SAM-CLIP Merging Vision Foundation Models towards Semantic and Spatial Understanding
[multimodal segment deep-learning segment-anything sam clip model-merging multi-task-learning multi-objective-learning catastrophic-forgetting continual-learning This is my reading note for SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding. This paper proposes a method to combine clip and Sam to perform zero shot semantic segmentation. To combined model merges the vision encoder of Sam and clip, but freezes the other encoders and heads. To avoid catastrophe forgetting, The paper uses two stage method, in first stage, only CLIP’S head is fine tuned; in second stage, the shared vision encode and two heads are fine tuned in a multi task way.
Introduction
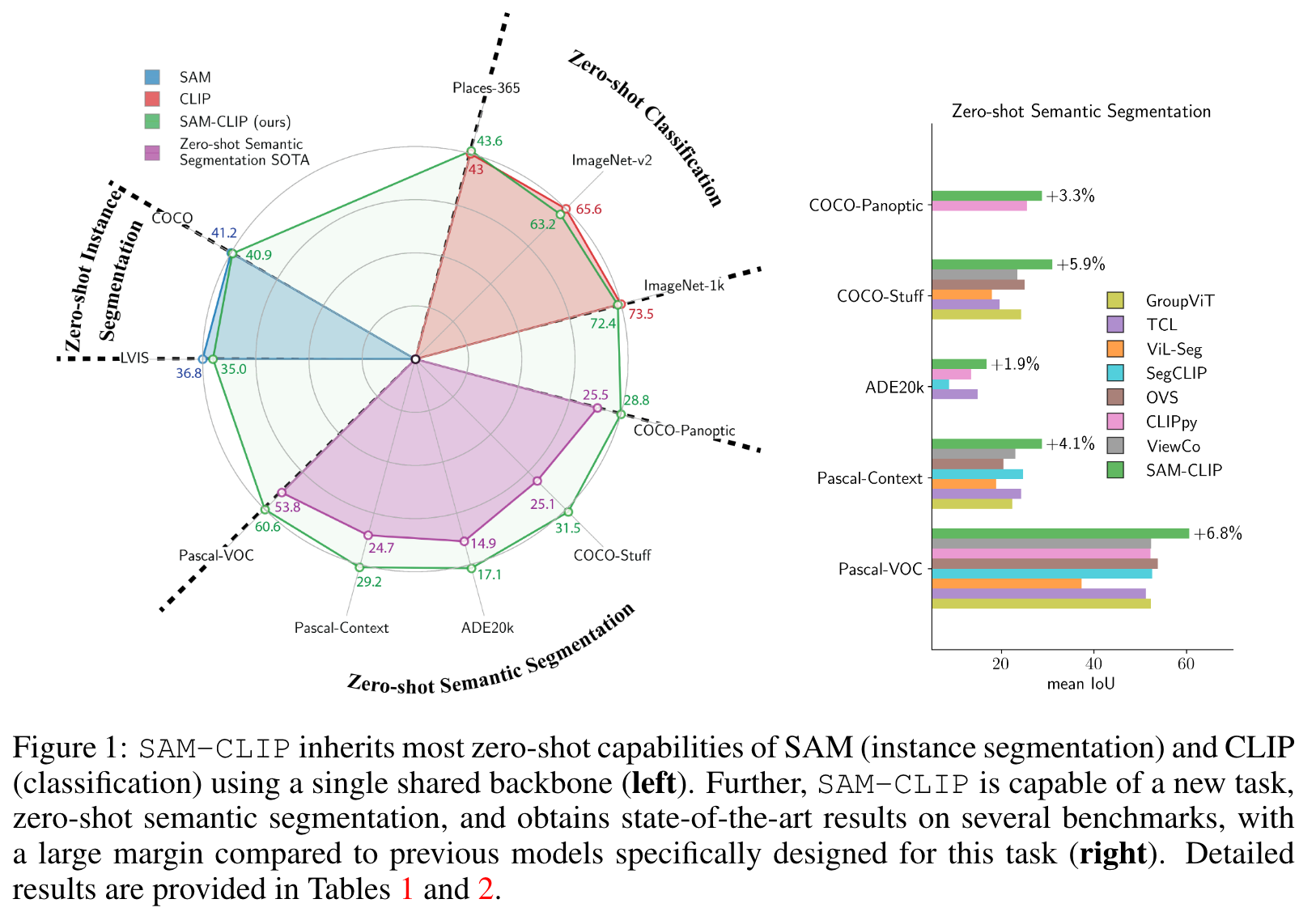
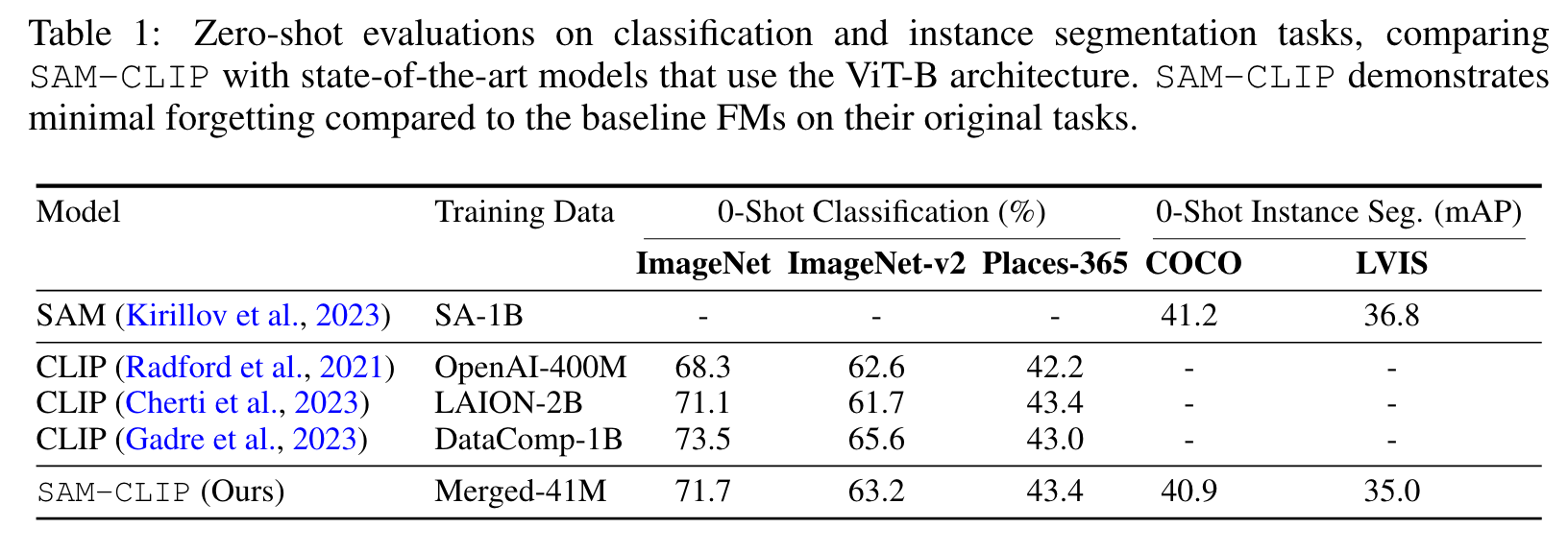
By applying our method to SAM and CLIP, we derive SAM-CLIP : a unified model that amalgamates the strengths of SAM and CLIP into a single backbone, making it apt for edge device applications. We show that SAM-CLIP learns richer visual representations, equipped with both localization and semantic features, suitable for a broad range of vision tasks. (p. 1)
A multi-objective pre-training method requires comparable or more data and compute power as single objective VFM training. Additionally, there are still challenges to be addressed, such as how to best mix datasets, how to handle interfering