SimVLM Simple Visual Language Model Pretraining with Weak Supervision
[simvlm multimodal prefix-lm masked-region-classification word-patch-alignment contrastive-loss word-region-alignment deep-learning image-text-matching transformer This is my reading note for SimVLM: Simple Visual Language Model Pretraining with Weak Supervision. SimVLM reduces the training complexity by exploiting large-scale weak supervision, and is trained end-to-end with a single prefix language modeling objective
Introduction
In order to capture the alignment between images and text, previous methods have extensively exploited two types of human-labeled datasets from multiple sources, which typically consist of the following steps. Firstly, object detection datasets are used to train a supervised object detector (OD) which allows further extracting region-of-interest (ROI) features from images Next, datasets with aligned image-text pairs are used for MLM pretraining of a fusion model that usually takes as input the concatenation of the extracted ROI features and the paired text (p. 2)
Related Work
Multiple cross-modality loss functions have been proposed as part of the training objectives, for example:
- image-text matching (p. 2)
- masked region classification/feature regression ( (p. 2)
- contrastive loss (p. 3)
- word-region alignment (p. 3)
- word-patch alignment (p. 3)
Our work by contrast, follows a minimalist approach that takes raw image inputs and makes use of only the language modeling loss, without resorting to auxiliary models like faster R-CNN for image region detection (p. 3)
Proposed Method
BACKGROUND
The bidirectional Masked Language Modeling (MLM) has been one of the most popular selfsupervised training objectives for textual representation learning. As demonstrated by BERT (Devlin et al., 2018), it is based on the idea of denoising autoencoder such that the model is trained to recover the corrupted tokens in a document (p. 3)
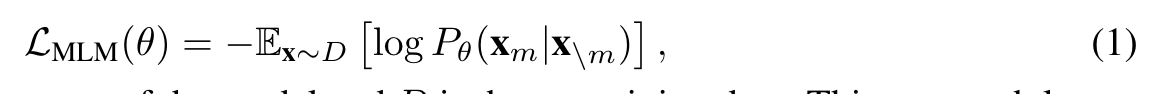
Alternatively, the unidirectional Language Modeling (LM) trains the model to directly maximize the likelihood of the sequence x under the forward autoregressive factorization (p. 3)
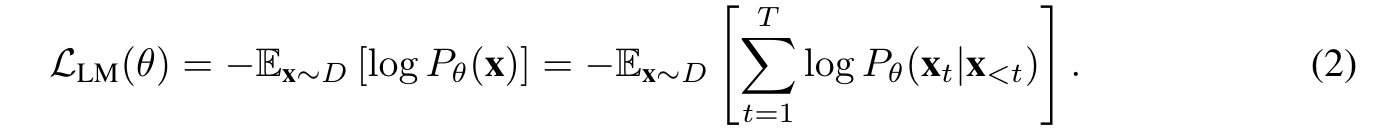
PROPOSED OBJECTIVE: PREFIX LANGUAGE MODELING
