PaLI-3 Vision Language Models Smaller, Faster, Stronger
[simvlm multimodal pre-training t5 vit deep-learning git image-text-matching beit flamingo coca pali3 contrast-loss ofa bert pali siglip palm palix This is reading note for PaLI-3 Vision Language Models: Smaller, Faster, Stronger. This paper proposes to use image-text-matching to replace contrast loss. The experiment indicates this method is especially effective in relatively small models.
Introduction
This paper presents PaLI-3, a smaller, faster and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, we compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively pretrained ones (SigLIP). We find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and text understanding. (p. 1)
RELATED WORK
In this paper we compare two dominant ways to pretrain image encoders using the PaLI framework:
- classification pretraining using large weakly labeled datasets (JFT, as in Kolesnikov et al., 2020; Zhai et al., 2022a; Dehghani et al., 2023)
- and contrastive pretraining on web-scale noisy data (WebLI, as in Zhai et al., 2023). (p. 2)
A recent finding spanning across PaLI (Chen et al., 2023b) and PaLI-X (Chen et al., 2023a) is that scaling up the classification pretrained image encoder seems more promising than was previously believed (Alayrac et al., 2022). Specifically, while classic image-only benchmarks such as ImageNet seem to indicate saturating performance from scaling pretraining of image-only models (Zhai et al., 2022a), PaLI shows that by scaling up the vision encoder from ViT-G (2B) to ViT-e (4B), the improvements on VL tasks are more noticeable than on ImageNet. PaLI-X further scaled up both the vision and language components, showing that these larger image encoders keep bringing benefit when plugged into large VLMs. This finding suggests that there is more to be found regarding the pretraining of image encoders in the