Inject Semantic Concepts into Image Tagging for Open-Set Recognition
[object-detection multimodal deep-learning ram tag clip image-tag-alignment swin This is my reading note for Inject Semantic Concepts into Image Tagging for Open-Set Recognition. This paper proposes an image tagging method based on CLIP. The major innovation is the introduction of image tag alignment loss which aligns image feature to the tag description feature. The tag descriptor is generated by LLM to describe the tog in a few sentences
Introduction
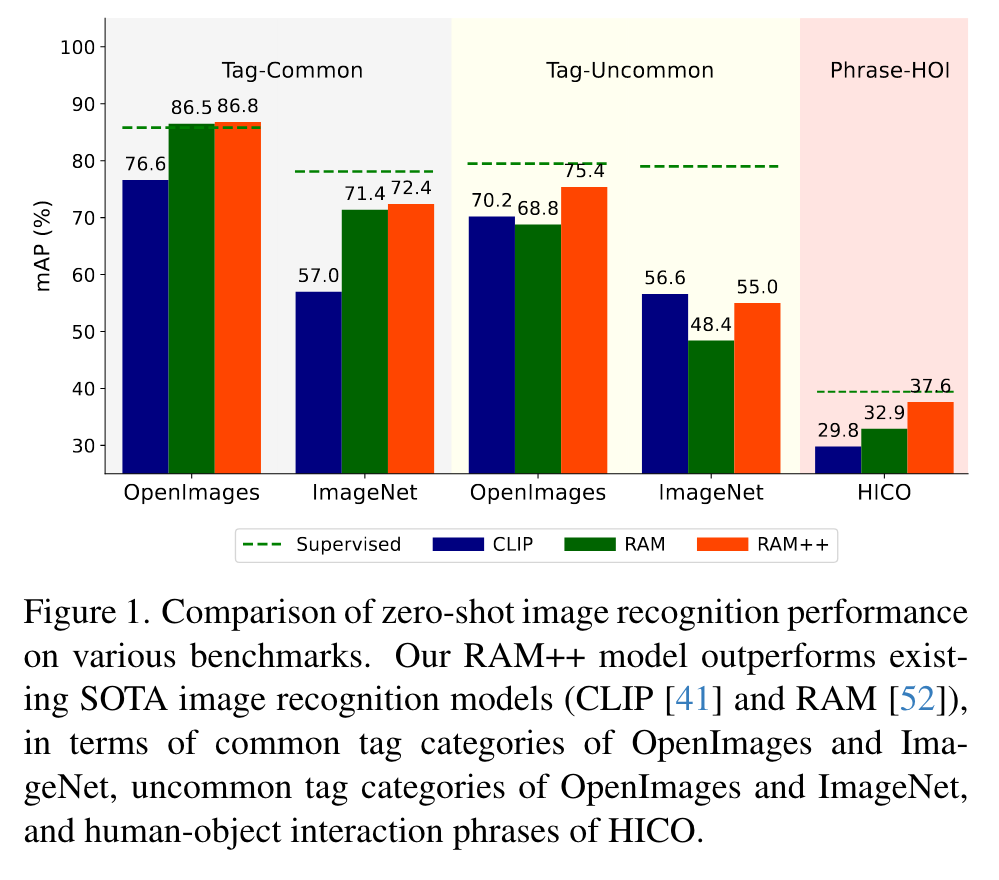
In this paper, we introduce the Recognize Anything Plus Model (RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. (p. 1)
