ProPainter Improving Propagation and Transformer for Video Inpainting
[tracking video-inpainting deep-learning transformer This is my reading note for ProPainter: Improving Propagation and Transformer for Video Inpainting. This paper proposes a video inpainting method which remove object from video while reserving spatial temporal consistency. The paper is based on flow based transformer. Two contributions are made, 1) the consistency to improve flow performance which is applied to both image and feature; 2) reduce the # of tokens of than Horner both spatially and temporally.
Introduction
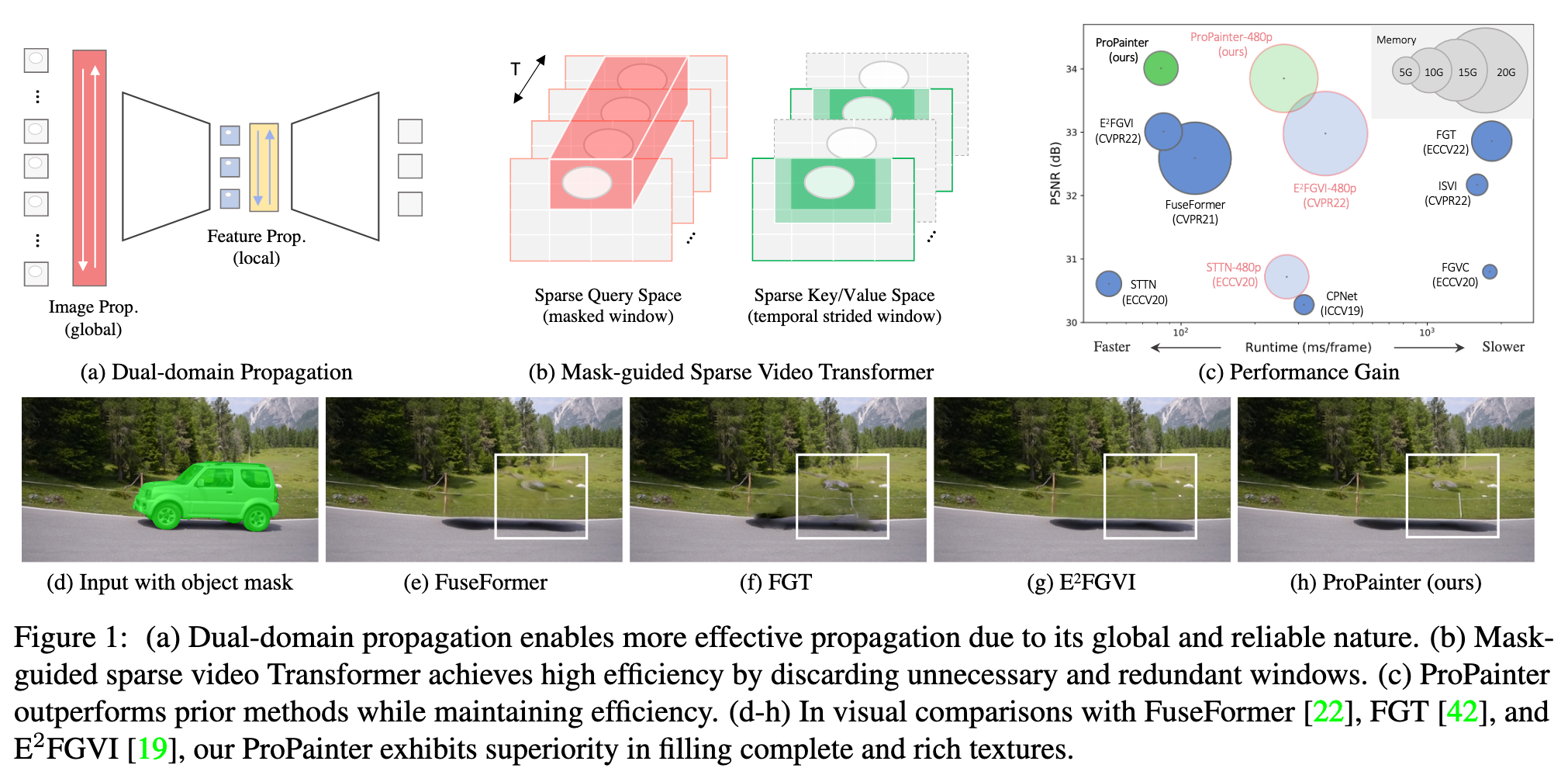
Flow-based propagation and spatiotemporal Transformer are two mainstream mechanisms in video inpainting (VI). Despite the effectiveness of these components, they still suffer from some limitations that affect their performance. Previous propagation-based approaches are performed separately either in the image or feature domain. Global image propagation isolated from learning may cause spatial misalignment due to inaccurate optical flow. Moreover, memory or computational constraints limit the temporal range of feature propagation and video Transformer, preventing exploration of correspondence information from distant frames. To address these issues, we propose an improved framework, called ProPainter, which involves enhanced ProPagation and an efficient Transformer. Specifically, we introduce dual-domain propagation that combines the advantages of image and feature warping, exploiting global correspondences reliably. We also propose a mask-guided sparse video Transformer, which achieves high efficiency by discarding unnecessary and redundant tokens (p. 1)
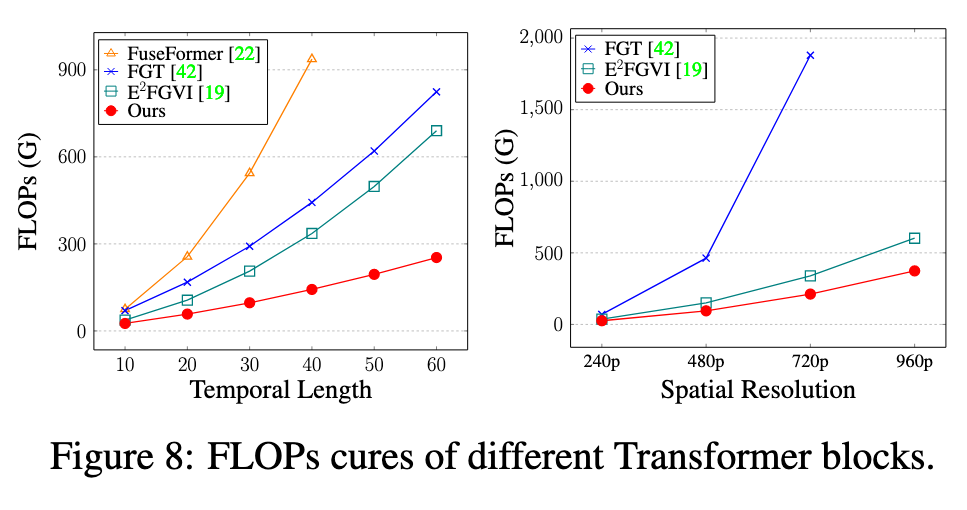
We demonstrate that with systematic redesigns and adaptation of best practices in the literature, we can achieve dual-domain propagation, as illustrated in Figure 1(a). To achieve reliable and efficient information propagation across a video, we identify several essential components: i) Efficient GPU-based propagation with reliability check – Unlike previous methods that rely on complex and time-consuming CPU-centric operations, such as indexing