Transformer in Computer Vision
[deep-learning transformer Transformer architecture has achieved state-of-the-art results in many NLP (Natural Language Processing) tasks. Though CNN has been the domiant models for CV tasks, using Transformers for vision tasks became a new research direction for the sake of reducing architecture complexity, and exploring scalability and training efficiency.
Here I will introduce the following representative papers:
- DETR: End-to-End Object Detection with Transformers
- ViT: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- Image GPT: Generative Pretraining from Pixels
ViT
Vision Transformer (ViT) is a pure transformer architecture (no CNN is required) applied directly to a sequence of image patches for classification tasks. The order of patches in sequence capture the spatial information of those patches, similar to words in sentences.
It also outperforms the state-of-the-art convolutional networks on many image classification tasks while requiring substantially fewer computational resources (at least 4 times fewer than SOTA CNN) to pre-train.)

DETR
DETR still uses CNN for feature extration and then use transformer to capture context of objects (boxes) in images. Here is the an visual illustration of DETR:
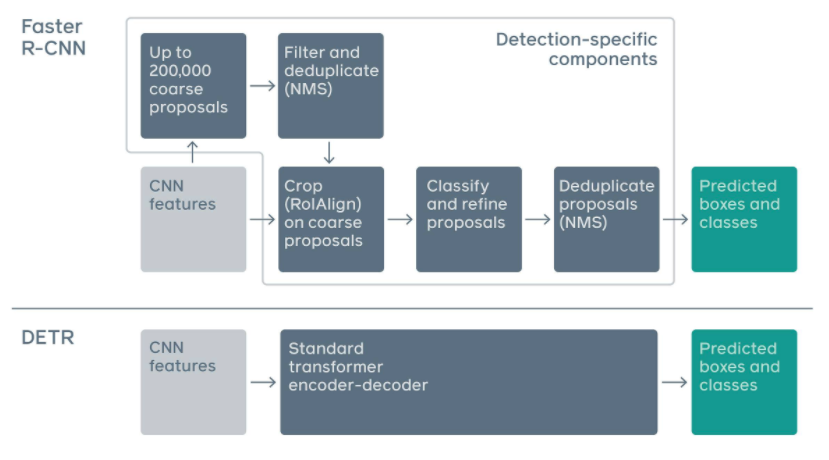
Compared with previous object detection model, e.g., MaskRCNN, YOLO, it doesn’t need to have anchor and nonmaximal suppression. Besides DETR could be directly applied for panoptic segmentation (joint semantic segmentation and instance segmentation).
Image GPT
Image GPT utilizes the GPT-2 like transformer to impaint images, which is trained on pixel sequence.

Summary
Transformer has shown promissing results in CV tasks, especially in object detection and image segmentation. Compare with CNN, transformer could capture the context information of different objects (regions) better due to attention mechansim, while CNN is limited convolution kernel size and down sample ratio.