GIT A Generative Image-to-text Transformer for Vision and Language
[global-attention attention clip image-caption multimodal coca blip vqa cross-attenion deep-learning git swin-transformer flamingo This is my reading note for GIT: A Generative Image-to-text Transformer for Vision and Language. This paper proposes a image-text pre-training model. The model contains visual encoder and text decoder; the text decoder is based on self-attention, which takes concatenated text tokens and visual tokens as input.

Introduction
In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. (p. 1)
- During pre-training, Masked Language Modeling (MLM) and Image-Text Matching (ITM) tasks have been widely used (Wang et al., 2020; Fang et al., 2021c; Li et al., 2020b; Zhang et al., 2021a; Chen et al., 2020b; Dou et al., 2021; Wang et al., 2021a; Kim et al., 2021). However, these losses are different from the downstream tasks, and task-specific adaptation has to be made. For example, ITM is removed for image captioning (Wang et al., 2021a; Li et al., 2020b), and an extra randomly initialized multi-layer perceptron is added for VQA (Wang et al., 2021b; Li et al., 2020b).
- To reduce this discrepancy, recent approaches (Cho et al., 2021; Wang et al., 2021b; Yang et al., 2021b; Wang et al., 2022b) have attempted to design unified generative models for pre-training, as most VL tasks can be cast as generation problems. These approaches typically leverage a multi-modal encoder and a text decoder with careful design on the text input and the text target.