context of VLMs, which may lead to different conclusions when looking at VLM tasks as compared to of “pure” vision tasks. In this paper, we dive into the impact of the image encoder for VLMs, by directly comparing classification pretrained vision models to contrastively pretrained ones, and reveal that the latter are vastly superior on a variety of tasks, especially localization and visually-situated text understanding. (p. 2)
MODEL
ARCHITECTURE
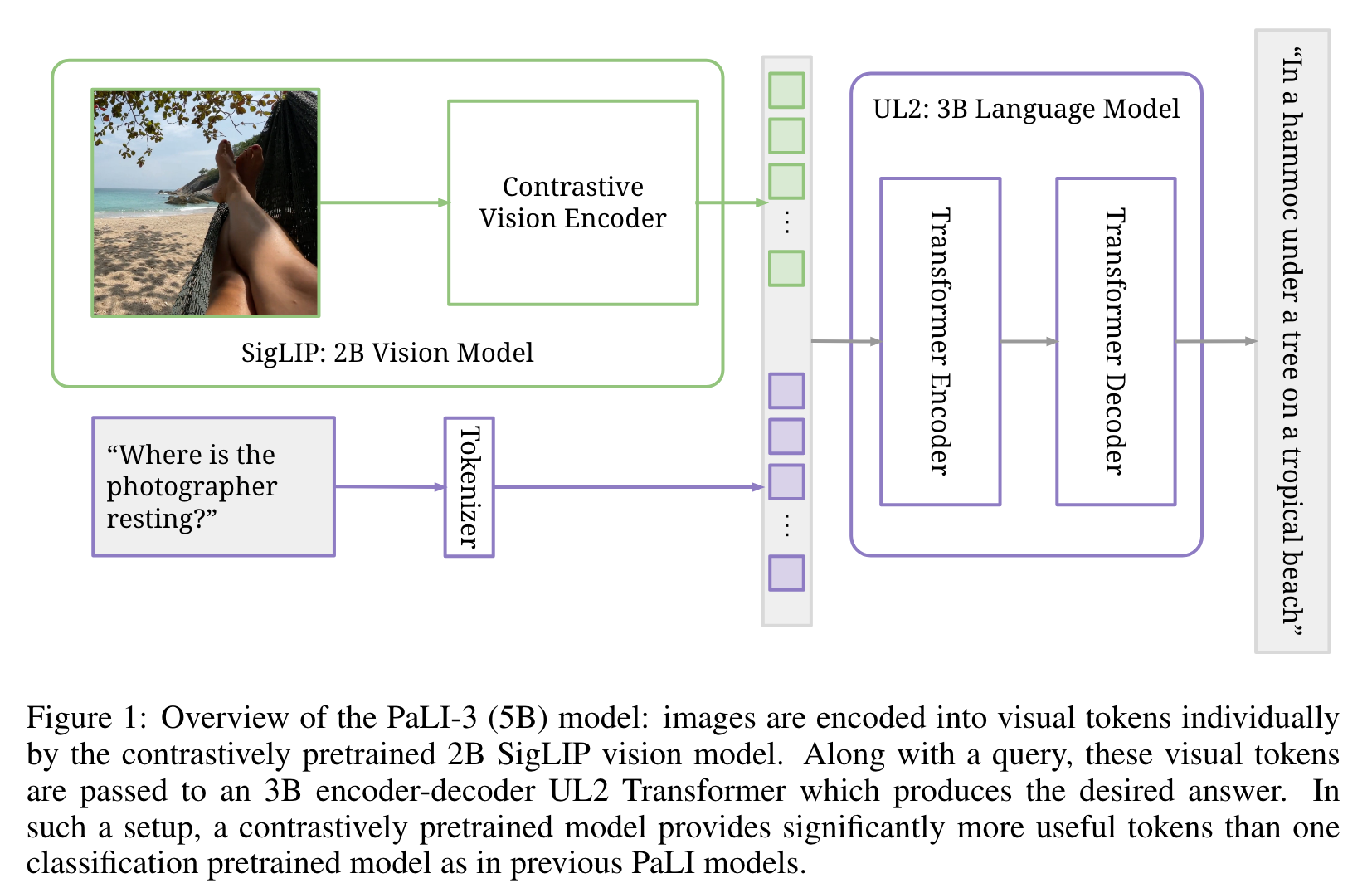
On a high level, the architecture follows Chen et al. (2023b;a): a ViT encodes the image into tokens which, together with text input (the question, prompt, instruction), are passed to an encoder-decoder transformer (Vaswani et al., 2017) that generates a text output. (p. 2)
Visual component
In short, an image embedding ViT-G/14 and a text embedding transformer are trained to separately embed images and texts, such that a binary classifier using the sigmoid crossentropy of the dot product of image and text embeddings correctly classifies whether the respective image and text correspond to each other or not. This is done in order to pretrain the ViT image embedding component, hence the text embedding transformer is discarded when inserting the ViT into PaLI. (p. 3)
Full PaLI model
The outputs of the ViT image encoder before pooling form the visual tokens, which are linearly projected and prepended to the embedded input text tokens. Together, these tokens are passed into a pretrained 3B parameter UL2 encoder-decoder language model (Tay et al., 2023), which generates text output. The text input to the model typically consists of a prompt that describes the type of task (e.g., “Generate the alt_text in ⟨lang⟩ at ⟨pos⟩” for captioning tasks) and encode necessary textual input for the task (e.g., “Answer in ⟨lang⟩: {question} ” for VQA tasks). (p. 3)
STAGES OF TRAINING
- Stage 0: Unimodal pretraining.
- Stage 1: Multimodal training. Then, this combined PaLI model is trained on a multimodal task and data mixture, albeit keeping the image encoder frozen (p. 3)
- Stage 2: Resolution increase. We increase PaLI-3’s resolution by fine-tuning the whole model (unfreezing the image encoder) with a short curriculum of increasing resolutions, keeping checkpoints at 812×812 and 1064×1064 resolution. (p. 4)
- Task specialization (transfer). Finally, for each individual task (benchmark), we fine-tune the PaLI-3 model with frozen ViT image encoder on the task’s training data as described in the corresponding section. For most tasks, we fine-tune the 812×812 resolution checkpoint, but for two document understanding tasks, we go up to 1064×1064 resolution. (p. 4)
EXPERIMENTS
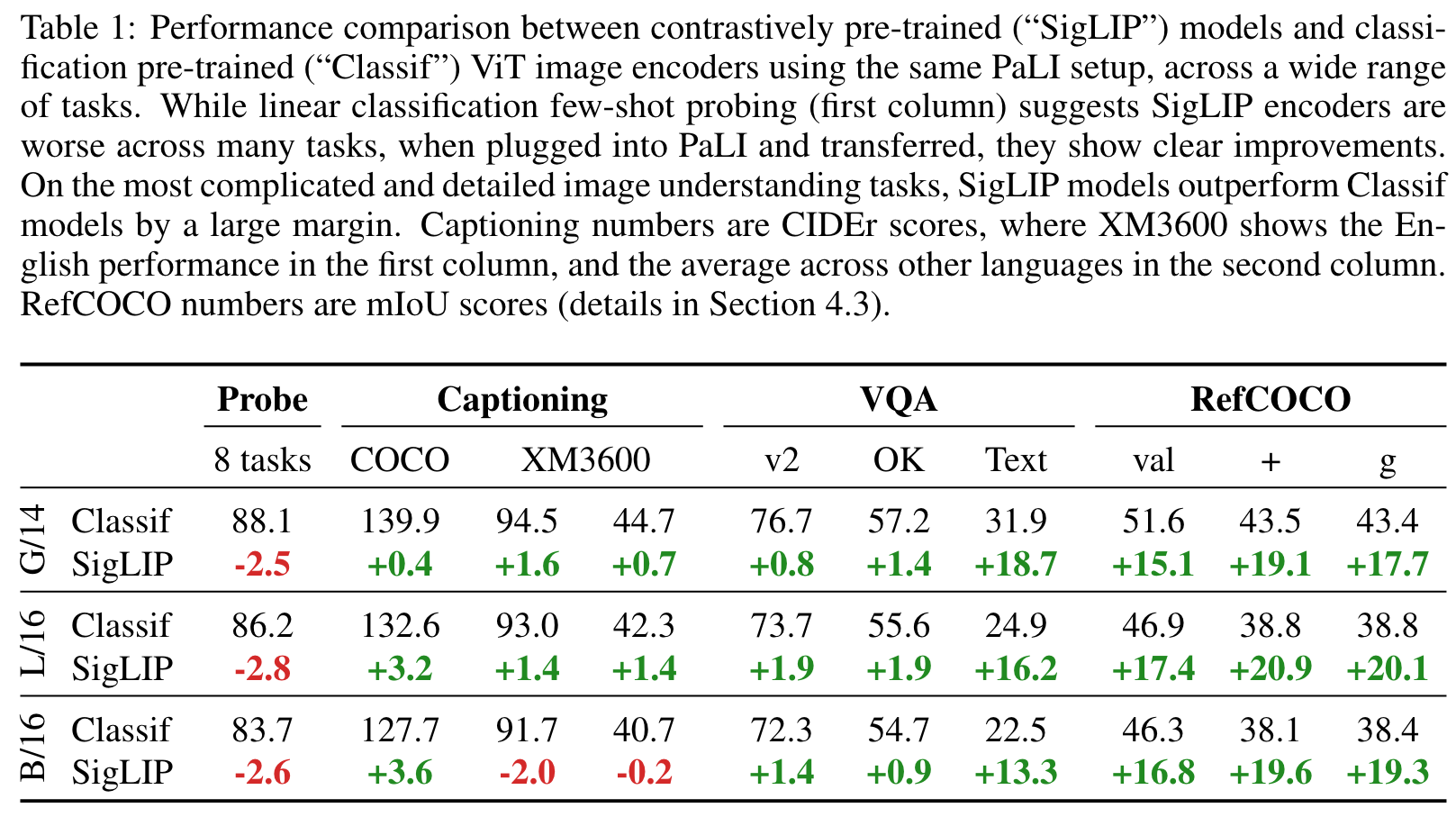
CLASSIFICATION OR CONTRASTIVELY PRETRAINED VIT?
