Deep Learning based Semantic Segmentation Algorithm
[segmentation deep-learning 
This posts describes some of the most representative deep learning based semantic segmentation algorithms in the literation. Some of the contents are based on 12篇文章带你逛遍主流分割网络
Fully Convolutional Network
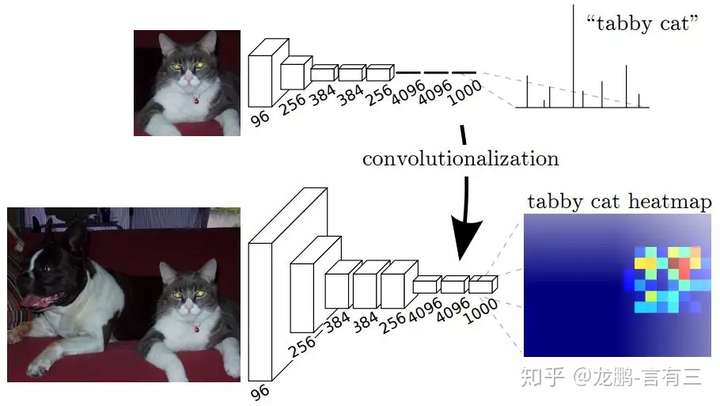
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build “fully convolutional” networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
SegNet
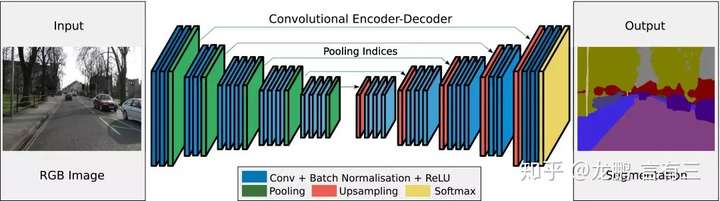
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
We present a novel and practical deep fully convolutional neural network architecture for semantic pixel-wise segmentation termed SegNet. This core trainable segmentation engine consists of an encoder network, a corresponding decoder network followed by a pixel-wise classification layer. The architecture of the encoder network is topologically identical to the 13 convolutional layers in the VGG16 network. The role of the decoder network is to map the low resolution encoder feature maps to full input resolution feature maps for pixel-wise classification. The novelty of SegNet lies is in the manner in which the decoder upsamples its lower resolution input feature map(s). Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. We compare our proposed architecture with the widely adopted FCN and also with the well known DeepLab-LargeFOV, DeconvNet architectures. This comparison reveals the memory versus accuracy trade-off involved in achieving good segmentation performance. SegNet was primarily motivated by scene understanding applications. Hence, it is designed to be efficient both in terms of memory and computational time during inference. It is also significantly smaller in the number of trainable parameters than other competing architectures. We also performed a controlled benchmark of SegNet and other architectures on both road scenes and SUN RGB-D indoor scene segmentation tasks. We show that SegNet provides good performance with competitive inference time and more efficient inference memory-wise as compared to other architectures. We also provide a Caffe implementation of SegNet and a web demo at http://mi.eng.cam.ac.uk/projects/segnet/.
Dilated Convolution
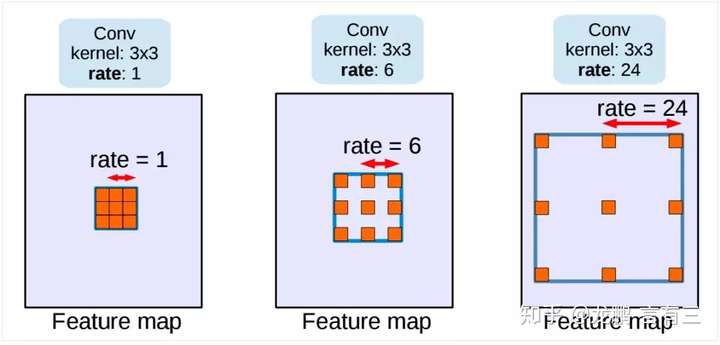
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
Deep Convolutional Neural Networks (DCNNs) have recently shown state of the art performance in high level vision tasks, such as image classification and object detection. This work brings together methods from DCNNs and probabilistic graphical models for addressing the task of pixel-level classification (also called “semantic image segmentation”). We show that responses at the final layer of DCNNs are not sufficiently localized for accurate object segmentation. This is due to the very invariance properties that make DCNNs good for high level tasks. We overcome this poor localization property of deep networks by combining the responses at the final DCNN layer with a fully connected Conditional Random Field (CRF). Qualitatively, our “DeepLab” system is able to localize segment boundaries at a level of accuracy which is beyond previous methods. Quantitatively, our method sets the new state-of-art at the PASCAL VOC-2012 semantic image segmentation task, reaching 71.6% IOU accuracy in the test set. We show how these results can be obtained efficiently: Careful network re-purposing and a novel application of the ‘hole’ algorithm from the wavelet community allow dense computation of neural net responses at 8 frames per second on a modern GPU.
ENet
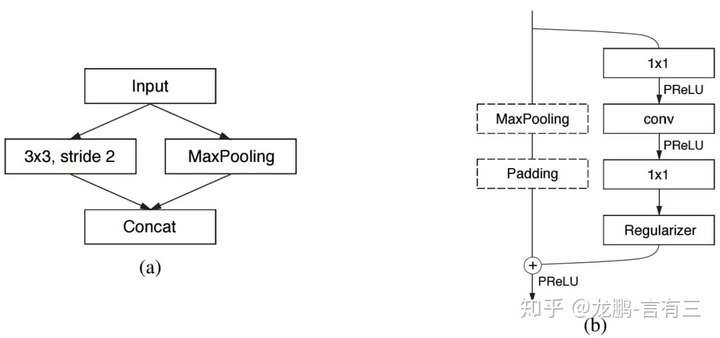
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
The ability to perform pixel-wise semantic segmentation in real-time is of paramount importance in mobile applications. Recent deep neural networks aimed at this task have the disadvantage of requiring a large number of floating point operations and have long run-times that hinder their usability. In this paper, we propose a novel deep neural network architecture named ENet (efficient neural network), created specifically for tasks requiring low latency operation. ENet is up to 18 faster, requires 75 less FLOPs, has 79 less parameters, and provides similar or better accuracy to existing models. We have tested it on CamVid, Cityscapes and SUN datasets and report on comparisons with existing state-of-the-art methods, and the trade-offs between accuracy and processing time of a network. We present performance measurements of the proposed architecture on embedded systems and suggest possible software improvements that could make ENet even faster.
CRFasRNN
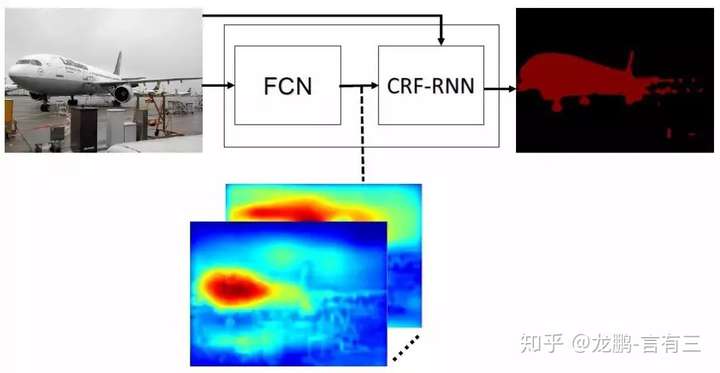
Conditional Random Fields as Recurrent Neural Networks
Pixel-level labelling tasks, such as semantic segmentation, play a central role in image understanding. Recent approaches have attempted to harness the capabilities of deep learning techniques for image recognition to tackle pixel-level labelling tasks. One central issue in this methodology is the limited capacity of deep learning techniques to delineate visual objects. To solve this problem, we introduce a new form of convolutional neural network that combines the strengths of Convolutional Neural Networks (CNNs) and Conditional Random Fields (CRFs)-based probabilistic graphical modelling. To this end, we formulate mean-field approximate inference for the Conditional Random Fields with Gaussian pairwise potentials as Recurrent Neural Networks. This network, called CRF-RNN, is then plugged in as a part of a CNN to obtain a deep network that has desirable properties of both CNNs and CRFs. Importantly, our system fully integrates CRF modelling with CNNs, making it possible to train the whole deep network end-to-end with the usual back-propagation algorithm, avoiding offline post-processing methods for object delineation. We apply the proposed method to the problem of semantic image segmentation, obtaining top results on the challenging Pascal VOC 2012 segmentation benchmark.
