IJCAI Best Papers
[deep-learning ijcai International Joint Conference on Artificial Intelligence (IJCAI) is one of the best conferences in AI. It used to happen every two years and now is every one year.

2018 Best Paper
SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks

Generating texts of different sentiment labels is getting more and more attention in the area of natural language generation. Recently, Generative Adversarial Net (GAN) has shown promising results in text generation. However, the texts generated by GAN usually suffer from the problems of poor quality, lack of diversity and mode collapse. In this paper, we propose a novel framework - SentiGAN, which has multiple generators and one multi-class discriminator, to address the above problems. In our framework, multiple generators are trained simultaneously, aiming at generating texts of different sentiment labels without supervision. We propose a penalty based objective in the generators to force each of them to generate diversified examples of a specific sentiment label. Moreover, the use of multiple generators and one multi-class discriminator can make each generator focus on generating its own examples of a specific sentiment label accurately. Experimental results on four datasets demonstrate that our model consistently outperforms several state-of-the-art text generation methods in the sentiment accuracy and quality of generated texts.
Reasoning about Consensus when Opinions Diffuse through Majority Dynamics

Opinion diffusion is studied on social graphs where agents hold binary opinions and where social pressure leads them to conform to the opinion manifested by the majority of their neighbors. Within this setting, questions related to whether a minority/majority can spread the opinion it supports to all the other agents are considered. It is shown that, no matter of the underlying graph, there is always a group formed by a half of the agents that can annihilate the opposite opinion. Instead, the influence power of minorities depends on certain features of the given graph, which are NP-hard to be identified. Deciding whether the two opinions can coexist in some stable configuration is NP-hard, too.
R-SVM+: Robust Learning with Privileged Information
In practice, the circumstance that training and test data are clean is not always satisfied. The performance of existing methods in the learning using privileged information (LUPI) paradigm may be seriously challenged, due to the lack of clear strategies to address potential noises in the data. This paper proposes a novel Robust SVM+ (RSVM+) algorithm based on a rigorous theoretical analysis. Under the SVM+ framework in the LUPI paradigm, we study the lower bound of perturbations of both example feature data and privileged feature data, which will mislead the model to make wrong decisions. By maximizing the lower bound, tolerance of the learned model over perturbations will be increased. Accordingly, a novel regularization function is introduced to upgrade a variant form of SVM+. The objective function of RSVM+ is transformed into a quadratic programming problem, which can be efficiently optimized using off-the-shelf solvers. Experiments on realworld datasets demonstrate the necessity of studying robust SVM+ and the effectiveness of the proposed algorithm.
From Conjunctive Queries to Instance Queries in Ontology-Mediated Querying
We consider ontology-mediated queries (OMQs) based on expressive description logics of the ALC family and (unions) of conjunctive queries, studying the rewritability into OMQs based on instance queries (IQs). Our results include exact characterizations of when such a rewriting is possible and tight complexity bounds for deciding rewritability. We also give a tight complexity bound for the related problem of deciding whether a given MMSNP sentence is equivalent to a CSP.
What Game are We Playing? End-to-end Learning in Normal and Extensive from Games
We consider ontology-mediated queries (OMQs) based on expressive description logics of the ALC family and (unions) of conjunctive queries, studying the rewritability into OMQs based on instance queries (IQs). Our results include exact characterizations of when such a rewriting is possible and tight complexity bounds for deciding rewritability. We also give a tight complexity bound for the related problem of deciding whether a given MMSNP sentence is equivalent to a CSP.
