A Comprehensive Survey on Multimodal Recommender Systems Taxonomy, Evaluation, and Future Directions
[multimodal recommendation deep-learning review This is my reading note for A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions. This paper provides a review for multimodality recommendation system. However, it doesn’t cover the method based on transformer. It still provides a good review on the metric of recommendation system.
Introduction
The algorithms of recommendation could be classified into collaborative filtering (CF), content-based filtering and hybrid recommendation system [43]. CF is based on analyzing and gathering the user’s historical behaviors data, which includes the historical interactions (e.g., clicks, look-through, purchases) and user preference (e.g., ratings). The content-based filtering suggests products based on the user profile and item profile of the user. The item is described with the keywords and the user’s profile will express the types of items the user likes. The main idea of this method is the user will probably choose similar items that they like before. (p. 2)
The users and items with few or even no interactions will influence the accuracy of recommendations. In order to alleviate the data sparsity problem [75, 77] and cold start issue, multimodal information has been introduced into the recommendation system. (p. 2)
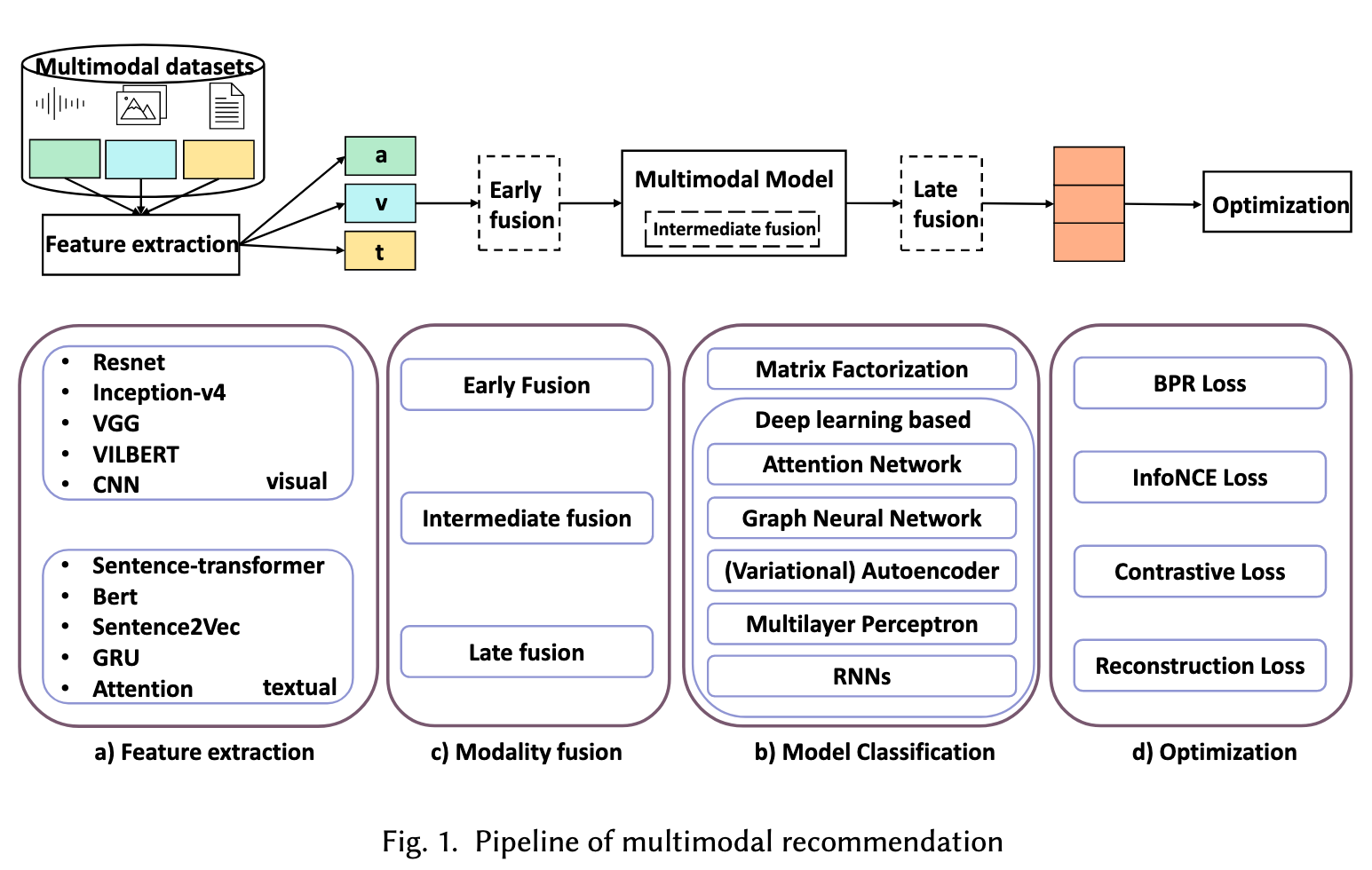
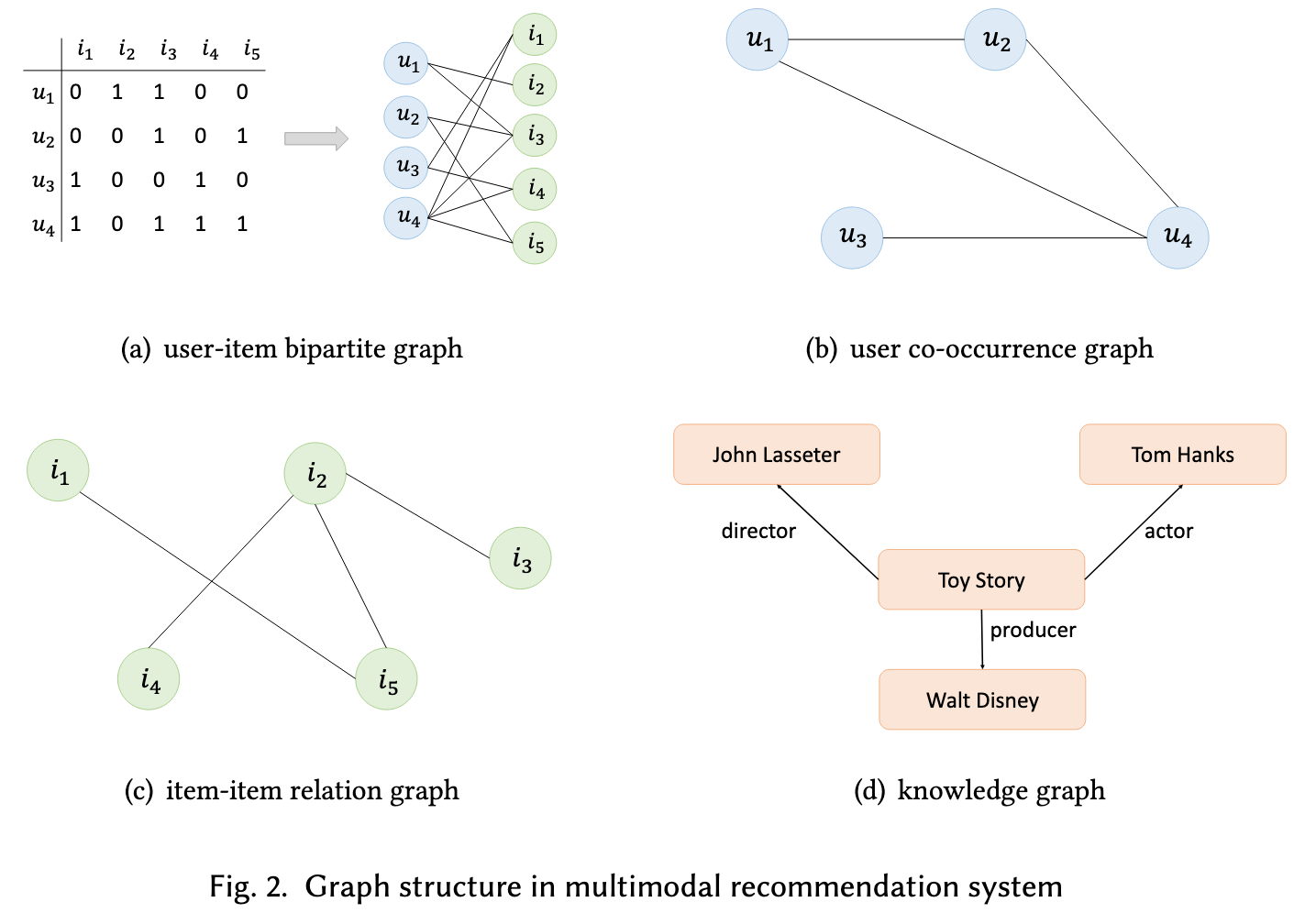
In order to incorporate multimodal information into the recommendation system, the current method is extracting the features from different modalities and then using the modality fusion result as the side information or the item representation. (p. 2)
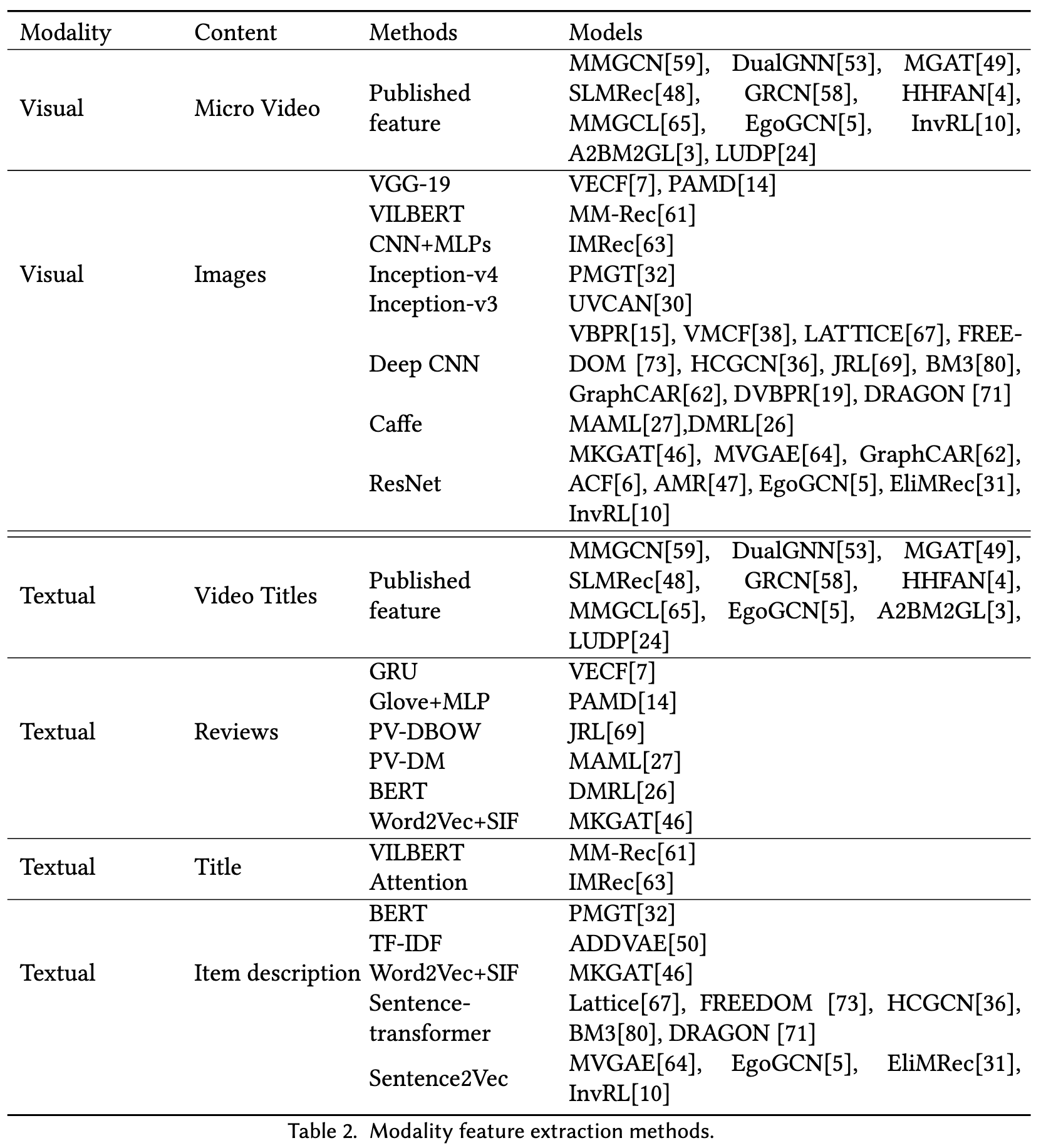
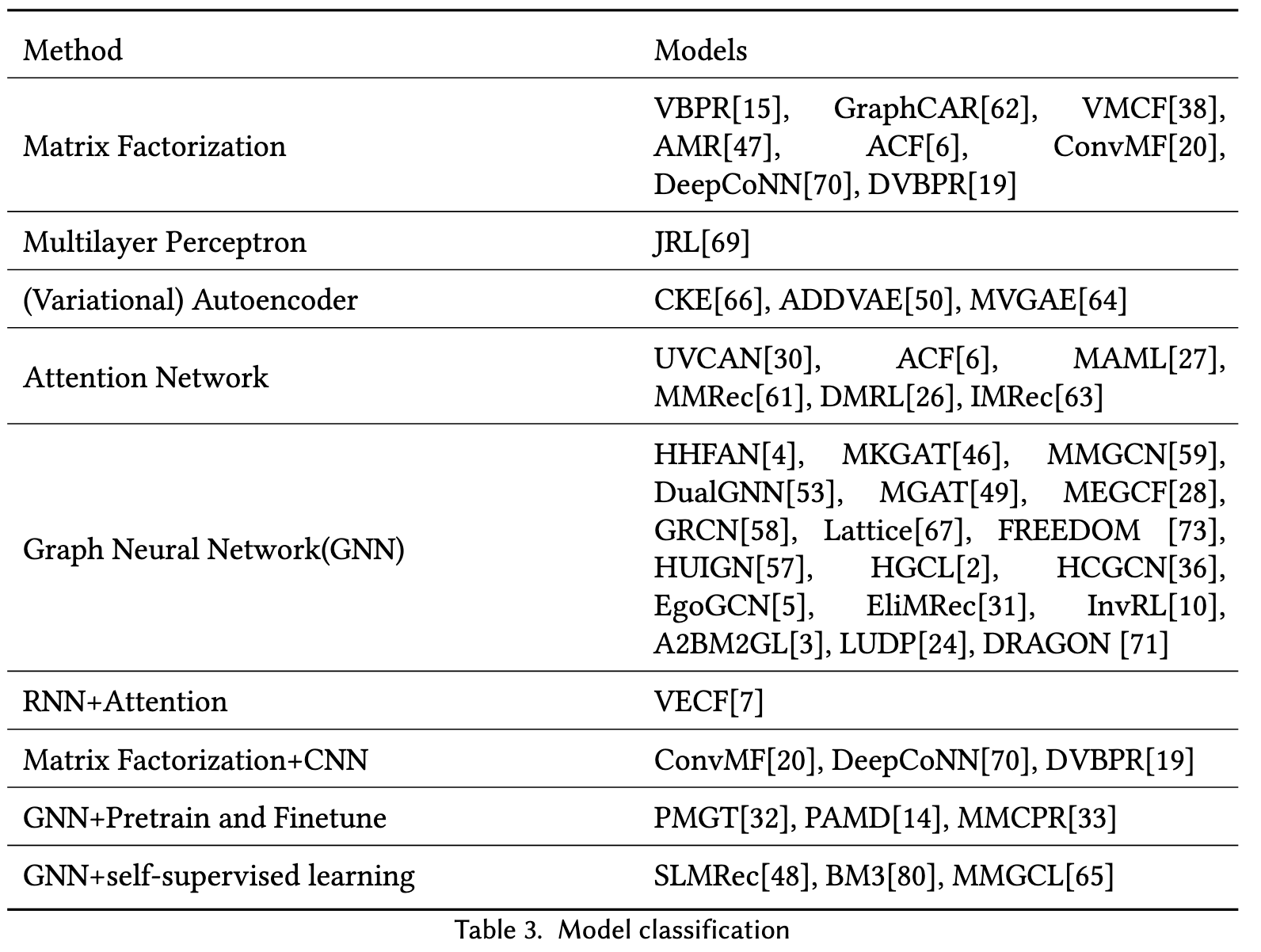