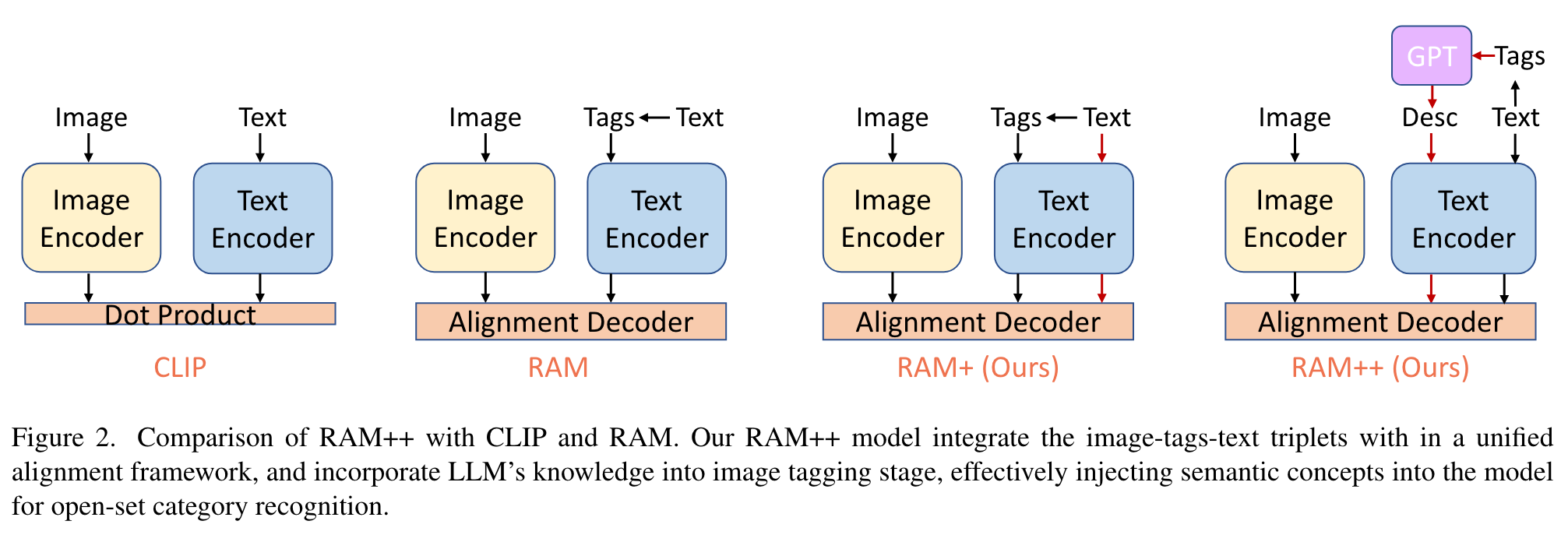
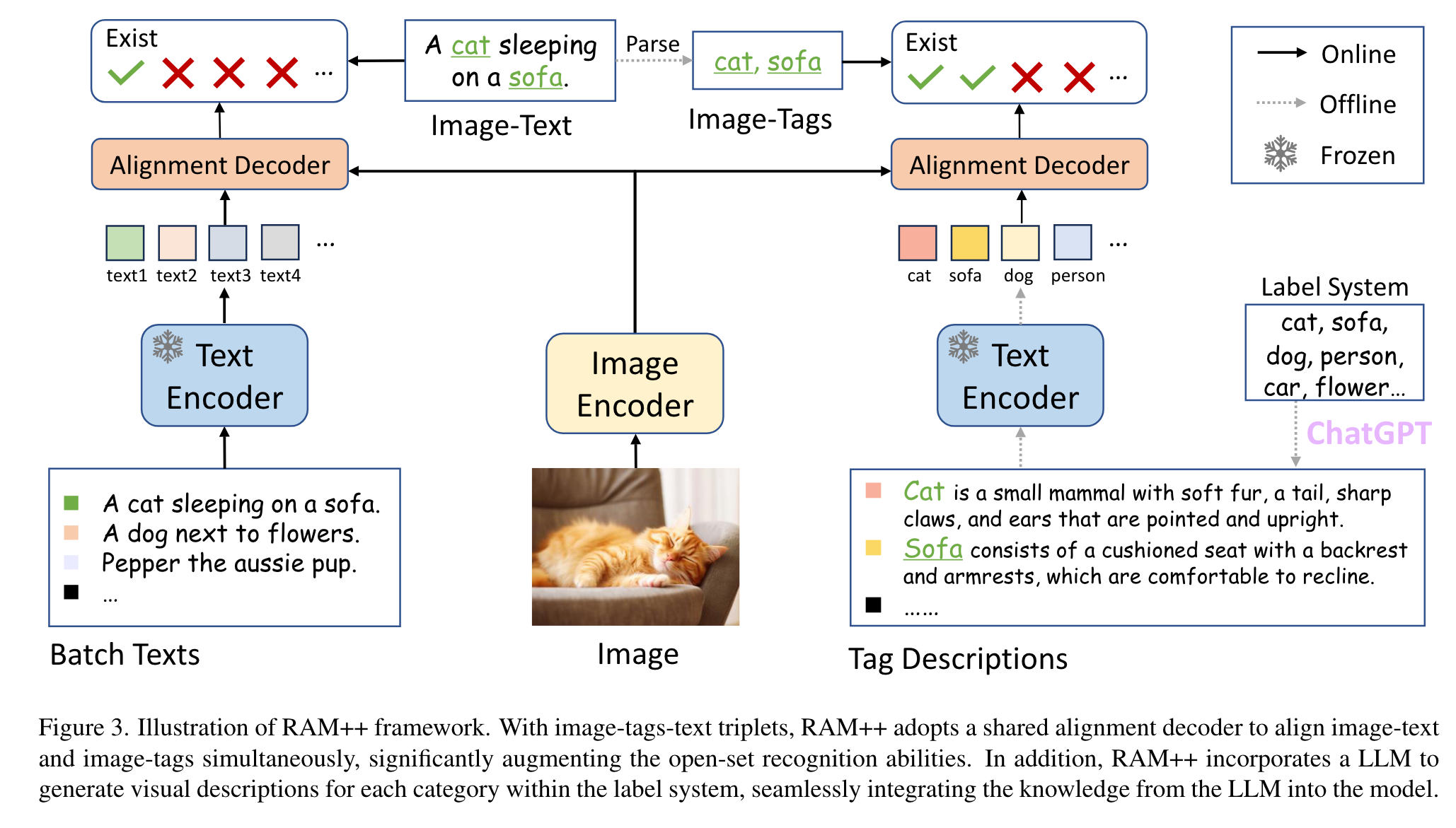
In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tagstext triplets. This design enables RAM++ not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories (p. 1)
There are two principal research avenues for image recognition:
- Image tagging, also known as multi-label image recognition, aims to provide multiple semantic labels within a given image. Predominantly, such models rely on manually annotated datasets with limited scale [12, 27], resulting in only performing well on specific datasets and categories.
- Vision-Language models based on large scale image-text pairs, which can align various semantic texts with an image. The representative work is CLIP [41], which has powerful open-set recognition capabilities and widely empowers other fields, such as open-set object detection [15], image segmentation [15] and video tasks [32]. (p. 2)
Although CLIP showcases remarkable zero-shot performance in image single label classification [9], its interaction on visual-linguistic features (dot product) is relatively shallow, making it difficult to handle more realistic finegrained image tagging tasks [52]. (p. 2)
Specifically, we adopt the LLM to automatically generate diverse visual descriptions for each tag category and synthesize into tag embeddings to align with image features. (p. 2)
Proposed Method
To recognize categories beyond the fixed label system, RAM utilizes an off-the-shelf text encoder [41] to extract textual tag embeddings. (p. 4)
Image-Text Alignment
With image-tags-text triplets, RAM only performs image tags alignment for image tagging. To enrich the semantic concepts beyond fixed tag categories, we introduce Image Text Alignment in addition to image-tags alignment within the tagging framework. (p. 4)
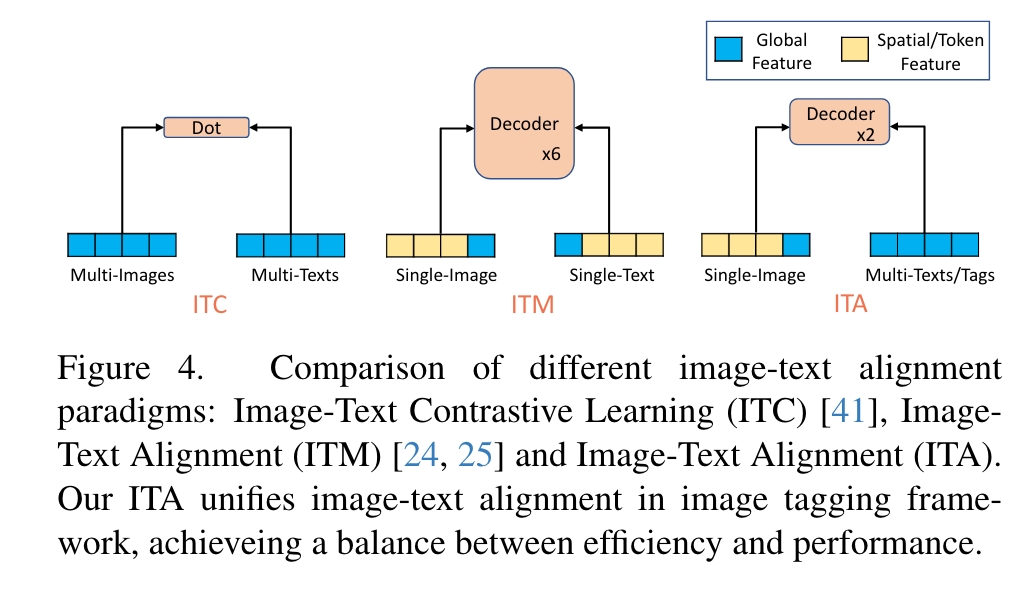
For image tagging, the tag categories are fixed but large quantity (over 4500 categories). Although extracting embedding for all categories is time-consuming, the tag embeddings can be extracted offline using an off-the-shelf text encoder. (p. 4)
