VAST A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset
[deep-learning multimodal audio vast value valor caption subtitle asr merlot avnet univl comvt This is my reading note for VAST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset. This paper proposes a method and a dataset for multimodal content understanding for video (vision, audio, subtitle and text). The major contribution is it proposes to use LLM to fuse different sources of text data (caption, subtitle, ASR text).
Introduction
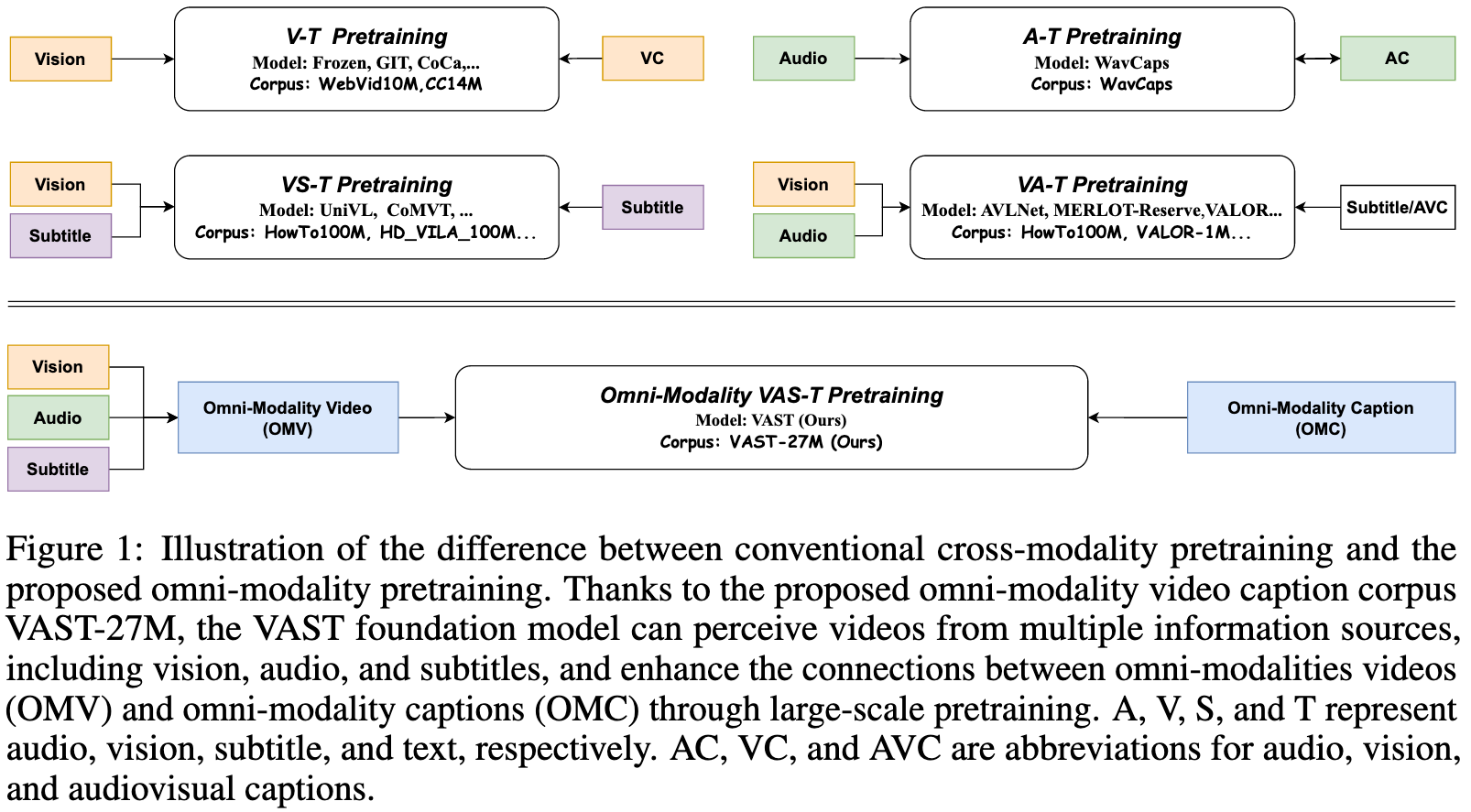
In this paper, we resort to establish connections between multi-modality video tracks, including Vision, Audio, and Subtitle, and Text by exploring an automatically generated large-scale omni-modality video caption dataset called VAST-27M. (p. 1)
