ICML 2019 Best Papers and Honourable of Mention
[icml 2019 deep-learning International Conference on Machine Learning (ICML) 2019 has got 3424 submissions and 744 accepted (accpetance rate is 22.6%). The result can be found here
Best Papers
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Rätsch, Sylvain Gelly, Bernhard Schölkopf, Olivier Bachem
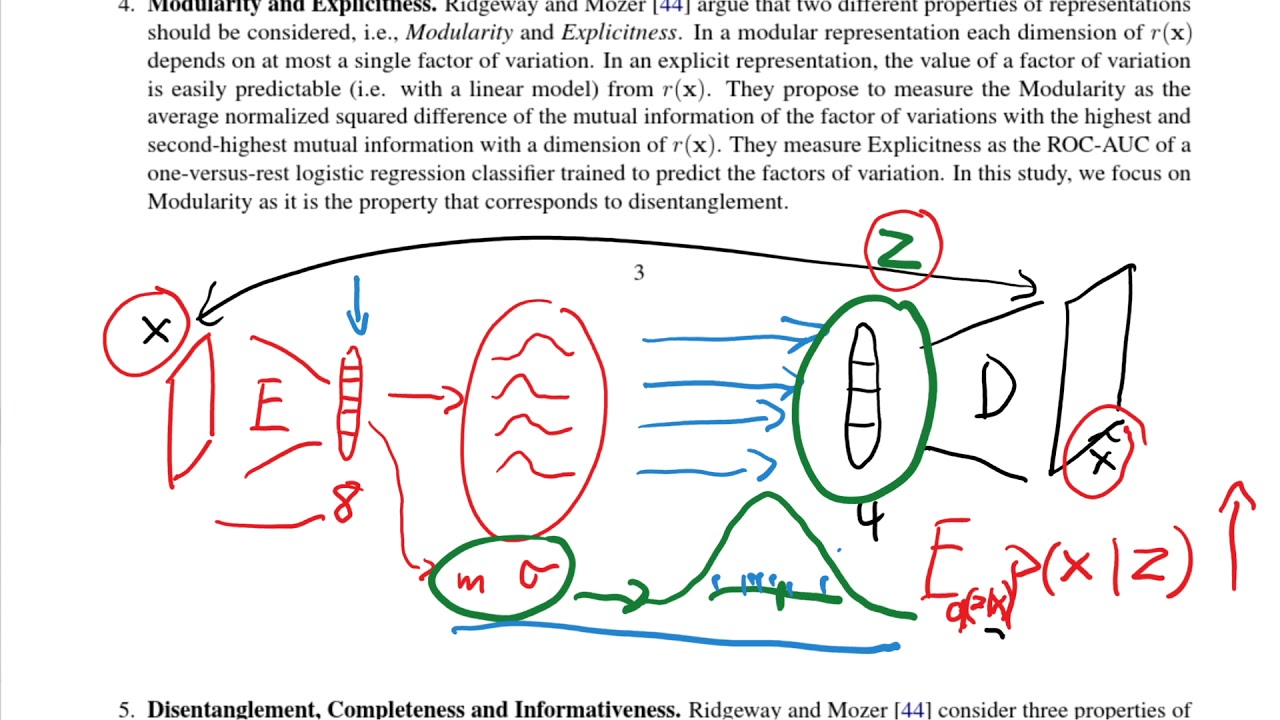
| In representation learning it is often assumed that real-world observations x (e.g., images or videos) are generated by a two-step generative process. First, a multivariate latent random variable z is sampled from a distribution P (z). Then, in a second step, the observation x is sampled from the conditional distribution P (x | z). The key idea behind this model is that the high-dimensional data x can be explained by the substantially lower dimensional and semantically meaningful latent variable z which is mapped to the higher-dimensional space of observations x. Informally, the goal of representation learning is to find useful transformations r(x) of x that “make it easier to extract useful information when building classifiers or other predictors”. |
A recent line of work has argued that representations that are disentangled are an important step towards a better representation learning. The key intuition is that a disentangled representation should separate the distinct, informative factors of variations in the data.
State-of-the-art approaches for unsupervised disentangle- ment learning are largely based on Variational Autoencoders (VAEs):
-
One assumes a specific prior P (z) on the latent space and then uses a deep neural network to parameterize the conditional probability P (x z). -
Similarly, the distribution P (z x) is approximated using a variational distribution Q(z x), again parametrized using a deep neural network.
The contributions of this paper are:
- The paper first theoretically showed that the unsupervised learning of disentangled representations is fundamentally impossible without inductive biases on both the models and the data.
- After training more than 12000 models covering most prominent methods and evaluation metrics in a reproducible large-scale experimental study on seven different data sets, it is observed that while the different methods successfully enforce properties `encouraged’ by the corresponding losses, well-disentangled models seemingly cannot be identified without supervision. Furthermore, increased disentanglement does not seem to lead to a decreased sample complexity of learning for downstream tasks.
- A lib disentanglement_lib is open sourced
- Based on these empirical evidence, we suggest three crit- ical areas of further research:
- The role of inductive bi- ases and implicit and explicit supervision should be made explicit: unsupervised model selection persists as a key question.
- The concrete practical benefits of enforcing a specific notion of disentanglement of the learned rep- resentations should be demonstrated.
- Experiments should be conducted in a reproducible experimental setup on data sets of varying degrees of difficulty.
Rates of Convergence for Sparse Variational Gaussian Process Regression
DavidR. Burt1,Carl E. Rasmussen1,Mark van der Wilk2

Excellent variational approximations to Gaussian process posteriors have been developed which avoid the (N3) scaling with dataset size N. They reduce the computational cost to (NM2), with M≪N being the number of inducing variables, which summarise the process. While the computational cost seems to be linear in N, the true complexity of the algorithm depends on how M must increase to ensure a certain quality of approximation. We address this by characterising the behavior of an upper bound on the KL divergence to the posterior. We show that with high probability the KL divergence can be made arbitrarily small by growing M more slowly than N. A particular case of interest is that for regression with normally distributed inputs in D-dimensions with the popular Squared Exponential kernel, M=(logDN) is sufficient. Our results show that as datasets grow, Gaussian process posteriors can truly be approximated cheaply, and provide a concrete rule for how to increase M in continual learning scenarios.
Honourable of Mention
Analogies Explained: Towards Understanding Word Embeddings
CarlAllen1,Timothy Hospedales
Word embeddings generated by neural network methods such as word2vec (W2V) are well known to exhibit seemingly linear behaviour, e.g. the embeddings of analogy “woman is to queen as man is to king” approximately describe a parallelogram. This property is particularly intriguing since the embeddings are not trained to achieve it. Several explanations have been proposed, but each introduces assumptions that do not hold in practice. We derive a probabilistically grounded definition of paraphrasing that we re-interpret as word transformation, a mathematical description of “wx is to wy”. From these concepts we prove existence of linear relationships between W2V-type embeddings that underlie the analogical phenomenon, identifying explicit error terms.
SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver
Po-WeiWang1,Priya L. Donti1 2,Bryan Wilder3,Zico Kolter
Integrating logical reasoning within deep learning architectures has been a major goal of modern AI systems. In this paper, we propose a new direction toward this goal by introducing a differentiable (smoothed) maximum satisfiability (MAXSAT) solver that can be integrated into the loop of larger deep learning systems. Our (approximate) solver is based upon a fast coordinate descent approach to solving the semidefinite program (SDP) associated with the MAXSAT problem. We show how to analytically differentiate through the solution to this SDP and efficiently solve the associated backward pass. We demonstrate that by integrating this solver into end-to-end learning systems, we can learn the logical structure of challenging problems in a minimally supervised fashion. In particular, we show that we can learn the parity function using single-bit supervision (a traditionally hard task for deep networks) and learn how to play 9×9 Sudoku solely from examples. We also solve a “visual Sudoku” problem that maps images of Sudoku puzzles to their associated logical solutions by combining our MAXSAT solver with a traditional convolutional architecture. Our approach thus shows promise in integrating logical structures within deep learning.
A Tail-Index Analysis of Stochastic Gradient Noise in Deep Neural Networks
Umut Şimşekli∗,L, event Sagun†, Mert Gürbüzbalaban
The gradient noise (GN) in the stochastic gradient descent (SGD) algorithm is often considered to be Gaussian in the large data regime by assuming that the classical central limit theorem (CLT) kicks in. This assumption is often made for mathematical convenience, since it enables SGD to be analyzed as a stochastic differential equation (SDE) driven by a Brownian motion. We argue that the Gaussianity assumption might fail to hold in deep learning settings and hence render the Brownian motion-based analyses inappropriate. Inspired by non-Gaussian natural phenomena, we consider the GN in a more general context and invoke the generalized CLT (GCLT), which suggests that the GN converges to a heavy-tailed α-stable random variable. Accordingly, we propose to analyze SGD as an SDE driven by a Lévy motion. Such SDEs can incur ‘jumps’, which force the SDE transition from narrow minima to wider minima, as proven by existing metastability theory. To validate the α-stable assumption, we conduct extensive experiments on common deep learning architectures and show that in all settings, the GN is highly non-Gaussian and admits heavy-tails. We further investigate the tail behavior in varying network architectures and sizes, loss functions, and datasets. Our results open up a different perspective and shed more light on the belief that SGD prefers wide minima.