VBPR [15] is the first model that considers introducing visual features into the recommendation system by concatenating visual embeddings with id embeddings as the item representation. [53, 58, 59] utilize the GCN-based methods to produce the representations of each modality and then fuse them together as the final representations. Except for fusing the modality representations, the knowledge graph based modality side information is also introduced into the multimodal recommendation [46]. (p. 2)
MMGCN [59], MGAT [49], DualGNN [53] and SLMRec [48] are the micro video recommendation models that utilize description, captions, audio, and frames inside the video to model the multimodal user preference on the micro-video. (p. 2)
FEATURE EXTRACTION
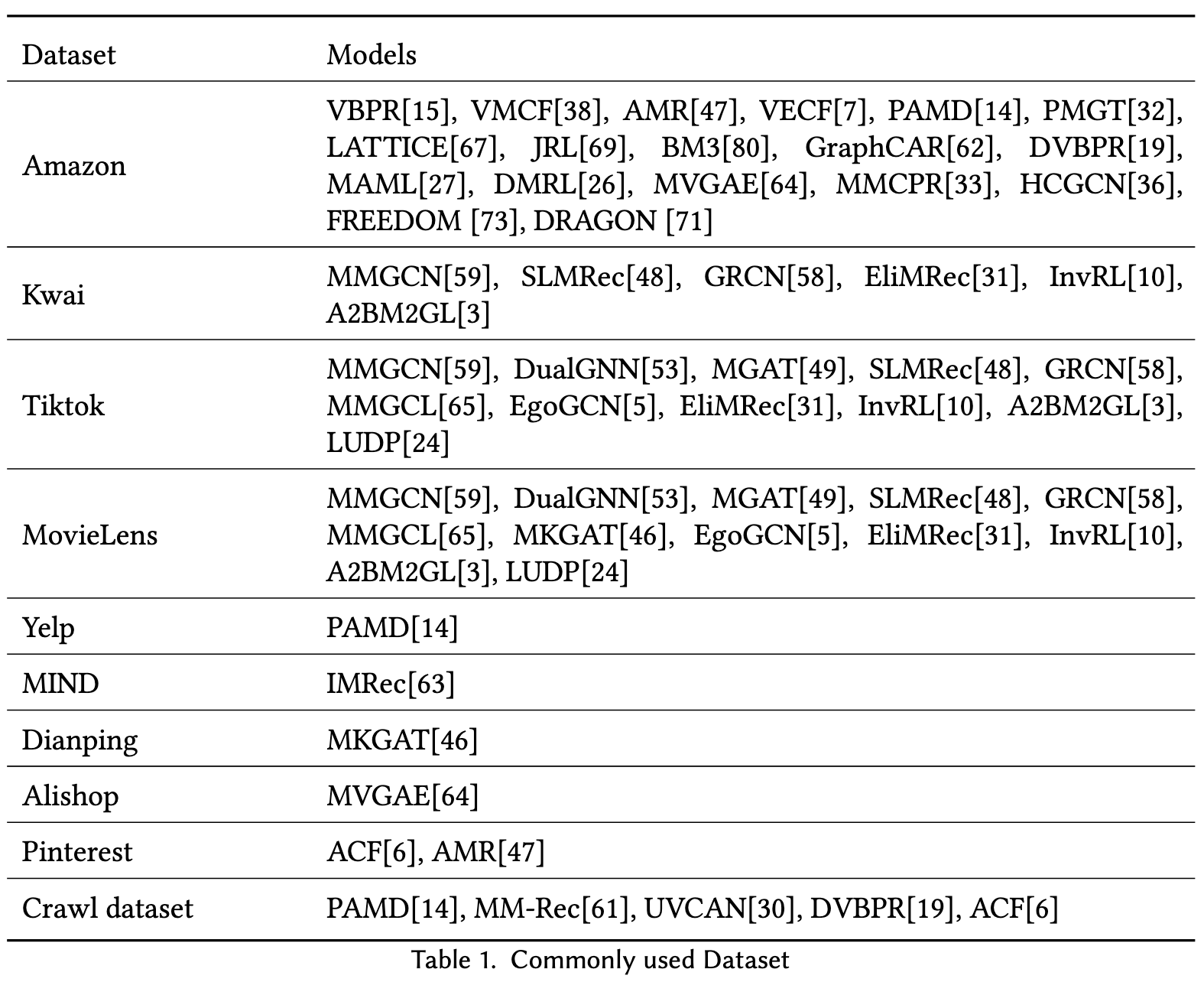
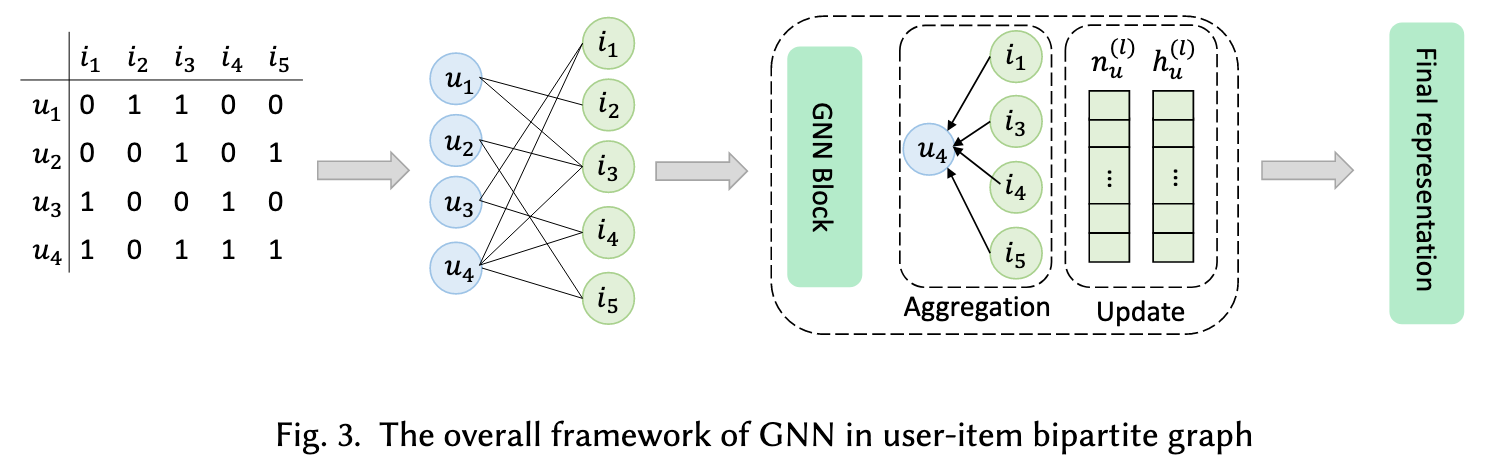
The modality data can be utilized in two ways. The first is passing the pre-extracted modality data into the model, and the second is passing the raw data into the model by applying end-to-end learning. According to most of the MMRec model settings, our framework are following the first method to use pre-extracted features. Different modality data have modality-specific methods to extract. (p. 5)
MODEL CLASSIFICATION
Self-supervised learning
