Single Object Tracking
[tracking reinforcement-learning graph deep-learning single ![]()
The aim of object track- ing is to localize an object in continuous video frames given an initial annotation in the first frame. In the setting of most existing work, it is usually assumed that the object of inter- est is always in the image scene, which means that there is no need to handle camera control during tracking. Namely, the object is tracked in a passive fashion. Active object tracking additionally considers camera control compared against traditional object tracking.
Online tracking by learning discriminative saliency map with convolutional neural network
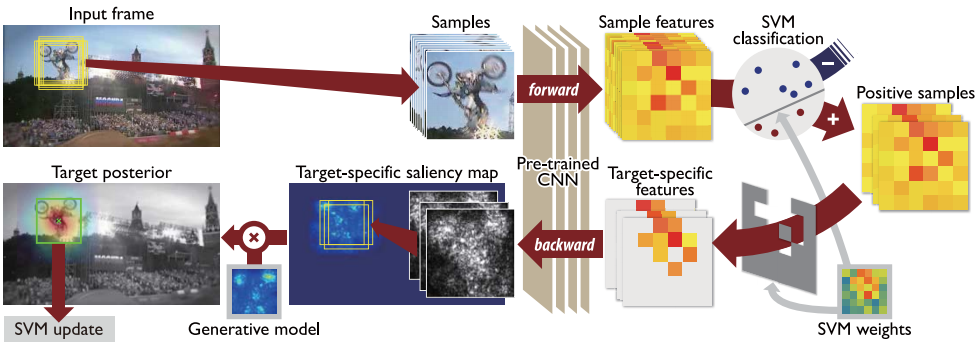
Given a CNN pre-trained (R-CNN) on a large-scale image repository in offline, our algorithm takes outputs from hidden layers of the network as feature descriptors. The features are used to learn discriminative target appearance models using an online Support Vector Machine (SVM). To handle the low spatial resolution due to pooling operation, we construct target-specific saliency map by back-projecting CNN features with guidance of the SVM, and obtain the final tracking result in each frame based on the appearance model generatively constructed with the saliency map.
The class-specific saliency map of a given image I is the gradient of class score Sc(I) with respect to the image, which is constructed by back-propagation.
Deeptrack: Learning discrimina- tive feature representations by convolutional neural networks for visual tracking

In this work, a single Convolutional Neural Network (CNN, consists of two convolutional layers and two fully-connected layers.) for learning effective feature representations of the target object is learned in a purely online manner. To achieve this several efforts are made:
- a novel truncated structural loss function that maintains as many training samples as possible and reduces the risk of tracking error accumulation.
- structural loss penalizes the samples according to the spatial distance to the motion estimated target
- truncated loss ignore the samples whose error are too small
- enhance the ordinary Stochastic Gradient Descent approach in CNN training with a robust sample selection mechanism. The sampling mechanism randomly generates positive samples for longer temporal span and negative samples for shorter temporal span, which are generated by taking the temporal relations and label noise into account.
- a lazy yet effective updating (e.g., updating only when significant appearances changes are found) scheme is designed for CNN training.
Video tracking using learned hierarchical features
we offline learn features robust to diverse motion patterns from auxiliary video sequences. The hierarchical features are learned via a two- layer convolutional neural network. Embedding the temporal slowness constraint in the stacked architecture makes the learned features robust to complicated motion transformations, which is important for visual object tracking.
Learning a deep compact image representation for visual tracking

By using auxiliary natural images, we train a stacked de- noising autoencoder offline to learn generic image features that are more robust against variations. Online tracking involves a classification neural network which is constructed from the encoder part of the trained autoencoder as a feature extractor and an additional classification layer. Both the feature extractor and the classifier can be further tuned to adapt to appearance changes of the moving object.
Visual tracking with fully convolutional networks
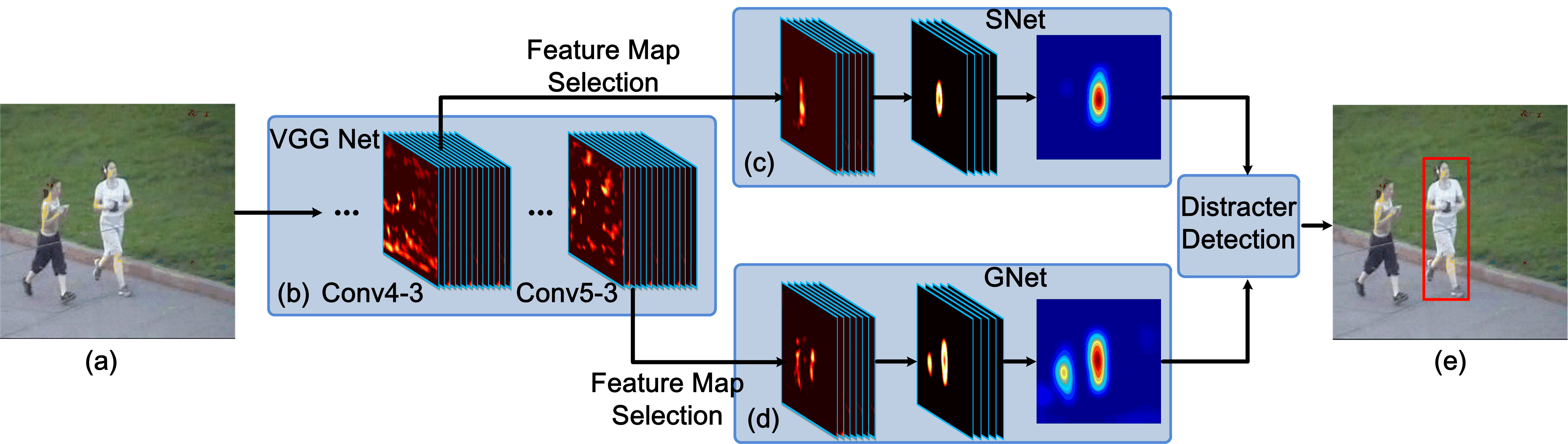
It is found that convolutional layers in different levels characterize the target from different perspectives. A top layer encodes more semantic features and serves as a category detector, while a lower layer carries more discriminative information and can better separate the target from distracters with similar appearance. Both layers are jointly used with a switch mechanism during tracking. It is also found that for a tracking target, only a subset of neurons are relevant. A feature map selection method is developed to remove noisy and irrelevant feature maps, which can reduce computation redundancy and improve tracking accuracy.
Hierarchical convolutional features for visual tracking

Based on the success of deep convolution neural network on image classification tasks, the output of CNN should be semantically represented the objects and robust to variations. However, the objective of visual tracking is to locate targets precisely rather than to infer their semantic classes. Using only the features from the last layer is thus not the optimal representation for targets. Thus the hierarchies of convolutional layers (VGG19 pretrained on ImageNet and fully connected layers removed) is interpreted as a nonlinear counterpart of an image pyramid representation and exploit these multiple levels of abstraction for visual tracking.
Given an image, we first crop the search window centered at the estimated position in the previous frame. We use the third, fourth and fifth convolu- tional layers as our target representations. Each layer indexed by i is then convolved with the learned linear correlation filter w(i) to generate a response map, whose location of the maximum value indicates the estimated target position. We search the multi-level response maps to infer the target location in a coarse-to-fine fashion. An optimal filter on l-th layer can be updated by mini- mizing the output error over all tracked results so far
Sequentially training convolutional networks for visual tracking

We regard a CNN as an ensemble with each channel of the output feature map as an individual base learner. To achieve the best ensemble online, all the base learners are sequentially sampled into the ensemble via important sampling. To further improve the robustness of each base learner, we propose to train the convolutional layers with random binary masks, which serves as a regularization to enforce each base learner to focus on different input features.
Denote the pre-trained CNN as CNN-E, which takes the RGB image as input and outputs a convolutional feature map X. An online adapted CNN, named as CNN-A is randomly initialized and consists of two convolutional layers interleaved with an ReLU layer as the nonlinear activation unit. It takes the feature map X as input and generates the final feature map.
End-to-end Active Object Tracking via Reinforcement Learning

A ConvNet-LSTM (two convolution layers followed by a fully connected layer and LSTM) function approximator is adopted, which takes as input only visual observations (i.e., frame sequences) and directly outputs camera motions (e.g., move forward, turn left, etc.). The tracker, regarded as an agent, is trained with the A3C algorithm, where we harness an environment augmentation technique and a customized rewarding function to encourage robust object tracking.
Visual Tracking by Reinforced Decision Making

This paper formulates the tracking problem as an identification problem, where query frame is compared with multiple apperarances models via a Siamese network to generate a prediction map. The prediction map (state) is then passed to policy networks to select the best prediction map (action).
The tracking algorithm utilizes this strategy to choose the best template for tracking a given frame. The template selection strategy is self-learned by utilizing a simple policy gradient method on numerous training episodes randomly generated from a tracking benchmark dataset.
Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning

The proposed ADNet learns the policy that selects the optimal actions to track the target from the state of its current position. In the ADnet, the policy net- work is designed with a convolutional neural network. The deep network to control actions is pre-trained using various training sequences and fine-tuned during tracking for online adaptation to target and background changes.
The ADNet is trained by a combined learning algorithm of su- pervised learning (SL) and reinforcement learning (RL) to train the ADNet.
- In the SL stage, we train our network to select actions to track the position of the target using samples extracted from training videos. In this step, the network learns to track general objects without sequential information.
- In the RL stage, the pre-trained network in the SL stage is used as an initial network. We perform RL via tracking simulation using training sequences composed of sampled states, actions, and rewards.