposes a high detail surface reconstruction algorithm based voxel volume and multi-view geometry. Two major novelties: improve reconstruction accuracy using a novel MVS depth-guidance strategy and enable the reconstruction of sub-voxel detail with a novel TSDF prediction architecture that can be queriedat any 3D point, using point back-projected fine-grained image features.

Introduction
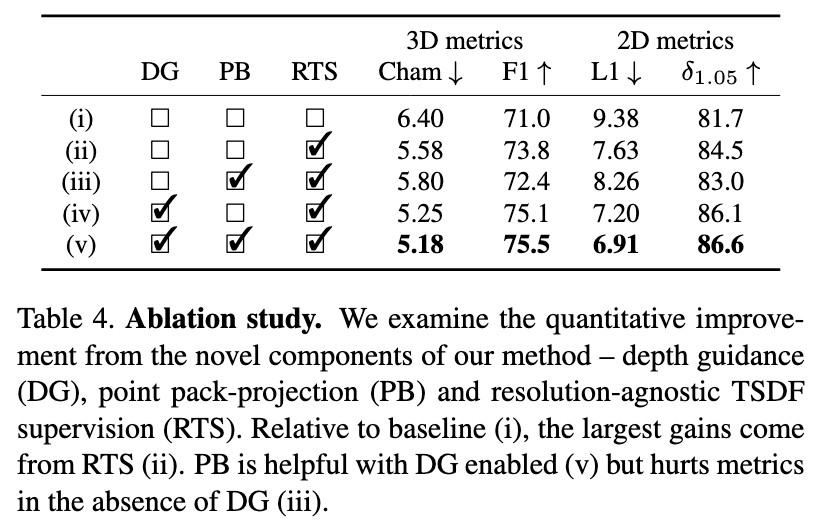
However, the reconstructed geometry, typically represented as a 3D truncated signed distance function (TSDF), is often coarse without fine geometric details. To address this problem, we propose three effective solutions for improving the fidelity of inference-based 3D reconstructions. We first present a resolution-agnostic TSDF supervision strategy to provide the network with a more accurate learning signal during training, avoiding the pitfalls of TSDF interpolation seen in previous work.
We then introduce a depth guidance strategy using multiview depth estimates to enhance the scene representation and recover more accurate surfaces. Finally, we develop a novel architecture for the final layers of the network, conditioning the output TSDF prediction on high-resolution image features in addition to coarse voxel features, enabling sharper reconstruction of fine details. (p. 1)
Limitation of existing work:
- However, resampling via tri-linear interpolation corrupts detail in the training data, because distance fields are not linear when non-planar geometry such a corner is present, as shown in Fig. 3. We avoid this issue by making supervised predictions only at the exact points where the ground-truth TSDF is known. (p. 2)
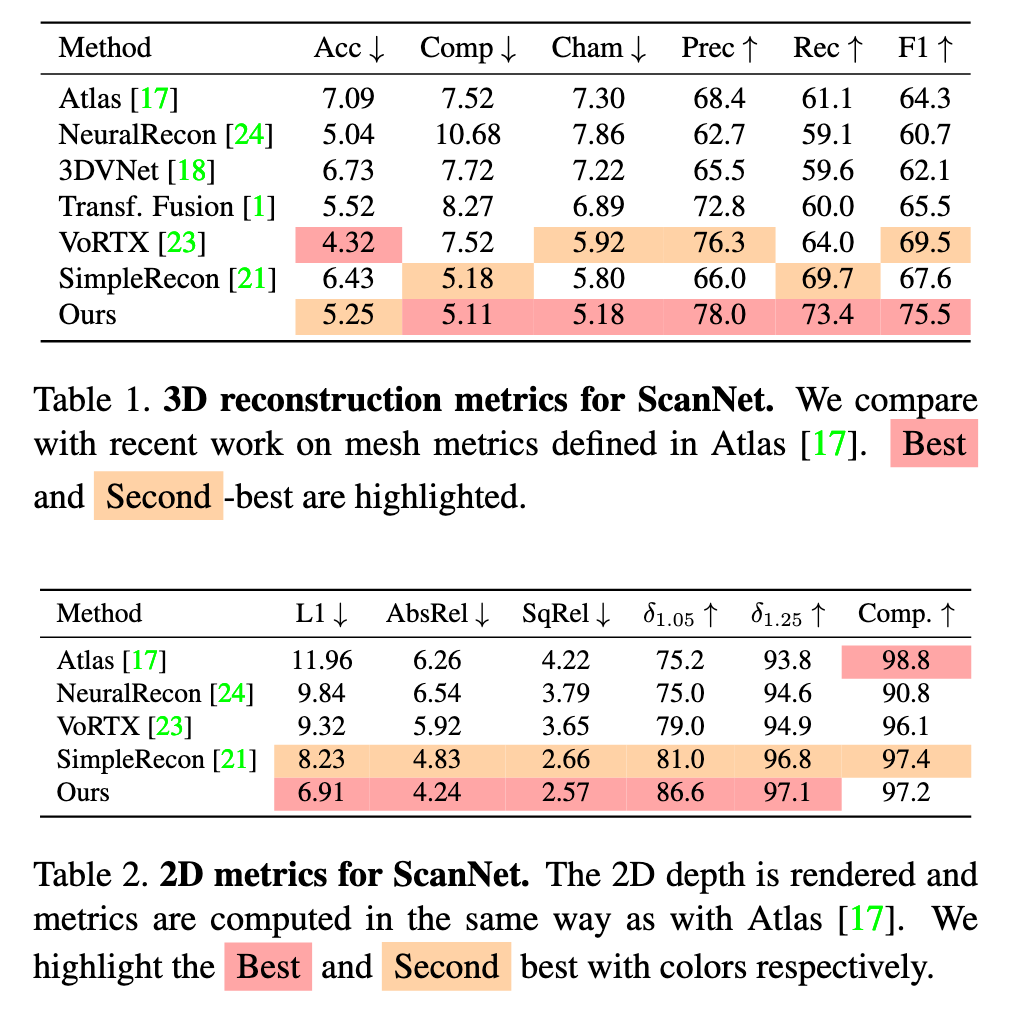