The two pre-train tasks are graph structure reconstruct and masked node feature reconstruction. It developed a mini-batch contextual neighbors sampling algorithm to sample negative and positive data which is used to handle large-scale graphs. After the Pre-train has been done, we could get the node representations and use them to initiate the item embeddings for the downstream tasks. (p. 16)
MODALITY FUSION
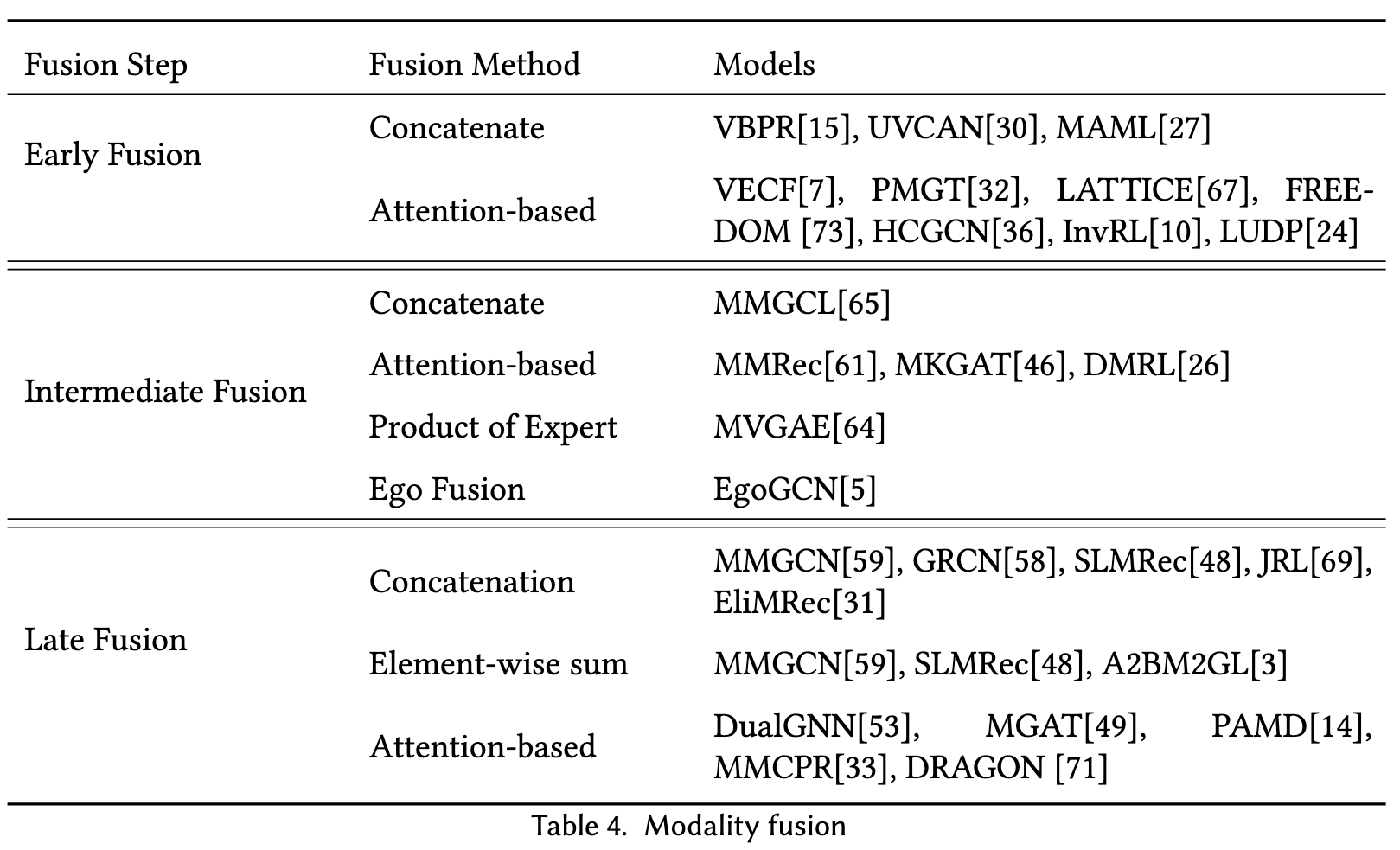
- Early fusion also names data-level fusion which means it fuses modality embeddings into a single feature representation and then inputs to the model. But this approach could not capture the complementary information of multi-modality and might include data redundancy. The early fusion approach is usually applied with some feature extraction methods (like PCA and autoencoder) to overcome the problem.
- Late fusion also named decision-level fusion based on the prediction result or scores of each modality. The commonly used approaches are max-fusion, averaged-fusion, Bayes’rule based and ensemble learning. This kind of approach could learn complementary information and each modality is independent from others which will not lead to the addition of mistakes.