Our ITA achieves a balance between performance and efficiency, capable of aligning a single image with thousands of tags or texts with high efficiency. Moreover, by deleting the self-attention layers in the alignment decoder, ITA support any quantity of texts or tags without affecting performance. (p. 4)
LLM-Based Tag Description
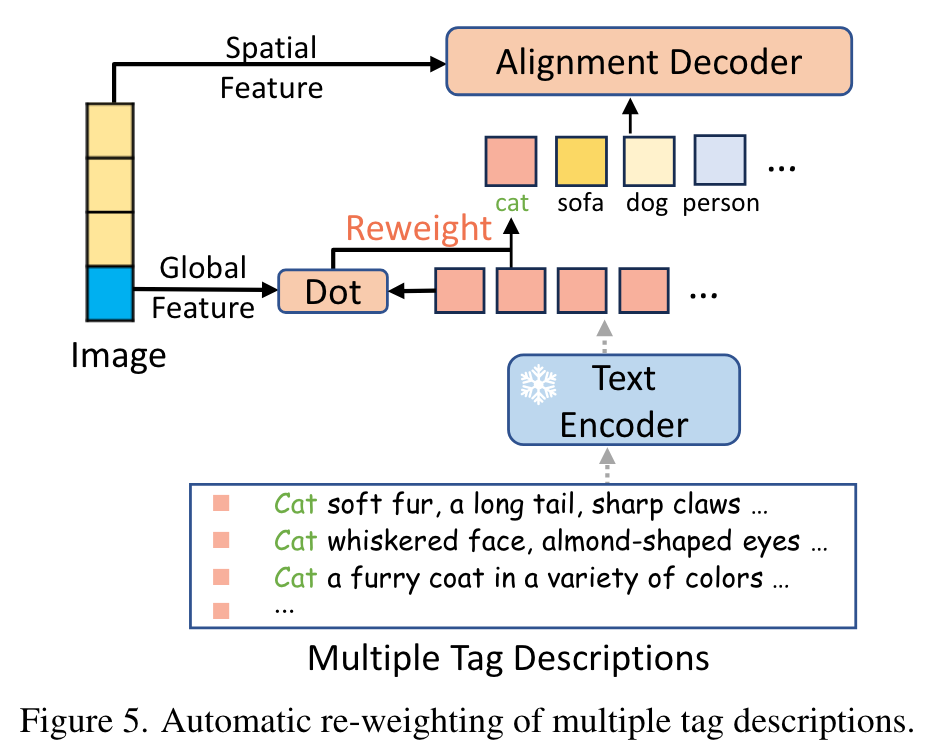
This approach involves generating distinct descriptions for each tag category, leveraging the capabilities of the LLM in the context of image tagging training. (p. 5)
We anticipate that the tag descriptions generated by LLMs predominantly exhibit two characteristics: 1) As diverse as possible to cover a broader range of scenarios; 2) As relevant as possible to image features for ensuring high relevance. (p. 5)
Drawing inspiration from [40], we design a total of five LLM prompts for each tag category, as follows: (1) “Describe concisely what a(n) {} looks like”; (2) “How can you identify a(n) {} concisely?”; (3) “What does a(n) {} look like concisely?”; (4) “What are the identifying characteristics of a(n) {}”; (5) “Please provide a concise description of the visual characteristics of {}”. (p. 5)
To promote the diversity of the LLM responses, we set temperature = 0.99. Consequently, we acquired 10 unique responses for each LLM prompt, amassing a total of 50 tag descriptions per category. (p. 5)
Experiment
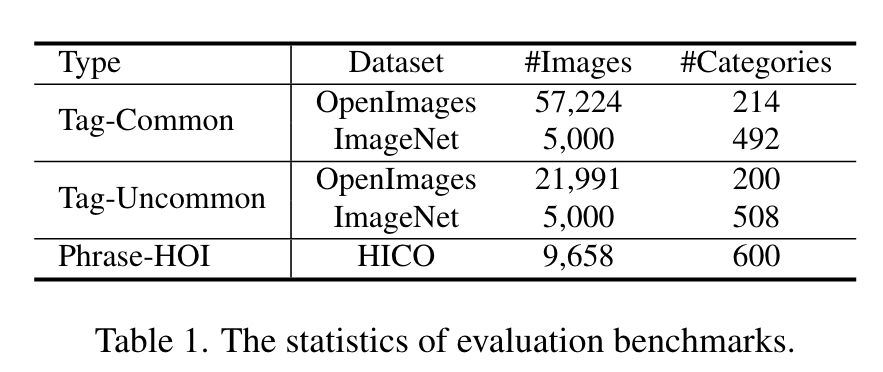
Our label system includes 4,585 categories that commonly used in texts. (p. 5)
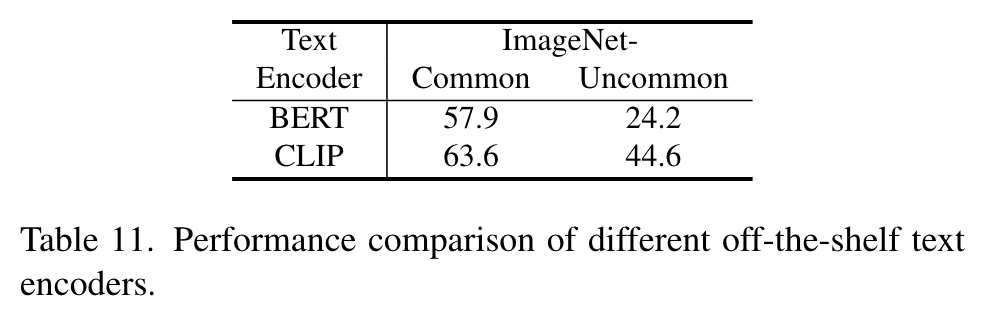
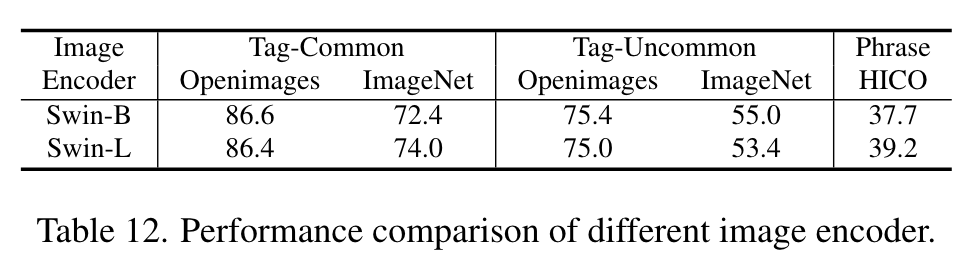
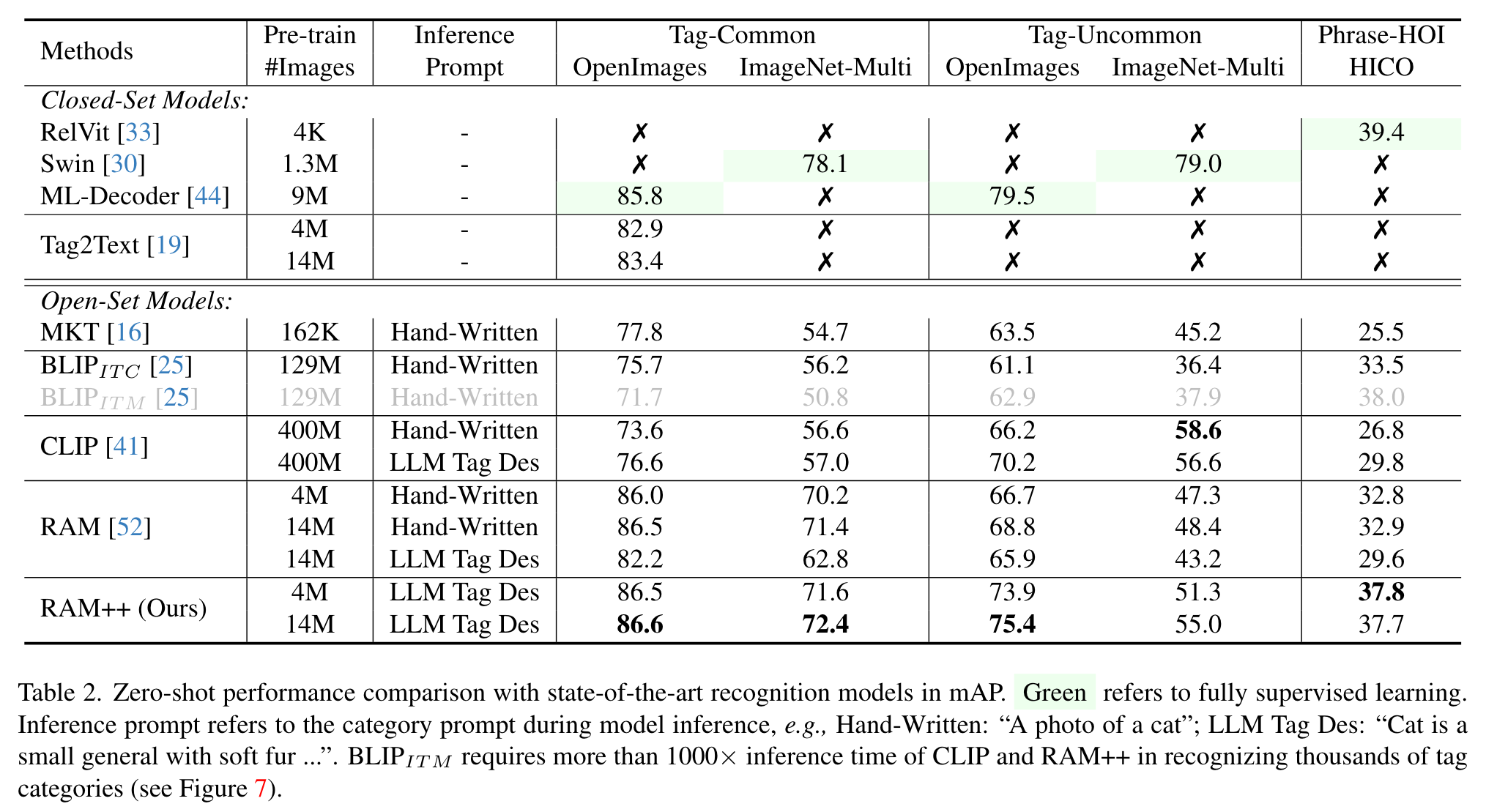