SigLIP models provide moderate gains on “simpler” tasks such as captioning and question-answering, and large gains for more “complicated” scene-text and spatial understanding tasks such as TextVQA and RefCOCO (p. 4)
VIDEO CAPTIONING AND QUESTION ANSWERING
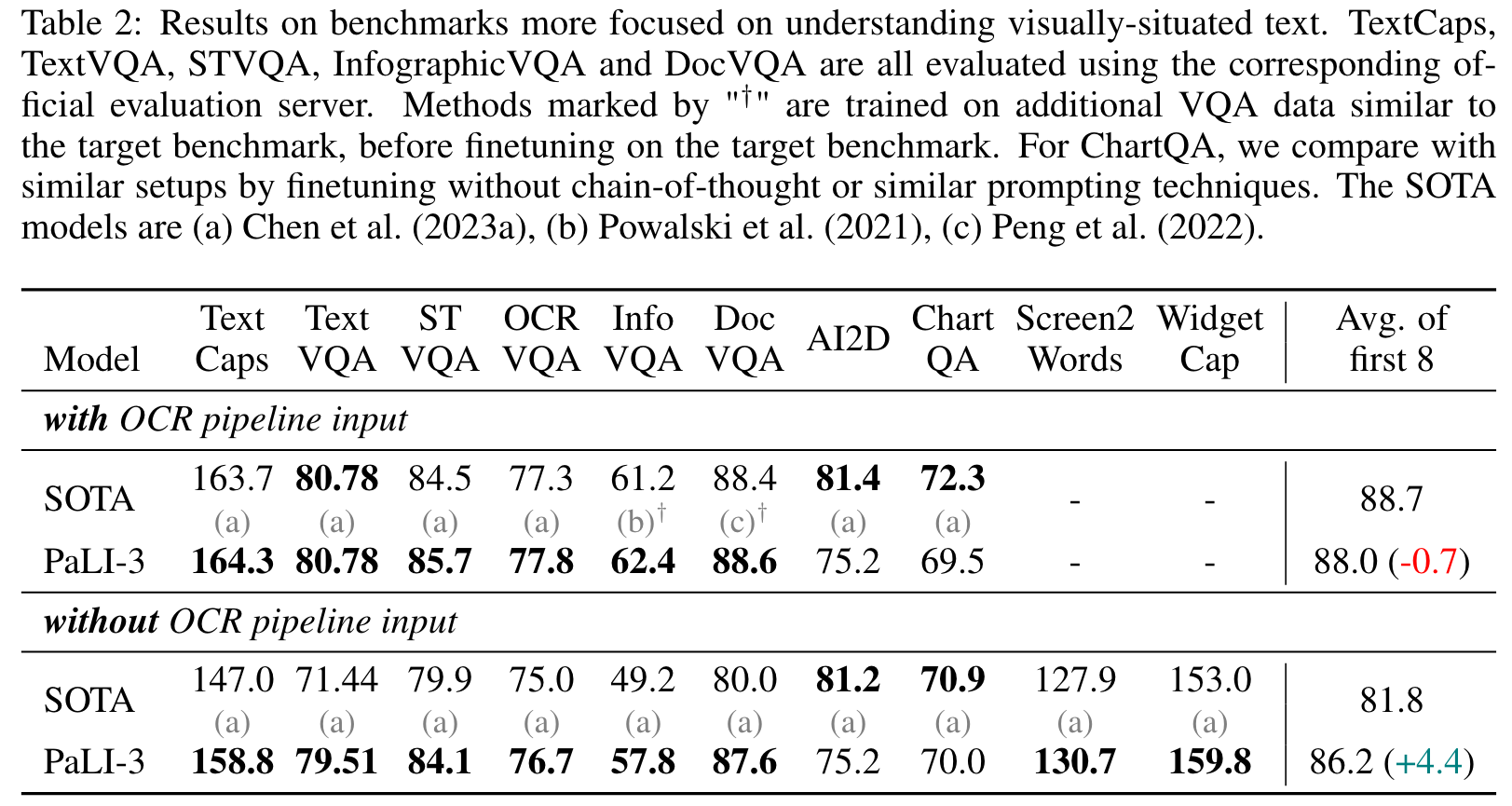
We sample at most 16 frames with a fixed temporal stride for each benchmark. Each frame is independently processed by the ViT image encoder, the resulting visual tokens are simply concatenated, leading to up to 4096 visual tokens. (p. 6)