However, we contend that current pre-training models are far from perfect, as most of them are restricted to establishing connections solely between the text and visual content of videos, without incorporating other modality tracks such as audio and subtitles. Specifically, environmental audio can provide additional contexts overlapping with the visual information to reduce ambiguity and increase the prediction confidence of models, or complement the visual information to supply more multi-modal cues. (p. 2)
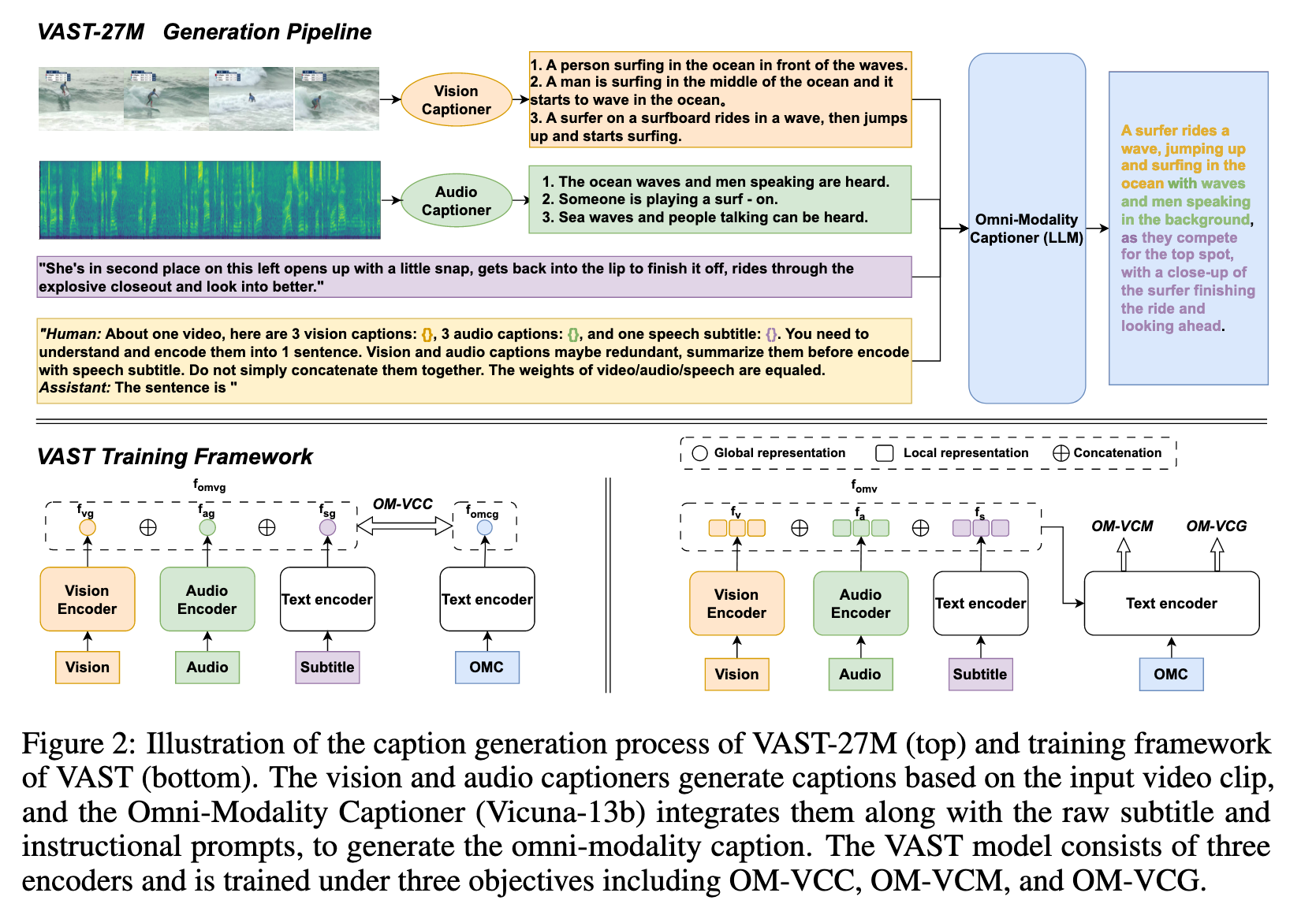
In the second stage, we employ Vicuna-13b [8], an off-the-shelf Large Language Model (LLM), as a zero-shot omni-modality captioner. We feed the LLM with the generated single-modality captions, subtitles, and instructional prompts to encourage LLM to integrate different modality information and summarize them into a single long sentence, forming an omni-modality caption. (p. 2)
