The Victim and The Beneficiary Exploiting a Poisoned Model to Train a Clean Model on Poisoned Data
[mixup backdoor-attack simclr dataset deep-learning data-augmentation self_supervised cut-mix attention-mix This is my reading note for The Victim and The Beneficiary: Exploiting a Poisoned Model to Train a Clean Model on Poisoned Data. This paper proposes a method to train a model which is oust to poison data attack.it contains three components: 1) use entropy to filter out poison data; 2) train a network on clean data and improve is robustness by using attention mix; 3) combine both prison data and clean data using semi-supervised learning.
Introduction
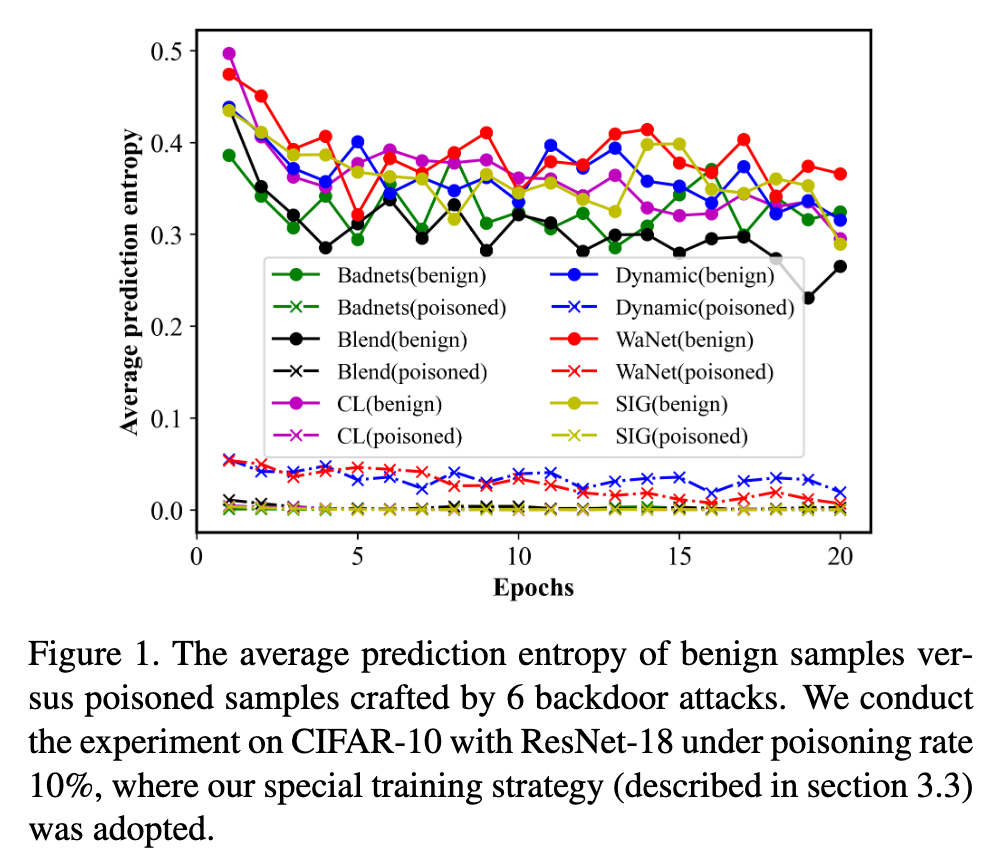
In this paper, we find that the poisoned samples and benign samples can be distinguished with prediction entropy. This inspires us to propose a novel dual-network training framework: The Victim and The Beneficiary (V&B), which exploits a poisoned model to train a clean model without extra benign samples. Firstly, we sacrifice the Victim network to be a powerful poisoned sample detector by training on suspicious samples. Secondly, we train the Beneficiary network on the credible samples selected by the Victim to inhibit backdoor injection. Thirdly, a semi-supervised suppression strategy is adopted for erasing potential backdoors and improving model performance. Furthermore, to better inhibit missed poisoned samples, we propose a strong data augmentation method, AttentionMix, which works well with our proposed V&B framework (p. 1)
Backdoor attacks [5, 11, 24] pose a serious security threat to the training process of DNNs and can be easily executed through data poisoning. Specifically, attackers [7, 10, 22] inject the designed trigger (e.g. a small patch or random noise) to a few benign samples selected from the training set and change their labels to the attacker-defined target label. These poisoned samples will force models to learn the correlation between the trigger and the target label. In the reference process, the attacked model will behave normally on benign samples but output the target label when the trigger is present. Deploying attacked models can lead to severe consequences, even life-threatening in some scenarios (e.g. autonomous driving). Hence, a secure training framework is needed when using third-party data or training platforms. (p. 1)
Many researchers have devoted themselves to this topic and proposed feasible defenses. Li et al. [18] utilize local benign samples to erase existing backdoors in DNNs, and Borgnia et al. [3] employ strong data augmentations to inhibit backdoor injection during training. Li et al. [17] find that the training loss decreased faster for poisoned samples than benign samples and designed a loss function to separate them. Finally, they select a fixed portion of samples with the lowest loss to erase potential backdoors. (p. 2)
In experiments, we find the entropy of model prediction is a more discriminative property, and a fixed threshold could filter out most poisoned samples, as shown in Figure 1. During training, poisoned samples will be learned faster than benign samples due to the similar feature of their triggers [17]. Hence, the poisoned network can confidently predict poisoned samples as the target label in early epochs but hesitates about the benign samples. (p. 2)
