MusicLM Generating Music From Text
[diffsound multimodal residual-vector-quantization audio-lm mubert deep-learning music-lm mulan audio transformer soundstream riffusion rvq This is my reading note on MusicLM: Generating Music From Text. The paper is mostly extended AudioLM to generate the music from text. To do this it utilizes two off shelf models to provide semantic information of audio and to project text to embed ding of the some space of audio
Introduction
MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To (p. 1)
Casting audio synthesis as a language modeling task in a discrete representation space, and leveraging a hierarchy of coarse-to-fine audio discrete units (or tokens), AudioLM achieves both highfidelity and long-term coherence over dozens of seconds. AudioLM learns to generate realistic audio from audio-only corpora, be it speech or piano music, without any annotation (p. 1)
MusicLM leverages AudioLM’s multi-stage autoregressive modeling as the generative component, while extending it to incorporate text conditioning To address the main challenge of paired data scarcity, we rely on MuLan (Huang et al., 2022), a joint music-text model that is trained to project music and its corresponding text description to representations close to each other in an embedding space. That is, we use the MuLan embeddings computed from the audio as conditioning during training, while we use MuLan embeddings computed from the text input during inference (p. 2)
Related Work
Quantization
SoundStream (Zeghidour et al., 2022) is a universal neural audio codec capable of compressing general audio at low bitrates, while maintaining a high reconstruction quality. To achieve this, SoundStream uses residual vector quantization (RVQ), allowing scalability to higher bitrate and quality, without a significant computational cost. More specifically, RVQ is a hierarchical quantization scheme composing a series of vector quantizers, where the target signal is reconstructed as the sum of quantizer outputs. Due to the composition of quantizers, RVQ avoids the exponential blowup in the codebook size as the target bitrate increases. Recently, SoundStream was extended by EnCodec (Defossez et al. ´ , 2022) to higher bitrates and stereophonic (p. 2)
Generative Models for Audio
Inspired by these approaches, AudioLM (Borsos et al., 2022) addresses the trade-off between coherence and high-quality synthesis by relying on a hierarchical tokenization and generation scheme. Concretely, the approach distinguishes between two token types: (1) semantic tokens that allow the modeling of long-term structure, extracted from models pretrained on audio data with the objective of masked language modeling; (2) acoustic tokens, provided by a neural audio codec, for capturing fine acoustic details. This allows AudioLM to generate coherent and high-quality speech as well as piano music continuations without relying on transcripts or symbolic music representations. (p. 3)
Conditioned Audio Generation
DiffSound (Yang et al., 2022) uses CLIP (Radford et al., 2021) as the text encoder and applies a diffusion model to predict the quantized mel spectrogram features of the target audio based on the text embeddings and an autoregressive Transformer decoder for predicting target audio codes produced by EnCodec (Defossez et al. ´ , 2022) (p. 3)
In Mubert (Mubert-Inc, 2022), the text prompt is embedded by a Transformer, music tags which are close to the encoded prompt are selected and used to query the song generation API. (p. 3)
This is in contrast to Riffusion (Forsgren & Martiros, 2022), which fine-tunes a Stable Diffusion model (Rombach et al., 2022a) on mel spectrograms of music pieces from a paired music-text dataset. (p. 3)
Joint Embedding Models for Music and Text
MuLan (Huang et al., 2022) is a music-text joint embedding model consisting of two embedding towers, one for each modality. The towers map the two modalities to a shared embedding space of 128 dimensions using contrastive learning, with a setup similar to (Radford et al., 2021; Wu et al., 2022b). The text embedding network is a BERT (Devlin et al., 2019) pre-trained on a large corpus of text-only data, while we use the ResNet-50 variant of the audio tower.