flow trajectories, we perform global image propagation on GPU with flow consistency check. This implementation can be inserted at the beginning of the inpainting network and jointly trained with the other modules. Thus, subsequent modules are able to correct any propagation errors and benefit from the long-range correspondence information provided by the global propagation, resulting in a significant performance improvement. ii) Improved feature propagation – Our implementation of feature propagation leverages flowbased deformable alignment [3], which improves robustness to occlusion and inaccurate flow completion compared to E2FGVI [19]. iii) Efficient flow completion – We design a highly efficient recurrent network to complete flows for dual-domain propagation, which is over 40 times (∼192 fps1) faster than SOTA method [43] while maintaining comparable performance (p. 2)
In addition to dual-domain propagation, we introduce an efficient mask-guided sparse video Transformer tailored for the VI task. The classic spatiotemporal Transformer is computationally intensive due to the quadratic number of interactions between video tokens, making it intractable for high-resolution and long temporal-length videos. (p. 2)
However, we observe that the inpainting mask usually covers only a small local region, such as the object area2. Moreover, adjacent frames contain highly redundant textures. These observations suggest that spatiotemporal attention is unnecessary for most unmasked areas, and it is adequate to consider only alternating interval frames in attention computation. Motivated by these observations, we redesign the Transformer by discarding unnecessary and redundant windows in the query and key/value space, respectively, significantly reducing computational complexity and memory without compromising inpainting performance. (p. 2)
Related Work
Flow-guided propagation. Optical flow [13, 18, 46] and homography [17, 1] are commonly used in video inpainting networks to align neighboring reference frames to enhance temporal coherence and aggregation (p. 3). Propagation-based methods in VI can be divided into two categories: image propagation and feature propagation.
