Segment Anything Meets Point Tracking
[sam-track tracking tracking-anything raft xmem deoat persam dino segment-anything deep-learning transformer seg-gpt sam point-tracking This is my reading note for Segment Anything Meets Point Tracking. This paper combines SAM with point tracker to perform object segment and tracking in video. To to that it use point tracker to track points through the frames.for points of each frame SAM generate masks from the points promote. After every 8 frames, new points will be sampled from the mask.for best performance, 8 positive points and l negative points is recommended.
Introduction
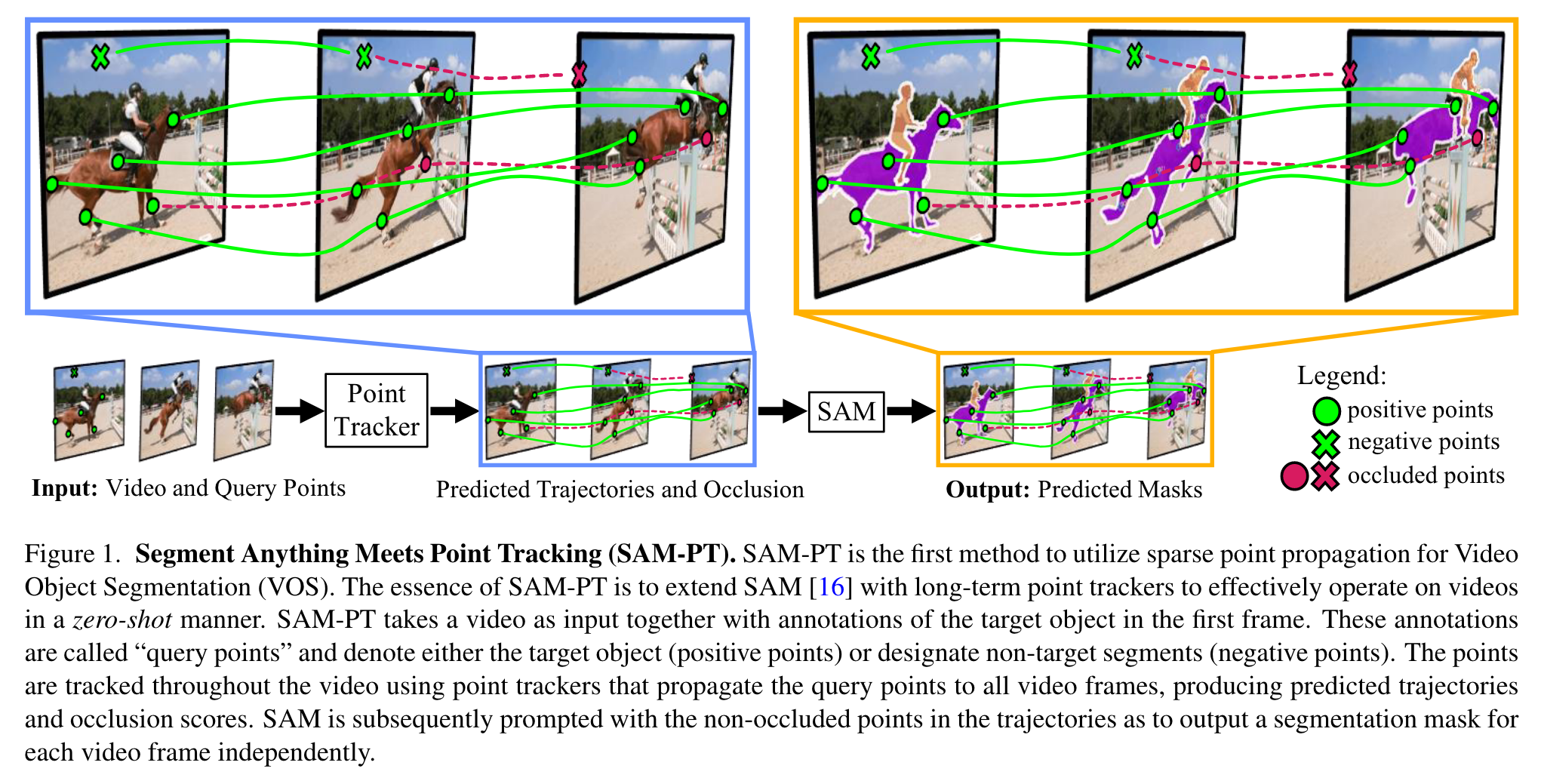
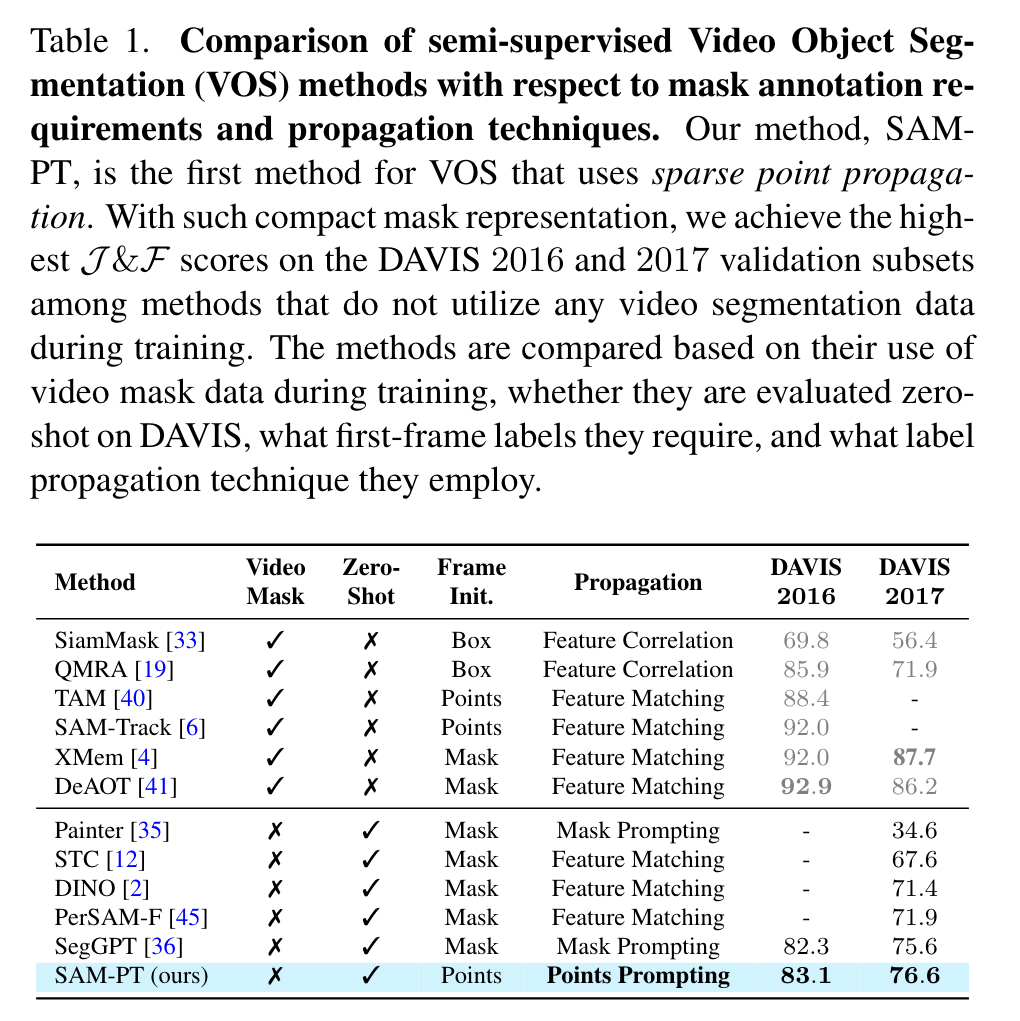
These annotations are called “query points” and denote either the target object (positive points) or designate non-target segments (negative points). The points are tracked throughout the video using point trackers that propagate the query points to all video frames, producing predicted trajectories (p. 1)