To further push the frontier of this direction, we present a simple Generative Image-to-text Transformer, named GIT, which consists only of one image encoder and one text decoder. The pre-training task is just to map the input image to the entire associated text description with the language modeling objective. (p. 2)
The image encoder is a Swin-like vision transformer (Dosovitskiy et al., 2021; Yuan et al., 2021) pre-trained on massive image-text pairs based on the contrastive task. To extend it to the video domain, we simply extract the features of multiple sampled frames and concatenate them as the video representation. For VQA, the input question is treated as a text prefix, and the answer is generated in an auto-regressive way. (p. 2)
Generative Image-to-text Transformer
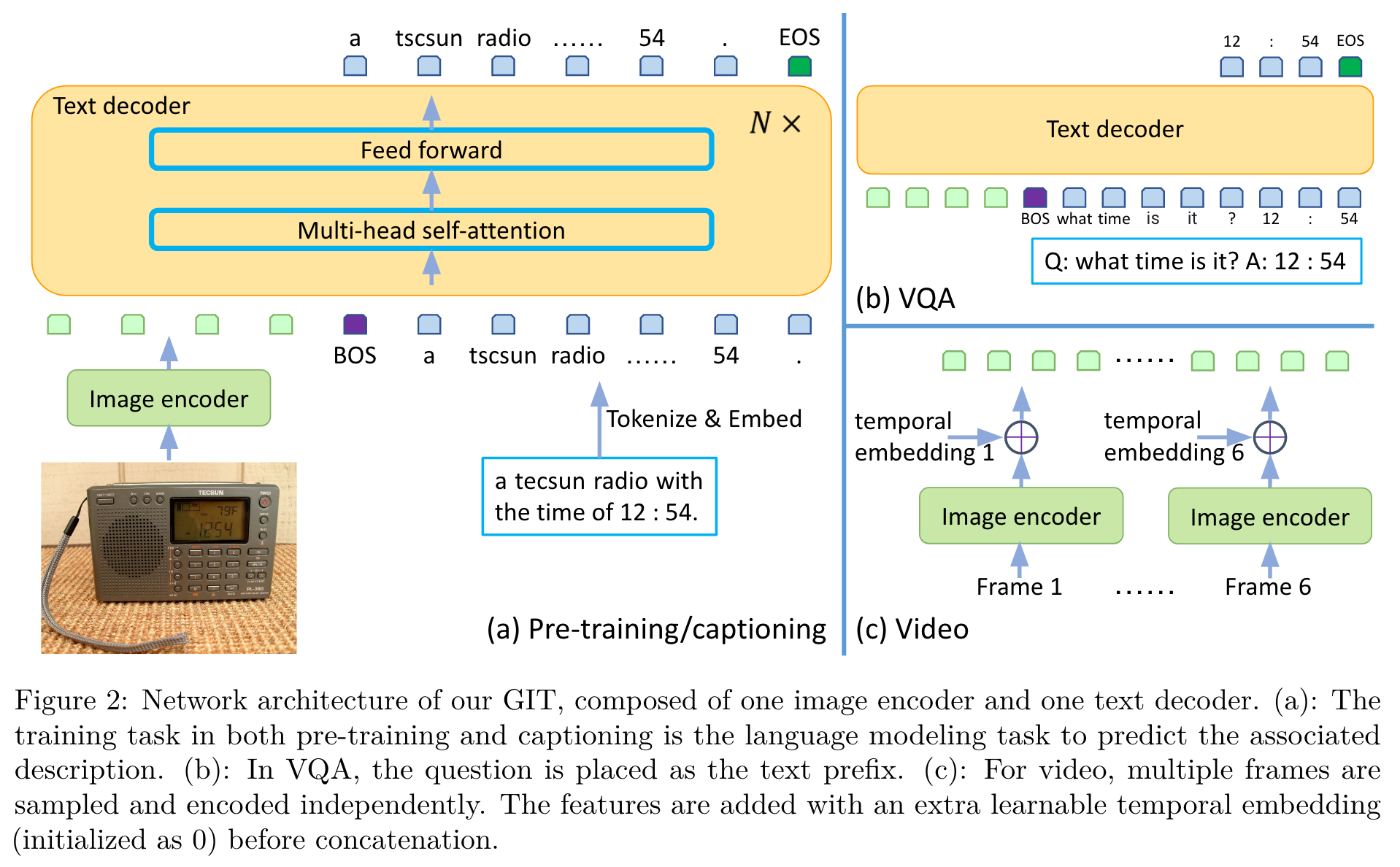
