Generative adversarial network
[generative-adversarial-network progressive-gan cycle-gan dc-gan gan stargan pix2pix deep-learning biggan wgan stylegan 
Generative adversarial network (GAN), since proposed in 2014 by Ian Goodfellow has drawn a lot of attentions. It is consisted of a generator and a discriminator, where the generator tries to generate sample and the discrimiantor tries to discriminate the sample generated by generator from the real ones.
In the ideal case, the generator will generate data as real as the real data; and the discriminator will not be able to discrimnator the sample generated by generator from the real ones.
/ch07_%E7%94%9F%E6%88%90%E5%AF%B9%E6%8A%97%E7%BD%91%E7%BB%9C(GAN)/img/ch7/7.1-gan_structure.png)
The quality of GAN can be measured via inception score: \(IS(G) = e^{\mathbb{E}_{x: p_\sigma} D_{KL}(p(y|x) \lVert p(y))}\) where $y$ is the label and $x$ is the generated dat. Or Fréchet Inception Distance (FID) \(FID(x, g) = \lVert \mu_x - \mu_g \rVert^2_2 + Tr(\Sigma_x + \Sigma_g - 2(\Sigma_x \Sigma_g)^{0.5})\)
Vanilla GAN
The cost function of vanilla GAN can be written as: \(\mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = { {\rm E}_{x\sim{p_{data}}(x)}}[\log D(x)] + { {\rm E}_{z\sim{p_z}(z)}}[\log (1 - D(G(z)))]\)
where the first part is the cross entropy on the discriminator output over the data distribution; and the second part is the cross entropy of negative discriminator output over the sampler distribution.
The training of GAN will iterate with the following steps:
- generate the data from generator and sample the real data
- use those two data to update the discriminator
- update the generator.
ImprovedGAN
PACGAN
PacGAN: The power of two samples in generative adversarial networks
PACGan discusses why GAN has the problem of model collapse and how to solve it. It proposed a principled approach to handling mode collapse, which we call packing. The main idea is to modify the discriminator to make decisions based on multiple samples from the same class, either real or artificially generated. It borrowed analysis tools from binary hypothesis testing—in particular the seminal result of Blackwell [Bla53]—to prove a fundamental connection between packing and mode collapse. It showed that packing naturally penalizes generators with mode collapse, thereby favoring generator distributions with less mode collapse during the training process.

