Low Light Enhancement
[msr low-light llnet hdr multi-scale-retinex deep-learning mbllen retinex-net LLNet: A deep autoencoder approach to natural low-light image enhancement

In surveillance, monitoring and tactical reconnaissance, gathering the right visual information from a dynamic environment and accurately processing such data are essential ingredients to making informed decisions which determines the success of an operation. Camera sensors are often cost-limited in ability to clearly capture objects without defects from images or videos taken in a poorly-lit environment. The goal in many applications is to enhance the brightness, contrast and reduce noise content of such images in an on-board real-time manner. We propose a deep autoencoder-based approach to identify signal features from low-light images handcrafting and adaptively brighten images without over-amplifying the lighter parts in images (i.e., without saturation of image pixels) in high dynamic range. We show that a variant of the recently proposed stacked-sparse denoising autoencoder can learn to adaptively enhance and denoise from synthetically darkened and noisy training examples. The network can then be successfully applied to naturally low-light environment and/or hardware degraded images. Results show significant credibility of deep learning based approaches both visually and by quantitative comparison with various popular enhancing, state-of-the-art denoising and hybrid enhancing-denoising techniques.
MSR-net:Low-light Image Enhancement Using Deep Convolutional Network

Images captured in low-light conditions usually suffer from very low contrast, which increases the difficulty of subsequent computer vision tasks in a great extent. In this paper, a low-light image enhancement model based on convolutional neural network and Retinex theory is proposed. Firstly, we show that multi-scale Retinex is equivalent to a feedforward convolutional neural network with different Gaussian convolution kernels. Motivated by this fact, we consider a Convolutional Neural Network(MSR-net) that directly learns an end-to-end mapping between dark and bright images. Different fundamentally from existing approaches, low-light image enhancement in this paper is regarded as a machine learning problem. In this model, most of the parameters are optimized by back-propagation, while the parameters of traditional models depend on the artificial setting. Experiments on a number of challenging images reveal the advantages of our method in comparison with other state-of-the-art methods from the qualitative and quantitative perspective.
It contains three steps:
- multi-scale logarithm transform \(R(x,y) = \log{(\frac{I(x,y)}{G(x,y)*I(x,y)})}\)
- difference of convolution
- color restoration via 1x1 convolution layer
According to Retinex theorem, low frequency component of image captures the natureness and high frequency component of image captures the detail.
Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images
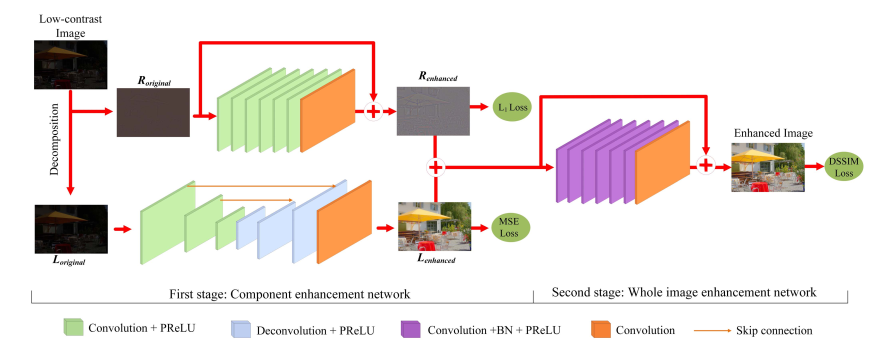
Due to the poor lighting condition and limited dynamic range of digital imaging devices, the recorded images are often under-/over-exposed and with low contrast. Most of previous single image contrast enhancement (SICE) methods adjust the tone curve to correct the contrast of an input image. Those methods, however, often fail in revealing image details because of the limited information in a single image. On the other hand, the SICE task can be better accomplished if we can learn extra information from appropriately collected training data. In this paper, we propose to use the convolutional neural network (CNN) to train a SICE enhancer. One key issue is how to construct a training data set of low-contrast and high-contrast image pairs for end-to-end CNN learning. To this end, we build a large-scale multi-exposure image data set, which contains 589 elaborately selected high-resolution multi-exposure sequences with 4,413 images. Thirteen representative multi-exposure image fusion and stack-based high dynamic range imaging algorithms are employed to generate the contrast enhanced images for each sequence, and subjective experiments are conducted to screen the best quality one as the reference image of each scene. With the constructed data set, a CNN can be easily trained as the SICE enhancer to improve the contrast of an under-/over-exposure image. Experimental results demonstrate the advantages of our method over existing SICE methods with a significant margin.
This paper proposed the low frequency and high frequency component of image seperately, where low frequency component is processed via hourglass network and high frequency component is processed via ResNet. Three losses were proposed:
- MSE for low frequency component
- L1 for high frequency component
- DSSIM for the final output.
Deep Retinex Decomposition for Low-Light Enhancement
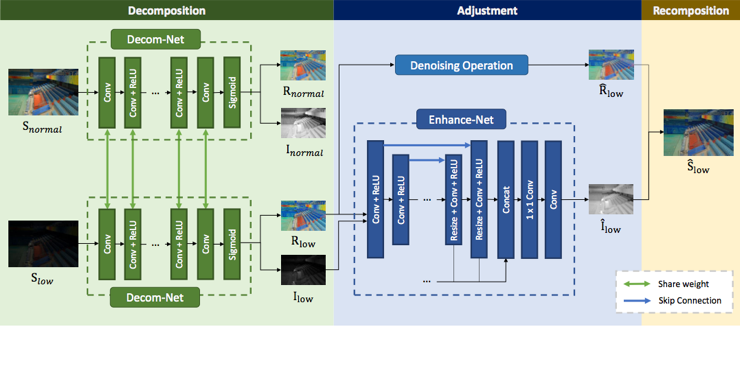
Retinex model is an effective tool for low-light image enhancement. It assumes that observed images can be decomposed into the reflectance and illumination. Most existing Retinex-based methods have carefully designed hand-crafted constraints and parameters for this highly ill-posed decomposition, which may be limited by model capacity when applied in various scenes. In this paper, we collect a LOw-Light dataset (LOL) containing low/normal-light image pairs and propose a deep Retinex-Net learned on this dataset, including a Decom-Net for decomposition and an Enhance-Net for illumination adjustment. In the training process for Decom-Net, there is no ground truth of decomposed reflectance and illumination. The network is learned with only key constraints including the consistent reflectance shared by paired low/normal-light images, and the smoothness of illumination. Based on the decomposition, subsequent lightness enhancement is conducted on illumination by an enhancement network called Enhance-Net, and for joint denoising there is a denoising operation on reflectance. The Retinex-Net is end-to-end trainable, so that the learned decomposition is by nature good for lightness adjustment. Extensive experiments demonstrate that our method not only achieves visually pleasing quality for low-light enhancement but also provides a good representation of image decomposition.
This paper proposed to decompose image into reflectance and illumination, which are proposed separately but with shared weight. The illumination is enhanced via a hourglass network and refelectance is denoised via BM3D. The final image is reconstructed by combining illumination and reflectance.
MBLLEN: Low-light Image/Video Enhancement Using CNNs

We present a deep learning based method for low-light image enhancement. This problem is challenging due to the difficulty in handling various factors simultaneously including brightness, contrast, artifacts and noise. To address this task, we propose the multi-branch low-light enhancement network (MBLLEN). The key idea is to extract rich features up to different levels, so that we can apply enhancement via multiple subnets and finally produce the output image via multi-branch fusion. In this manner, image quality is improved from different aspects. Through extensive experiments, our proposed MBLLEN is found to outperform the state-of-art techniques by a large margin. We additionally show that our method can be directly extended to handle low-light videos.
This paper proposed to also use hourglass network. For video enhancement, 3D convolution is used.
Learning to See in the Dark
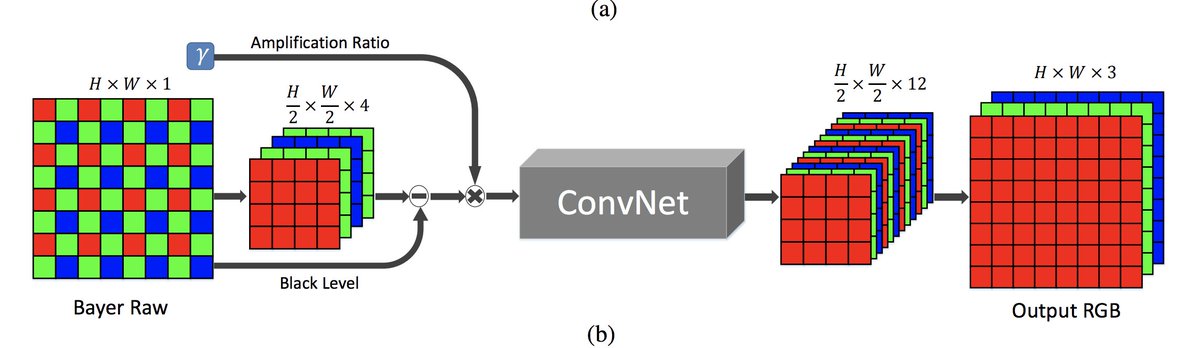
Imaging in low light is challenging due to low photon count and low SNR. Short-exposure images suffer from noise, while long exposure can induce blur and is often impractical. A variety of denoising, deblurring, and enhancement techniques have been proposed, but their effectiveness is limited in extreme conditions, such as video-rate imaging at night. To support the development of learning-based pipelines for low-light image processing, we introduce a dataset of raw short-exposure low-light images, with corresponding long-exposure reference images. Using the presented dataset, we develop a pipeline for processing low-light images, based on end-to-end training of a fully-convolutional network. The network operates directly on raw sensor data and replaces much of the traditional image processing pipeline, which tends to perform poorly on such data. We report promising results on the new dataset, analyze factors that affect performance, and highlight opportunities for future work. The results are shown in the supplementary video at this https URL
Kindling the Darkness: A Practical Low-light Image Enhancer

Images captured under low-light conditions often suffer from (partially) poor visibility. Besides unsatisfactory lightings, multiple types of degradations, such as noise and color distortion due to the limited quality of cameras, hide in the dark. In other words, solely turning up the brightness of dark regions will inevitably amplify hidden artifacts. This work builds a simple yet effective network for \textbf{Kin}dling the \textbf{D}arkness (denoted as KinD), which, inspired by Retinex theory, decomposes images into two components. One component (illumination) is responsible for light adjustment, while the other (reflectance) for degradation removal. In such a way, the original space is decoupled into two smaller subspaces, expecting to be better regularized/learned. It is worth to note that our network is trained with paired images shot under different exposure conditions, instead of using any ground-truth reflectance and illumination information. Extensive experiments are conducted to demonstrate the efficacy of our design and its superiority over state-of-the-art alternatives. Our KinD is robust against severe visual defects, and user-friendly to arbitrarily adjust light levels. In addition, our model spends less than 50ms to process an image in VGA resolution on a 2080Ti GPU. All the above merits make our KinD attractive for practical use.
This paper is similar to Deep Retinex Decomposition for Low-Light Enhancement. The innovations include:
- to effectively remove visual defects amplified through lightening dark regions, reflectance map is used to infer the illumination map;
- the network is trained with paired images captured under different light/exposure conditions, instead of using any ground-truth reflectance and illumination information;
- for reflectance map, total variation and ssim was proposed besides MSE.