gradients and instabilities in multi-task training (Du et al., 2019), and how to access to VFM pre-training datasets that are often proprietary (Radford et al., 2021), which limit the scalability and feasibility of this approach. (p. 2)
To overcome these challenges, model merging has emerged as a rapidly growing area of research (Sung et al., 2023; Yadav et al., 2023). The majority of merging techniques focus on combining multiple task-specific models into a single model without requiring additional training. (p. 2)
For instance, this can be achieved through techniques such as model weights interpolation (Ilharco et al., 2022b), parameter importance analysis (Matena & Raffel, 2022), or leveraging invariances in the models (Ainsworth et al., 2022). These techniques, on the other side, put too much stress on not using data or not performing additional training/finetuning resulting in decreased performance or lack of generalization to diverse set of tasks (Sung et al., 2023). (p. 2)
We treat model merging as a continual learning problem, where, given a pretrained VFM, the knowledge of a second VFM is merged without forgetting of the initial knowledge. On one side, in contrast to weight averaging techniques, we allow access to small part of pretraining data or its surrogates to be replayed during the merging process. We leverage multi-task distillation on the replay data to avoid forgetting the original knowledge of pretrained VFMs during the merging process. On the other side, our merging process is significantly more efficient than traditional multitask training by requiring less than 10% of the data and computational cost compared to their original pretraining (Section 3). (p. 3)
Background
Continual Learning
The main challenge in continual learning is catastrophic forgetting (McClelland et al., 1995; McCloskey & Cohen, 1989) referring to loss of previously learned knowledge due to learning new tasks. Continual Learning algorithms usually alleviate forgetting via
- regularization (Kirkpatrick et al., 2017; Zenke et al., 2017),
- experience replay (Rebuffi et al., 2017; Hayes et al., 2019),
- regularized replay (Chaudhry et al., 2018; Farajtabar et al., 2020),
- dynamic expansion (Yoon et al., 2017; Schwarz et al., 2018),
- and optimization based methods (Pan et al., 2020; Mirzadeh et al., 2020), among them, replay based methods proved to be simple yet very successful ones (Lomonaco et al., 2022; Balaji et al., 2020). (p. 4)
Merging Models
Merging Models techniques aim to combine the capability of different models by simple interpolation operations such as
- weight averaging (Wortsman et al., 2022)
- and task arithmetic (Ilharco et al., 2022b).
- Recently there’s abundance of such techniques (Choshen et al., 2022; Matena & Raffel, 2022; Muqeeth et al., 2023; Wu et al., 2023; Ilharco et al., 2022a; Stoica et al., 2023; Khanuja et al., 2021; Bai et al., 2022) employing different weight schemes and parameter sensitivity and importance. (p. 4)