SAM-PT leverages robust and sparse point selection and propagation techniques for mask generation. Compared to traditional object-centric mask propagation strategies, we uniquely use point propagation to exploit local structure information that is agnostic to object semantics (p. 1)
- TAM [40] integrates SAM with the state-of-the-art memory-based mask tracker XMem [4]. Likewise, SAM-Track [6] combines SAM with DeAOT [41]. (p. 2)
- Other methods that do not leverage SAM, such as SegGPT [36], can successfully solve a number of segmentation problems using visual prompting, but still require mask annotation for the first video frame. (p. 2)
Instead of employing object-centric dense feature matching or mask propagation, we propose a point-driven approach that capitalizes on tracking points using rich local structure information embedded in videos. (p. 2)
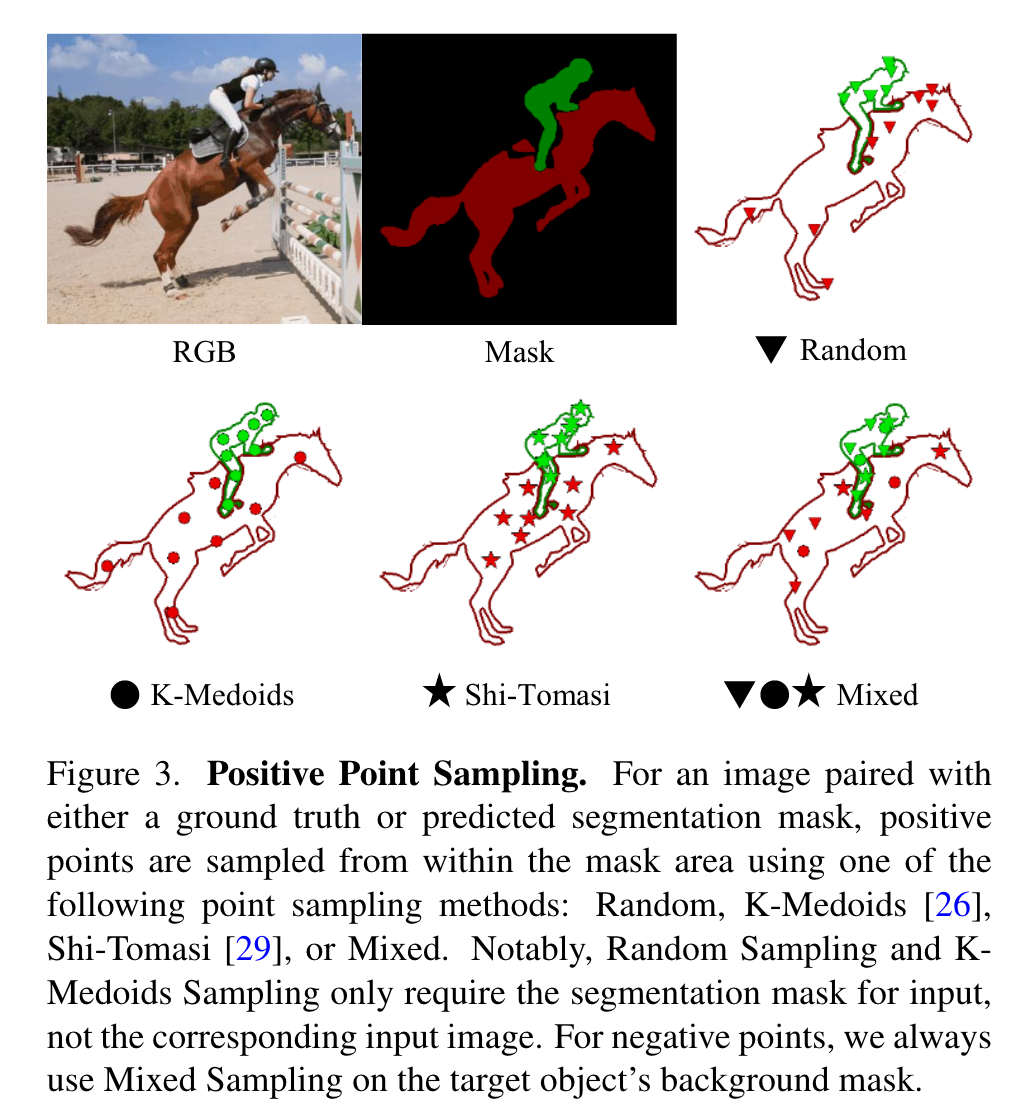
We identify that initializing points to track using K-Medoids cluster centers from a mask label was the strategy most compatible with prompting SAM. Tracking both positive and negative points enables the clear delineation of target objects from their background. To further refine the output masks, we propose multiple mask decoding passes that integrate both types of points. In addition, we devised a point re-initialization strategy that increases tracking accuracy over time. This approach involves discarding points that have become unreliable or occluded, and adding points from object parts or segments that become visible in later frames, such as when the object rotates. (p. 2)
Related Work
Point Tracking for Video Segmentation.
their effectiveness is confined to a specific set of distinct interest points and they often struggle when applied to non-rigid, dynamic scenes. Flow-based methods, such as RAFT [30], excel in tracking dense points between successive frames. However, they stumble with deriving accurate long-range point trajectories. When chaining flow predictions over time, errors (p. 2)
Segment and Track Anything models
These methods employ SAM for mask initialization or correction and XMem/DeAOT for mask tracking and prediction. Using the pre-trained mask trackers recovers the indistribution performance, but hinders the performance in zero-shot settings. PerSAM [45] also demonstrates the ability to track multiple reference objects in a (p. 3)
Zero-shot VOS / VIS
In the semi-supervised video object segmentation, they take a reference mask as input and perform frame-by-frame feature matching, which propagates the reference mask across the entirety of the video (p. 3)
Segment Anything Model
SAM comprises of three main components: an image encoder, a flexible prompt encoder, and a fast mask decoder. The image encoder is a Vision Transformer (ViT) backbone and processes high-resolution 1024 × 1024 images to generate an image embedding of 64 × 64 spatial size. The prompt encoder takes sparse prompts as input, including points, boxes, and text, or dense prompts such as masks, and translates these prompts into c-dimensional tokens. The lightweight mask decoder then integrates the image and prompt embeddings to predict segmentation masks in real-time, allowing SAM to adapt to diverse prompts with minimal computational overhead. (p. 3)
