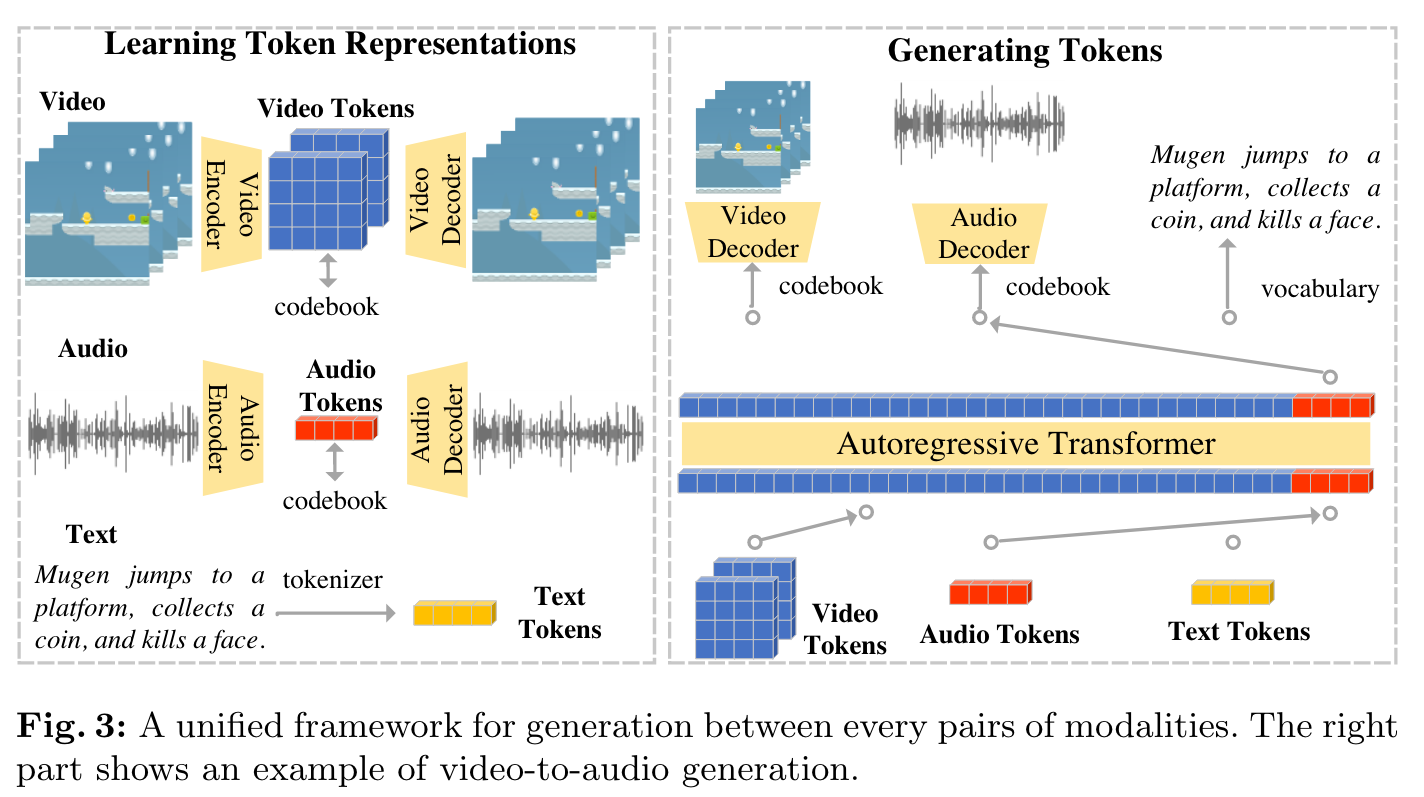
MUGEN A Playground for Video-Audio-Text Multimodal Understanding and GENeration
[text2video multimodal dataset deep-learning audio mugen transformer text2image This is my reading note for MUGEN: A Playground for Video-Audio-Text Multimodal Understanding and GENeration. In this paper, we introduce MUGEN, a large-scale controllable video-audio- text dataset with rich annotations for multimodal understanding and generation.