PROPOSED APPROACH
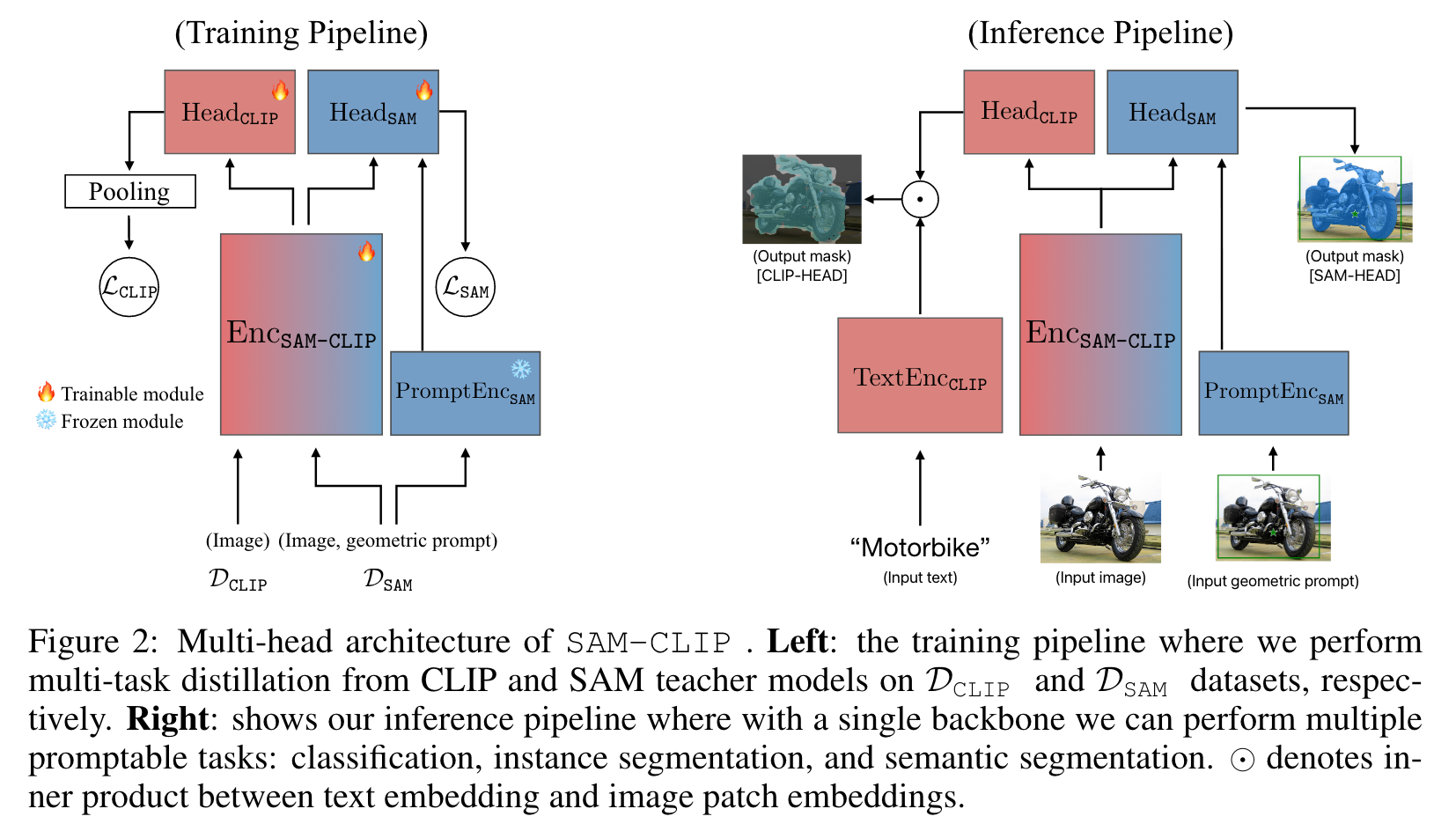
We start with a VFM as the base model, then transfer knowledge from other auxiliary VFMs to it with minimal forgetting. We assume that each VFM possesses a vision encoder, and potentially other modality encoders, as well as task-specific decoders/heads. Our goal is to combine the vision encoders into a single backbone such that it can be used in conjunction with other modality encoders, which remain frozen. (p. 5)
However, existing pretrained CLIP ViT models are inefficient in dealing with high-resolution images that are used for SAM training. Hence, we choose SAM as the base model and inherits its ViT-Det structure that can process high-resolution inputs efficiently. (p. 5)
We assume access to limited subsets of datasets (or their proxies) used to train the base and auxiliary VFMs, which function as memory replay in our CL setup. (p. 5)
As a baseline merging approach, we perform KD on DCLIP utilizing a cosine distillation loss (Grill et al., 2020): (p. 5)
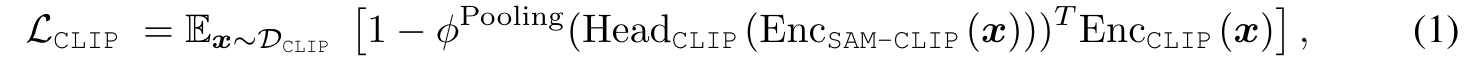
In this setup, parameters of both HeadCLIP and Enc_{SAM-CLIP} are learnable, while the CLIP encoder, Enc_{CLIP} , is frozen and used as a teacher. While this infuses SAM with CLIP’s semantic abilities, it incurs at the cost of catastrophic