Commonsense Knowledge Aware Conversation Generation with Graph Attention
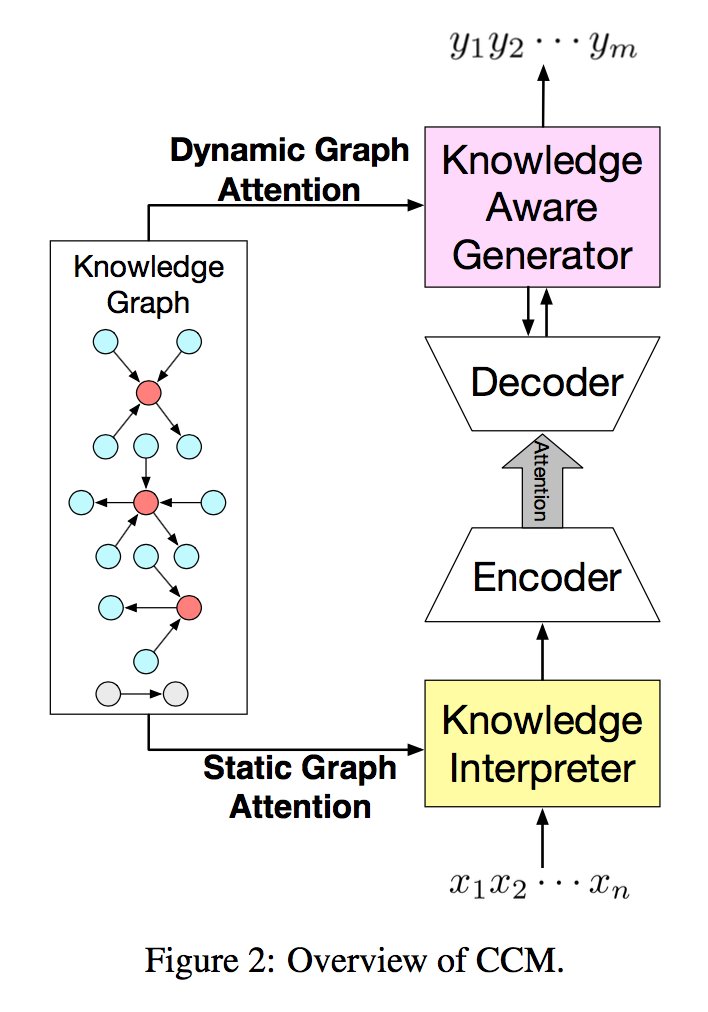
Commonsense knowledge is vital to many natural language processing tasks. In this paper, we present a novel open-domain conversation generation model to demonstrate how large-scale commonsense knowledge can facilitate language understanding and generation. Given a user post, the model retrieves relevant knowledge graphs from a knowledge base and then encodes the graphs with a static graph attention mechanism, which augments the semantic information of the post and thus supports better understanding of the post. Then, during word generation, the model attentively reads the retrieved knowledge graphs and the knowledge triples within each graph to facilitate better generation through a dynamic graph attention mechanism. This is the first attempt that uses large-scale commonsense knowledge in conversation generation. Furthermore, unlike existing models that use knowledge triples (entities) separately and independently, our model treats each knowledge graph as a whole, which encodes more structured, connected semantic information in the graphs. Experiments show that the proposed model can generate more appropriate and informative responses than stateof-the-art baselines.
A Degeneracy Framework for Graph Similarity

The problem of accurately measuring the similarity between graphs is at the core of many applications in a variety of disciplines. Most existing methods for graph similarity focus either on local or on global properties of graphs. However, even if graphs seem very similar from a local or a global perspective, they may exhibit different structure at different scales. In this paper, we present a general framework for graph similarity which takes into account structure at multiple different scales. The proposed framework capitalizes on the wellknown k-core decomposition of graphs in order to build a hierarchy of nested subgraphs. We apply the framework to derive variants of four graph kernels, namely graphlet kernel, shortest-path kernel, Weisfeiler-Lehman subtree kernel, and pyramid match graph kernel. The framework is not limited to graph kernels, but can be applied to any graph comparison algorithm. The proposed framework is evaluated on several benchmark datasets for graph classification. In most cases, the corebased kernels achieve significant improvements in terms of classification accuracy over the base kernels, while their time complexity remains very attractive.
2017 Best Paper
Foundations of Declarative Data Analysis Using Limit Datalog Programs
Motivated by applications in declarative data analysis, we study DatalogZ—an extension of positive Datalog with arithmetic functions over integers. This language is known to be undecidable, so we propose two fragments. In limit DatalogZ predicates are axiomatised to keep minimal/maximal numeric values, allowing us to show that fact entailment is CONEXPTIME-complete in combined, and CONP-complete in data complexity. Moreover, an additional stability requirement causes the complexity to drop to EXPTIME and PTIME, respectively. Finally, we show that stable DatalogZ can express many useful data analysis tasks, and so our results provide a sound foundation for the development of advanced information systems.
Constraint-Based Symmetry Detection in General Game Playing
Symmetry detection is a promising approach for reducing the search tree of games. In General Game Playing (GGP), where any game is compactly represented by a set of rules in the Game Description Language (GDL), the state-of-the-art methods for symmetry detection rely on a rule graph associated with the GDL description of the game. Though such rule-based symmetry detection methods can be applied to various tree search algorithms, they cover only a limited number of symmetries which are apparent in the GDL description. In this paper, we develop an alternative approach to symmetry detection in stochastic games that exploits constraint programming techniques. The minimax optimization problem in a GDL game is cast as a stochastic constraint satisfaction problem (SCSP), which can be viewed as a sequence of one-stage SCSPs. Minimax symmetries are inferred according to the microstructure complement of these one-stage constraint networks. Based on a theoretical analysis of this approach, we experimentally show on various games that the recent stochastic constraint solver MAC-UCB, coupled with constraint-based symmetry detection, significantly outperforms the standard Monte Carlo Tree Search algorithms, coupled with rule-based symmetry detection. This constraint-driven approach is also validated by the excellent results obtained by our player during the last GGP competition.
General Heterogeneous Transfer Distance Metric Learning via Knowledge Fragments Transfer
Transfer learning aims to improve the performance of target learning task by leveraging information (or transferring knowledge) from other related tasks. Recently, transfer distance metric learning (TDML) has attracted lots of interests, but most of these methods assume that feature representations for the source and target learning tasks are the same. Hence, they are not suitable for the applications, in which the data are from heterogeneous domains (feature spaces, modalities and even semantics). Although some existing heterogeneous transfer learning (HTL) approaches is able to handle such domains, they lack flexibility in real-world applications, and the learned transformations are often restricted to be linear. We therefore develop a general and flexible heterogeneous TDML (HTDML) framework based on the knowledge fragment transfer strategy. In the proposed HTDML, any (linear or nonlinear) distance metric learning algorithms can be employed to learn the source metric beforehand. Then a set of knowledge fragments are extracted from the pre-learned source metric to help target metric learning. In addition, either linear or nonlinear distance metric can be learned for the target domain. Extensive experiments on both scene classification and object recognition demonstrate superiority of the proposed method.
2016 Best Paper
Hierarchical Finite State Controllers for Generalized Planning
Finite State Controllers (FSCs) are an effective way to represent sequential plans compactly. By imposing appropriate conditions on transitions, FSCs can also represent generalized plans that solve a range of planning problems from a given domain. In this paper we introduce the concept of hierarchical FSCs for planning by allowing controllers to call other controllers. We show that hierarchical FSCs can represent generalized plans more compactly than individual FSCs. Moreover, our call mechanism makes it possible to generate hierarchical FSCs in a modular fashion, or even to apply recursion. We also introduce a compilation that enables a classical planner to generate hierarchical FSCs that solve challenging generalized planning problems. The compilation takes as input a set of planning problems from a given domain and outputs a single classical planning problem, whose solution corresponds to hierarchical FSC.
Recursive Decomposition for Nonconvex Optimization

Continuous optimization is an important problem in many areas of AI, including vision, robotics, probabilistic inference, and machine learning. Unfortunately, most real-world optimization problems are nonconvex, causing standard convex techniques to find only local optima, even with extensions like random restarts and simulated annealing. We observe that, in many cases, the local modes of the objective function have combinatorial structure, and thus ideas from combinatorial optimization can be brought to bear. Based on this, we propose a problem-decomposition approach to nonconvex optimization. Similarly to DPLL-style SAT solvers and recursive conditioning in probabilistic inference, our algorithm, RDIS, recursively sets variables so as to simplify and decompose the objective function into approximately independent subfunctions, until the remaining functions are simple enough to be optimized by standard techniques like gradient descent. The variables to set are chosen by graph partitioning, ensuring decomposition whenever possible. We show analytically that RDIS can solve a broad class of nonconvex optimization problems exponentially faster than gradient descent with random restarts. Experimentally, RDIS outperforms standard techniques on problems like structure from motion and protein folding.
Bayesian Active Learning for Posterior Estimation
This paper studies active posterior estimation in a Bayesian setting when the likelihood is expensive to evaluate. Existing techniques for posterior estimation are based on generating samples representative of the posterior. Such methods do not consider efficiency in terms of likelihood evaluations. In order to be query efficient we treat posterior estimation in an active regression framework. We propose two myopic query strategies to choose where to evaluate the likelihood and implement them using Gaussian processes. Via experiments on a series of synthetic and real examples we demonstrate that our approach is significantly more query efficient than existing techniques and other heuristics for posterior estimation.
2013 Best Paper
Bayesian Optimization in High Dimensions via Random Embeddings
Bayesian optimization techniques have been successfully applied to robotics, planning, sensor placement, recommendation, advertising, intelligent user interfaces and automatic algorithm configuration. Despite these successes, the approach is restricted to problems of moderate dimension, and several workshops on Bayesian optimization have identified its scaling to high dimensions as one of the holy grails of the field. In this paper, we introduce a novel random embedding idea to attack this problem. The resulting Random EMbedding Bayesian Optimization (REMBO) algorithm is very simple and applies to domains with both categorical and continuous variables. The experiments demonstrate that REMBO can effectively solve high-dimensional problems, including automatic parameter configuration of a popular mixed integer linear programming solver
Flexibility and Decoupling in the Simple Temporal Problem
In this paper we concentrate on finding a suitable metric to determine the flexibility of a Simple Temporal Problem (STP). After reviewing some flexibility metrics that have been proposed, we conclude that these metrics fail to capture the correlation between events specified in the STP, resulting in an overestimation of the available flexibility in the system. We propose to use an intuitively more acceptable flexibility metric based upon uncorrelated time-intervals for the allowed starting times of events in an STP. This metric is shown to be computable in low-polynomial time. As a byproduct of the flexibility computation, we get a decomposition of the STN almost for free: for every possible k-partitioning of the event space, a decomposition can be computed in O(k)-time. Even more importantly, we show that contrary to popular belief, such a decomposition does not affect the flexibility of the original STP.
2011 Best Paper
Unweighted Coalitional Manipulation Under the Borda Rule is NP-Hard
The Borda voting rule is a positional scoring rule where, for m candidates, for every vote the first candidate receives m − 1 points, the second m − 2 points and so on. A Borda winner is a candidate with highest total score. It has been a prominent open problem to determine the computational complexity of UNWEIGHTED COALITIONAL MANIPULATION UNDER BORDA: Can one add a certain number of additional votes (called manipulators) to an election such that a distinguished candidate becomes a winner? We settle this open problem by showing NP-hardness even for two manipulators and three input votes. Moreover, we discuss extensions and limitations of this hardness result.
On the Decidability of Connectedness Constraints in 2D and 3D Euclidean Spaces
We investigate (quantifier-free) spatial constraint languages with equality, contact and connectedness predicates, as well as Boolean operations on regions, interpreted over low-dimensional Euclidean spaces. We show that the complexity of reasoning varies dramatically depending on the dimension of the space and on the type of regions considered. For example, the logic with the interior-connectedness predicate (and without contact) is undecidable over polygons or regular closed sets in R2, EXPTIMEcomplete over polyhedra in R3, and NP-complete over regular closed sets in R3.
Nested Rollout Policy Adaptation for Monte Carlo Tree Search
Monte Carlo tree search (MCTS) methods have had recent success in games, planning, and optimization. MCTS uses results from rollouts to guide search; a rollout is a path that descends the tree with a randomized decision at each ply until reaching a leaf. MCTS results can be strongly influenced by the choice of appropriate policy to bias the rollouts. Most previous work on MCTS uses static uniform random or domain-specific policies. We describe a new MCTS method that dynamically adapts the rollout policy during search, in deterministic optimization problems. Our starting point is Cazenave’s original Nested Monte Carlo Search (NMCS), but rather than navigating the tree directly we instead use gradient ascent on the rollout policy at each level of the nested search. We benchmark this new Nested Rollout Policy Adaptation (NRPA) algorithm and examine its behavior. Our test problems are instances of Crossword Puzzle Construction and Morpion Solitaire. Over moderate time scales NRPA can substantially improve search efficiency compared to NMCS, and over longer time scales NRPA improves upon all previous published solutions for the test problems. Results include a new Morpion Solitaire solution that improves upon the previous human-generated record that had stood for over 30 years.