PspNet
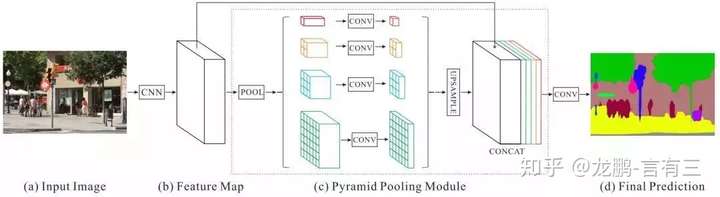
Pyramid Scene Parsing Network
Scene parsing is challenging for unrestricted open vocabulary and diverse scenes. In this paper, we exploit the capability of global context information by different-region-based context aggregation through our pyramid pooling module together with the proposed pyramid scene parsing network (PSPNet). Our global prior representation is effective to produce good quality results on the scene parsing task, while PSPNet provides a superior framework for pixel-level prediction tasks. The proposed approach achieves state-of-the-art performance on various datasets. It came first in ImageNet scene parsing challenge 2016, PASCAL VOC 2012 benchmark and Cityscapes benchmark. A single PSPNet yields new record of mIoU accuracy 85.4% on PASCAL VOC 2012 and accuracy 80.2% on Cityscapes.
ParseNet
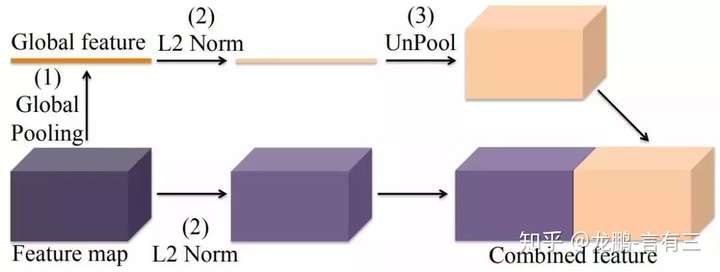
ParseNet: Looking Wider to See Better
We present a technique for adding global context to deep convolutional networks for semantic segmentation. The approach is simple, using the average feature for a layer to augment the features at each location. In addition, we study several idiosyncrasies of training, significantly increasing the performance of baseline networks (e.g. from FCN). When we add our proposed global feature, and a technique for learning normalization parameters, accuracy increases consistently even over our improved versions of the baselines. Our proposed approach, ParseNet, achieves state-of-the-art performance on SiftFlow and PASCAL-Context with small additional computational cost over baselines, and near current state-of-the-art performance on PASCAL VOC 2012 semantic segmentation with a simple approach. Code is available at https://github.com/weiliu89/caffe/tree/fcn
RefineNet
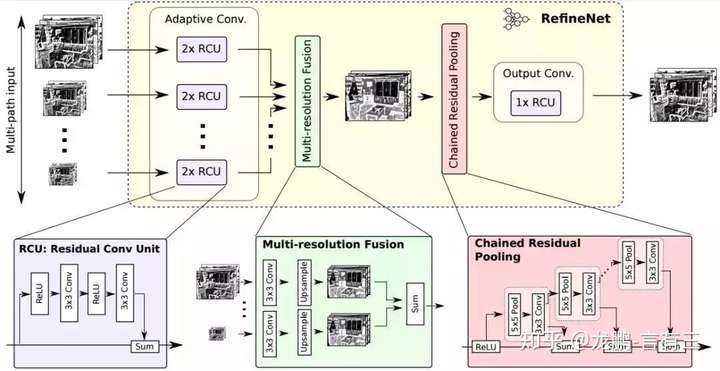
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
Recently, very deep convolutional neural networks (CNNs) have shown outstanding performance in object recognition and have also been the first choice for dense classification problems such as semantic segmentation. However, repeated subsampling operations like pooling or convolution striding in deep CNNs lead to a significant decrease in the initial image resolution. Here, we present RefineNet, a generic multi-path refinement network that explicitly exploits all the information available along the down-sampling process to enable high-resolution prediction using long-range residual connections. In this way, the deeper layers that capture high-level semantic features can be directly refined using fine-grained features from earlier convolutions. The individual components of RefineNet employ residual connections following the identity mapping mindset, which allows for effective end-to-end training. Further, we introduce chained residual pooling, which captures rich background context in an efficient manner. We carry out comprehensive experiments and set new state-of-the-art results on seven public datasets. In particular, we achieve an intersection-over-union score of 83.4 on the challenging PASCAL VOC 2012 dataset, which is the best reported result to date.