Related Work
Cross-Modality Pretraining Corpus

Multi-Modality Learning
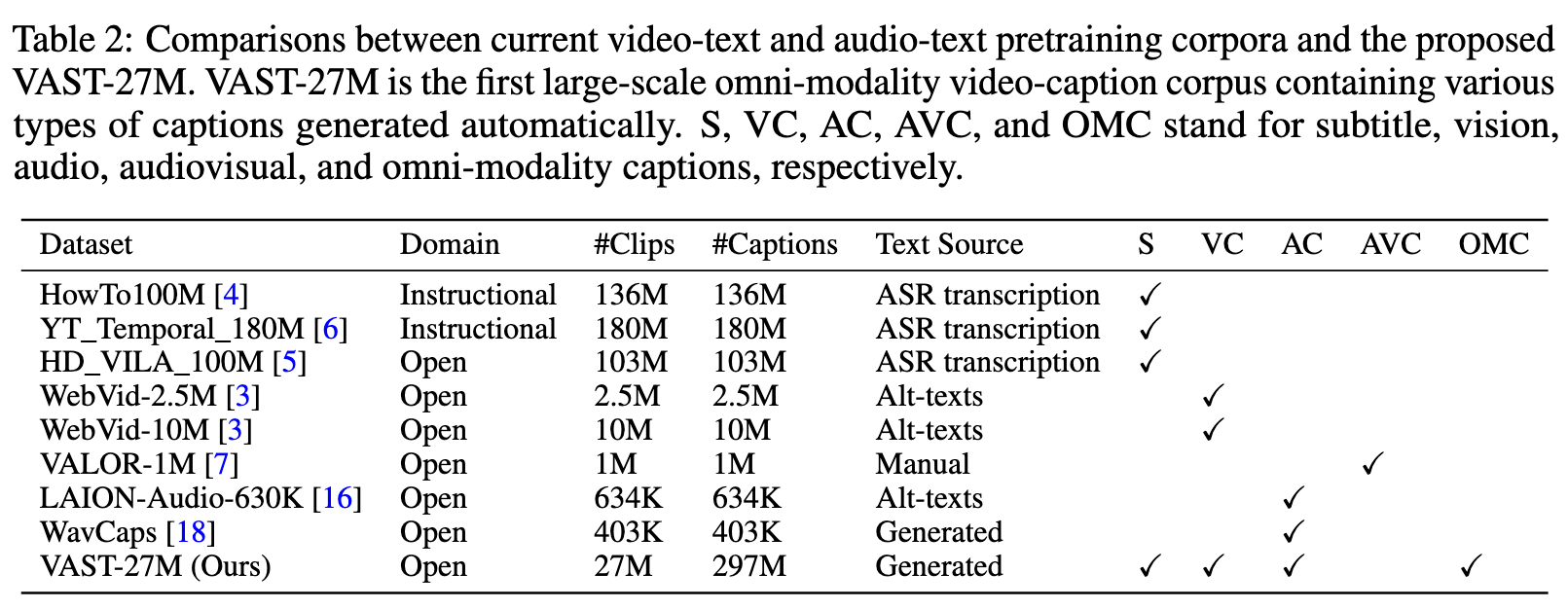
- In the context of video-text pretraining, there are works that jointly model subtitles or audio together with vision and text. Notable examples of incorporating subtitles include UniVL [23], CoMVT [24], and VALUE [20]. However, the subtitle-text correlations established in these models are implicit and weak, achieved through masked prediction [23] or next utterance prediction [24] that uses raw subtitles as prediction targets, rather than abstract text. This approach introduces inconsistency between the pretraining and fine-tuning stages. In contrast, VAST fully harnesses the generalization capabilities of Large Language Models to extract the most crucial information from subtitles into language descriptions.