We employ SwinBase [30] pretrained on ImageNet [9] as the image encoder, and also select base scale models when comparing with other methods for fair comparison. We leverage the off-the-shelf text encoder from CLIP [41] to extract tag and text features. The alignment decoder is a 2-layer transformer [47] with each layer only consist of cross-attention layer and feed-forward layer. We adopt ASL [43] loss function for both image tagging and image-text alignment (p. 5)

Ablation
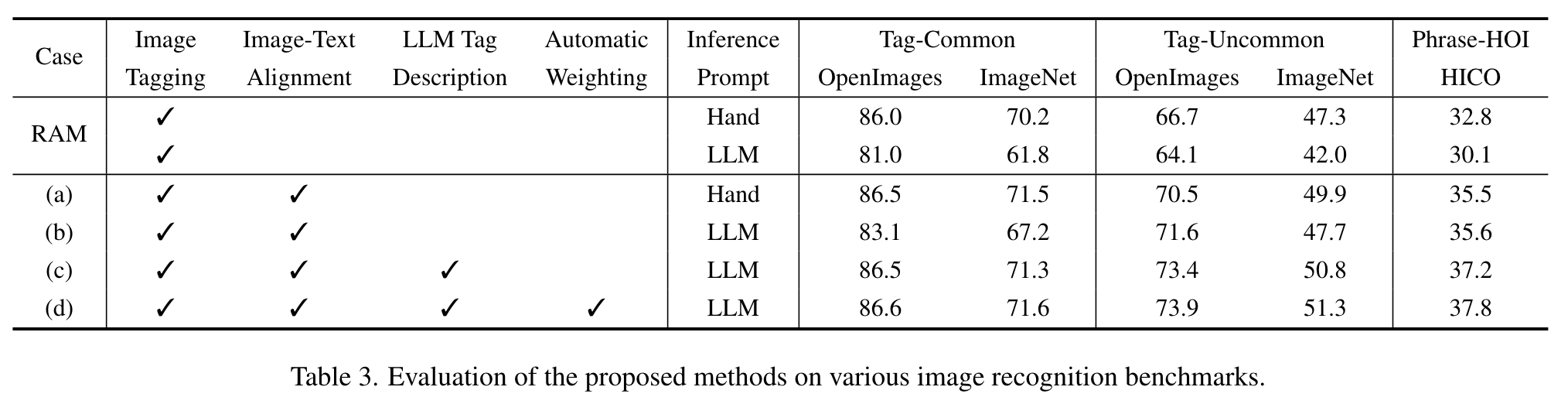
- Case (a) demonstrates that the integration of Image-Text Alignment within the image tagging framework can effectively enhance the model’s recognition capabilities in openset categories (p. 7)
- Case (c) underscores the effectiveness of incorporating LLM-based tag descriptions in the training stage. (p. 7)
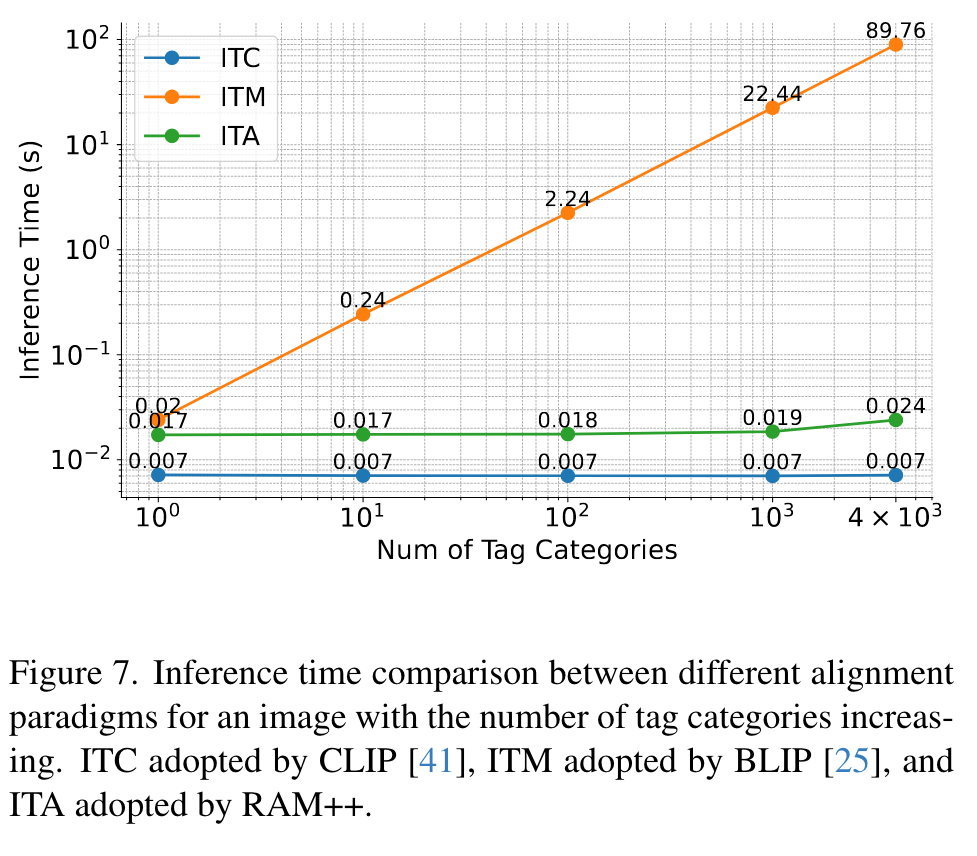
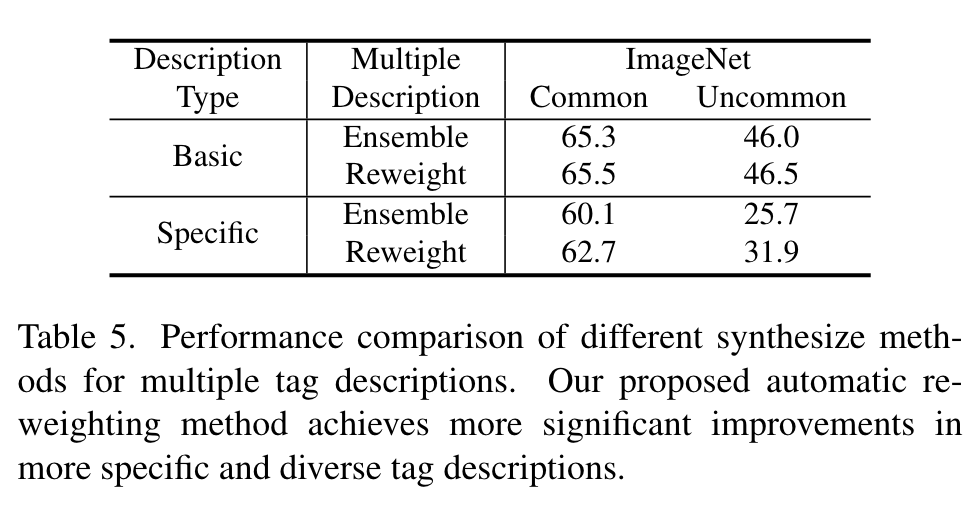