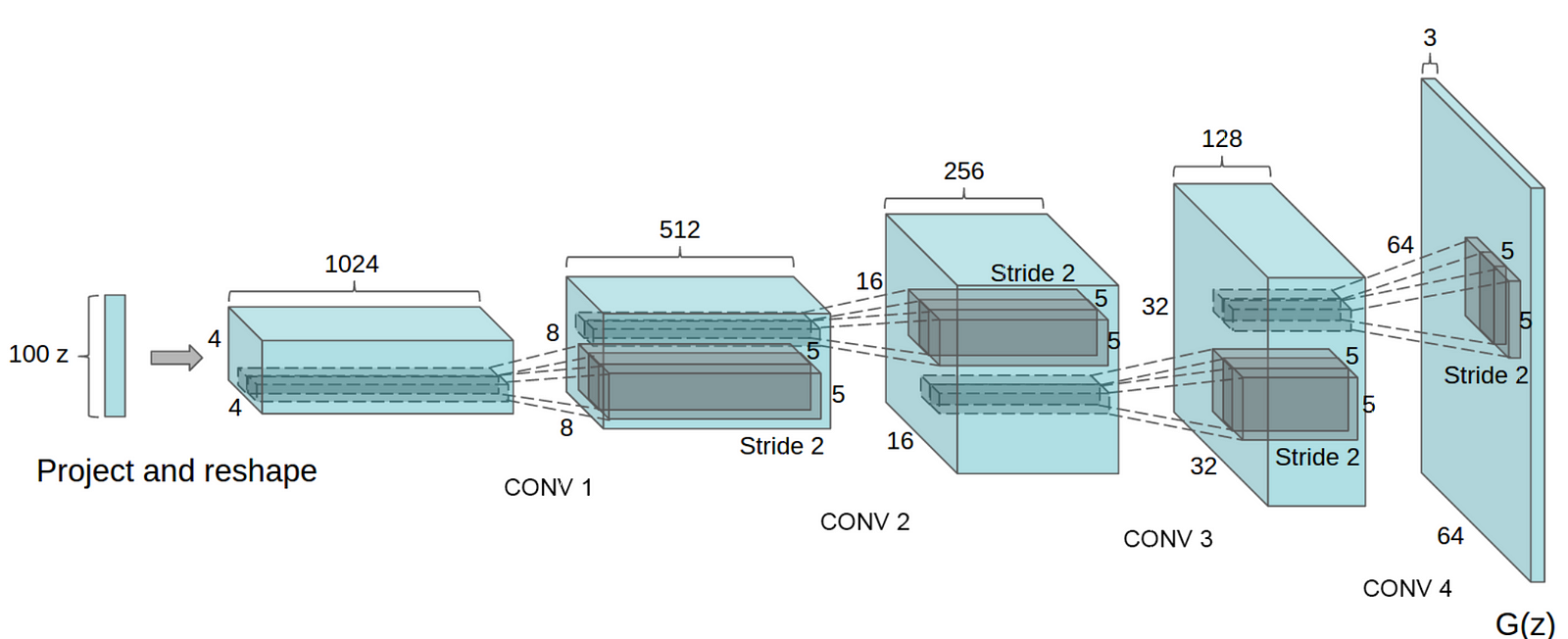
DC-GAN
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
DC-GAN use deep neural network for both the generator and discriminator. It emphasizes several guidelines for stable Deep Convolutional GANs
- Replace any pooling layers with strided convolutions (discriminator) and fractional-strided convolutions (generator).
- Use batchnorm in both the generator and the discriminator.
- Remove fully connected hidden layers for deeper architectures.
- Use ReLU activation in generator for all layers except for the output, which uses Tanh.
- Use LeakyReLU activation in the discriminator for all layers.
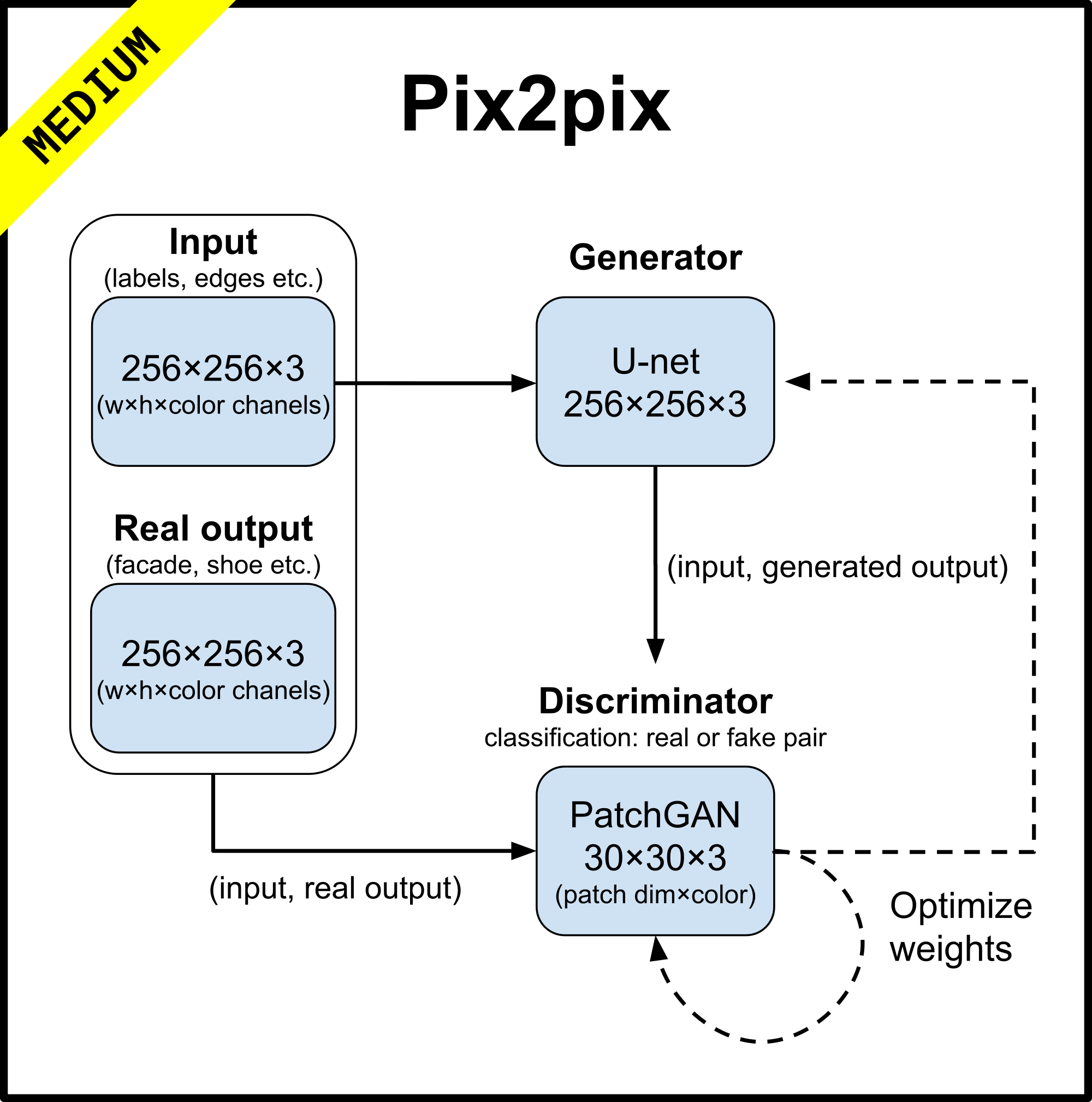
pix2pix
Image-to-Image Translation with Conditional Adversarial Networks
Pix2pix is able to solve a wide set of image to image transfer problem. It uses U-Net for generator and convolutional PatchGAN for patch-level discriminator, to address the problem that output GAN tends to be blur.
Vid2Vid
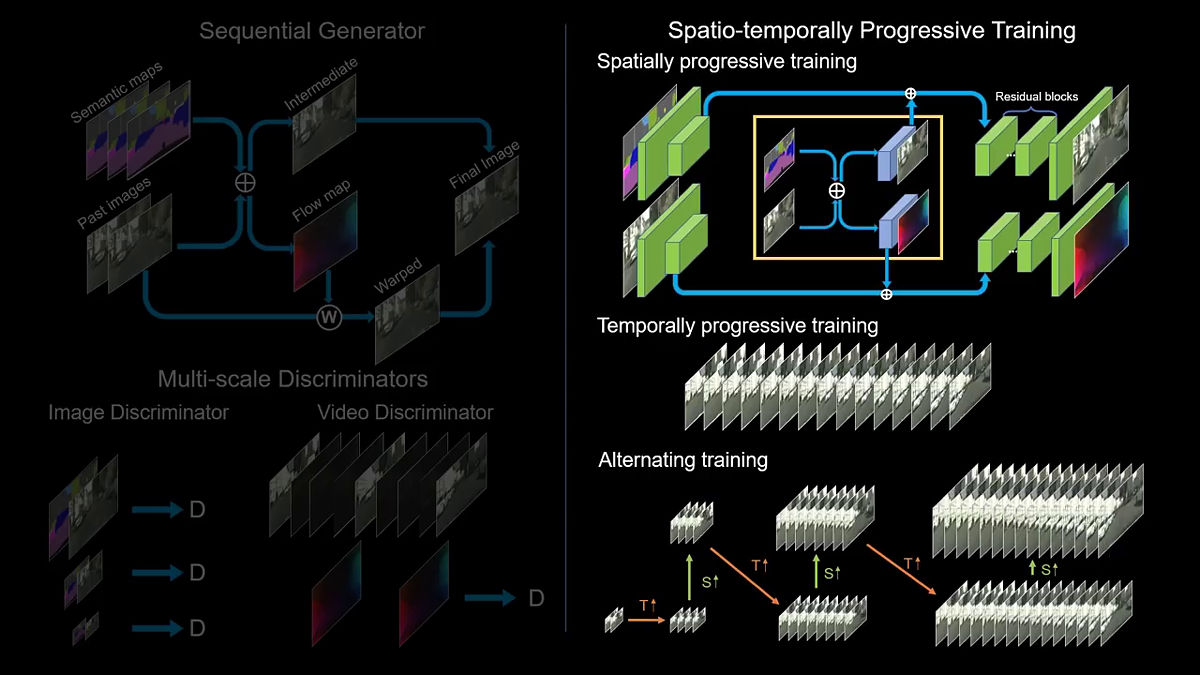
Video-to-Video Synthesis