- On the other hand, notable examples of incorporating audio include AVLNet [25], MERLOT Reserve [26], i-Code [27], and VALOR [7]. However, AVLNet, MERLOT Reserve, and i-Code focus on learning audio-subtitle relations rather than audio-text, limiting their generalization to tasks such as text-to-audio retrieval and audio captioning. While VALOR jointly models audio, vision, and text, it primarily targets perceiving environmental sounds and pays less attention to human speech. (p. 4)
Dataset
Vision Captioner Training
commence by training a vision caption model on large-scale image-text corpora, including CC4M, CC12M, and a randomly selected set of 100M image-text pairs from LAION-400M [29]. Subsequently, we fine-tune the model on a combination of manually labeled image and video caption datasets, such as MSCOCO [30], VATEX [31], MSRVTT [32], and MSVD [33]. (p. 4)
Audio Captioner Training
For the audio captioning task, we train a dedicated audio caption model using a combination of large-scale audio-text corpora, namely VALOR-1M and WavCaps datasets. (p. 4)
Caption Generation
For each video clip of VAST-27M, we employ the trained vision and audio captioners to generate 5 captions each, using a Top-K sampling approach with K=10. Subsequently, we utilize the off-the-shelf Vicuna-13b [8] model as the omni-modality captioner. For each video clip, we randomly select 3 vision captions and 3 audio captions, and feed them, along with the raw subtitle and designed instructional prompts, into the LLM. (p. 5)
Approach
Basic Framework
As shown in Figure 2, VAST employs a fully end-to-end Transformer architecture, comprising a vision encoder (ViT [35]), an audio encoder (BEATs [36]), and a text encoder (BERT [2]). The text encoder is responsible for encoding single-modality captions or subtitles, as well as performing multi-modal encoding/decoding through cross-attention layers. (p. 5)
Pretraining Objectives
- Omni-Modality Video-Caption Contrastive Loss (OM-VCC). The contrastive loss is employed to regularize the feature distance between omni-modality video (OMV) and caption (OMC). (p. 6)