Method
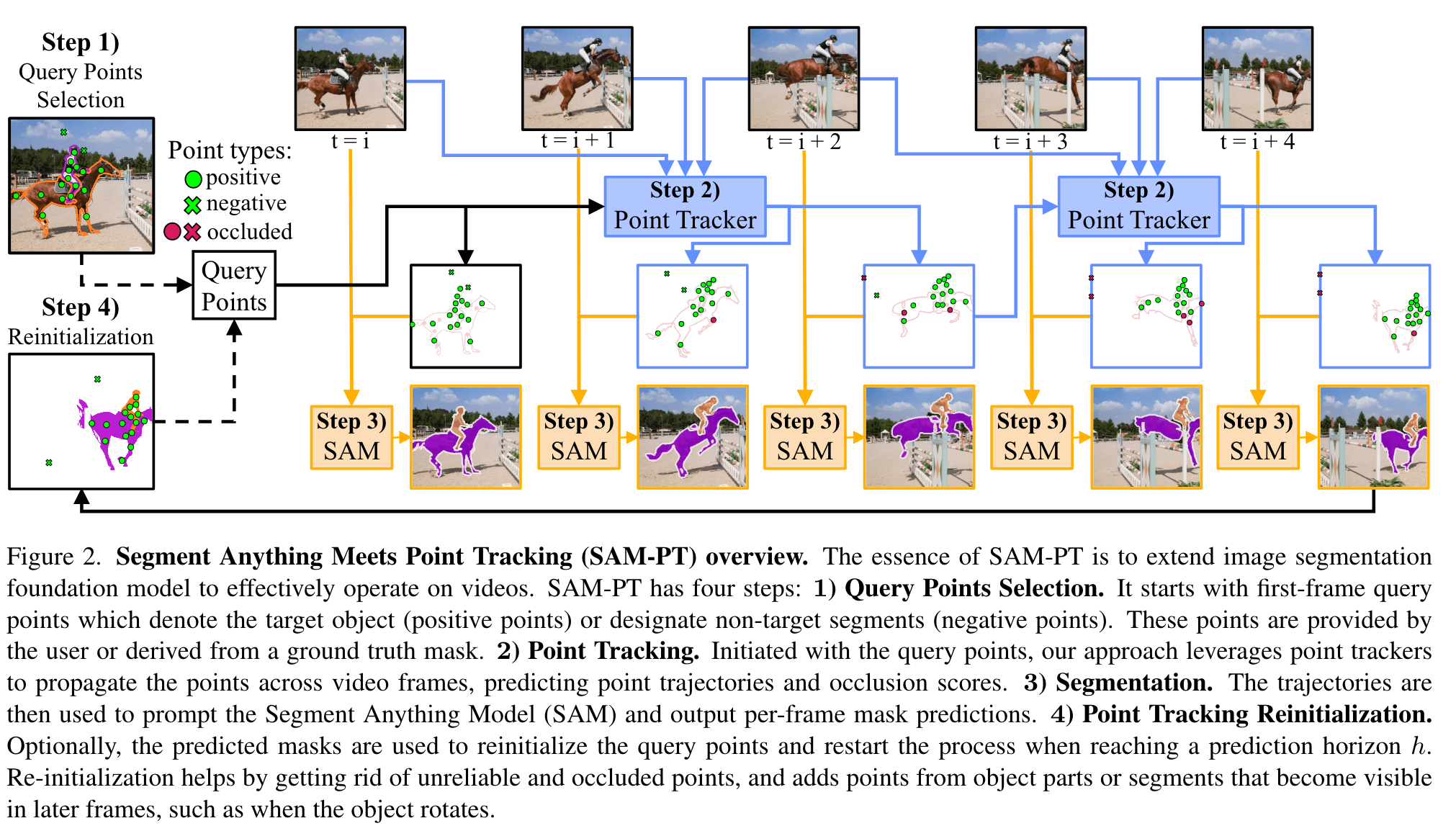
SAM-PT is illustrated in Fig. 2 and is primarily composed of four steps: 1) selecting query points for the first frame; 2) propagating these points to all video frames using point trackers; 3) using SAM to generate per-frame segmentation masks based on the propagated points; 4) optionally reinitializing the process by sampling query points from the predicted masks. We next elaborate on these four steps. (p. 3)
Segmentation
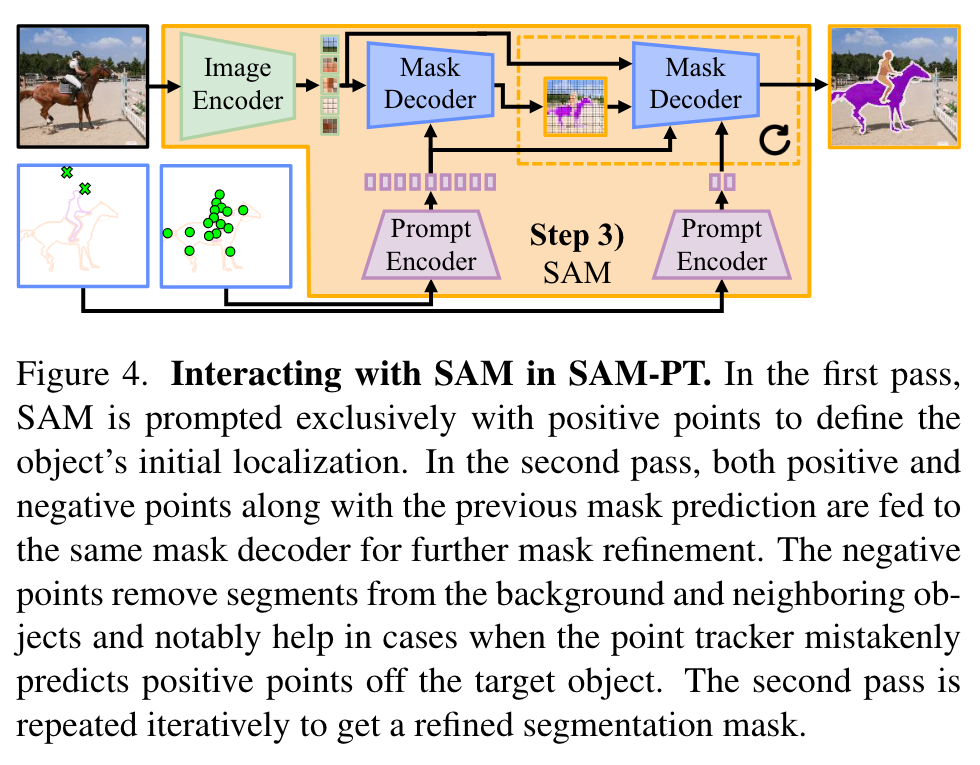
we prompt SAM exclusively with positive points to define the object’s initial localization. Subsequently, in the second pass, we prompt SAM with both positive and negative points along with the previous mask prediction. Negative points provide a more nuanced distinction between the object and the background and help by removing wrongly segmented areas. (p. 5)
Lastly, we execute a variable number of mask refinement iterations by repeating the second pass. This utilizes SAM’s capacity to refine vague masks into more precise ones (p. 5)
Point Tracking Reinitialization
We optionally execute a reinitialization of the query points using the predicted masks once a prediction horizon of h = 8 frames is reached, and denote the variant as SAM-PT-reinit. Upon reaching this horizon, we have h predicted masks and will take the last predicted mask to sample new points. At this stage, all previous points are discarded and substituted with the newly sampled points (p. 5)