2009 Best Paper
Consequence-Driven Reasoning for Horn SHIQ Ontologies
We present a novel reasoning procedure for Horn SHIQ ontologies—SHIQ ontologies that can be translated to the Horn fragment of first-order logic. In contrast to traditional reasoning procedures for ontologies, our procedure does not build models or model representations, but works by deriving new consequent axioms. The procedure is closely related to the so-called completion-based procedure for EL++ ontologies, and can be regarded as an extension thereof. In fact, our procedure is theoretically optimal for Horn SHIQ ontologies as well as for the common fragment of EL++ and SHIQ. A preliminary empirical evaluation of our procedure on large medical ontologies demonstrates a dramatic improvement over existing ontology reasoners. Specifically, our implementation allows the classification of the largest available OWL version of Galen. To the best of our knowledge no other reasoner is able to classify this ontology
Learning Conditional Preference Networks with Queries
We investigate the problem of eliciting CP-nets in the well-known model of exact learning with equivalence and membership queries. The goal is to identify a preference ordering with a binary-valued CP-net by guiding the user through a sequence of queries. Each example is a dominance test on some pair of outcomes. In this setting, we show that acyclic CP-nets are not learnable with equivalence queries alone, while they are learnable with the help of membership queries if the supplied examples are restricted to swaps. A similar property holds for tree CP-nets with arbitrary examples. In fact, membership queries allow us to provide attributeefficient algorithms for which the query complexity is only logarithmic in the number of attributes. Such results highlight the utility of this model for eliciting CP-nets in large multi-attribute domains.
2007 Best Paper
Performance Analysis of Online Anticipatory Algorithms for Large Multistage Stochastic Integer Programs
Despite significant algorithmic advances in recent years, finding optimal policies for large-scale, multistage stochastic combinatorial optimization problems remains far beyond the reach of existing methods. This paper studies a complementary approach, online anticipatory algorithms, that make decisions at each step by solving the anticipatory relaxation for a polynomial number of scenarios. Online anticipatory algorithms have exhibited surprisingly good results on a variety of applications and this paper aims at understanding their success. In particular, the paper derives sufficient conditions under which online anticipatory algorithms achieve good expected utility and studies the various types of errors arising in the algorithms including the anticipativity and sampling errors. The sampling error is shown to be negligible with a logarithmic number of scenarios. The anticipativity error is harder to bound and is shown to be low, both theoretically and experimentally, for the existing applications.
Automated Heart Wall Motion Abnormality Detection From Ultrasound Images using Bayesian Networks
Coronary Heart Disease can be diagnosed by measuring and scoring regional motion of the heart wall in ultrasound images of the left ventricle (LV) of the heart. We describe a completely automated and robust technique that detects diseased hearts based on detection and automatic tracking of the endocardium and epicardium of the LV. The local wall regions and the entire heart are then classified as normal or abnormal based on the regional and global LV wall motion. In order to leverage structural information about the heart we applied Bayesian Networks to this problem, and learned the relations among the wall regions off of the data using a structure learning algorithm. We checked the validity of the obtained structure using anatomical knowledge of the heart and medical rules as described by doctors. The resultant Bayesian Network classifier depends only on a small subset of numerical features extracted from dual-contours tracked through time and selected using a filterbased approach. Our numerical results confirm that our system is robust and accurate on echocardiograms collected in routine clinical practice at one hospital; our system is built to be used in real-time.
Building Structure into Local Search for SAT
Local search procedures for solving satisfiability problems have attracted considerable attention since the development of GSAT in 1992. However, recent work indicates that for many real-world problems, complete search methods have the advantage, because modern heuristics are able to effectively exploit problem structure. Indeed, to develop a local search technique that can effectively deal with variable dependencies has been an open challenge since 1997. In this paper we show that local search techniques can effectively exploit information about problem structure producing significant improvements in performance on structured problem instances. Building on the earlier work of Ostrowski et al. we describe how information about variable dependencies can be built into a local search, so that only independent variables are considered for flipping. The cost effect of a flip is then dynamically calculated using a dependency lattice that models dependent variables using gates (specifically and, or and equivalence gates). The experimental study on hard structured benchmark problems demonstrates that our new approach significantly outperforms the previously reported best local search techniques.