MuLan is trained on pairs of music clips and their corresponding text annotations. Importantly, MuLan imposes only weak requirements on its training data quality, learning cross-modal correspondences even when the music-text pairs are only weakly associated. The ability to link music to unconstrained natural language descriptions makes it applicable for retrieval or zero-shot music tagging. In this work, we rely on the pretrained and frozen model of Huang et al. (2022). (p. 3)
Proposed Method

Representation and Tokenization of Audio and Text
In particular, by following the approach of AudioLM, we use the self-supervised audio representations of SoundStream (Zeghidour et al., 2022), as acoustic tokens to enable high-fidelity synthesis, and w2vBERT (Chung et al., 2021), as semantic tokens to facilitate long-term coherent generation. For representing the conditioning, we rely on the MuLan music embedding during training and the MuLan text embedding at inference time. (p. 4)
SoundStream. We use a SoundStream model for 24 kHz monophonic audio with a striding factor of 480, resulting in 50 Hz embeddings. The quantization of these embeddings is learned during training by an RVQ with 12 quantizers, each with a vocabulary size of 1024. This results in a bitrate of 6 kbps, where one second of audio is represented by 600 tokens (p. 4)
w2v-BERT. After pretraining and freezing the model, we extract embeddings from the 7th layer and quantize them using the centroids of a learned k-means over the embeddings. We use 1024 clusters and a sampling rate of 25 Hz, resulting in 25 semantic tokens for every second of audio, denoted by S (p. 4)
MuLan. Since MuLan operates on 10-second audio inputs and we need to process longer audio sequences, we calculate the audio embeddings on 10-second windows with 1-second stride and average the resulting embeddings. We then discretize the resulting embedding by applying an RVQ with 12 vector quantizers, each with a vocabulary size of 1024. This process yields 12 MuLan audio tokens MA for an audio sequence. During inference, we use as conditioning the MuLan text embedding extracted from the text prompt, and quantize it with the same RVQ as the one used for the audio embeddings, to obtain 12 tokens MT . (p. 4)
Models

We use decoder-only Transformers for modeling the semantic stage and the acoustic stages of AudioLM. The models share the same architecture, composed of 24 layers, 16 attention heads, an embedding dimension of 1024, feed-forward layers of dimensionality 4096, dropout of 0.1, and relative positional embeddings (Raffel et al., 2020), resulting in 430M parameters per stage. (p. 5)
Experiment
Metric
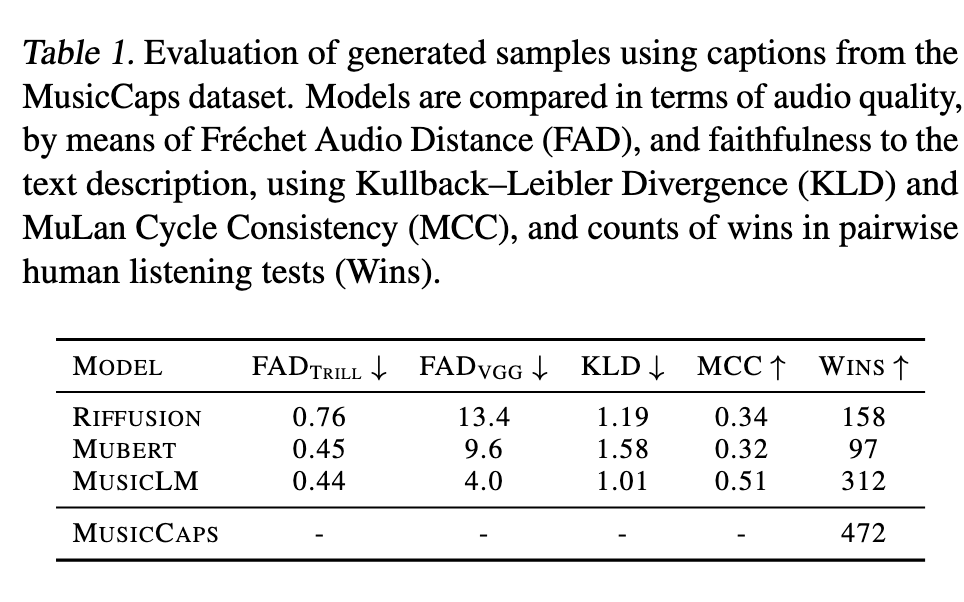
Three metrics are used for evaluation:
- The Frechet Audio Distance (Kilgour et al., 2019) is a reference-free audio quality metric, which correlates well with human perception (p. 5)
- we use a LEAF (Zeghidour et al., 2021) classifier trained for multi-label classification on AudioSet, to compute class predictions for both the generated and the reference music and measure the KL divergence between probability distributions of class predictions. (p. 6)
- MuLan Cycle Consistency (MCC). As a joint musictext embedding model, MuLan can be used to quantify the similarity between music-text pairs. We compute the MuLan embeddings from the text descriptions in MusicCaps as well as the generated music based on them, and define the MCC metric as the average cosine similarity between these embeddings. (p. 6)