Introduction
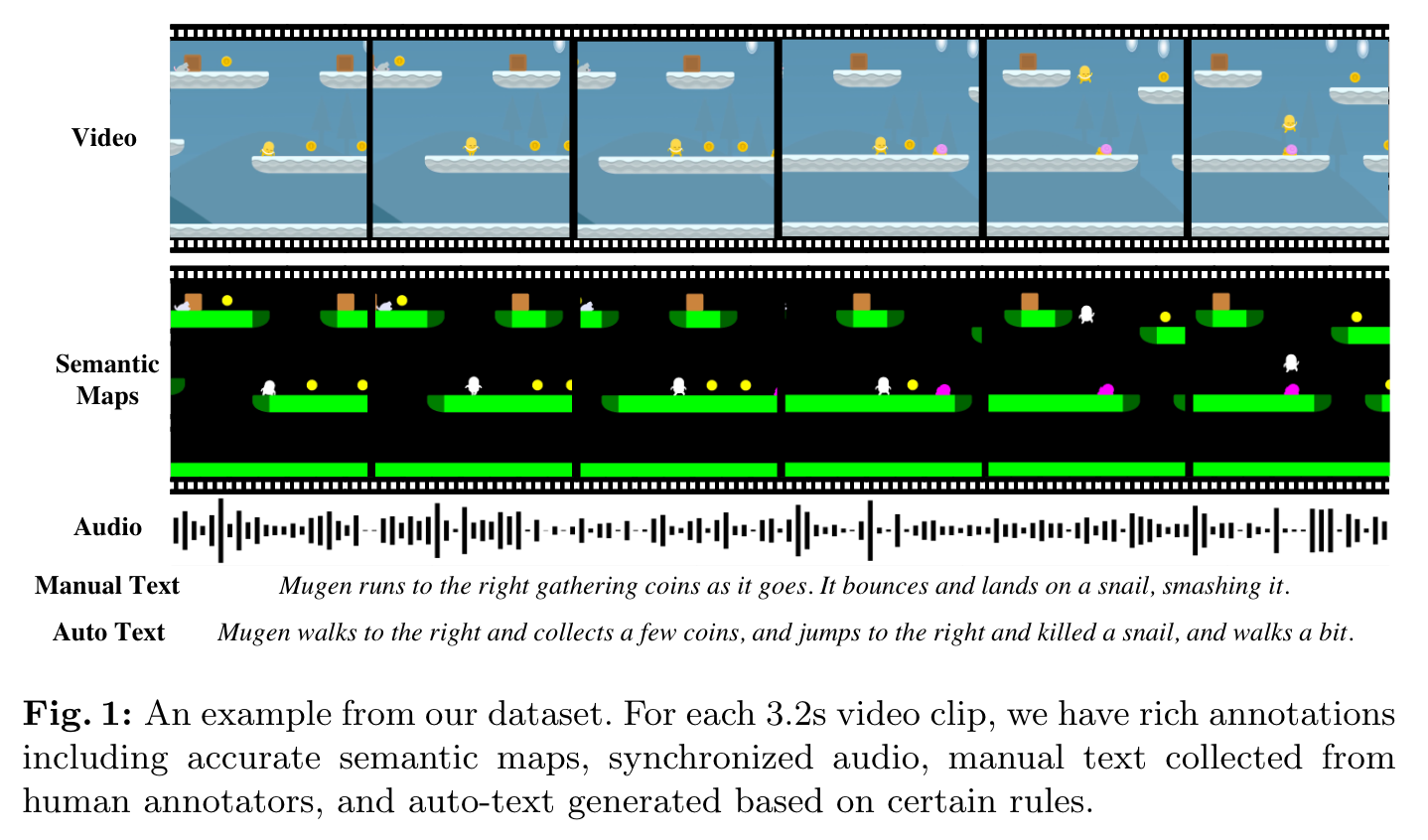
To collect videos, we train reinforcement learning (RL) agents to navigate the world and record gameplay. To increase video diversity and reduce bias towards the actions of any single agent, we trained 14 RL agents with different objectives. We record 233K videos of gameplay where the game environment is procedurally generated, so there are no video duplicates. We then sample 375K 3.2s video clips from this video set to collect text descriptions from human annotators (which we call “manual text”). For each video clip, there are additional annotations that come for free: 1) audio is generated from a set of background music and foreground sound effects; 2) accurate semantic maps are generated for each frame using the game assets; 3) automatic text descriptions (“auto-text”) are generated based on Mugen’s actions and language templates (p. 3)
Related Work
Existing multimodal datasets belong to two categories based on the visual content: open world (in-the-wild environments) and closed world (constrained environments). Open world datasets such as MSCOCO [45], ConceptualCaptions [6], and WIT [64] are widely used for image-text research. CLEVR [30] is a closed world dataset collected by arranging different 3D shapes on a clean background, which enables systematic progress in visual reasoning by reducing the complexity and bias from the real world. (p. 4)
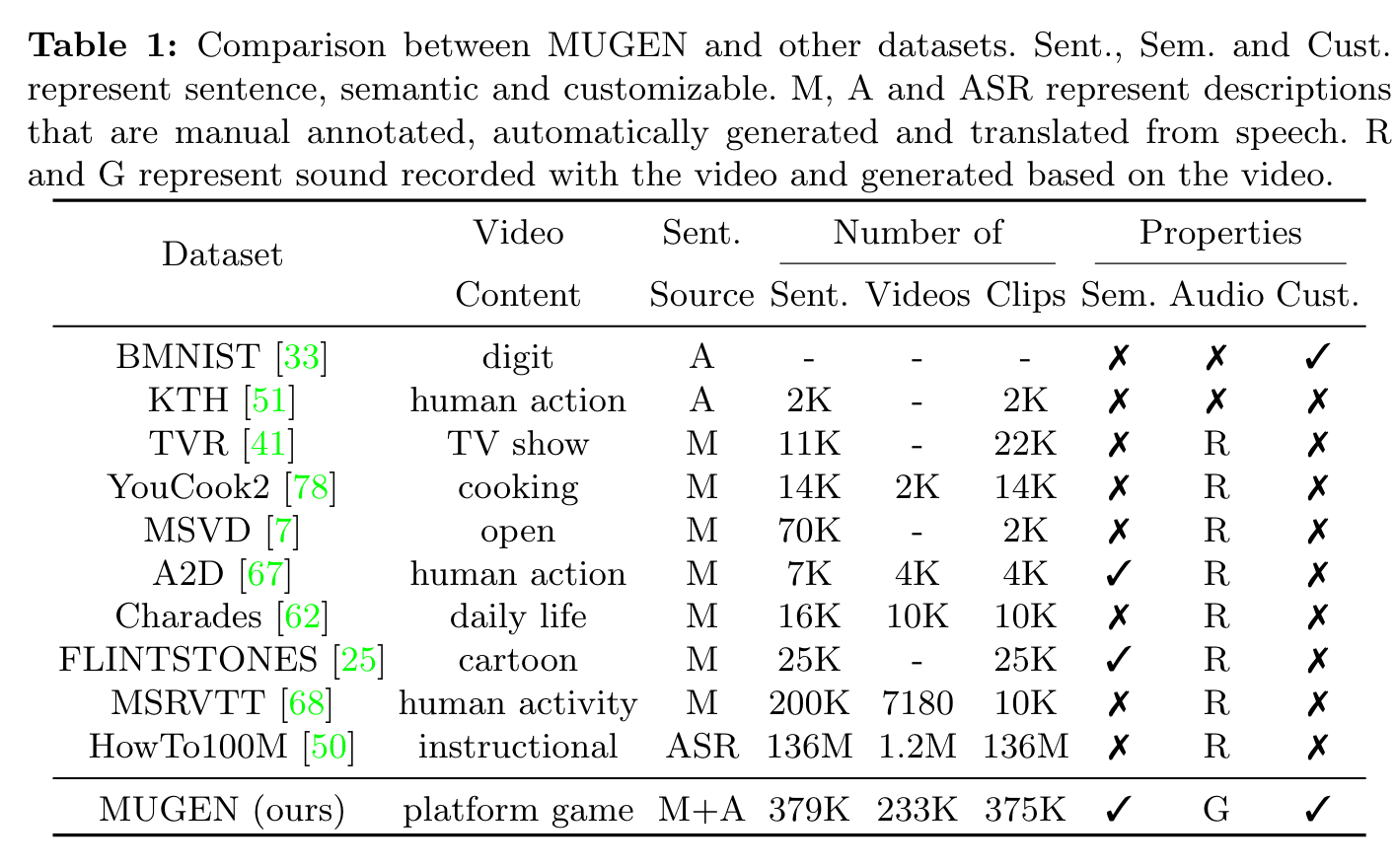
Most video-text datasets are open world. MSRVTT [68], ANetCap [37], MSVD [7], and DiDeMo [3] contain videos of sports and human actions col- lected from the web. YouCook2 [78] and HowTo100M [50] contain instructional videos collected from YouTube. TVR [41], TVQA [40], and LSMDC [57] are collected from TV series and movies. Ego4D [24] is collected by people wearing an egocentric camera recording everyday activities around the world. Videos in these datasets contain complex backgrounds and diverse events, which makes them very challenging. Datasets from constrained environments, e.g. Bouncing MNIST (BMNIST) [33] and KTH [51], have been proposed. These datasets don’t capture some of the core challenges in videos such as multiple entities interact- ing with each other in meaningful ways. FLINTSTONES [25] is created from an animated series, but the scenes are too diverse for the size of the dataset. In contrast, MUGEN simplifies the visual complexities of the scenes and objects, but captures complex motion and interactions between multiple entities. (p. 4)
MUGEN Dataset
OpenAI’s CoinRun is a platform game developed for quantifying generaliza- tion of RL agents [11,15,29]. The game has a single main character (who we call Mugen) with the objective to collect coins without being killed by monsters. Each level has a number of coins and monsters, and the level ends when Mugen collects all coins, Mugen is killed by a monster, or the level times out after 21 seconds. The environment is procedurally generated, with each level having a unique configuration of platforms, coins, and monsters. (p. 6)
Audio
The audio consists of two layers, sound effects and background music. We chose 8 sound effects corresponding to Mugen’s core actions: walk, jump, collect coin, kill monster, power-up, climb ladder, bump head, die. Each sound effect is triggered by these actions, and one sound effect plays at a time. Background music features 2 themes for the space and snow game themes. Background music is layered with the sound effect audio to produce the full audio track. (p. 6)
Video Collection
We train RL agents to navigate the environment and collect gameplay videos. We use an IMPALA-CNN architecture [16] and train agents with Proximal Policy Optimization [59]. Inputs to the agent include the current game frame and the agent’s velocity. (p. 6)
Instead, we save all metadata such as world lay- out and character movements in a json format, from which we can render RGB frames and pixel-accurate segmentation maps at any resolution up to 1400×1400 on-the-fly, resulting in more efficient data storage. (p. 7)
Manual Text
We split the 233K videos into 3.2s (96 frames) clips and ask annotators to describe in 1-2 sentences what happens in the short video. (p. 7)
Auto-Text
In addition to collecting human annotation, we also developed a template-based algorithm to automatically generate textual descriptions for videos based on game engine metadata. (p. 7)