ReSeg
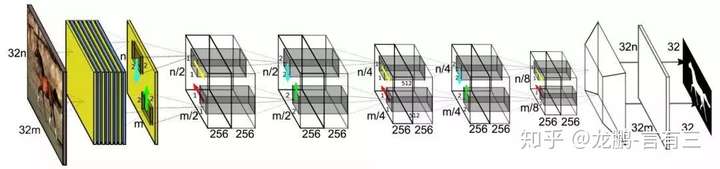
ReSeg: A Recurrent Neural Network-based Model for Semantic Segmentation
We propose a structured prediction architecture, which exploits the local generic features extracted by Convolutional Neural Networks and the capacity of Recurrent Neural Networks (RNN) to retrieve distant dependencies. The proposed architecture, called ReSeg, is based on the recently introduced ReNet model for image classification. We modify and extend it to perform the more challenging task of semantic segmentation. Each ReNet layer is composed of four RNN that sweep the image horizontally and vertically in both directions, encoding patches or activations, and providing relevant global information. Moreover, ReNet layers are stacked on top of pre-trained convolutional layers, benefiting from generic local features. Upsampling layers follow ReNet layers to recover the original image resolution in the final predictions. The proposed ReSeg architecture is efficient, flexible and suitable for a variety of semantic segmentation tasks. We evaluate ReSeg on several widely-used semantic segmentation datasets: Weizmann Horse, Oxford Flower, and CamVid; achieving state-of-the-art performance. Results show that ReSeg can act as a suitable architecture for semantic segmentation tasks, and may have further applications in other structured prediction problems. The source code and model hyperparameters are available on https://github.com/fvisin/reseg.
LSTM-CF
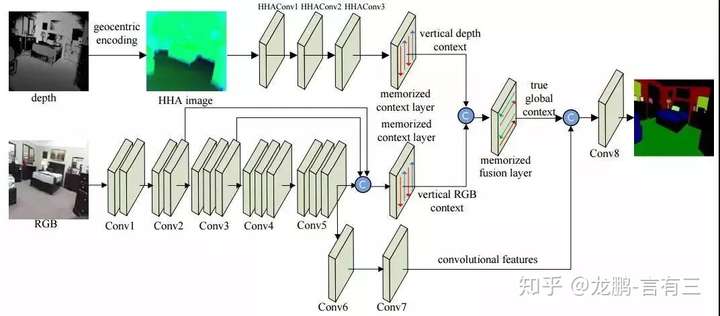
LSTM-CF: Unifying Context Modeling and Fusion with LSTMs for RGB-D Scene Labeling
Semantic labeling of RGB-D scenes is crucial to many intelligent applications including perceptual robotics. It generates pixelwise and fine-grained label maps from simultaneously sensed photometric (RGB) and depth channels. This paper addresses this problem by i) developing a novel Long Short-Term Memorized Context Fusion (LSTM-CF) Model that captures and fuses contextual information from multiple channels of photometric and depth data, and ii) incorporating this model into deep convolutional neural networks (CNNs) for end-to-end training. Specifically, contexts in photometric and depth channels are, respectively, captured by stacking several convolutional layers and a long short-term memory layer; the memory layer encodes both short-range and long-range spatial dependencies in an image along the vertical direction. Another long short-term memorized fusion layer is set up to integrate the contexts along the vertical direction from different channels, and perform bi-directional propagation of the fused vertical contexts along the horizontal direction to obtain true 2D global contexts. At last, the fused contextual representation is concatenated with the convolutional features extracted from the photometric channels in order to improve the accuracy of fine-scale semantic labeling. Our proposed model has set a new state of the art, i.e., 48.1% and 49.4% average class accuracy over 37 categories (2.2% and 5.4% improvement) on the large-scale SUNRGBD dataset and the NYUDv2dataset, respectively.