- The former employs bidirectional global propagation in the image domain with a pre-completed flow field. While this approach can fill the majority of holes in a corrupted video, it requires an additional image or video inpainting network after propagation to hallucinate the remaining missing regions. This isolated two-step process can result in unpleasant artifacts and texture misalignment due to inaccurate flow, as shown in Figure 1(f).
- To address this issue, a recent approach called E2FGVI [19] implements propagation in the feature domain, incorporating flow completion and content hallucination modules in an end-to-end framework. With the learnable warping module, the feature propagation module relieves the pressure of having inaccurate flow. However, E2FGVI employs a downsampled flow field to match the spatial size of the feature domain, limiting the precision of spatial warping and the efficacy of propagation, potentially resulting in blurry results. Moreover, feature propagation can only be performed within a short range of video sequences due to memory and computational constraints, hindering propagation from distant frames and leading to missing texture, as shown in Figure 1(g). (p. 2)
To address this issue, some Transformers [21, 1, 42] decouple the spatiotemporal attention by performing spatial and temporal attention alternately, while others [19, 42] adopt window-based Transformers [23, 38] to reduce the spatial range for efficient video attention. However, these approaches still involve redundant or unnecessary tokens. Inspired by token pruning for adaptive attention [29, 39, 25, 20, 15] in high-level tasks, our study proposes a more efficient and faster video Transformer with sparse spatiotemporal attention and a largely reduced token space while maintaining inpainting performance. (p. 3)
Proposed Method
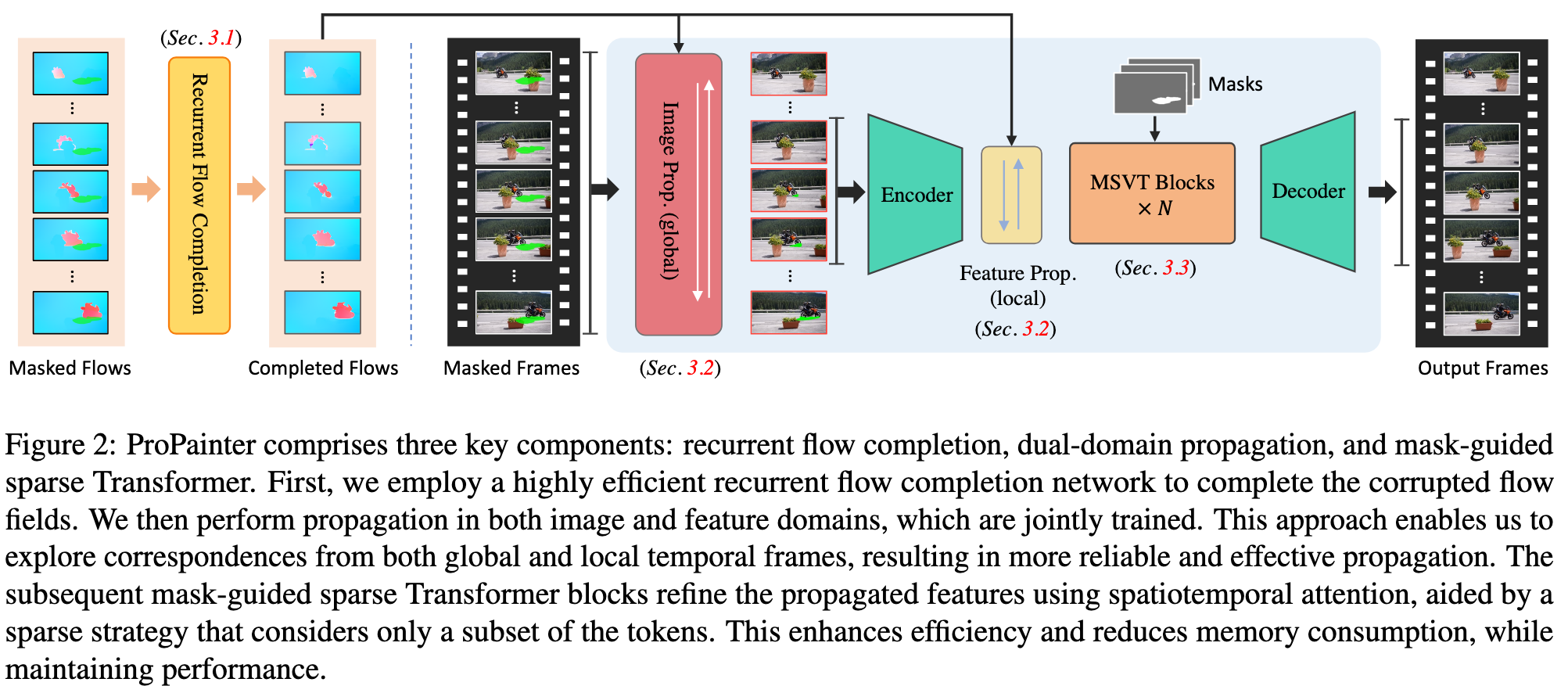
ProPainter, as shown in Figure 2, is composed of three key components: Recurrent Flow Completion (RFC), Dual-Domain Propagation (DDP), and Mask-guided Sparse Video Transformer (MSVT). Before feeding the sequence into ProPainter, we extract the forward and backward optical flows, denoted as Ff = {Ff t = Ft→t+1 ∈ RH×W×2}T −1 t=1 and Fb = {Fbt = Ft+1→t ∈ RH×W×2}T −1 t=1 from a given video X. We first use RFC to complete the corrupted flow fields. Guided by the completed flows, we then perform global image propagation and local feature propagation sequentially. Finally, we employ multiple MSVT blocks to refine propagation features and a decoder to reconstruct the final video sequence Yˆ = {Yˆ t ∈ RH×W×3}Tt=1. (p. 3)