Network Architecture
With an extra linear layer and a layernorm layer, the image features are projected into D dimensions, which are the input to the text decoder. The concurrent work of CoCa (Yu et al., 2022) unifies the contrastive task and the generation task. as one pre-training phase. Our approach is equivalent to separating the two tasks sequentially: (i) using the contrastive task to pre-train the image encoder followed by (ii) using the generation task to pre-train both the image encoder and text decoder. (p. 4)
The transformer module consists of multiple transformer blocks, each of which is composed of one self-attention layer and one feed-forward layer. (p. 4)
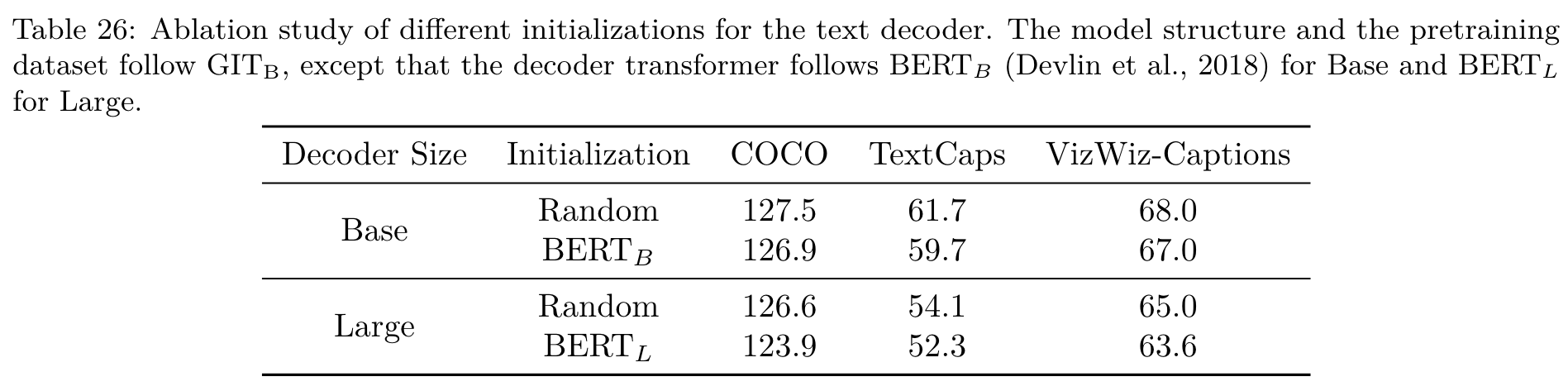