DeepMask
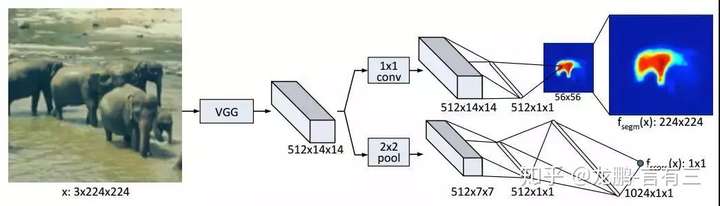
Learning to Segment Object Candidates
Recent object detection systems rely on two critical steps: (1) a set of object proposals is predicted as efficiently as possible, and (2) this set of candidate proposals is then passed to an object classifier. Such approaches have been shown they can be fast, while achieving the state of the art in detection performance. In this paper, we propose a new way to generate object proposals, introducing an approach based on a discriminative convolutional network. Our model is trained jointly with two objectives: given an image patch, the first part of the system outputs a class-agnostic segmentation mask, while the second part of the system outputs the likelihood of the patch being centered on a full object. At test time, the model is efficiently applied on the whole test image and generates a set of segmentation masks, each of them being assigned with a corresponding object likelihood score. We show that our model yields significant improvements over state-of-the-art object proposal algorithms. In particular, compared to previous approaches, our model obtains substantially higher object recall using fewer proposals. We also show that our model is able to generalize to unseen categories it has not seen during training. Unlike all previous approaches for generating object masks, we do not rely on edges, superpixels, or any other form of low-level segmentation.
SharpMask

Learning to Refine Object Segments
Object segmentation requires both object-level information and low-level pixel data. This presents a challenge for feedforward networks: lower layers in convolutional nets capture rich spatial information, while upper layers encode object-level knowledge but are invariant to factors such as pose and appearance. In this work we propose to augment feedforward nets for object segmentation with a novel top-down refinement approach. The resulting bottom-up/top-down architecture is capable of efficiently generating high-fidelity object masks. Similarly to skip connections, our approach leverages features at all layers of the net. Unlike skip connections, our approach does not attempt to output independent predictions at each layer. Instead, we first output a coarse
mask encodingin a feedforward pass, then refine this mask encoding in a top-down pass utilizing features at successively lower layers. The approach is simple, fast, and effective. Building on the recent DeepMask network for generating object proposals, we show accuracy improvements of 10-20% in average recall for various setups. Additionally, by optimizing the overall network architecture, our approach, which we call SharpMask, is 50% faster than the original DeepMask network (under .8s per image).
LEDNet
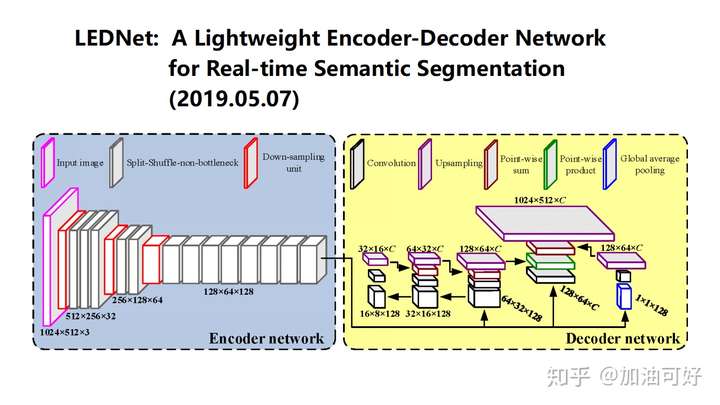
LEDNet: A Lightweight Encoder-Decoder Network for Real-Time Semantic Segmentation The extensive computational burden limits the usage of CNNs in mobile devices for dense estimation tasks. In this paper, we present a lightweight network to address this problem,namely LEDNet, which employs an asymmetric encoder-decoder architecture for the task of real-time semantic segmentation.More specifically, the encoder adopts a ResNet as backbone network, where two new operations, channel split and shuffle, are utilized in each residual block to greatly reduce computation cost while maintaining higher segmentation accuracy. On the other hand, an attention pyramid network (APN) is employed in the decoder to further lighten the entire network complexity. Our model has less than 1M parameters,and is able to run at over 71 FPS in a single GTX 1080Ti GPU. The comprehensive experiments demonstrate that our approach achieves state-of-the-art results in terms of speed and accuracy trade-off on CityScapes dataset.