pixelNeRF Neural Radiance Fields from One or Few Images
[cnn mlp nerf deep-learning differential-rendering pixelnerf pixelNeRF: Neural Radiance Fields from One or Few Images tries to learn a discontinuous neutral scene representation from one or few input images. To this end, pixelNeRF introduced an architecture that conditions a NeRF on image inputs in a fully convolutional manner. This allows the network to be trained across multiple scenes to learn a scene prior, enabling it to perform novel view synthesis in a feed-forward manner from a sparse set of views (as few as one).
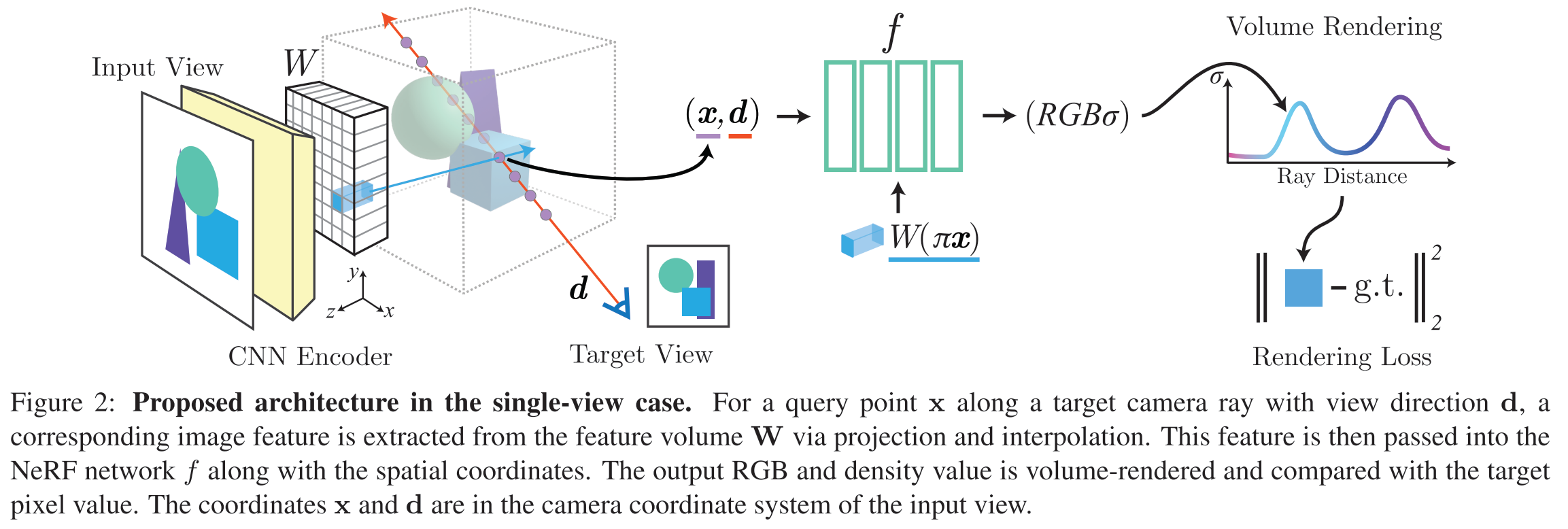
Figure below shows the architecture of the proposed method. we condition NeRF on input images by first computing a fully convolutional image feature grid from the input image. Then for each query spatial point x and viewing direction d of interest in the view coordinate frame, we sample the corresponding image feature via projection and bilinear interpolation. The query specification is sent along with the image features to the NeRF network that outputs density and color, where the spatial image features are fed to each layer as a residual. When more than one image is available, the inputs are first encoded into a latent represen- tation in each camera’s coordinate frame, which are then pooled in an intermediate layer prior to predicting the color and density. The model is supervised with a reconstruction loss between a ground truth image and a view rendered using conventional volume rendering techniques.
Encoder
The encoder is based on ResNet34. Given a input image I of a scene, we first extract a feature volume W = E(I). Then, for a point on a camera ray x, we retrieve the corresponding image feature by projecting x onto the image plane to the image coordinates π(x) using known intrinsics, then bilinearly interpolating between the pixelwise features to extract the feature vector W(π(x)).
For the image encoder E, to capture both local and global information effectively, we extract a feature pyramid from the image. We use a ResNet34 backbone pretrained on ImageNet for our experiments. Features are extracted prior to the first 4 pooling layers, upsam- pled using bilinear interpolation, and concatenated to form latent vectors of size 512 aligned to each pixel. For a H×W image, the feature maps have shapes
- 64 ×H/2 ×W/2
- 64 ×H/4 ×W/4
- 128 ×H/8 ×W/8
- 256 ×H/16 ×W/16
These are upsampled bilinearly to H/2 × W/2 and concatenated into a volume of size 512 × H/2 × W/2. For a 64 × 64 image, to avoid losing too much resolution, we skip the first pooling layer, so that the image reso- lutions are at 1/2, 1/2, 1/4, 1/8 of the input rather than 1/2, 1/4, 1/8, 1/16. We use ImageNet pretrained weights provided through PyTorch.
NERF
The image features output by the encoder are then passed into the NeRF network, along with the position and view direction (both in the input view coordinate system), as
\[f(\gamma(x),d;W(\pi(x)))=(\sigma,c)\]Here \(\gamma(x)\) is the frequency encoding which maps the each of x into a 6x2 elements. Specifically, we feed the encoded position and view direction through the network and add the image feature as a residual at the beginning of each ResNet block. We train an independent linear layer for each block residual, in a similar manner as AdaIn and SPADE.
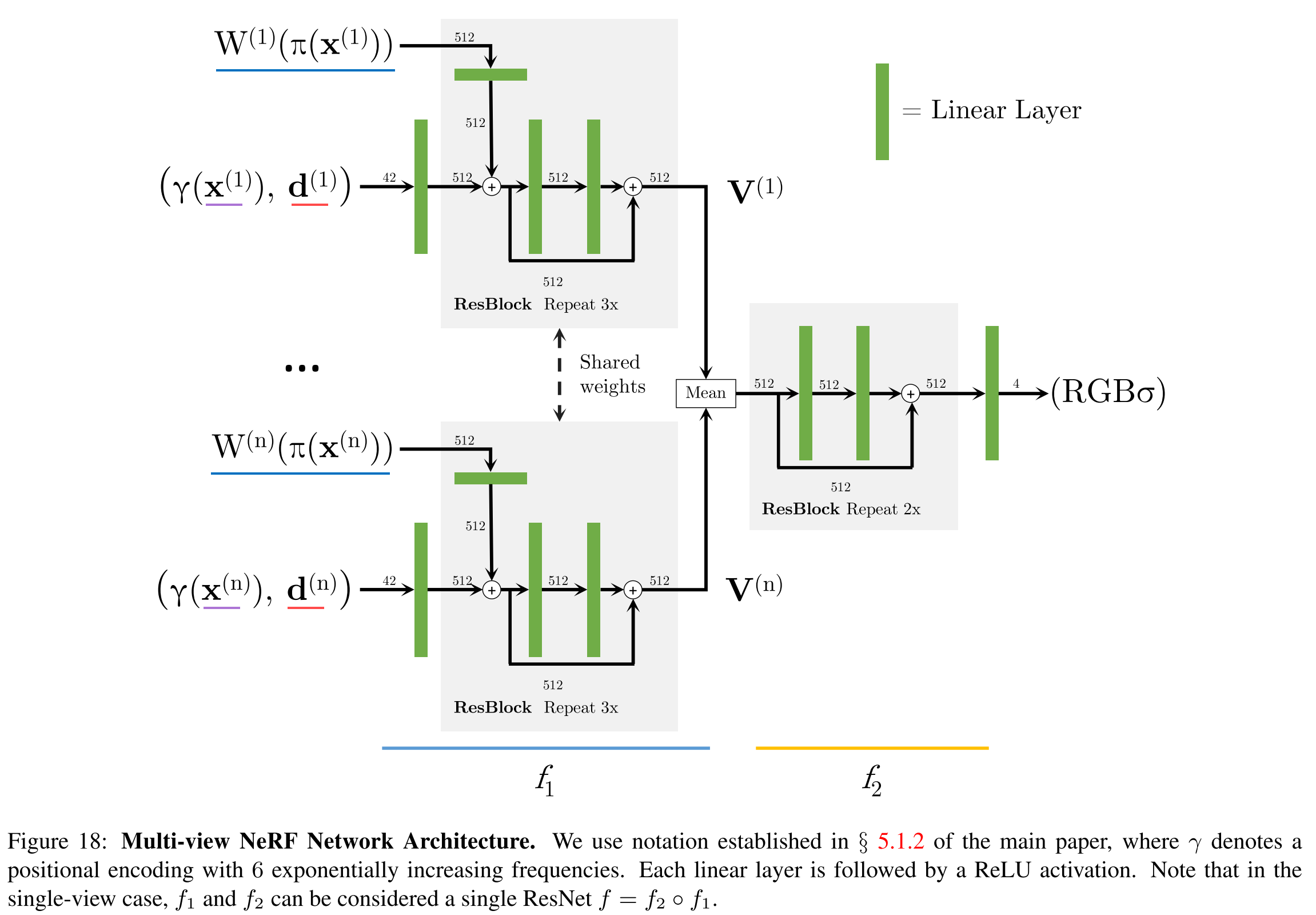
We employ a fully-connected ResNet architecture with 5 ResNet blocks and width 512, similar to that in [28]. To enable arbitrary number of views as input, we aggregate across the source-views after block 3 using an average-pooling operation.
To improve the sampling efficiency, in practice, we also use coarse and fine NeRF networks fc, ff as in the vanilla NeRF [27], both of which share an identical architecture described above.
I am not sure why they didn’t consider U-Net if they want to reserve the details.
This is illustrated as figure below.
Multiple Input Images
In the case that we have multiple input views of the scene, we assume only that the relative camera poses are known. For the new target camera ray, we transform a query point x with view direction d, into the coordinate system of each input view i with the world to camera transform.
To obtain the output density and color, we process the coordinates and corresponding features in each view coordinate frame independently and aggregate across the views within the NeRF network.
Coordinate System
For the 3D learning task, prediction can be done either in a viewer-centered coordinate system, i.e. view space, or in an object-centered coordinate system, i.e. canonical space. Most existing methods [51, 25, 28, 40] predict in canonical space, where all ob- jects of a semantic category are aligned to a consistent orientation. While this makes learning spatial regularities easier, using a canonical space inhibits prediction performance on unseen object categories and scenes with more than one object, where there is no predefined or well-defined canonical pose. PixelNeRF operates in view-space, which has been shown to allow better reconstruction of unseen object categories in [38, 2], and discourages the memorization of the training set [42].
pixelNeRF predicts a NeRF representation in the camera coordinate system of the input image instead of a canonical coordinate frame. This is not only integral for general- ization to unseen scenes and object categories [42, 38], but also for flexibility, since no clear canonical coordinate sys- tem exists on scenes with multiple objects or real scenes.
Experiment Result
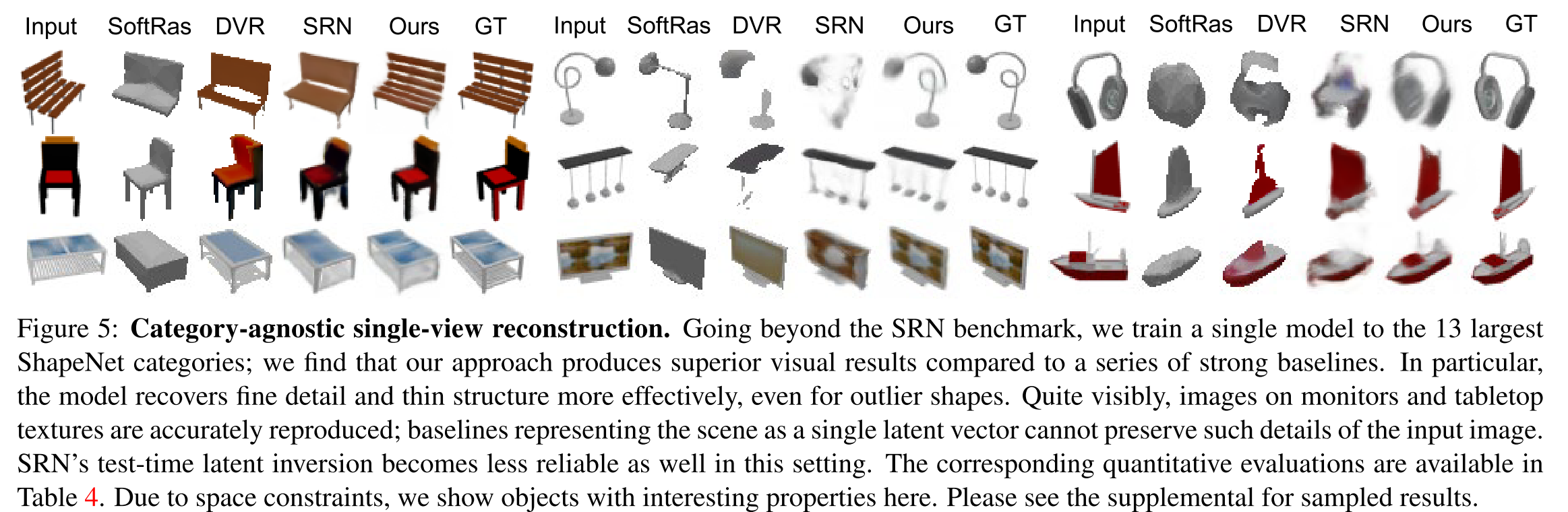
pixelNeRF predicts a NeRF represent