Tag: clip4clip
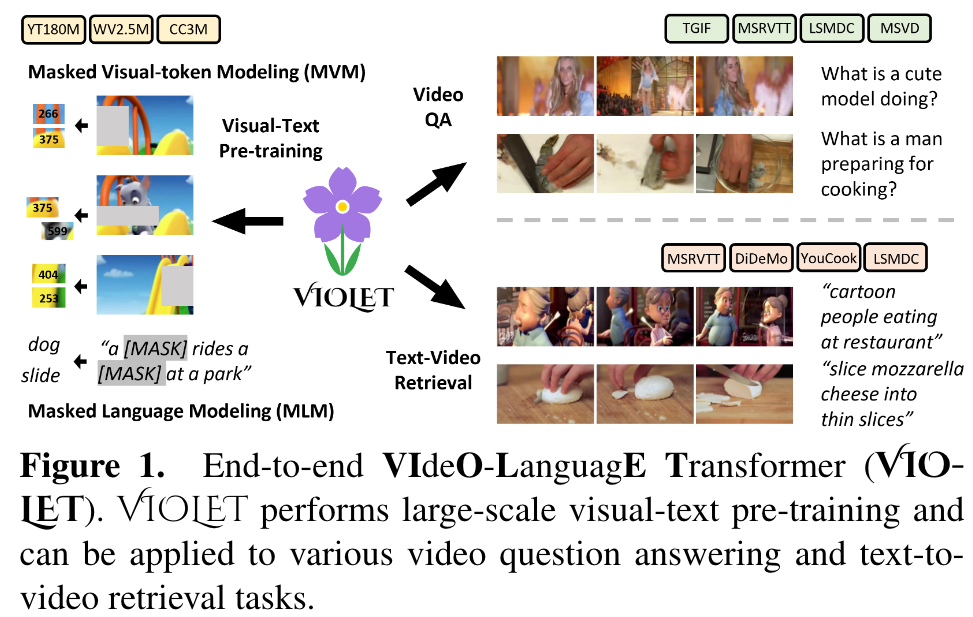
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- X-CLIP End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval (04 Jul 2023)
This is my reading note for X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. This paper proposes a method on extending clip to video data. it mostly studied how to aggregate the similarity score from the frame level to video level.