Recurrent Flow Completion
Pre-trained flow completion modules are commonly used in video inpainting networks [37, 10, 43, 42]. The rationale behind this approach is that it is simpler to complete missing flow than to directly fill in complex RGB content [37]. Furthermore, using completed flow to propagate pixels reduces the pressure of video inpainting and better maintains temporal coherence. (p. 3)
However, flow completion modules that are learned together with inpainting-oriented losses can result in a suboptimal learning process and less accurate completed flow. Moreover, the downsampled flow may limit the precision of spatial warping and the efficacy of propagation, which can result in blurred and incomplete filling content, as shown in Figure 1(g). Therefore, an independent flow completion model is not only important but also necessary for video inpainting. (p. 3)
To improve efficiency and enhance flow coherence further, we adopt a recurrent network [2, 3] for flow completion, which provides precise optical flow fields for subsequent propagation modules. (p. 3)
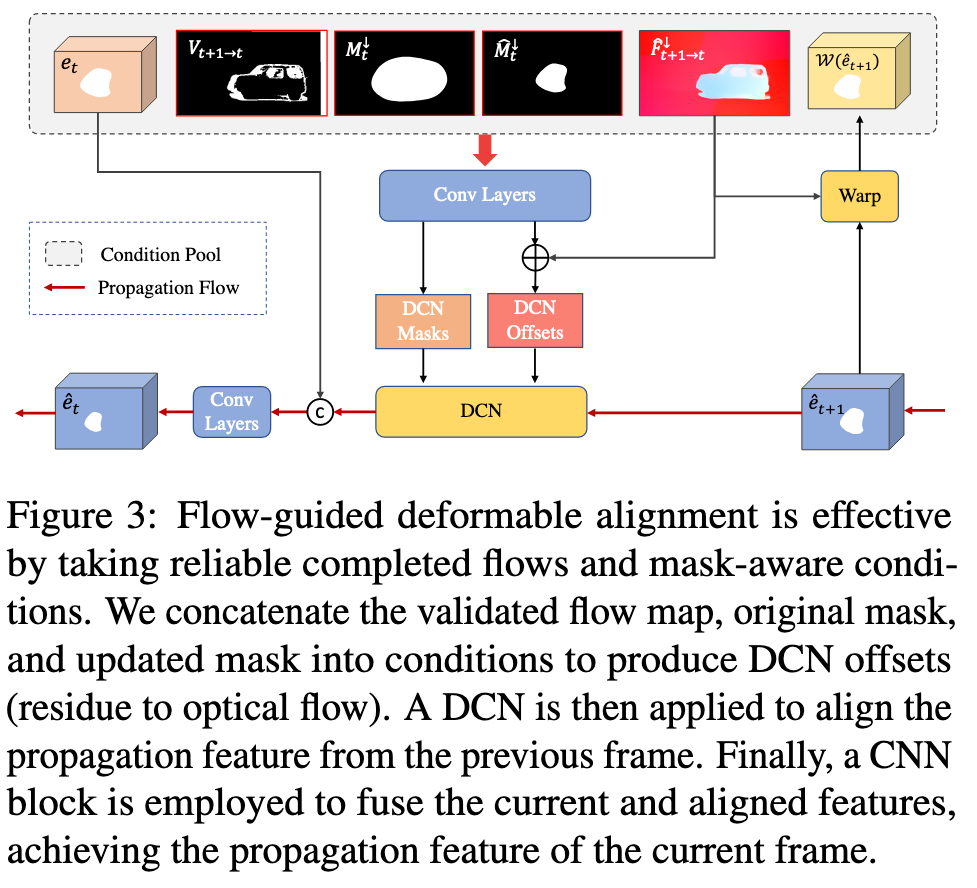
Next, we employ deformable alignment [3] that is based on deformable convolution (DCN) [8, 45], to bidirectionally propagate the flow information from nearby frames for flow completion. (p. 3)
Dual-domain Propagation
After completing the flow, we perform global and local propagation in the image and feature domains, respectively. We employ distinct alignment operations and strategies for each domain. Both domains involve bidirectional propagation in the forward and backward directions. (p. 4)
Image propagation
To maintain efficiency and simplicity, we adopt flow-based warping for image propagation, along with a simple reliability check strategy. This process does not involve any learnable operation. We first check the validity of completed flow based on forward-backward consistency error (p. 4)
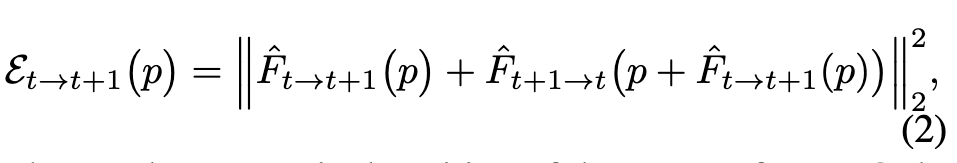
Feature propagation
Similar to E2FGVI [19], we also adopt flow-guided deformable alignment module [3] for feature propagation, which has demonstrated remarkable benefits in various low-level video tasks [5, 4, 44]. Unlike the deformable alignment used in Sec. 3.1 that directly learns DCN offsets, flow-guided deformable alignment employs the completed flow as a base offset and refines it by learning offset residue. However, our design differs from E2FGVI in that we offer richer conditions for learning DCN offsets. (p. 5)
Mask-Guided Sparse Video Transformer
To overcome this, we propose a novel sparse video Transformer that builds on the window-based approach. (p. 5)
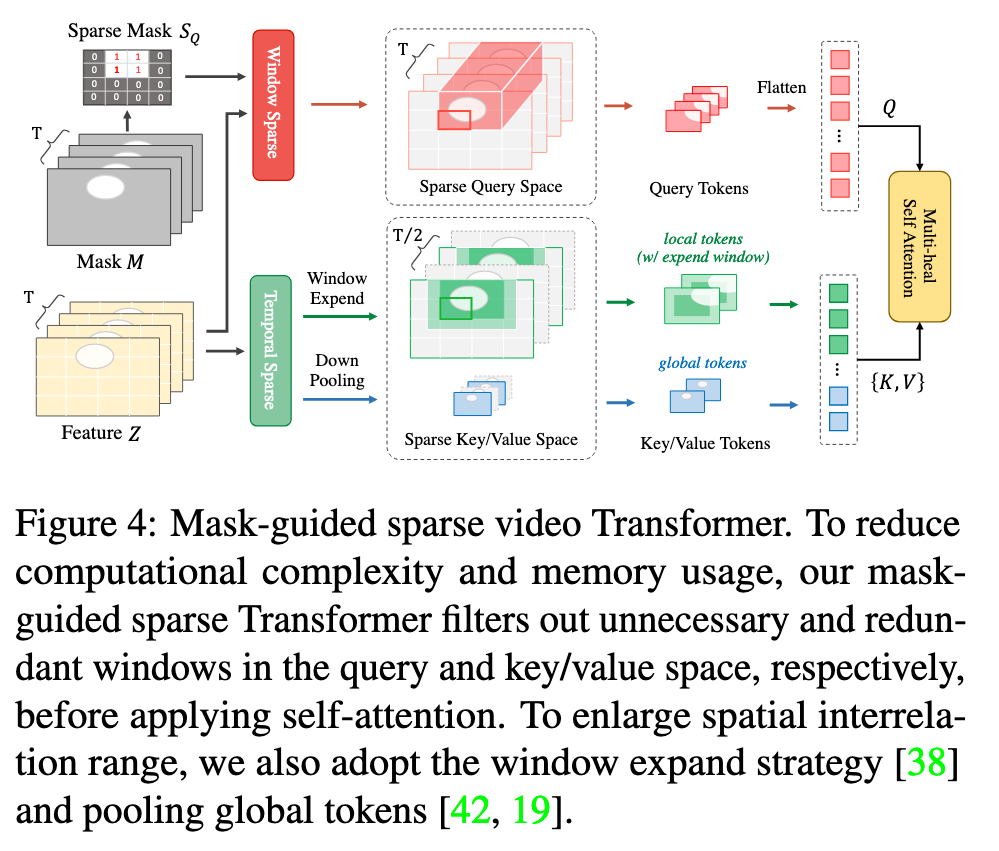
Sparse Query Space. We observe that mask regions often occupy only a small area of the video, such as in the case of object removal in the DAVIS [28] dataset, where the proportion of object regions is only 13.6%. This indicates that spatiotemporal attention may not be necessary for all query windows. To exploit this observation, we selectively apply attention to query windows that intersect with the mask regions. (p. 5)
Sparse Key/Value Space. Due to the highly redundant and repetitive textures in adjacent frames, it is unnecessary to include all frames as key/value tokens in each Transformer block. Instead, we will only include strided temporal frames alternately, with a temporal stride of 2 in our design. (p. 6)
Experiment
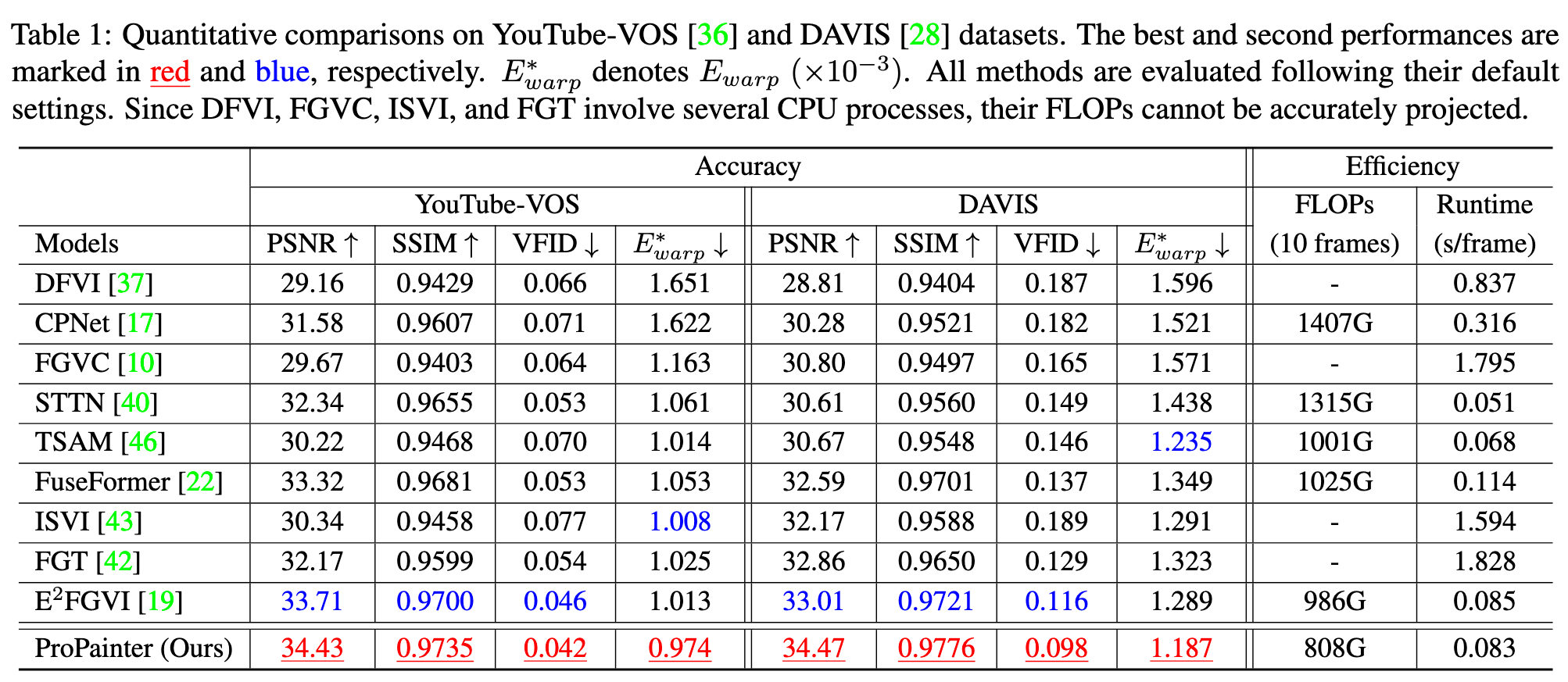
Ablation Study
Removing image propagation causing it to fail to complete missing content with details. (p. 8)