- Second, prior work [1, 2, 17, 23, 24] uses dense backprojection, sampling a feature from each input image in each voxel. This causes blurring in the back-projection volume, which increases the difficulty of extracting accurate surface locations. To address this, our method uses an initial multi-view stereo depth estimation step, after which the depth estimates are used to enhance the feature volume and guide the 3D CNN toward areas of high surface likelihood. We show that this step significantly increases the quality of the reconstructions produced by our system. (p. 2)
- Third, because of the high computational cost of 3D CNNs, it is expensive to increase the voxel resolution. Existing works use voxel sizes of 4cm or larger [1, 2, 17, 23, 24], which is not enough to resolve the level of geometric detail visible in natural images at ranges of a few meters. To remedy this, we propose a new method to query the TSDF prediction at any point in R3, conditioned on the CNN grid features and image features projected directly to the query point. This reduces aliasing and allows our model to resolve sub-voxel detail. Furthermore, this enables reconstruction at arbitrary resolution without re-training. (p. 2)
Related Work
Multi-view stereo. 3D reconstruction is traditionally posed as per-pixel depth estimation [9, 10, 22]. While recent works have shown strong results [12, 21], a known drawback is that the estimation of each depth map is independent, so continuity across frustum boundaries is not enforced, and this often leads to artifacts. (p. 2)
Feed-forward 3D reconstruction. An effective recent strategy is to perform volumetric reconstruction directly in scene space using feed-forward neural networks [1, 2, 17, 23, 24]. In this line of research, image features are encoded by a 2D CNN and densely back-projected into a global feature volume, then a 3D CNN predicts the scene TSDF. These models can generalize to new scenes at inference time without computationally-demanding test-time optimization, and they can produce smooth and complete reconstructions. However, they tend to blur out surface details and omit thin structures. (p. 2)
Geometric priors in neural radiance fields. Recent novel-view synthesis methods based on neural radiance fields [16] have shown remarkable 2D rendering quality, typically relying on time-consuming per-scene optimization to obtain good results. (p. 2)
Geometric priors in feed-forward networks. Only a few previous methods based on feed-forward networks have incorporated geometric priors. (p. 2)
Proposed Method
Resolution-agnostic TSDF supervision

To preserve the accuracy of the ground truth with no added cost, we instead supervise only at the points {x} where the ground truth is known, so that no interpolation is required. This decouples the accuracy of our ground truth from its sampling rate, rendering it resolution-agnostic. To support this, our model must be able to estimate the TSDF at any point in R3, which we achieve using the strategy outlined in Section 3.2.3. (p. 3)
Depth guidance
In order to localize image features in 3D space, we sample a pixel feature at each voxel from each available input image: (p. 4)
We fuse Dˆ into scene space using the standard TSDF fusion [4] to form Vd. We then concatenate Vd as an extra channel in the back-projection volume (p. 4)
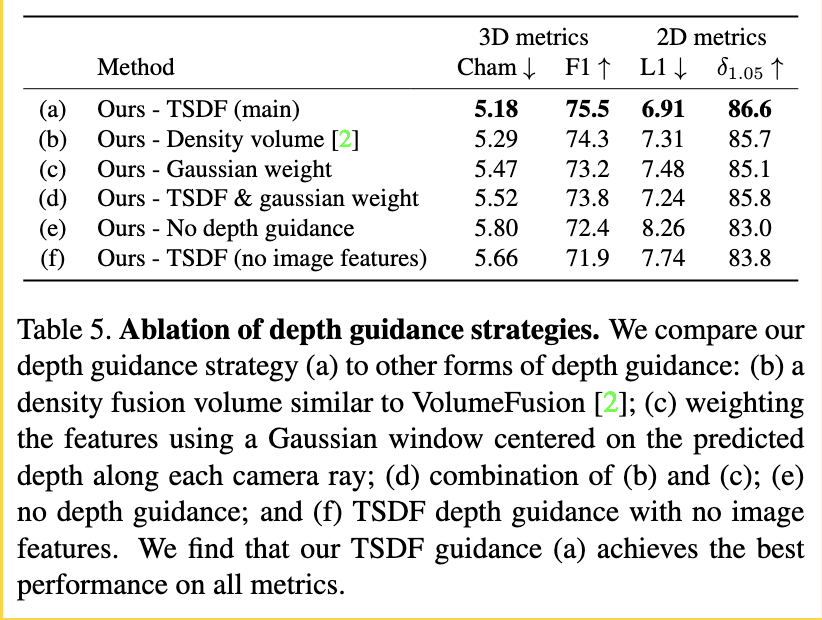
With naive application of the depth guidance, we find that this additional signal increases our network’s propensity to over-fit to the training data, relying too heavily on the depth guidance which is often inaccurate. To address this, we scale each predicted depth map by a factor sampled uniformly in the range [0.9, 1.1] as a data augmentation during training. This reduces over-fitting and encourages the network to learn to use the image features in regions where the depth maps are unreliable. (p. 4)
Output resolution & occupancy filtering
Our model can be sampled at any point in R3, and we choose to sample it on a regular grid at test time in order to support meshing with marching cubes [15]. (p. 4). At high resolutions, it thus becomes expensive due to the cost of running the additional back-projection and θS densely over the full volume. To mitigate this, we predict the per-voxel occupancy Oˆ with an additional MLP: Oˆ = θO(V). Then at test time we sample Sˆ only within voxels that are predicted to be occupied. (p. 4)
Training
At training time, we require a ground-truth TSDF S to supervise Sˆ. For training on real scans, we use TSDF fusion [4] to generate S on a discrete grid of points X. While ground truth depth can be noisy when acquired by sensors such as structured-light infrared scanners, we minimize artifacts by 1) using a large number of views to generate the ground-truth, 2) using an appropriate TSDF truncation distance following previous work [17, 23, 24], and 3) discarding depths beyond the range where the accuracy starts to visibly degrade (p. 5)
Experiment Result
Ablation

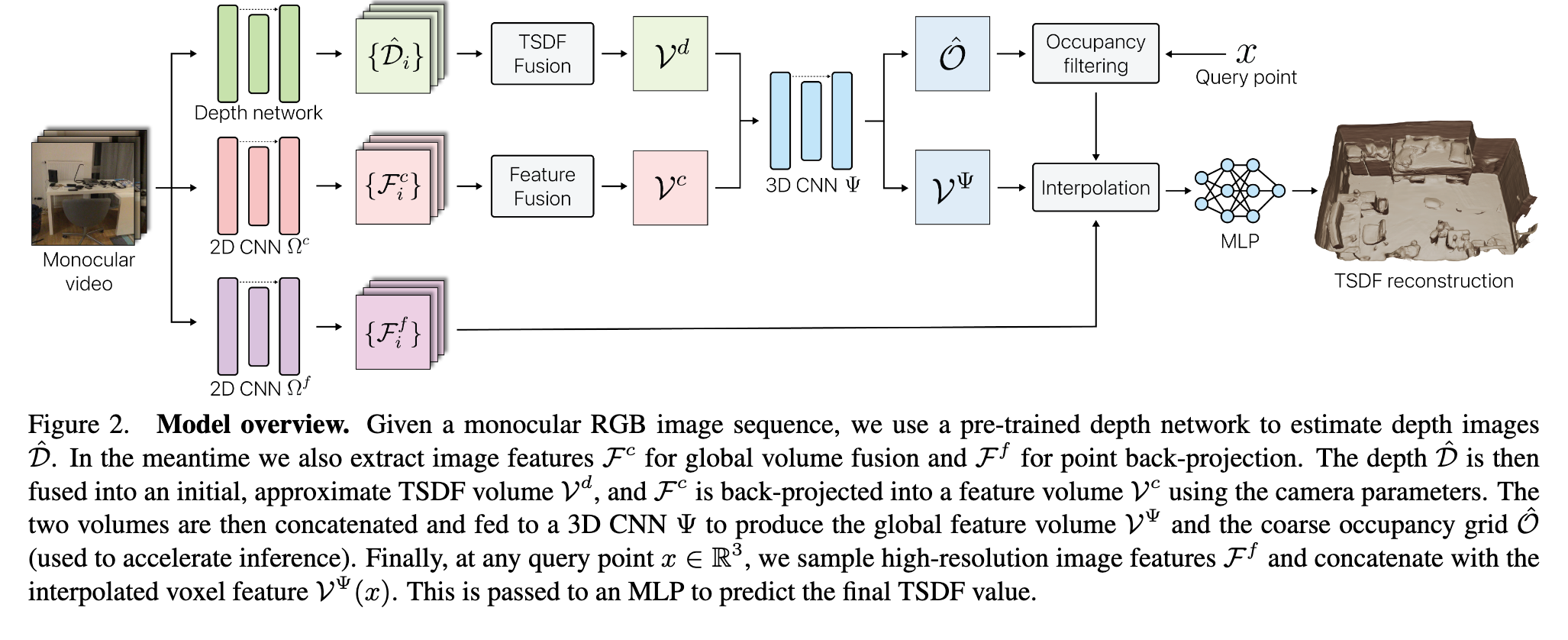
We note that resolution-agnostic TSDF supervision (RTS) and depth guidance (DG) both result in significant improvement across all metrics. Interestingly, point back-projection (PB) improves all metrics when DG is used ((v) vs. (iv)) but degrades them in the absence of DG ((iii) vs. (ii)). We interpret this as follows: the high frequency content recovered by PB is locally accurate, but if the coarse alignment relative to ground truth is incorrect, then the added details actually reduce overall accuracy. DG helps to correctly localize the large structures, interacting constructively with PB to achieve the best performance. (p. 7)