Towards A Unified Analysis of Random Fourier Features
Zhu Li,Jean-François Ton,Dino Oglic,Dino Sejdinovic
Random Fourier features is a widely used, simple, and effective technique for scaling up kernel methods. The existing theoretical analysis of the approach, however, remains focused on specific learning tasks and typically gives pessimistic bounds which are at odds with the empirical results. We tackle these problems and provide the first unified risk analysis of learning with random Fourier features using the squared error and Lipschitz continuous loss functions. In our bounds, the trade-off between the computational cost and the expected risk convergence rate is problem specific and expressed in terms of the regularization parameter and the number of effective degrees of freedom. We study both the standard random Fourier features method for which we improve the existing bounds on the number of features required to guarantee the corresponding minimax risk convergence rate of kernel ridge regression, as well as a data-dependent modification which samples features proportional to ridge leverage scores and further reduces the required number of features. As ridge leverage scores are expensive to compute, we devise a simple approximation scheme which provably reduces the computational cost without loss of statistical efficiency
Amortized Monte Carlo Integration
Adam Golinski、Yee Whye Teh、Frank Wood、Tom Rainforth
Current approaches to amortizing Bayesian inference focus solely on approximating the posterior distribution. Typically, this approximation is in turn used to calculate expectations for one or more target functions. In this paper, we address the inefficiency of this computational pipeline when the target function(s) are known upfront. To this end, we introduce a method for amortizing Monte Carlo integration. Our approach operates in a similar manner to amortized inference, but tailors the produced amortization artifacts to maximize the accuracy of the resulting expectation calculation(s). We show that while existing approaches have fundamental limitations in the level of accuracy that can be achieved for a given run time computational budget, our framework can, at least in theory, produce arbitrary small errors for a wide range of target functions with O(1) computational cost at run time. Furthermore, our framework allows not only for amortizing over possible datasets, but also over possible target functions.
Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning
Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro A. Ortega, DJ Strouse, Joel Z. Leibo, Nando de Freitas
We propose a unified mechanism for achieving coordination and communication in Multi-Agent Reinforcement Learning (MARL), through rewarding agents for having causal influence over other agents’ actions. Causal influence is assessed using counterfactual reasoning. At each timestep, an agent simulates alternate actions that it could have taken, and computes their effect on the behavior of other agents. Actions that lead to bigger changes in other agents’ behavior are considered influential and are rewarded. We show that this is equivalent to rewarding agents for having high mutual information between their actions. Empirical results demonstrate that influence leads to enhanced coordination and communication in challenging social dilemma environments, dramatically increasing the learning curves of the deep RL agents, and leading to more meaningful learned communication protocols. The influence rewards for all agents can be computed in a decentralized way by enabling agents to learn a model of other agents using deep neural networks. In contrast, key previous works on emergent communication in the MARL setting were unable to learn diverse policies in a decentralized manner and had to resort to centralized training. Consequently, the influence reward opens up a window of new opportunities for research in this area.
Stochastic Beams and Where to Find Them: The Gumbel-Top-k Trick for Sampling Sequences Without Replacement
Wouter Kool, Herke van Hoof, Max Welling
The well-known Gumbel-Max trick for sampling from a categorical distribution can be extended to sample k elements without replacement. We show how to implicitly apply this ‘Gumbel-Top-k’ trick on a factorized distribution over sequences, allowing to draw exact samples without replacement using a Stochastic Beam Search. Even for exponentially large domains, the number of model evaluations grows only linear in k and the maximum sampled sequence length. The algorithm creates a theoretical connection between sampling and (deterministic) beam search and can be used as a principled intermediate alternative. In a translation task, the proposed method compares favourably against alternatives to obtain diverse yet good quality translations. We show that sequences sampled without replacement can be used to construct low-variance estimators for expected sentence-level BLEU score and model entropy.