forgetting of SAM’s original capabilities. Further, we show that training-free mitigative methods against catastrophic forgetting, such as Wise-FT (Wortsman et al., 2022), to be ineffective in our context of VFM merging, as demonstrated in section C. (p. 5)
To address these challenges, we propose a rehearsal-based multi-task distillation. Inspired by Kumar et al. (2022), we consider a two-stage training: head-probing and multi-task distillation. An optional stage of resolution adaptation can be appended if the multiple heads are trained under different resolutions (p. 5)
- Head probing: In this stage, we first freeze the image backbone, EncSAM-CLIP , and only train HeadCLIP (p. 5)
- Multi-task distillation: In this stage, we allow all heads as well as our image encoder to be learnable. We perform a multi-task training on LCLIP + λLSAM , with: (p. 5)

IMPLEMENTATION DETAILS
Model Architecture
We employ the ViT-B/16 version of the Segment Anything Model (SAM) as our base architecture (Kirillov et al., 2023), comprising 12 transformer layers. To integrate CLIP capabilities, we append a lightweight CLIP head consisting of 3 transformer layers to the SAM backbone. The patch token outputs from this CLIP head undergo a pooling layer to produce an image-level embedding, akin to the role of the CLS token output in ViT models. We adopt maxpooling since we observe that it can lead to better zero-shot classification and semantic segmentation performance of SAM-CLIP than average pooling. (p. 6)