- The intermediate fusion fuse the modality information after getting the high dimensional embeddings of each modality and then utilize the middle layer to do fusion. This kind of fusion depends on the model design. (p. 17)
MEASUREMENT AND OPTIMIZATION
Evaluation metrics
Commonly used evaluation metrics for the recommendation system include accuracy, precision, recall, F1-score, hit rate, Normalized Discounted Cumulative Gain (NDCG) and Mean Average Precision (MAP). (p. 18)
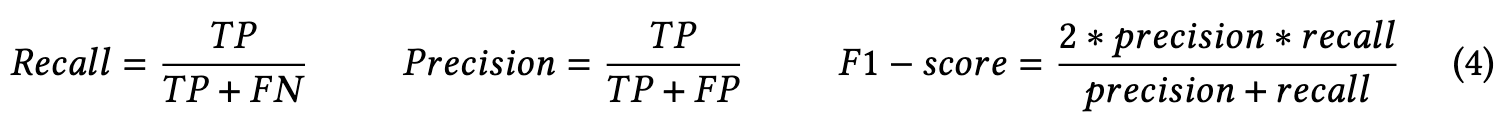
The hit rate likes the name implies, represents the ratio of hit items in the predicted top-k list over the total items in the test set. If a user actually interacts with one of the top-k items we recommend, it is considered a hit. (p. 18)

Precision and Recall do not consider ordering. The average precision (AP) is used to evaluate order-sensitive recommendation results for one user, and MAP is the average of 𝐴𝑃@𝐾 over all users: (p. 18)
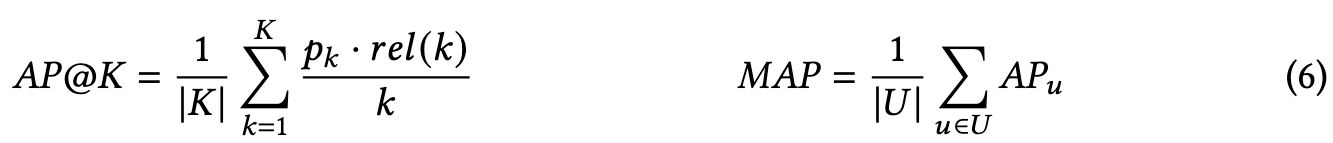
Normalized Discounted Cumulative Gain (NDCG) is also a measure of rank quality. Cumulative Gain (CG) is the relevance score in a recommendation list, DCG fills the gaps that CG only utilizes the relevance score but did not consider the rank position. iDCG is the DCG of the ideal ordered recommendation list. NDCG is calculated by DCG over iDCG, formally: (p. 18)

Objective Functions

The Weighted ApproximateRank Pairwise (WARP) [60] updated the basic pairwise loss by considering the ranking that penalizes a positive item at a lower rank much more heavily than the one at the top. While BPR [41] approaches the top-k task as a ranking problem, encouraging the ranking of positive things above negative ones for the given user, Cross entropy loss approaches the top-k task as a classification challenge and make the target user u and the target item i as similar as possible. BPR loss is more suitable for the top-k recommendation (p. 19)
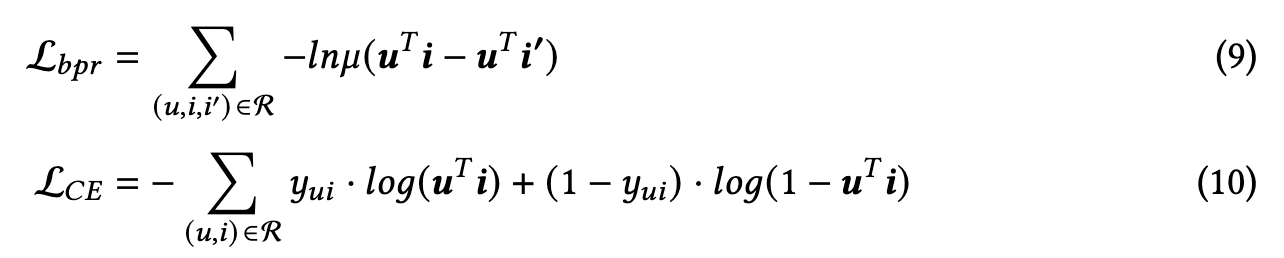
Contrastive loss aims to increase the similarity between similar items but make the item representation different from the other items. And the InfoNCE loss is the variant that considers the problem as a multi-class classification [48, 65]. (p. 19)
Future Direction
Future research directions should be studied on how to efficiently utilize the multimodal features: (1) Find out the efficient modality fusion method that can capture complementary information that a single modality can not contain. (2) How to solve the modality missing issue and reconstruct the meaningful representation. (p. 27)
The recommender system should not only consider the accuracy but also the other recommendation qualities such as the recommendation list’s diversity and the presence of unique items (p. 29)
A sequential recommendation system is different from the recommendation systems that use collaborative filtering and content-based filtering, as it attempts to understand and model the sequential behaviors of the users over time. The multimodal information could greatly influence the user’s preference, however, most of the existing sequential recommendation models ignore such useful information. (p. 29)