2005 Best Paper
Learning Coordination Classifiers
We present a new approach to ensemble classification that requires learning only a single base classifier. The idea is to learn a classifier that simultaneously predicts pairs of test labels—as opposed to learning multiple predictors for single test labels— then coordinating the assignment of individual labels by propagating beliefs on a graph over the data. We argue that the approach is statistically well motivated, even for independent identically distributed (iid) data. In fact, we present experimental results that show improvements in classification accuracy over single-example classifiers, across a range of iid data sets and over a set of base classifiers. Like boosting, the technique increases representational capacity while controlling variance through a principled form of classifier combination.
Solving Checkers
AI has had notable success in building highperformance game-playing programs to compete against the best human players. However, the availability of fast and plentiful machines with large memories and disks creates the possibility of a game. This has been done before for simple or relatively small games. In this paper, we present new ideas and algorithms for solving the game of checkers. Checkers is a popular game of skill with a search space of possible positions. This paper reports on our first result. One of the most challenging checkers openings has been solved – the White Doctor opening is a draw. Solving roughly 50 more openings will result in the game-theoretic value of checkers being determined
A Probabilistic Model of Redundancy in Information Extraction
Unsupervised Information Extraction (UIE) is the task of extracting knowledge from text without using hand-tagged training examples. A fundamental problem for both UIE and supervised IE is assessing the probability that extracted information is correct. In massive corpora such as the Web, the same extraction is found repeatedly in different documents. How does this redundancy impact the probability of correctness? This paper introduces a combinatorial “balls-andurns” model that computes the impact of sample size, redundancy, and corroboration from multiple distinct extraction rules on the probability that an extraction is correct. We describe methods for estimating the model’s parameters in practice and demonstrate experimentally that for UIE the model’s log likelihoods are 15 times better, on average, than those obtained by Pointwise Mutual Information (PMI) and the noisy-or model used in previous work. For supervised IE, the model’s performance is comparable to that of Support Vector Machines, and Logistic Regression.
2003 Best Paper
Approximating Game-Theoretic Optimal Strategies for Full-scale Poker
The computation of the first complete approximations of game-theoretic optimal strategies for fullscale poker is addressed. Several abstraction techniques are combined to represent the game of 2-player Texas Hold’em, having size O(1018), using closely related models each having size 0(1O7). Despite the reduction in size by a factor of 100 billion, the resulting models retain the key properties and structure of the real game. Linear programming solutions to the abstracted game are used to create substantially improved poker-playing programs, able to defeat strong human players and be competitive against world-class opponents.
Thin Junction Tree Filters for Simultaneous Localization and Mapping
Simultaneous Localization and Mapping (SLAM ) is a fundamental problem in mobile robotics: while a robot navigates in an unknown environment, it must incrementally build a map of its surroundings and, at the same time, localize itself within that map. One popular solution is to treat SLAM as an estimation problem and apply the Kalman filter; this approach is elegant, but it does not scale well: the size of the belief state and the time complexity of the filter update both grow quadratically in the number of landmarks in the map. This paper presents a filtering technique that maintains a tractable approximation of the belief state as a thin junction tree. The junction tree grows under filter updates and is periodically “thinned” via efficient maximum likelihood projections so inference remains tractable. When applied to the SLAM problem, these thin junction tree filters have a linearspace belief state and a linear-time filtering operation. Further approximation yields a filtering operation that is often constant-time. Experiments on a suite of SLAM problems validate the approach.
2001 Best Paper
Complexity Results for Structure-Based Causality
We give a precise picture of the computational complexity of causal relationships in Pearl’s structural models, where we focus on causality between variables, event causality, and probabilistic causality. As for causality between variables, we consider the notions of causal irrelevance, cause, cause in a context, direct cause, and indirect cause. As for event causality, we analyze the complexity of the notions of necessary and possible cause, and of the sophisticated notions of weak and actual cause by Halpern and Pearl. In the course of this, we also prove an open conjecture by Halpern and Pearl, and establish other semantic results. We then analyze the complexity of the probabilistic notions of probabilistic causal irrelevance, likely causes of events, and occurrences of events despite other events. Moreover, we consider decision and optimization problems involving counterfactual formulas. To our knowledge, no complexity aspects of causal relationships in the structural-model approach have been considered so far, and our results shed light on this issue.