Dataset Preparation
This forms our D_CLIP containing 40.6M unlabeled images. For the SAM self distillation, we sample 5.7% subset from the SA-1B dataset to form DSAM , which originally comprises 11M images and 1.1B masks. We randomly select 1% of DCLIP and DSAM as validation sets. (p. 6)
Training
The first stage of CLIP-head probing takes 20 epochs on DCLIP , while the backbone is kept frozen. (p. 6)
In the second stage (16 epochs), we unfreeze the backbone EncSAM-CLIP and proceed with joint fine-tuning together with HeadCLIP and HeadSAM , incorporating both CLIP and SAM distillation losses at the ratio of 1:10. (p. 6)
Further, the learning rates applied to EncSAM-CLIP and HeadSAM are 10 times smaller than that of HeadCLIP in order to reduce the forgetting of the original SAM abilities. (p. 6)
Resolution Adaption
To remedy this issue, we adapt the CLIP head for 1024px input using a very short and efficient stage of finetuning: freezing the image encoder and only finetuning the CLIP-head with LCLIP for 3 epochs (p. 7)
EXPERIMENTS
ZERO-SHOT EVALUATIONS

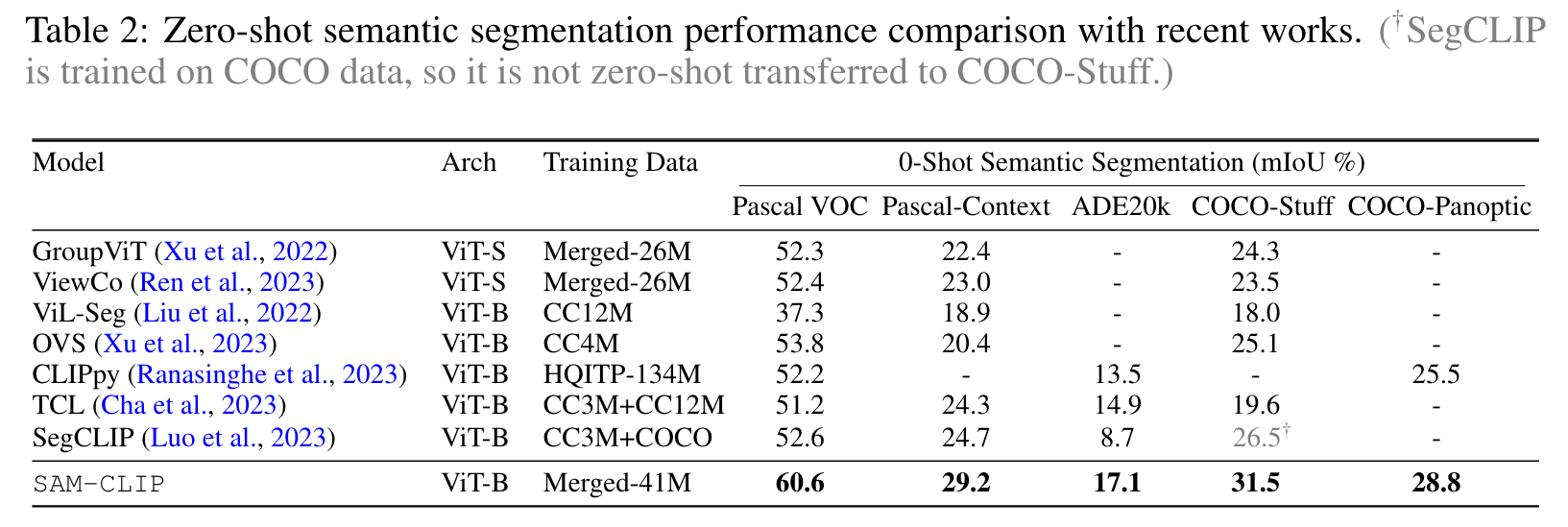
We adopt a common evaluation protocol for this task: i) each input image is resized to 448×448px and pass to the image encoder and CLIP-head of SAM-CLIP to obtain 28 × 28 patch features; ii) OpenAI’s 80 pre-defined CLIP text templates are employed