Instead of well initializing the image encoder, we randomly initialize the text decoder. This design choice is highly motivated from the experiment studies of Wang et al. (2020), in which the random initialization shows similar performance, compared with the BERT initialization. (p. 5)
The concurrent work of Flamingo (Alayrac et al., 2022) employs a similar architecture of image encoder + text decoder, but their decoder is pre-trained and frozen to preserve the generalization capability of the large language model. In our GIT, all parameters are updated to better fit the VL tasks. (p. 5)
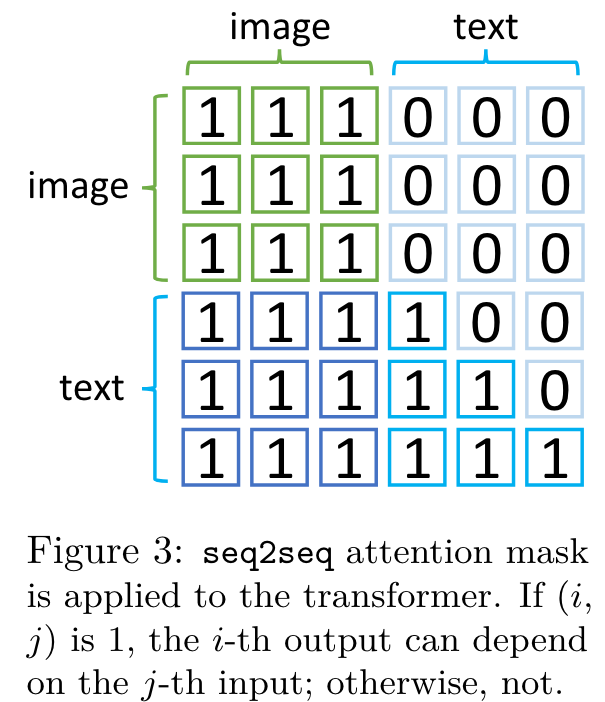
Fine-tuning
with large-scale pre-training, we find the self-attention-based decoder achieves better performance overall, while in small-scale setting, the cross-attention based approach wins. A plausible explanation is that with sufficient training, the decoder parameters can well process both the image and the text, and the image tokens can be better updated with the self-attention for text generation. With cross-attention, the image tokens cannot attend to each other. (p. 5)
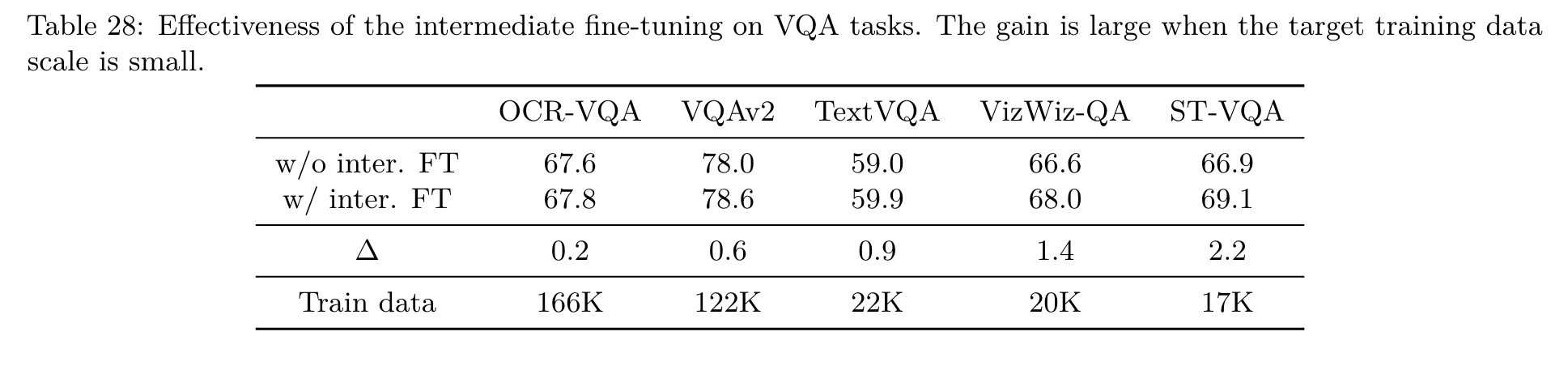
For visual question answering, the question and the ground-truth answer are concatenated as a new special caption during the fine-tuning, but the LM loss is only applied on the answer and the [EOS] tokens. During inference, the question is interpreted as the caption prefix and the completed part is the prediction. (p. 5)
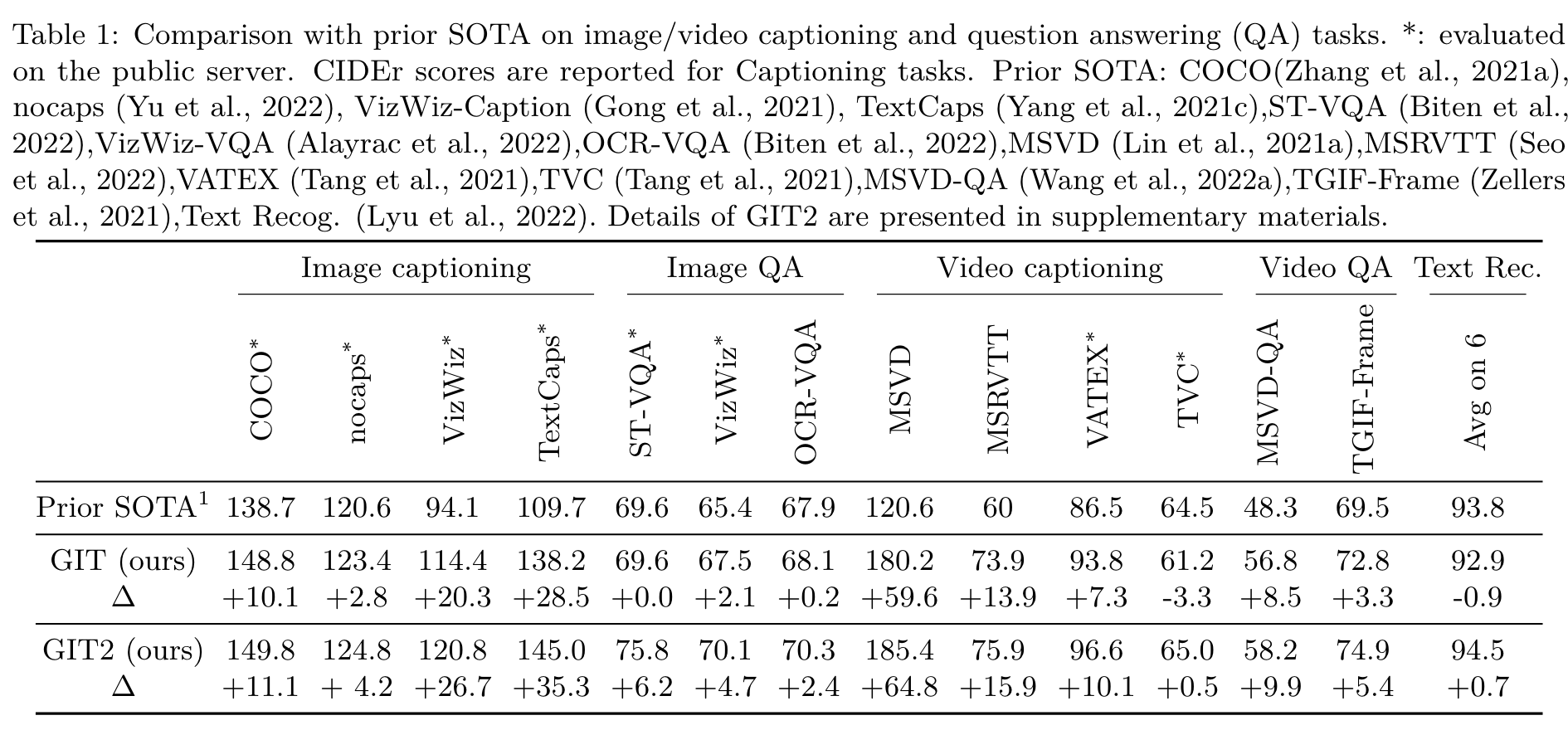
Empirically, we find the model gradually learns how to read the scene text with large-scale pre-training, and our model achieves new SoTA performance on these tasks. (p. 6)
Afterwards, we add a learnable temporal embedding (initialized as zeros), and concatenate the features from sampled frames. (p. 6)
Implementation
The learning rates of the image encoder and the decoder are 1e−5 and 5e−5, respectively, and follow the cosine decay to 0. The total number of epochs is 2. (p. 6)
Experiments
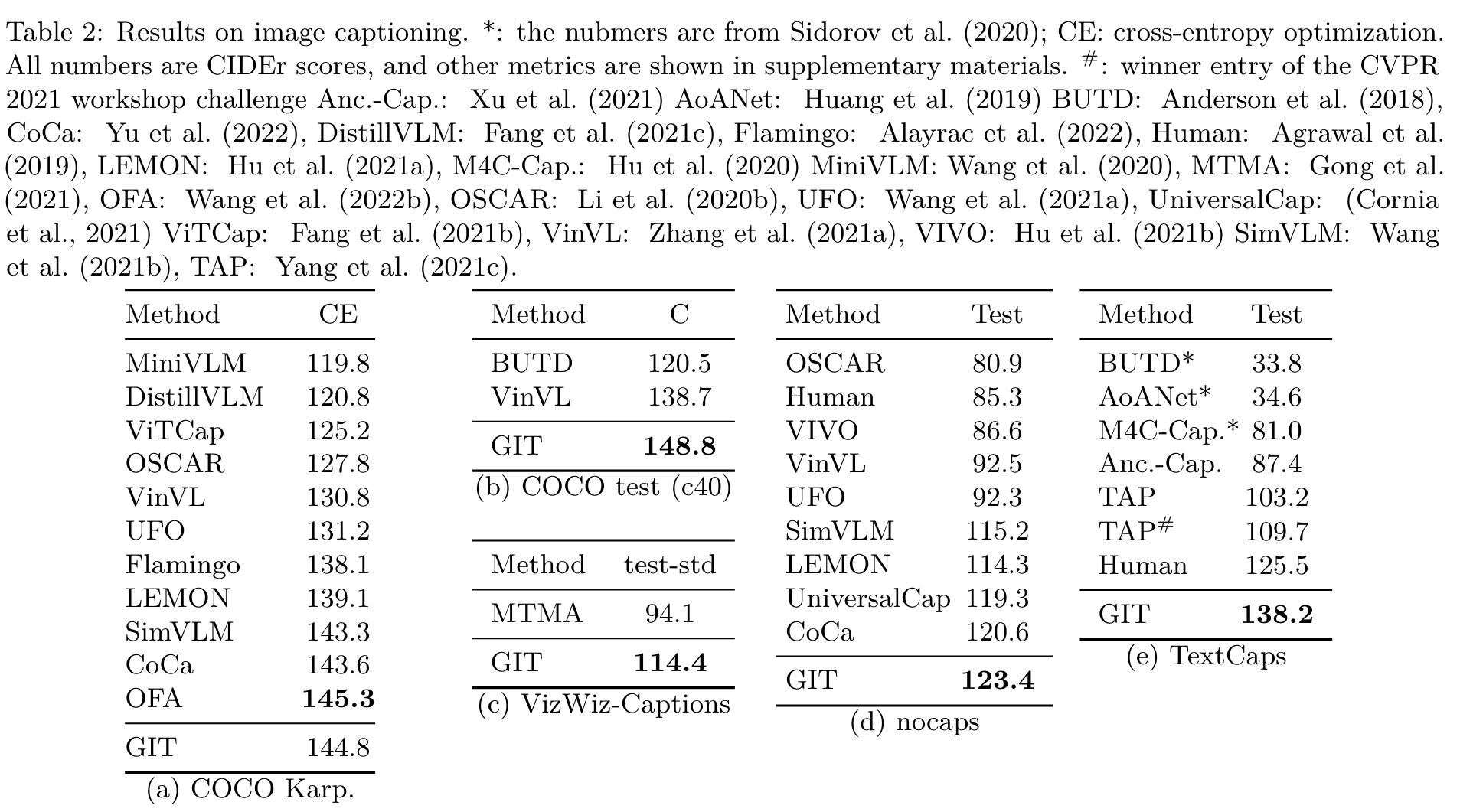
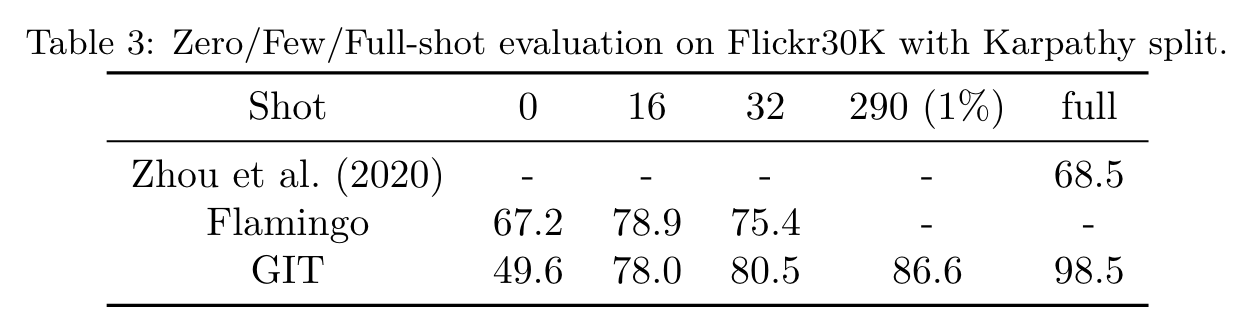
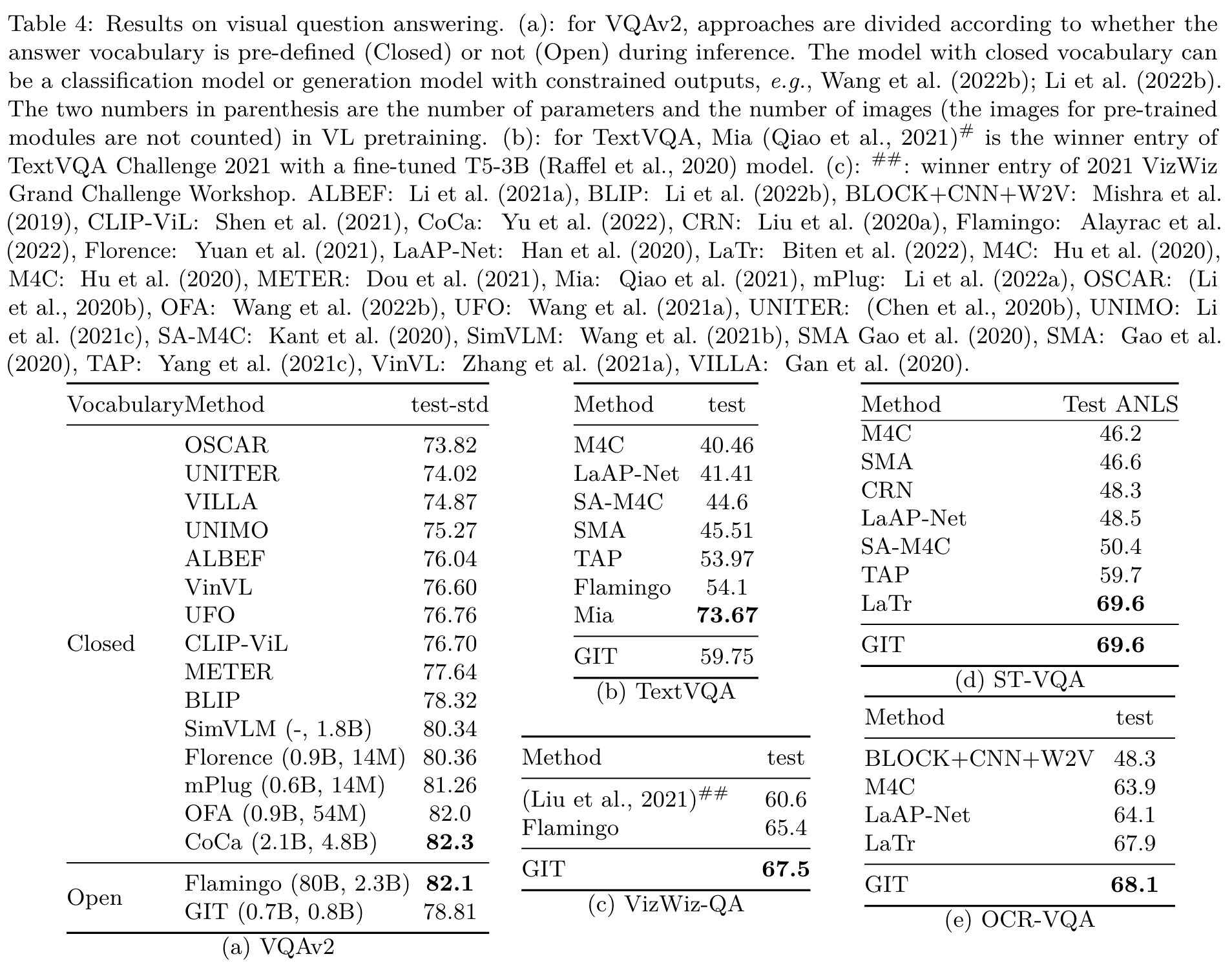
Ablation
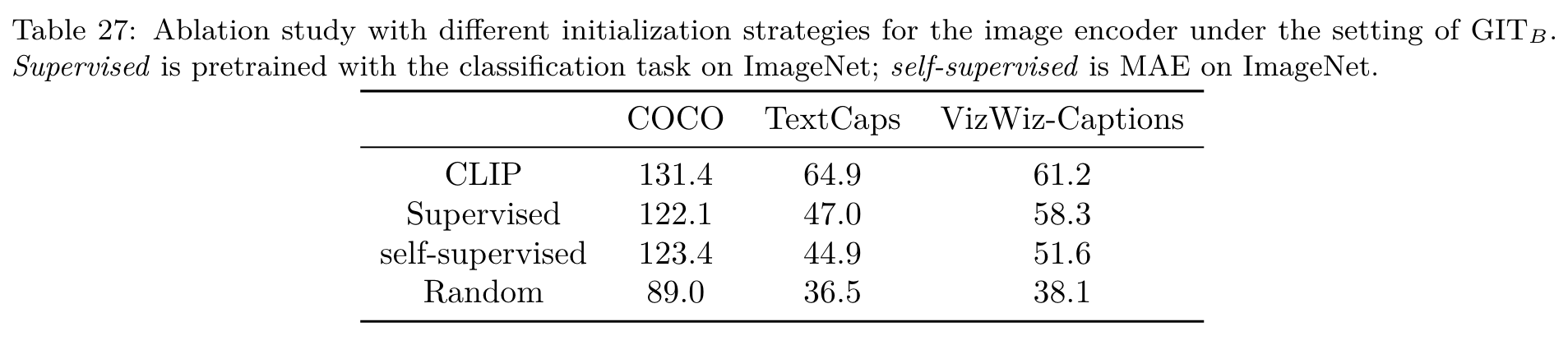
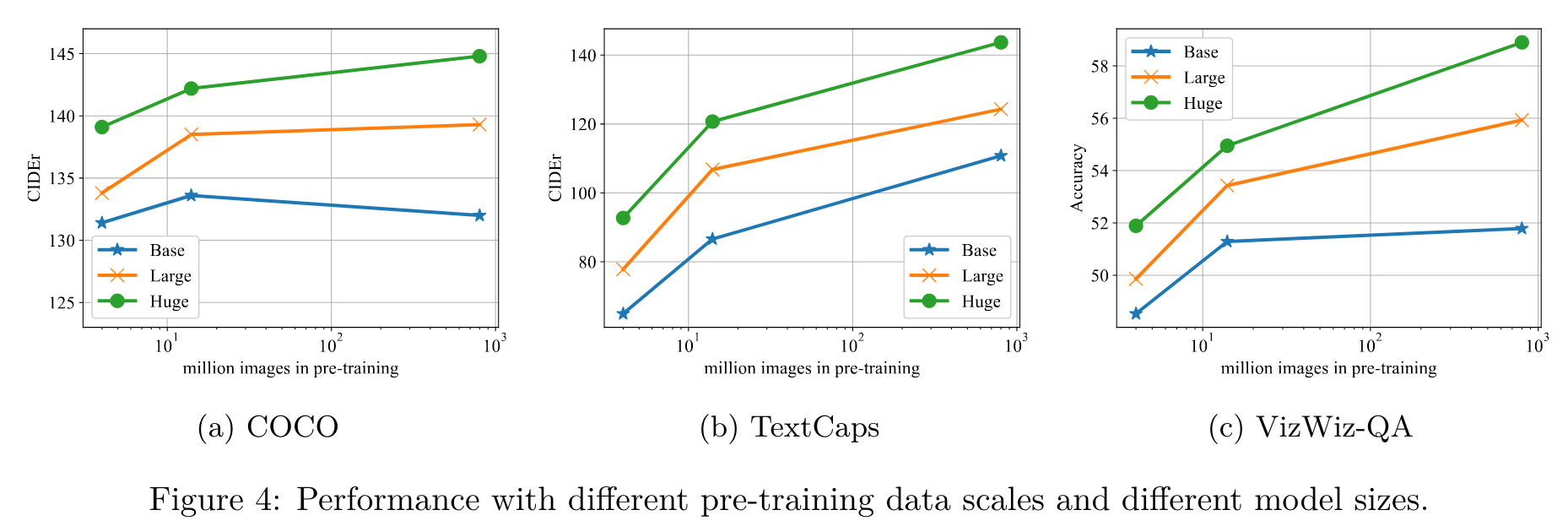
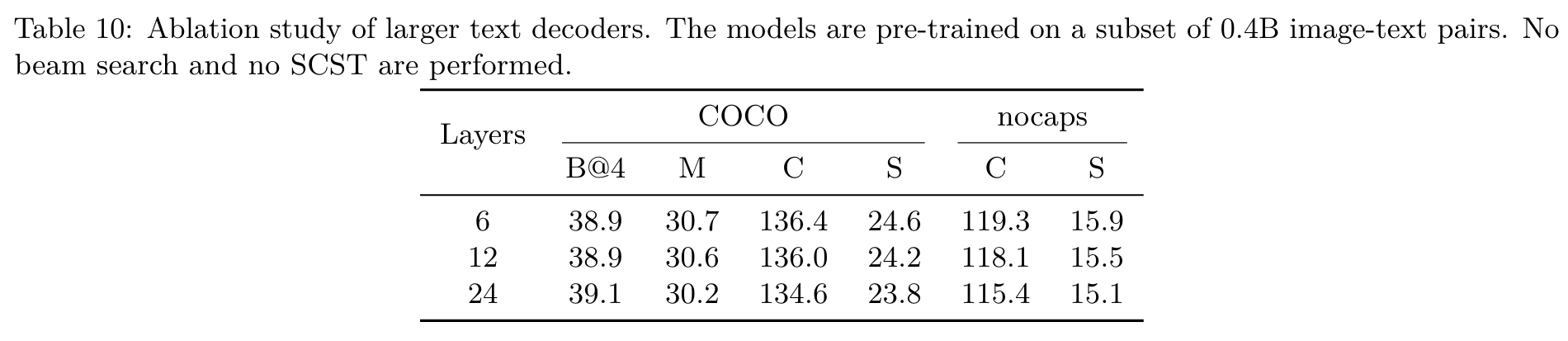
Meanwhile, the Base model with limited capacity may not be able to benefit effectively from large-scale data. Empirically, we find it is difficult to effectively scale