PrefixLM differs from the standard LM such that it enables bi-directional attention on the prefix sequence (e.g. x<Tp in Eq. (3)), and only conducts autoregressive factorization on the remaining tokens (p. 4)
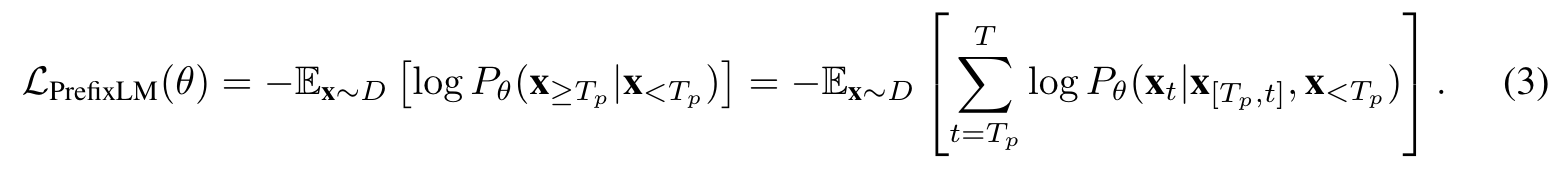
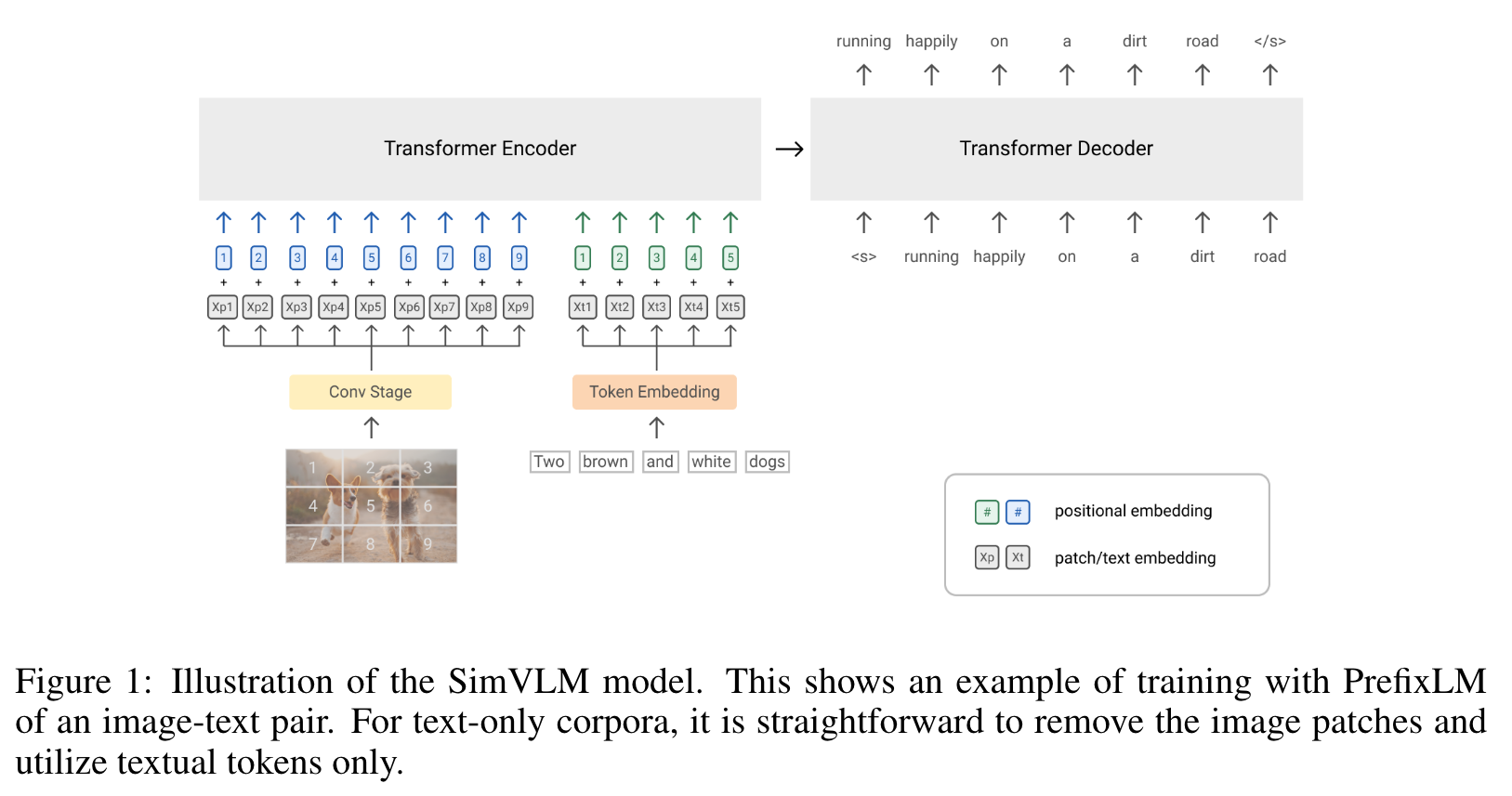
Intuitively, images can be considered as prefix for their textual descriptions as they often appear before text in a web document. Therefore, for a given image-text pair, we prepend image feature sequence of length Ti to the text sequence, and enforce the model to sample a prefix of length Tp ≥ Ti to calculate LM loss on text data only (p. 4)
EXPERIMENTS
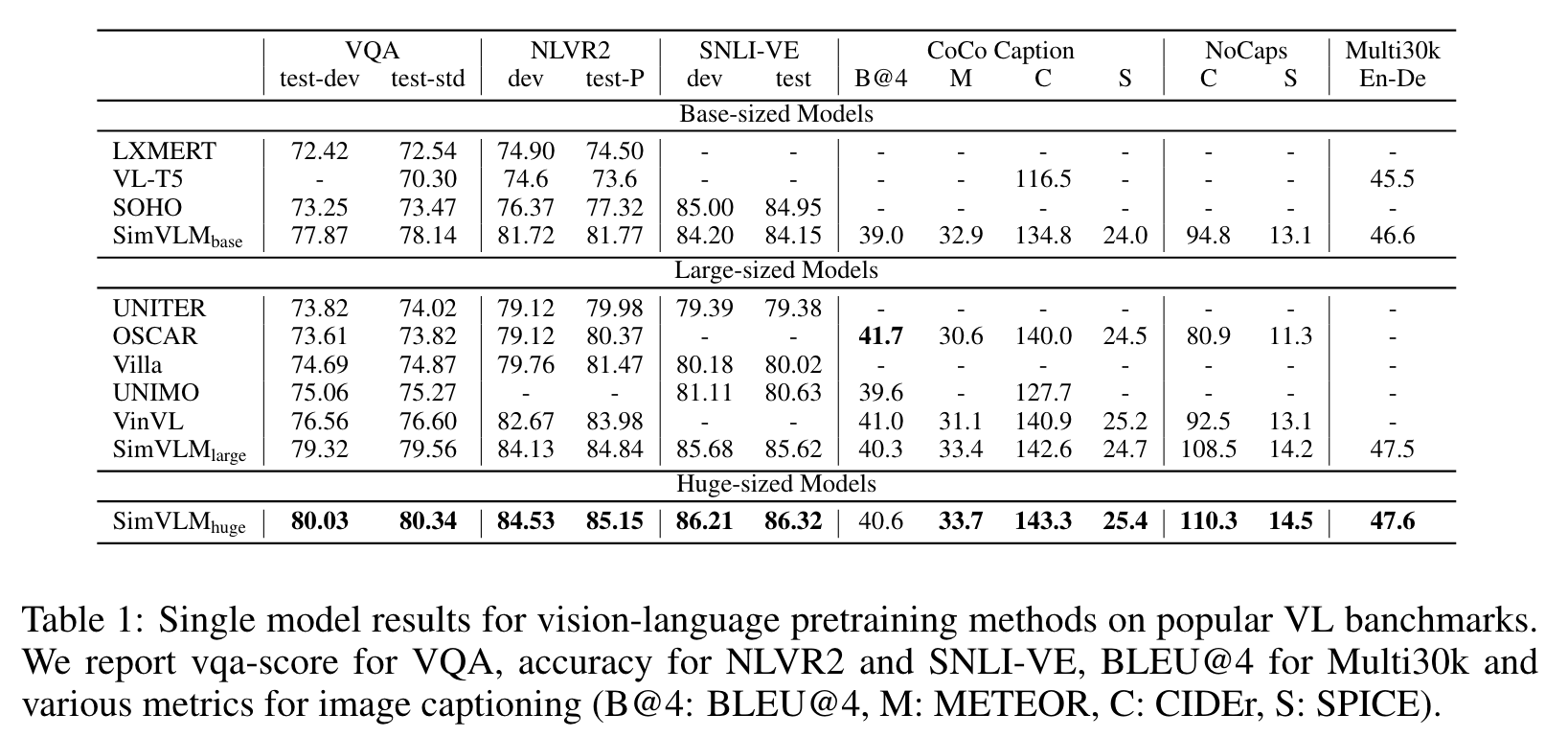
Ablation Study
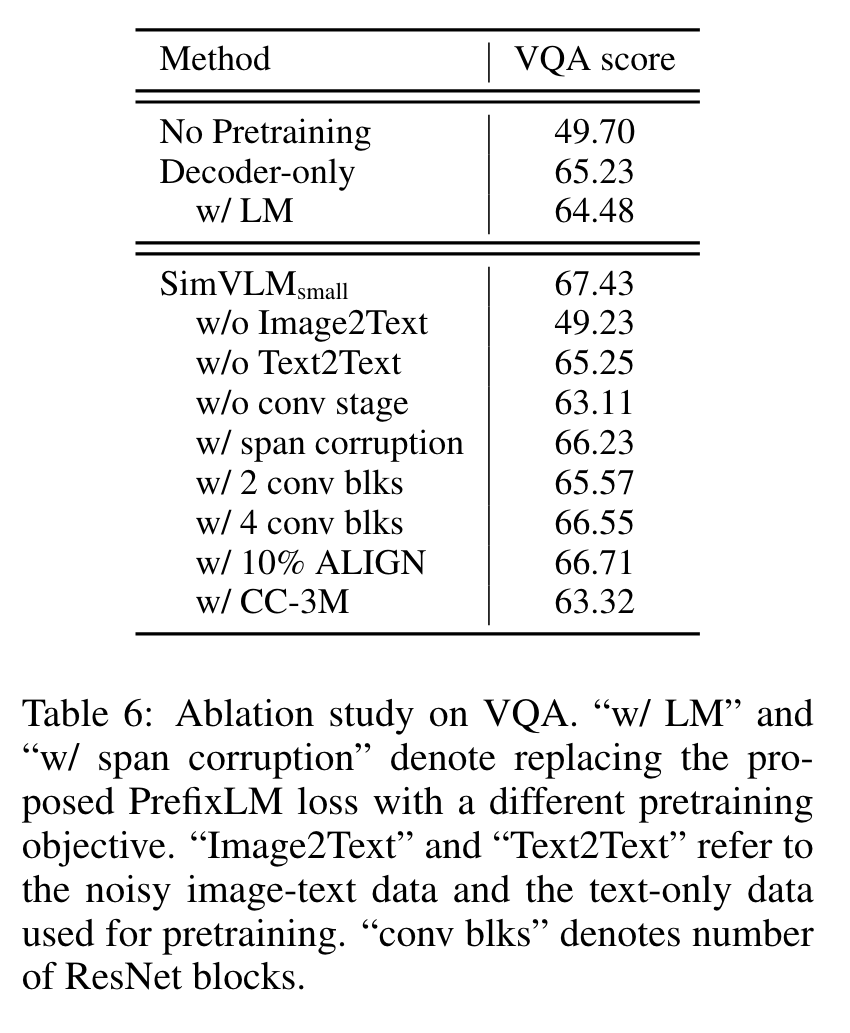
First, we compare encoder-decoder models with decoder-only models of comparable model size, and find that decoder-only model performs significantly worse on VQA. This suggests the inductive bias of separating bidirectional encoding from unidirectional decoding is beneficial for joint VL representation learning. Next, we study the effectiveness of pretraining objectives and results show that the PrefixLM objective outperforms both span corruption (Raffel et al., 2019) and naive LM, illustrating the importance of using a unified objective formulation for both image-text and text-only data. Moreover, we ablate the contribution of datasets. While weakly aligned image-text data are required for bridging the gap between visual and textual representations, text-only corpora also improves the model quality. This is probably because textual signals are extremely noisy in the former and thus the model relies on the later to acquire better language understanding. In addition, we experimented with 10% ALIGN and CC-3M (Sharma et al., 2018) datasets, and confirms the importance of data scaling. We then study the effect of the convolution stage and find it critical for VL performance. Following Dai et al. (2021), we experiment with using either the first 2/3/4 ResNet Conv blocks, and empirically observe that the 3 conv block setup works best. This indicates that image and text have different levels of representation granularity and thus utilizing contextualized patches is beneficial. (p. 9)