In this paper, we propose a novel video-to-video synthesis approach under the generative adversarial learning framework. Through carefully-designed generator and discriminator architectures, coupled with a spatio-temporal adversarial objective, we achieve high-resolution, photorealistic, temporally coherent video results on a diverse set of input formats including segmentation masks, sketches, and poses.
Cycle-GAN
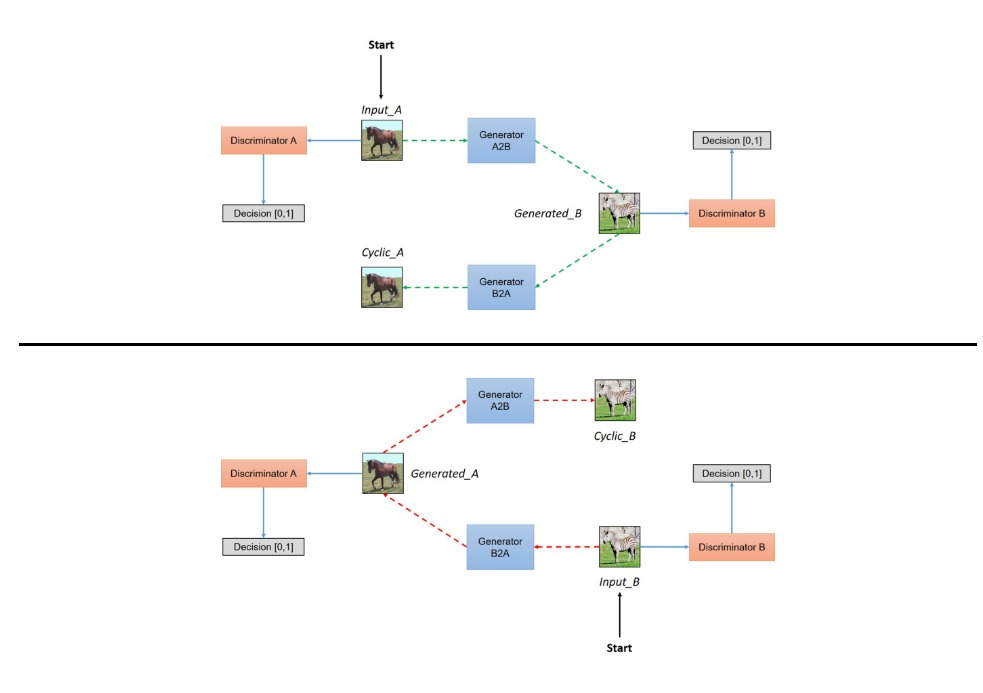
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Cycle-GAN tackles the problem that, the source image and target image pair may not be available; however, images from source domain and images from target domain are available. To resolve this, cycle consistent loss is proposed, which ensures the image of source domain transferred to target domain can be transfer back: \(G(F(X)) = X, F(G(Y)) = Y\)
WGAN
Wasserstein Generative Adversarial Networks
WGAN claims that in GAN (other many others), the density distribution for the real data doesn’t exists, that means the cross-entropy loss function doesn’t hold. As a result, wasserstein is proposed, which is a approximation of earth move distance function.
Progressive GAN
PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
In Progressive GAN, the generator and discriminator is trained progressively, namely, a simpler one is trainied for low resolution image, then more layer are added for higer resolution image. This progressive training dramatically improves the stability and speed of the training process.

StackGAN
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
Similar as Progressive-GAN, StackGAN also addresses the problem of generating image from text. Samples generated by existing text-to-image approaches can roughly reflect the meaning of the given descriptions, but they fail to contain necessary details and vivid object parts. In this paper, we propose Stacked Generative Adversarial Networks (StackGAN) to generate 256x256 photo-realistic images conditioned on text descriptions. We decompose the hard problem into more manageable sub-problems through a sketch-refinement process. The Stage-I GAN sketches the primitive shape and colors of the object based on the given text description, yielding Stage-I low-resolution images. The Stage-II GAN takes Stage-I results and text descriptions as inputs, and generates high-resolution images with photo-realistic details. It is able to rectify defects in Stage-I results and add compelling details with the refinement process. To improve the diversity of the synthesized images and stabilize the training of the conditional-GAN, we introduce a novel Conditioning Augmentation technique that encourages smoothness in the latent conditioning manifold.

BigGan
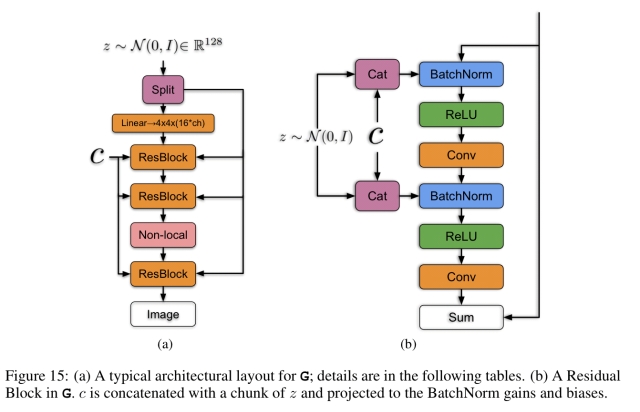
LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
BigGan considers the problem of training GAN on large scale dataset, e.g., ImageNet. It proposes that increasing batch size, number of output channels of convolution layers and depth of network (combined with residual blocks) could dramatically improve the performance. Truncation Trick is also proposed to generate the input for generator to improve stability, where noise is sampled from a normal distribution but any value above the threshold is resampled.
SeqGAN
SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
SeqGAN address the limitation of existing GAN in discrete sequential data, e.g., text. Modeling the data generator as a stochastic policy in reinforcement learning (RL), SeqGAN bypasses the generator differentiation problem by directly performing gradient policy update. The RL reward signal comes from the GAN discriminator judged on a complete sequence, and is passed back to the intermediate state-action steps using Monte Carlo search.

StarGan
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
StarGan address problem of learning GAN simultaneously for multiple domains. To do that, the input to the generator is a label vector of the target domain of the image to be generated. It also adopts the idea of Cycle-gan.

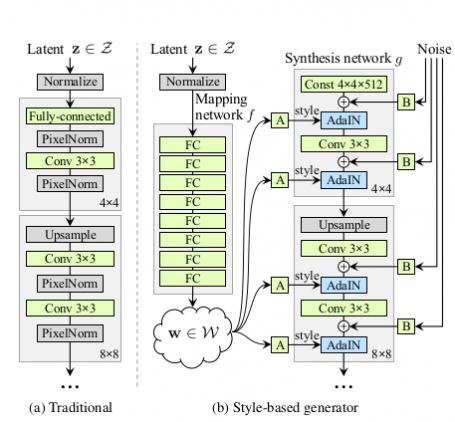
StyleGan
A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGan has a totall diferent architecture compared with other GANs (as shown below). It has three inputs:
- constant input: a $512x4x4$ tensor encodes the image prior;
- latent vector after mapping network: encodes the style information;
- noise: added to input to multiple hidden layer to further improve the result.