up the text decoder. Preliminary results are shown in Table 10, which shows a larger decoder shows no improvement. The reason might be that it is difficult to effectively train with limited amount of text by LM. (p. 11)
With smaller dataset, the latter with cross-attention outperforms, while with large-scale data, the former wins. A plausible explanation is that with more pre-training data, the parameters are well optimized such that the shared projection can adapt to both the image and the text (p. 36)
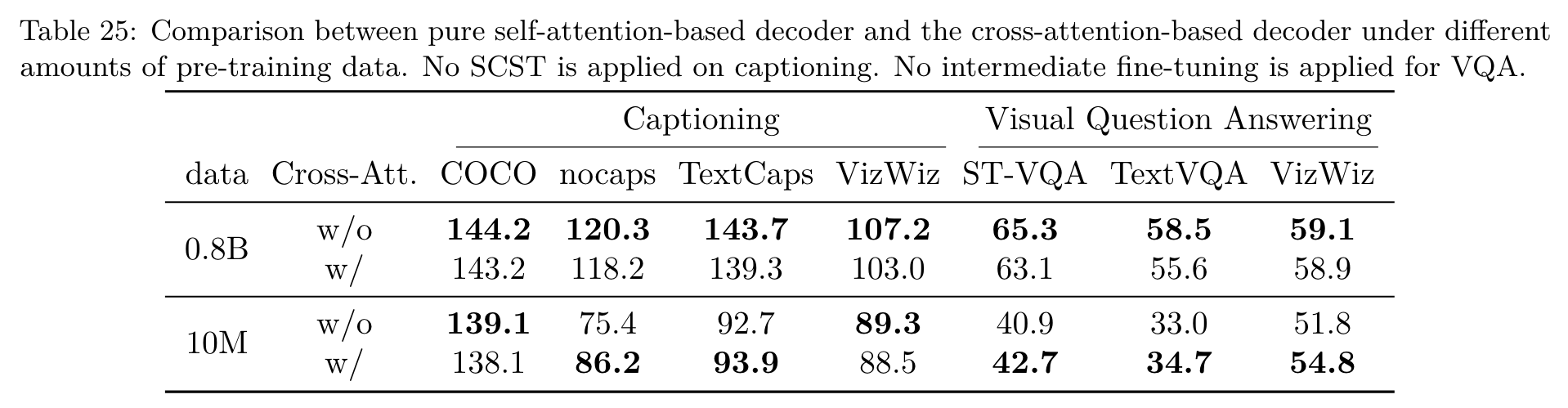
domains, which mitigates the drawback of the shared parameters. With the self-attention, the image token can be attended with each other for a better representation during decoding. In all experiments, we use the former architecture. (p. 37)