Machine Learning Translation and the Google Translate Algorithm
[ ]Daniil Korbut has kinderly written an introduction to Machine Learning Translation and the Google Translate Algorithm. I have summarized its content here.
The Problem
Years ago, it was very time consuming to translate the text from an unknown language. Using simple vocabularies with word-for-word translation was hard for two reasons: 1) the reader had to know the grammar rules and 2) needed to keep in mind all language versions while translating the whole sentence.
The old method relies on defining a lot of grammar rules manually. However there are always a lot of exceptions to rules. When we try to capture all these rules, exceptions and exceptions to the exceptions in the program, the quality of translation breaks down.
Solution
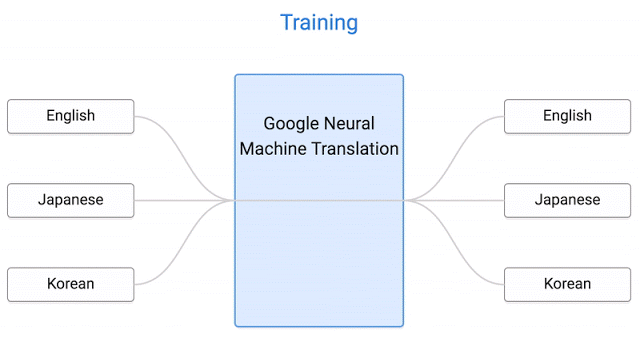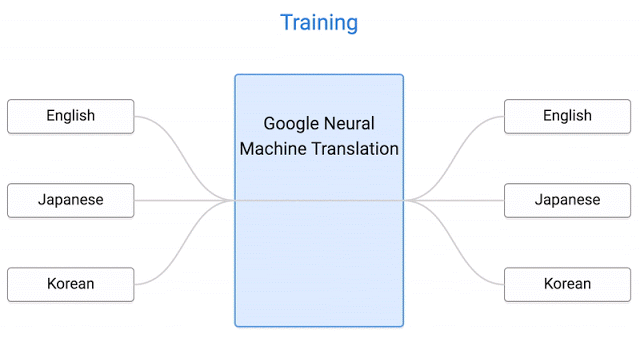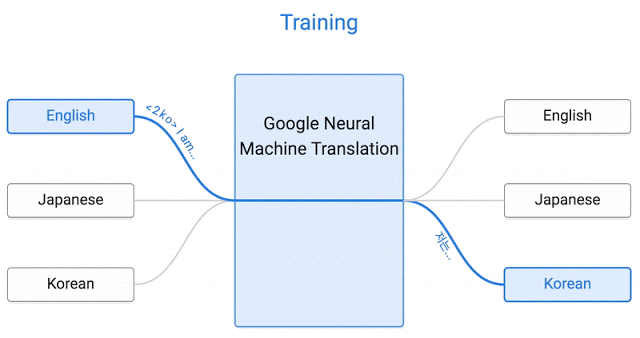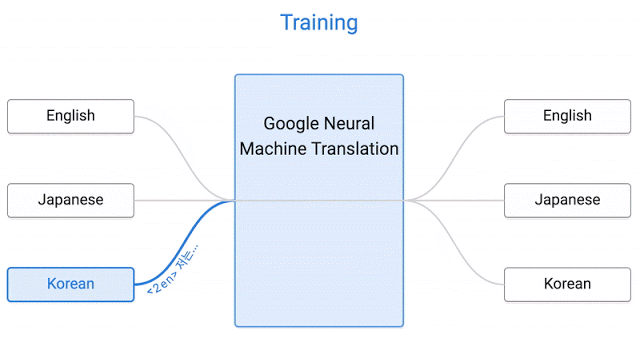
Modern machine translation systems use a different approach: they allocate the rules from text by analyzing a huge set of documents.
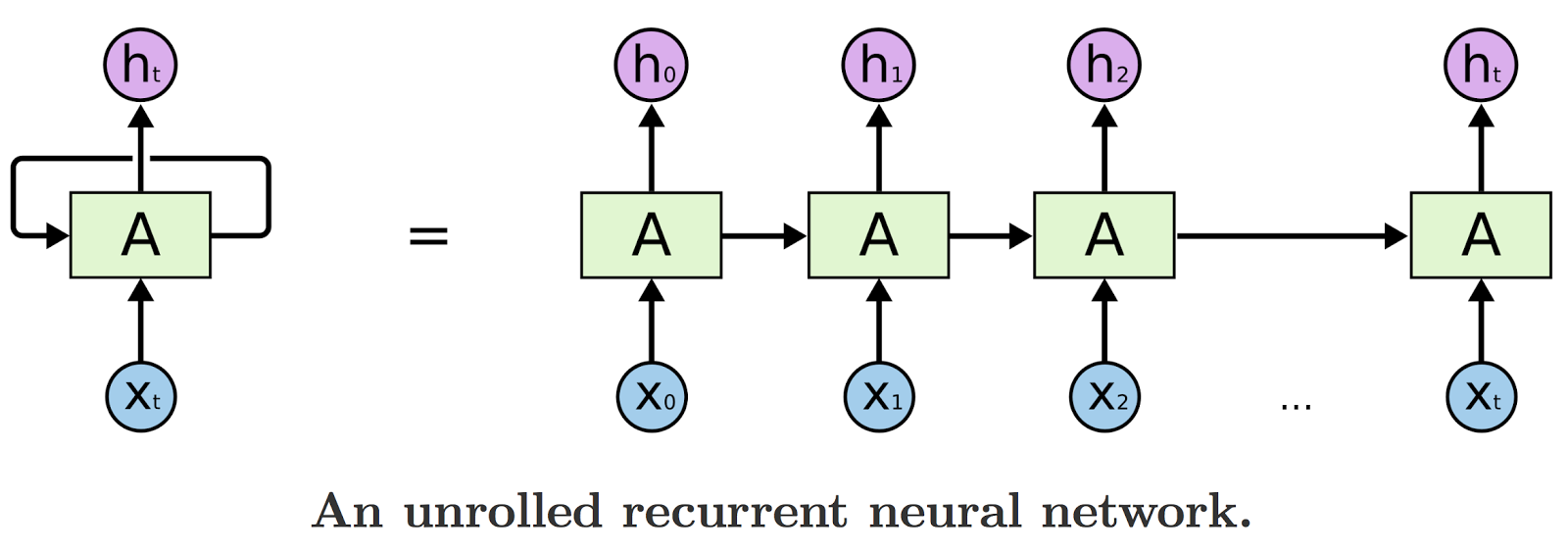
Recurrent Neural Networks
Here is where Long Short-Term Memory networks (LSTMs) come into play, helping us to work with sequences whose length we can’t know a priori. LSTMs are a special kind of recurrent neural network (RNN), capable of learning long-term dependencies. All RNNs look like a chain of repeating modules.