- Omni-Modality Video-Caption Matching Loss (OM-VCM). This loss encourages the model to infer whether a pair of OMV and OMC is matched or not. (p. 6)
- Omni-Modality Video Caption Generation Loss (OM-VCG). This loss employs conditional causal masked language modeling to enhance the model’s ability to generate omni-modality captions. Specifically, 60% of the tokens in OMC are masked at the input of the text encoder. (p. 6)
we uniformly model the relations of V-T, A-T, VA-T, VS-T, and VAS-T (previously introduced as LOM). (p. 6)
Experiments
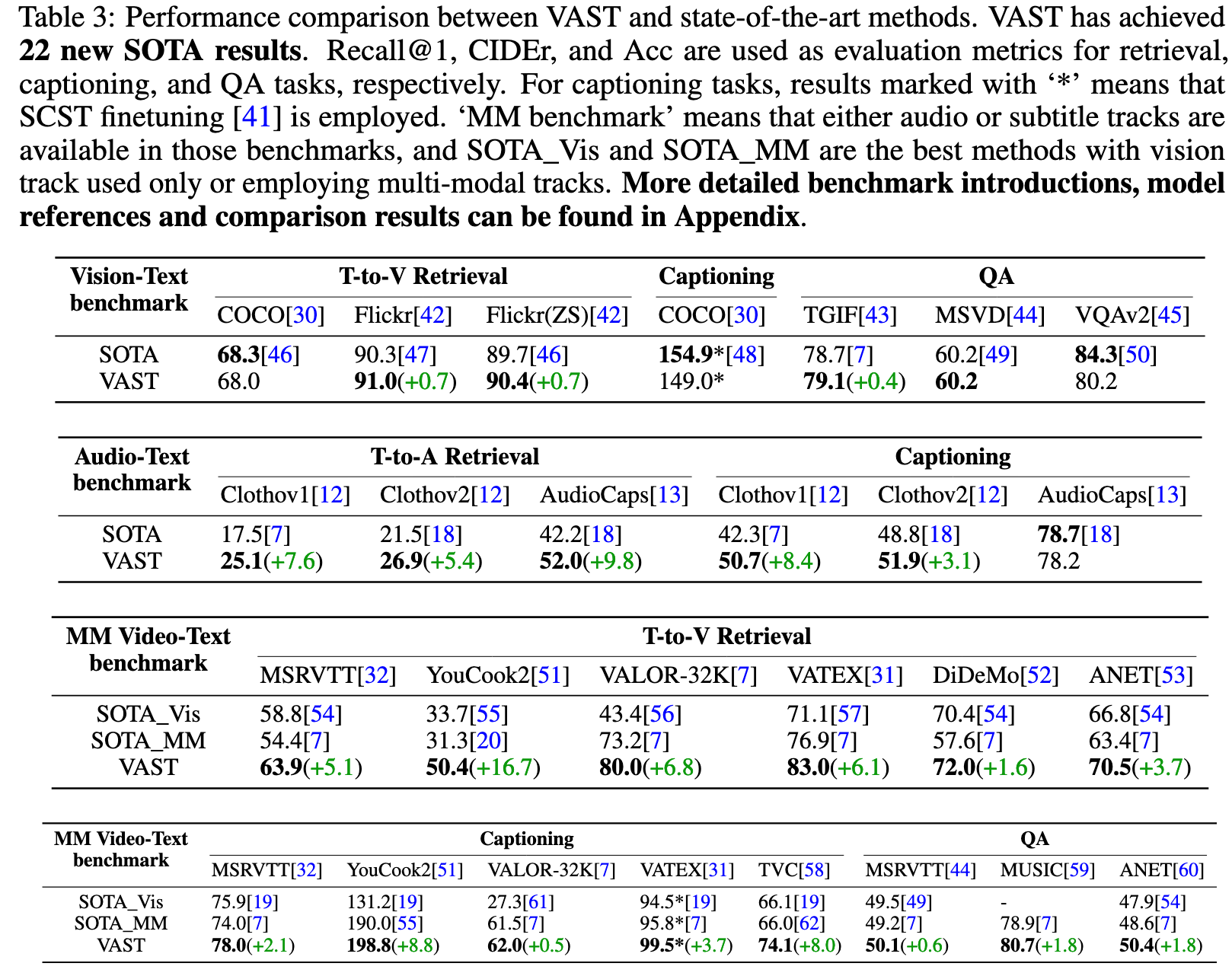
Regarding the adaptation to downstream tasks, for retrieval tasks, all candidates are ranked using VCC, and then the Top-50 candidates are reranked using VCM. For captioning tasks, beam search with a beam size of 3 is employed. For QA tasks, they are formulated as open-ended generative problems, where questions serve as prefixes, and answers are predicted without any constraints. (p. 7)