The steps are iteratively executed until the entire video is processed. The reinitialization process serves to enhance tracking accuracy over time by discarding points that have become unreliable or occluded, while incorporating points from object segments that become visible later in the video. (p. 5)
SAM-PT vs. Object-centric Mask Propagation
First, point propagation exploits local structure context that is agnostic to global object semantics. This enhances our model’s capability for zero-shot generalization, (p. 5)
SAM-PT allows for a more compact object representation with sparse points, capturing enough information to characterize the object’s segments/parts effectively. Finally, the use of points is naturally compatible with SAM, an image segmentation foundation model trained to operate on sparse point prompts, offering an integrated solution that aligns well with the intrinsic capacities of the underlying model. (p. 5)
Implementation Details
PIPS is trained exclusively on a synthetic dataset, FlyingThings++ [11], derived from the FlyingThings [24] optical flow dataset. (p. 7)
we found that using iterative refinement negatively impacted both SAM-PT and SAM-PT-reinit on the MOSE dataset, and likewise hindered SAM-PT-reinit on the YouTube-VOS dataset (p. 7)
Experiment

Ablation Study
Query Point Sampling

Point Tracking

TapNet’s limitations stem from its lack of effective time consistency and its training on 256x256 images, which hampered its performance with higher-resolution images. SuperGlue, while proficient in matching sparse features across rigid scenes, grapples with effectively matching points from the reference frame in dynamic scenes, particularly under object deformations. RAFT, being an optical flow model, faced difficulties handling occlusions. (p. 8)
Negative Points
Tab. 2b highlights that incorporating negative points had a favorable impact, particularly in reducing segmentation errors when points deviated from the target object. The addition of negative points empowered SAM to better handle the point trackers’ failure cases, leading to improved segmentation and a 1.8-point enhancement over the non-use of negative points. (p. 8)
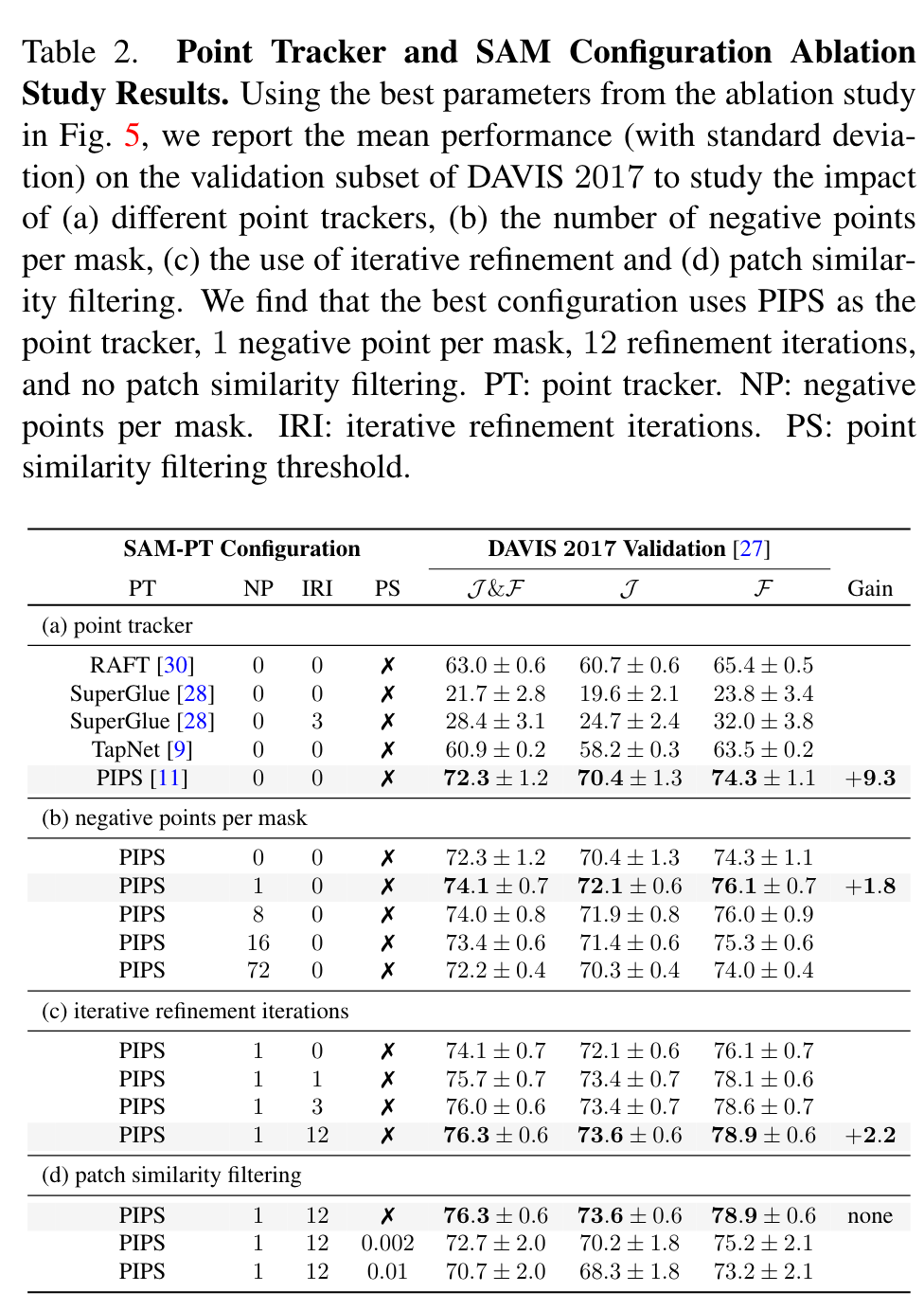

In summary, our best-performing SAM-PT model employs K-Medoids for point selection with 8 points per mask, PIPS for point tracking, a single negative point per mask, and employs 12 iterations for iterative refinement without patch similarity filtering. Meanwhile, using reinitialization achieved optimum performance with 12 refinement iterations and 72 negative points per mask. (p. 9)
Limitation
Despite the competitive zero-shot performance, certain limitations persist, primarily due to the limitations of our point tracker in handling occlusion, small objects, motion blur, and re-identification. In such scenarios, the point tracker’s errors propagate into future video frames (p. 9)