Bidirectional RNNs
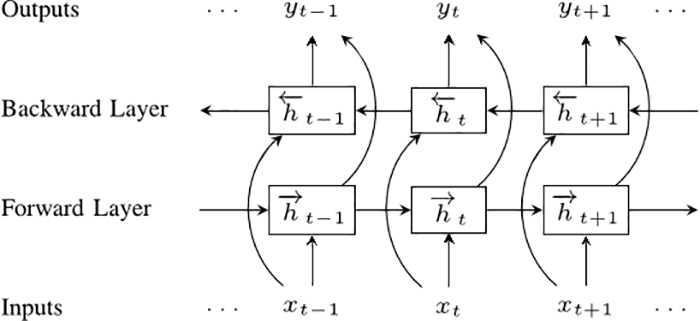
Our next step is bidirectional recurrent neural networks (BRNNs). What a BRNN does, is split the neurons of a regular RNN into two directions. One direction is for positive time, or forward states. The other direction is for negative time, or backward states. The output of these two states are not connected to inputs of the opposite direction states.
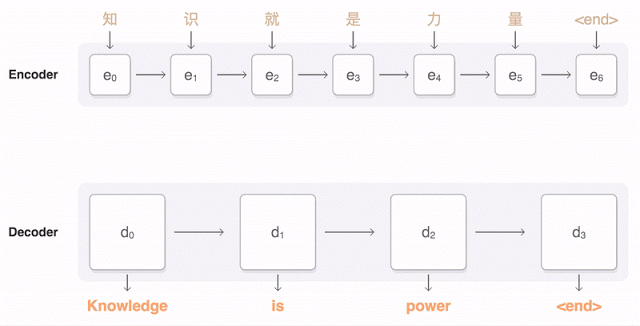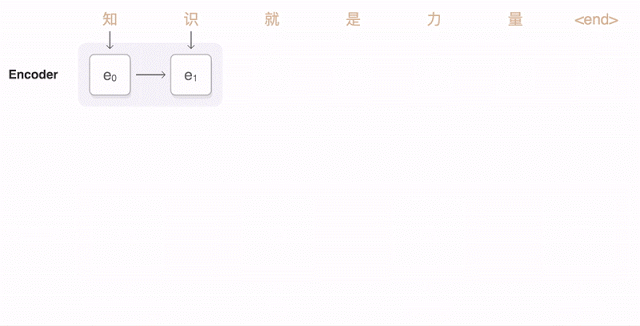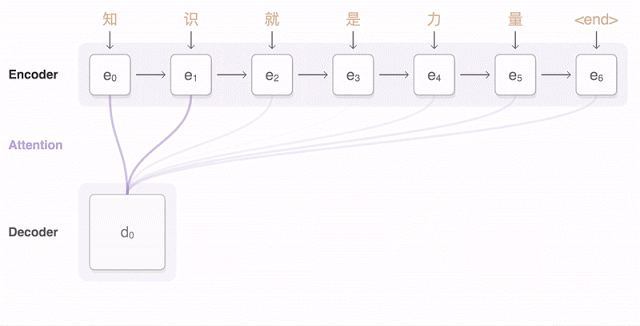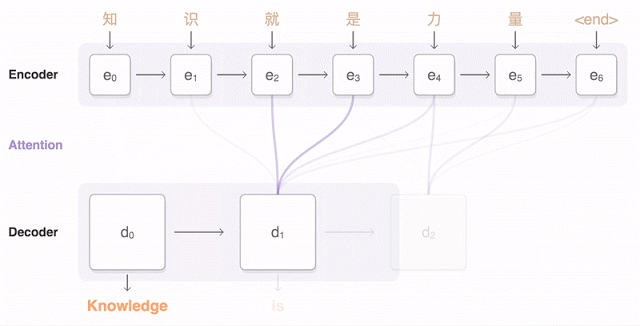
Sequence to sequence
Now we’re ready to move to sequence to sequence models (also called seq2seq). The basic seq2seq model consist of two RNNs: an encoder network that processes the input and a decoder network that generates the output.
Metric
Researchers are using BLEU (bilingual evaluation understudy) to evaluate the performance of the machine translation: