MovieChat From Dense Token to Sparse Memory for Long Video Understanding
[video-chat multimodal video-chatgpt deep-learning movie-chat transformer video-llama This is my reading note on MovieChat: From Dense Token to Sparse Memory for Long Video Understanding. This paper proposes a method for long video understands it utilizes existing image encoder to extract tokens form the video via sliding window. A short term memory is a FIFO of those tokens, a long term memory is to merge the similar tokens. Those short term memory and long term memory are then appended after the question and feed to the LLM. The alignment of visual features to LLM purely depends on the existing image encoder.
Introduction
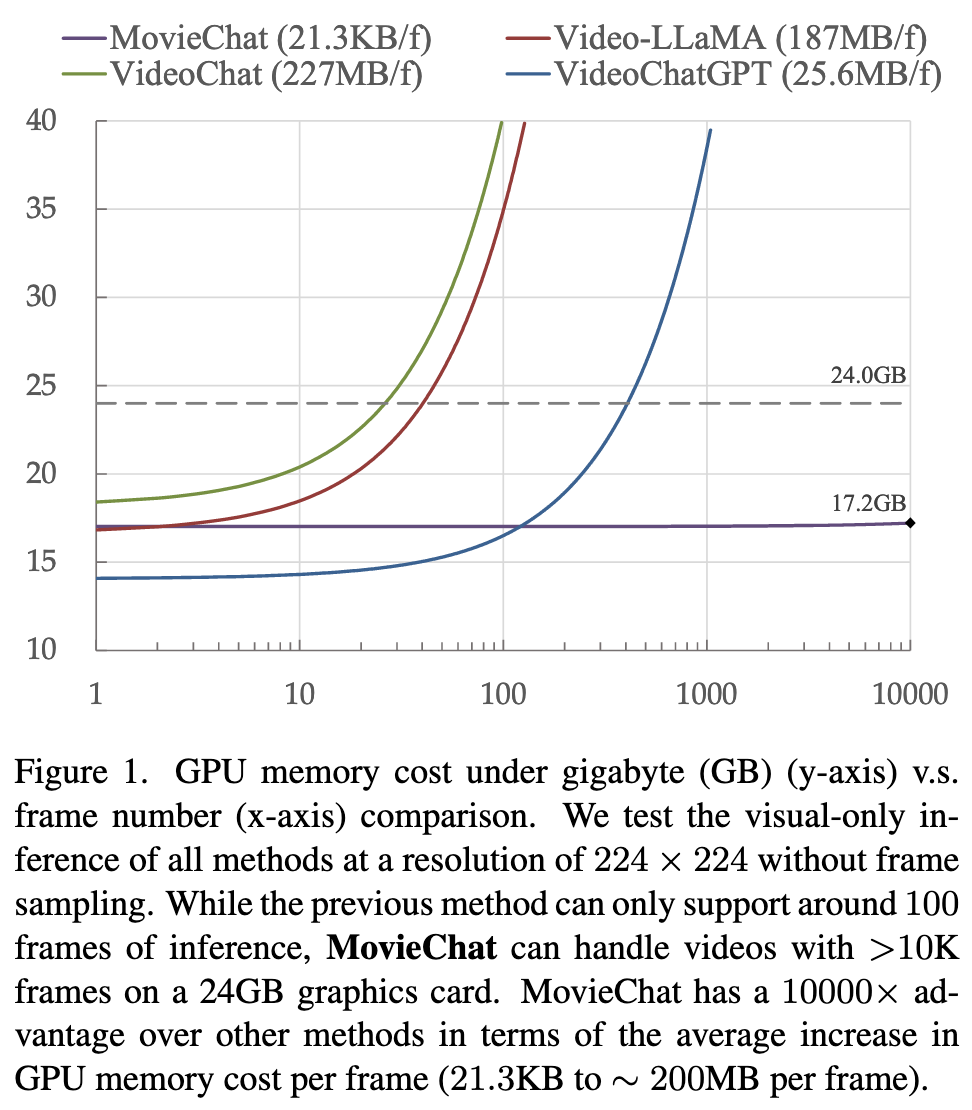
For long videos, the computation complexity, memory cost, and long-term temporal connection are the remaining challenges. Inspired by Atkinson-Shiffrin memory model, we develop an memory mechanism including a rapidly updated short-term memory and a compact thus sustained long-term memory. We employ tokens in Transformers as the carriers of memory. (p. 1)
Relation Work
The common paradigm in the field of video foundation models is now characterized by the combination of extensive large-scale video-language pretraining, followed by fine-tuning on specific downstream tasks [45,46,48,57,77,89,96,111]. Such paradigm depends on end-to-end video-language joint training with pretext pre-training tasks such as masked language modeling [47], masked video modeling [80, 87], video-language masked modeling [25], video-text matching [86], and video-text contrastive learning [96]. (p. 2)
BLIP2 [41] proposes a generic and efficient pre-training strategy that bootstraps vision-language pre-training from off-theshelf frozen pre-trained image encoders and frozen large language models (p. 2)
MeMOT [12] build a large spatiotemporal memory that stores the past observations of the tracked objects. XMem [15] develop an architecture that incorporates multiple independent yet deeplyconnected feature memory stores to handle long videos with thousands frames. (p. 2)
Unlike using embedded feature given by certain visual encoder, we found that using tokens in Transformers [84] as the carriers of memory suitable for both LLMs (p. 2) and ViT [20] based visual encoder. Our proposed method mainly focus on reducing the redundant of visual tokens in video and building a memory mechanism to pass the information among large temporal range. (p. 3)
Proposed Method
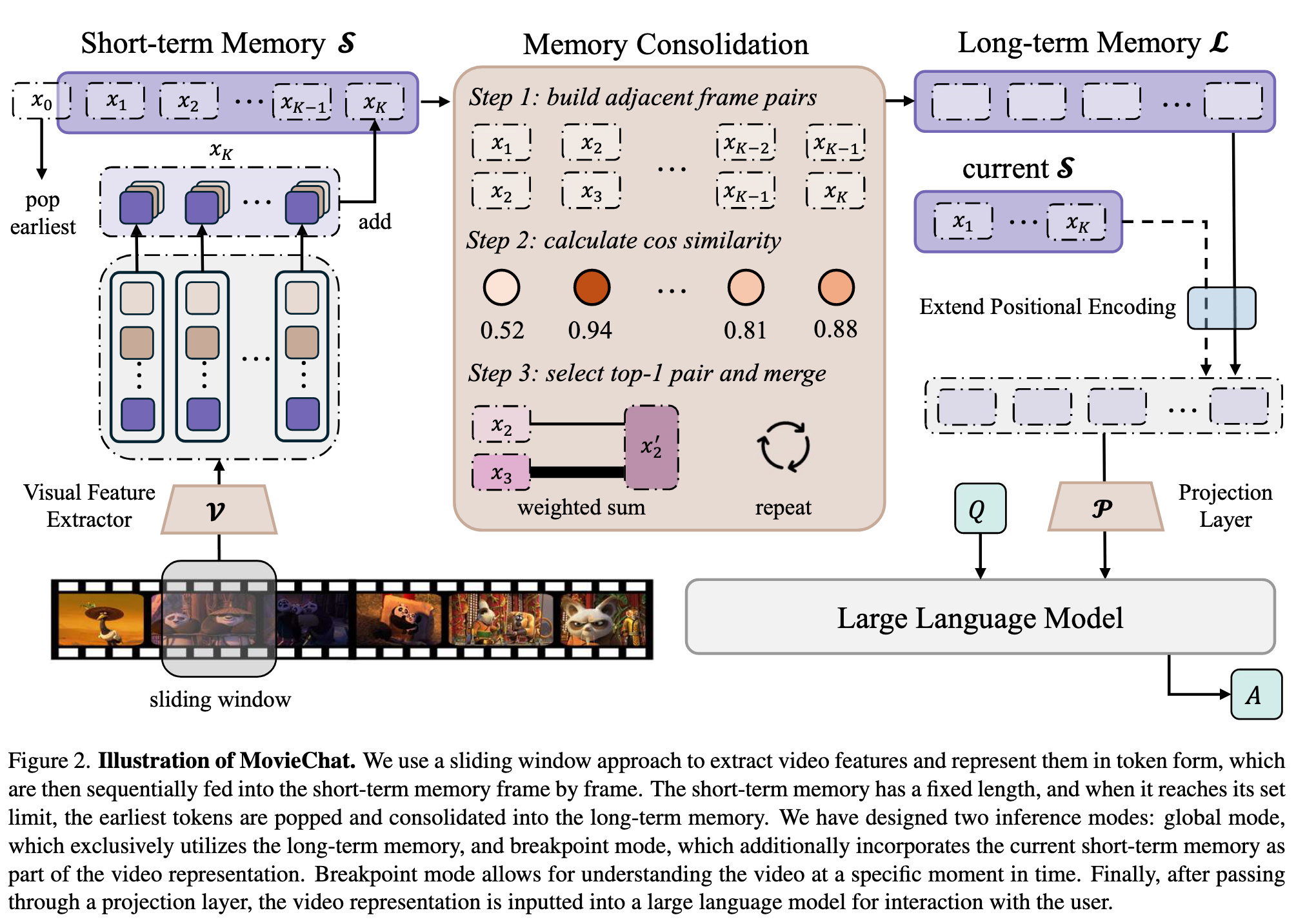
MovieChat is designed for ultra-long videos (>10K frames) understanding through interactive dialogue with the user. To address the impractical storage demands of concurrently storing a vast number of frames in both GPU memory and RAM, we employ a sliding window approach to efficiently process the video (p. 3)
we simply use image-based model to get frame wise feature in the form of tokens. To be specific, we utilize pre-trained models as our visual feature extractor, including the ViT-G/14 from EVA-CLIP [23] and the Q-former from BLIP-2 [42] (p. 3)

Short-term memory stores the visual tokens in a temporary buffer. The previously extracted visual features by sliding window K times without further processing are used to construct short-term memory (p. 4)
Long term memory. To this end, we propose a method to merge temporally adjacent similar frames. This method transforms the dense tokens to the sparse memory and storing them in long-term memory. (p. 4)
To be specific, as shown in Algorithm 1, we conduct memory consolidation by merging the most similar tokens in the adjacent frames following ToMe [10]. We found that the token enbedding in transformers already summarize the information of each frame for use in cos similarity (p. 4)
In order to handle long enough long memory, we adopted the hierarchical decomposed positional encoding method proposed by Su et al. [75], extending the absolute positional encoding of length n to n2 (p. 4)
Inference
Global mode. Global mode is defined as the understanding and question-answering for the whole video. In this case, we only use long-term memory L as the video representation V. Breakpoint mode. Breakpoint mode is defined as understanding specific moments in a video. Since events have continuity, we need to consider not only the information directly related to the moments stored in short-term memory S but also the information indirectly related stored in long-term memory L. Based on this, we hypothesize that when querying the movie at a specific moment, the video representation V should be the aggregation of L, S, and the current video clip feature x. We found that simply concatenating these items yields excellent performance. We (p. 4)
After that, the video representation V goes through a qformer and a linear projection layer before being fed into the LLM, which can be formulated as: A = L(Q,P(V)), (4) where P is the projection from visual space to text space, L is the large language model, A, Q are the answer or instruction and the question. (p. 4)
Experiment Results