to generate textual embeddings for each semantic class, and these embeddings act as mask prediction classifiers and operate on the patch features from the CLIP head; iii) we linearly upscale the mask prediction logits to match the dimensions of the input image. (p. 8)
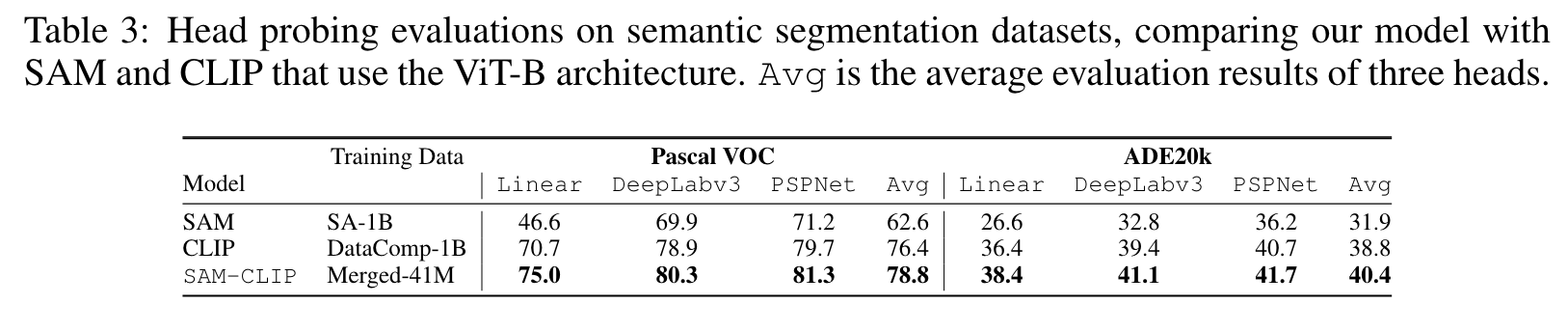
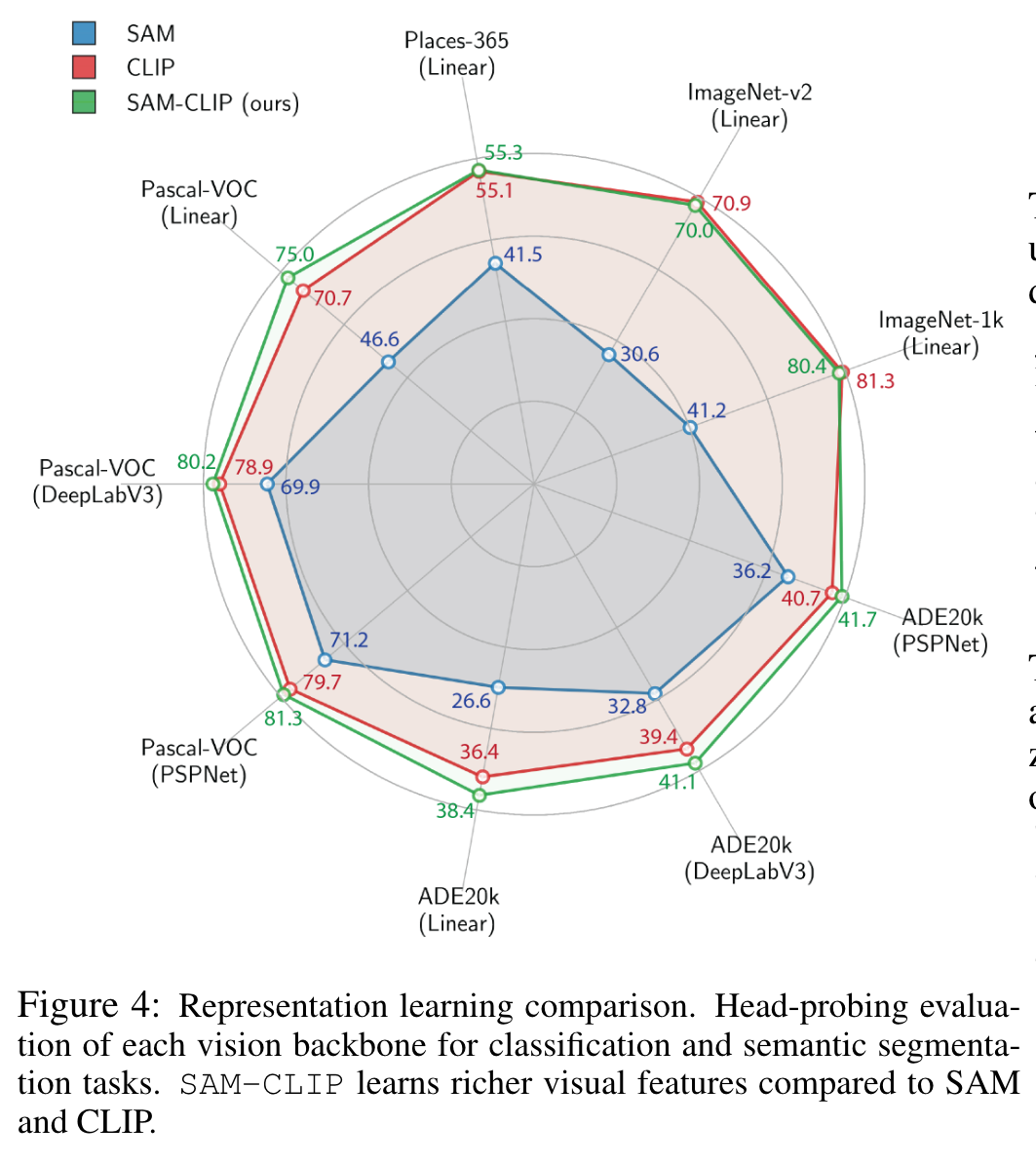
HEAD-PROBING EVALUATIONS ON LEARNED REPRESENTATIONS
The results are presented in Table 3.We observe that SAM representations do not perform as well as those of CLIP for tasks that require semantic understanding, even for semantic segmentation task (p. 8)
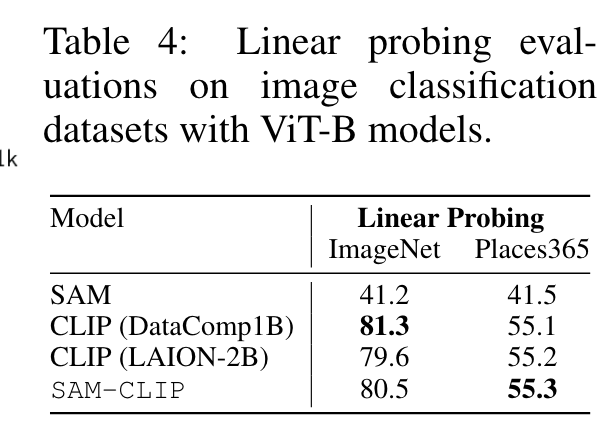
Results in Table 4 show that SAM-CLIP attains comparable performance with CLIP, implying that the image-level representation of SAM-CLIP is also well-learned. (p. 8)
COMPOSING BOTH CLIP AND SAM HEADS FOR BETTER SEGMENTATION

Specifically, we resize the input image to 1024px and pass it through EncSAM-CLIP , and use the CLIP head to generate low-resolution mask prediction (32 × 32) using text prompts. Then, we generate some point prompts from the mask prediction (importance sampling based on the mask prediction confidence), and pass the mask prediction and point prompts together to the prompt encoder module as geometric prompts. Finally, HeadSAM takes embeddings from both the prompt encoder and the image encoder to generate high-resolution mask predictions (256 × 256) (p. 9)