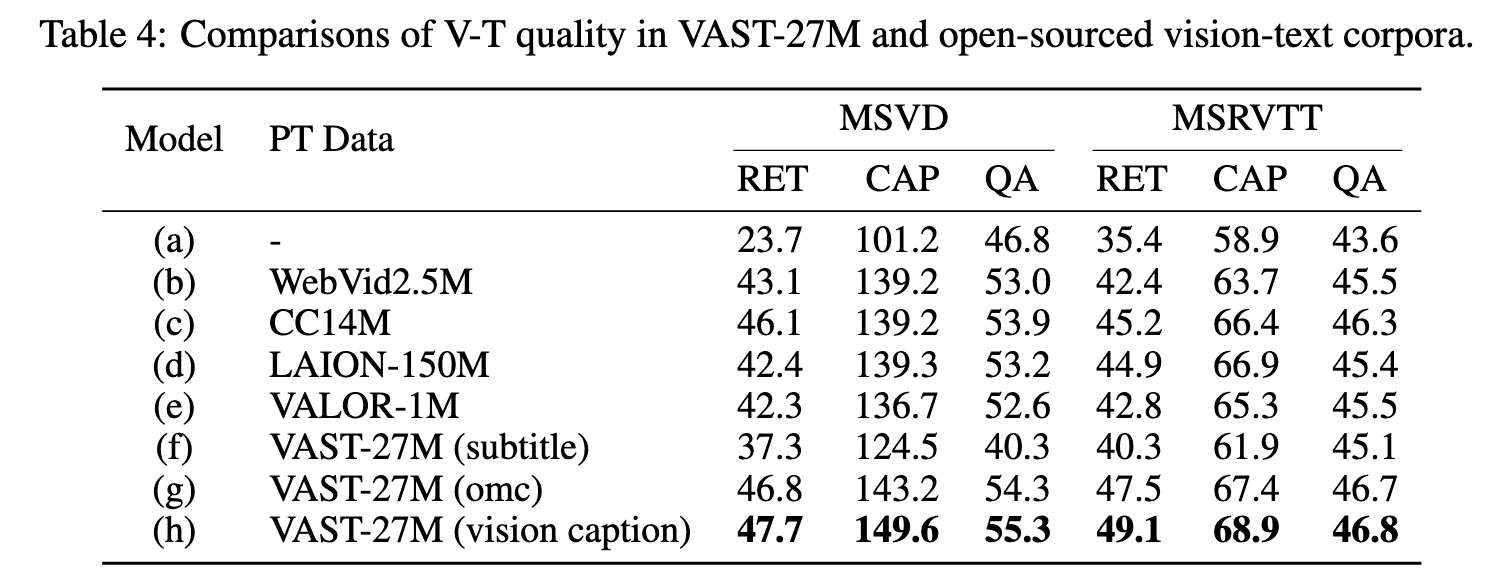
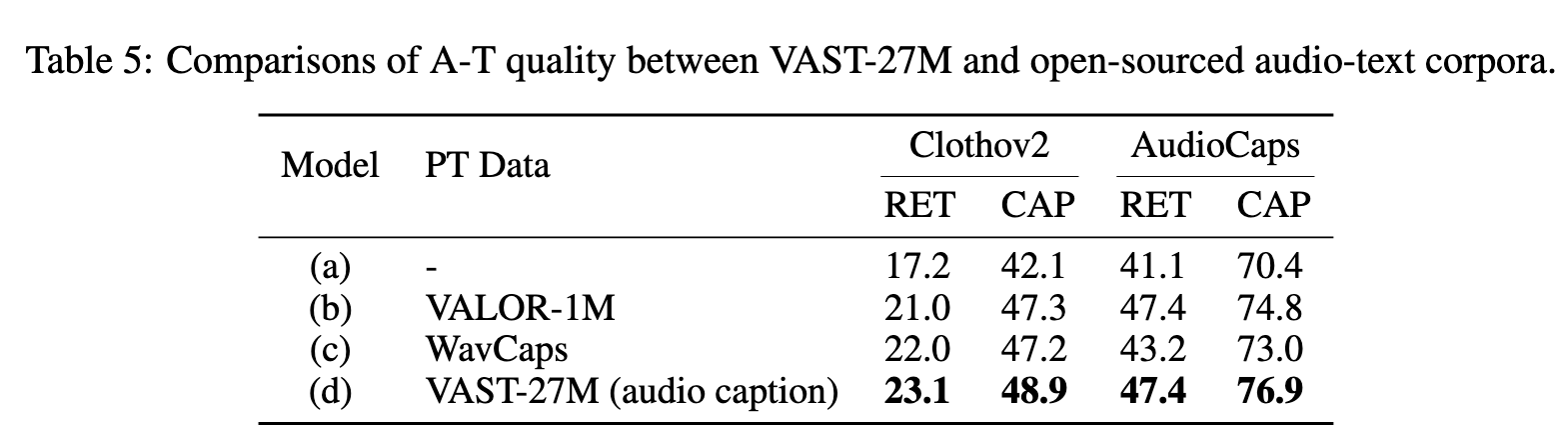
We achieve this by training models on these corpora and fine-tuning them on different types of downstream tasks, including video retrieval (RET), captioning (CAP), and question answering (QA). (p. 8)
Model trained on VAST-27M (g) outperforms other corpora but is still inferior to model (h), as the multi-modal captions introduce noise when only vision contents are fed into the model. (p. 8)
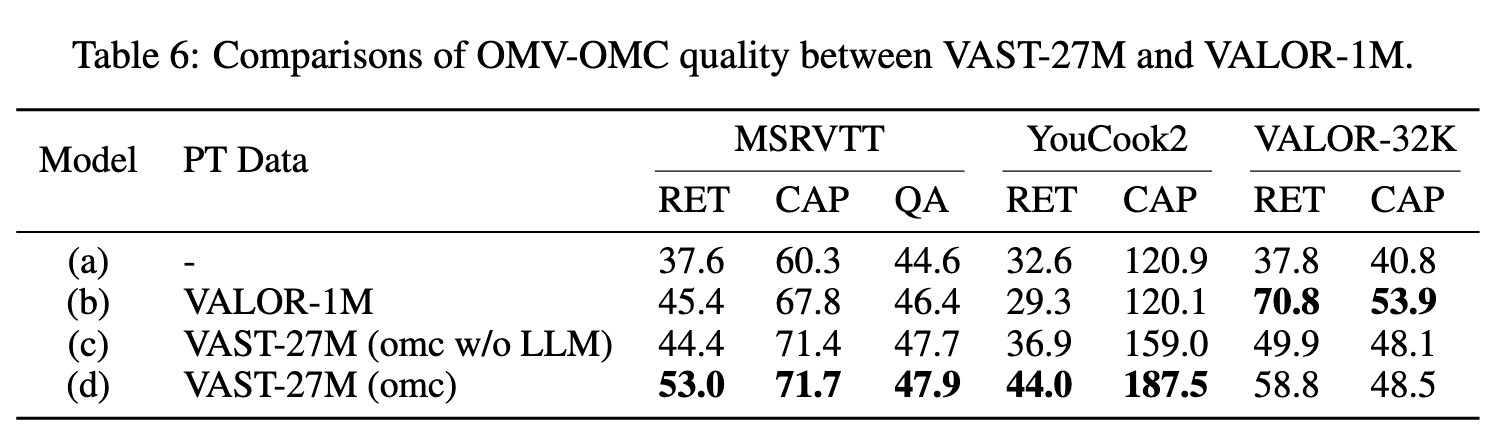
Ablation
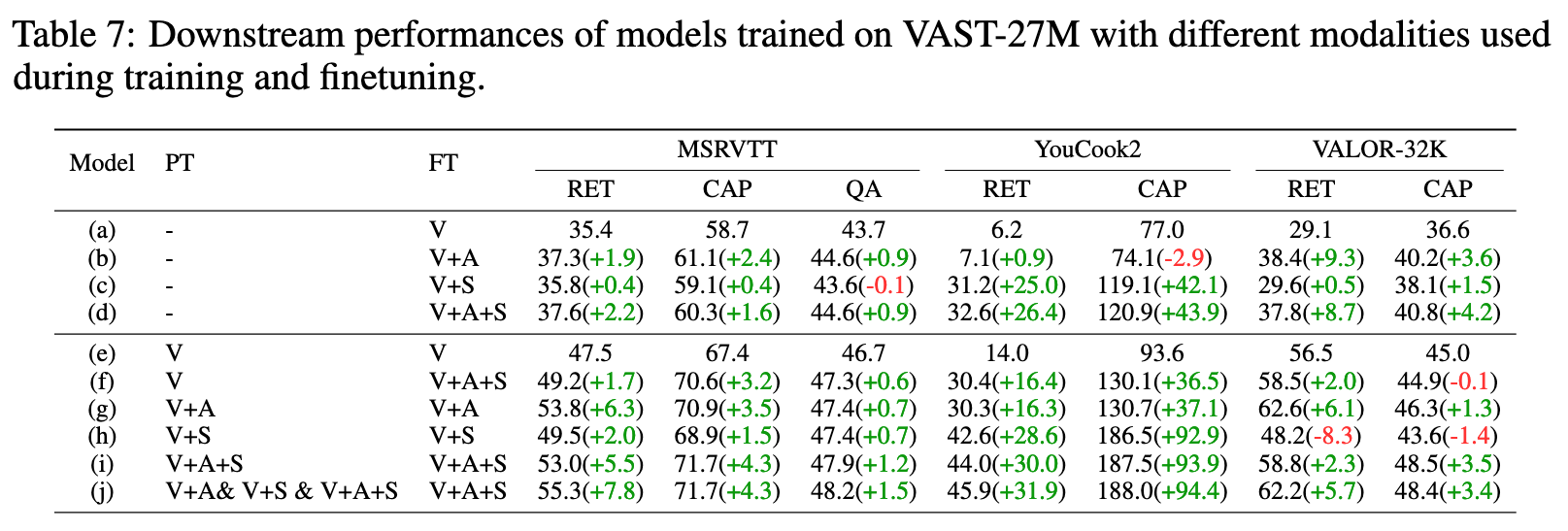
As an additional experiment, we train model (c) on VAST-27M but replace the omni-modality captions generated by LLM with a simple concatenation of vision, audio captions, and subtitles. Model (d) outperforms model (c) on all benchmarks, showcasing the necessity and effectiveness of leveraging the powerful capabilities of LLM to integrate single-modality captions into omni-modality ones. (p. 9)