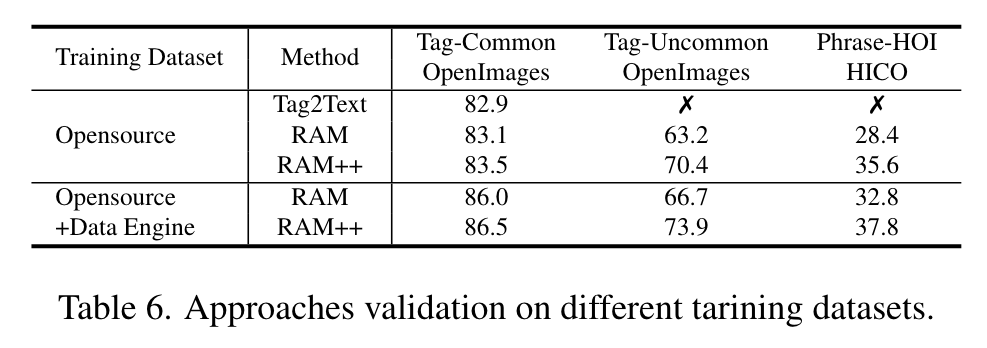
We observe that the LLM description diversity controlled by temperature is characterized by limited semantic diversity yet mostly rephrasing the same sentence. (p. 8)
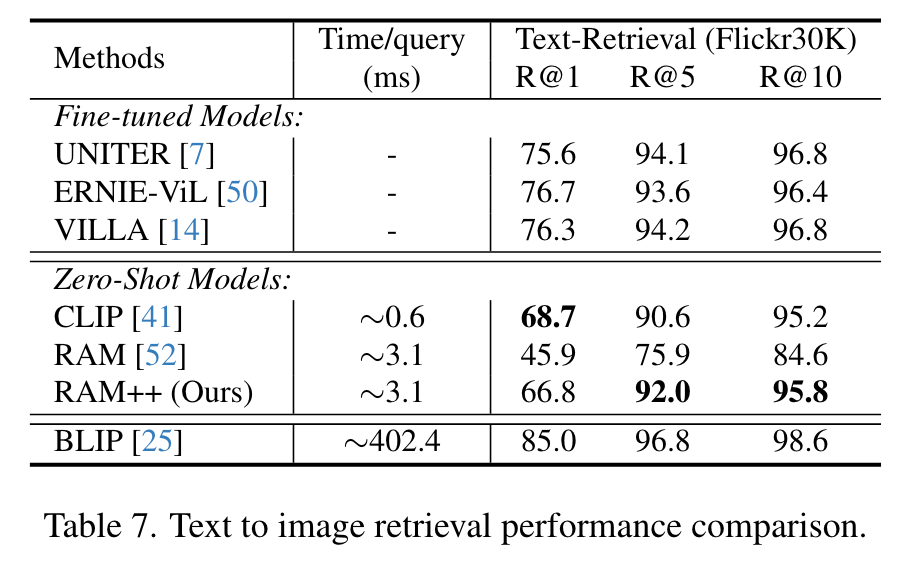
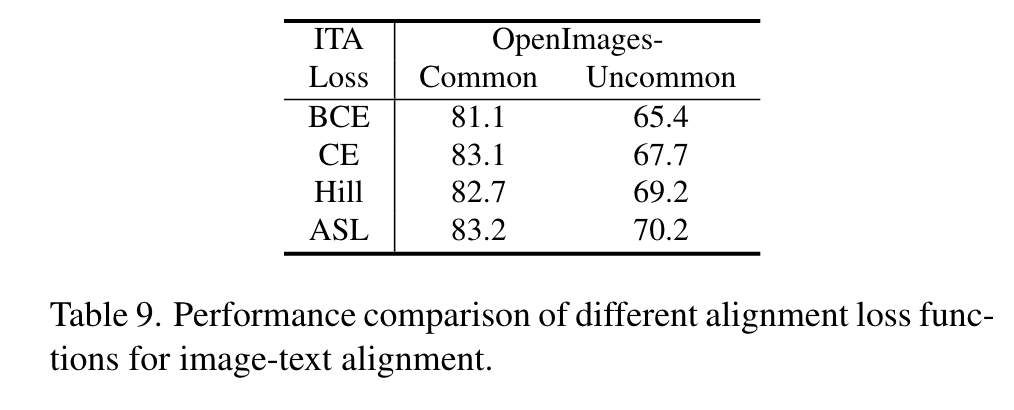
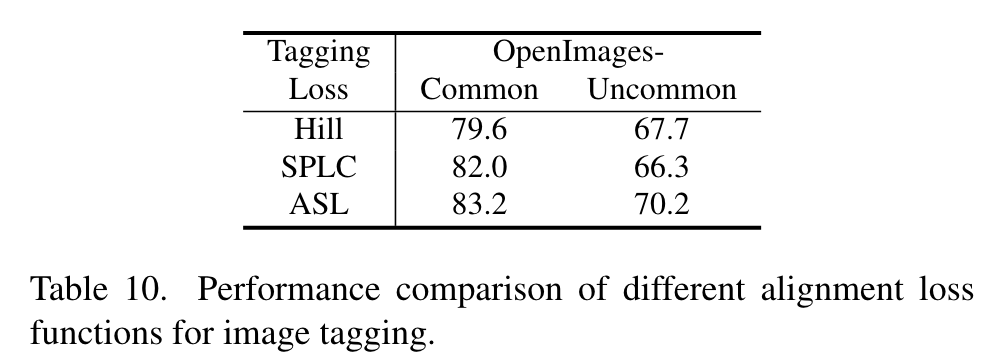
Image-Text Alignment Loss Function. In Table 9 and Table 10, we compare different alignment loss functions for image-text alignment and image tagging, including the Cross Entropy (CE) function employed by CLIP, and other robust tagging loss functions (BCE, ASL [43], Hill [51], SPLC [51]). The results indicate that ASL outperforms other loss functions, which alleviates the potential missing labels and imbalance between positive and negative samples. (p. 11)