Related Work
Data Augmentation
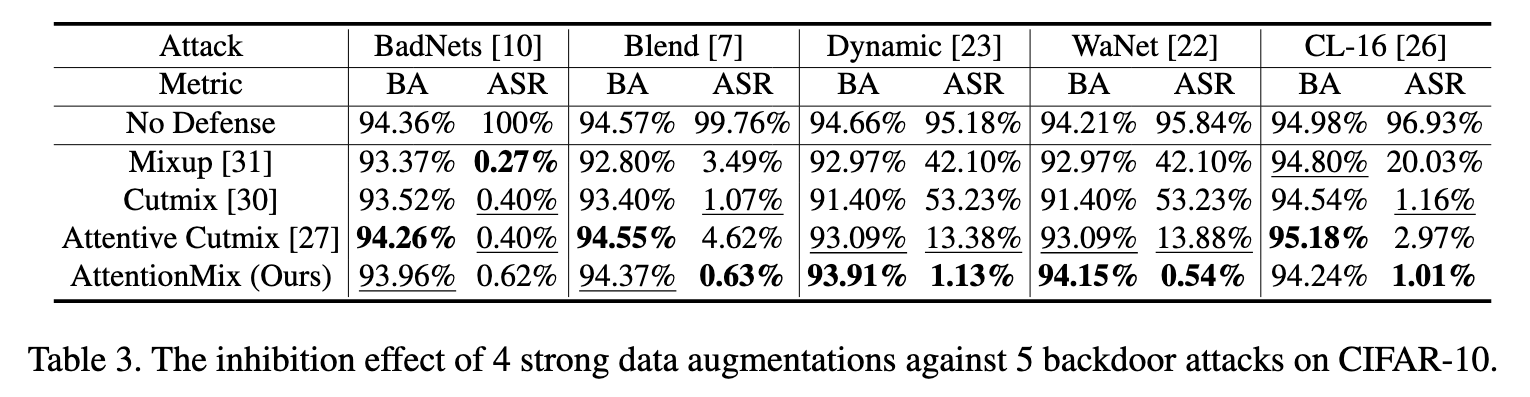
many strong data augmentation techniques [27, 30, 31] have been proposed to further improve model performance. Mixup [31] linearly interpolates any two images and their labels, then trains the model with generated samples. However, the generated samples tend to be unnatural, which will decrease model performances on localization and object detection tasks. Instead of linear interpolation, Cutmix [30] replaces a random patch with the same region from another image and mixes their labels according to the ratio of the patch area. Further, Attentive Cutmix [27] only pastes the influential region located by an attention mechanism to other images, effectively forcing models to learn discriminative details. Yet it also mixes labels based on the ratio of the region area, ignoring the importance of the region in two original images, and direct pasting may bring complete triggers into benign samples. (p. 2)
Backdoor Attack and Defense
Poisoned-based backdoor attack
In early studies, attackers usually adopt simple and visible patterns as the trigger, such as a black-white checkerboard [10]. To escape human inspections, some works use human-imperceptible deformations [22] as the trigger or design unique triggers [16, 23] for each poisoned sample. However, they randomly select benign samples to inject triggers and change their labels (called poison-label attacks), possibly causing the content of an image not to match its label. Instead of randomly selecting samples to poison, Turner et al. [26], Mauro et al. [1], and Liu et al. [21] only inject triggers into benign samples under the target label (called clean-label attacks). Although some triggers are imperceptible in the input space, they can be easily detected by defenses focused on latent space extracted by CNNs. Therefore, recent studies [33, 34] not only ensure the trigger’s invisibility in the input space but also restrict the similarity between poison samples and corresponding benign samples in the latent space. (p. 2)
Backdoor Defense
For poisoning-based attacks, defense methods could be divided into three categories from their working stage, including (1) preprocessing before training [9, 12, 25], (2) poison suppression during training [14, 17, 20], and (3) backdoor erasing after training [18, 28, 32]. For preprocessing, Hayase et al. [12] and Chen et al. [4] filter the training set through statistics or clustering and train the model with benign samples. For poison suppressing, Borgnia et al. [3] leverage strong data augmentation (e.g. Mixup, Cutmix) to alleviate poisoned samples’ adverse effects. Huang et al. [14] design a decoupling training process, which first learns a feature extractor via SimCLR [6] to prevent poisoned samples from clustering in feature space. For backdoor erasing, Liu et al. [19] prune the lowactivation neurons for validation samples (benign samples) and then fine-tune the model with these benign samples. While Li et al. [18] first fine-tune the poisoned model with a small portion of benign samples to obtain a teacher model, then erase the original model’s backdoor through knowledge distillation. (p. 3)
Method
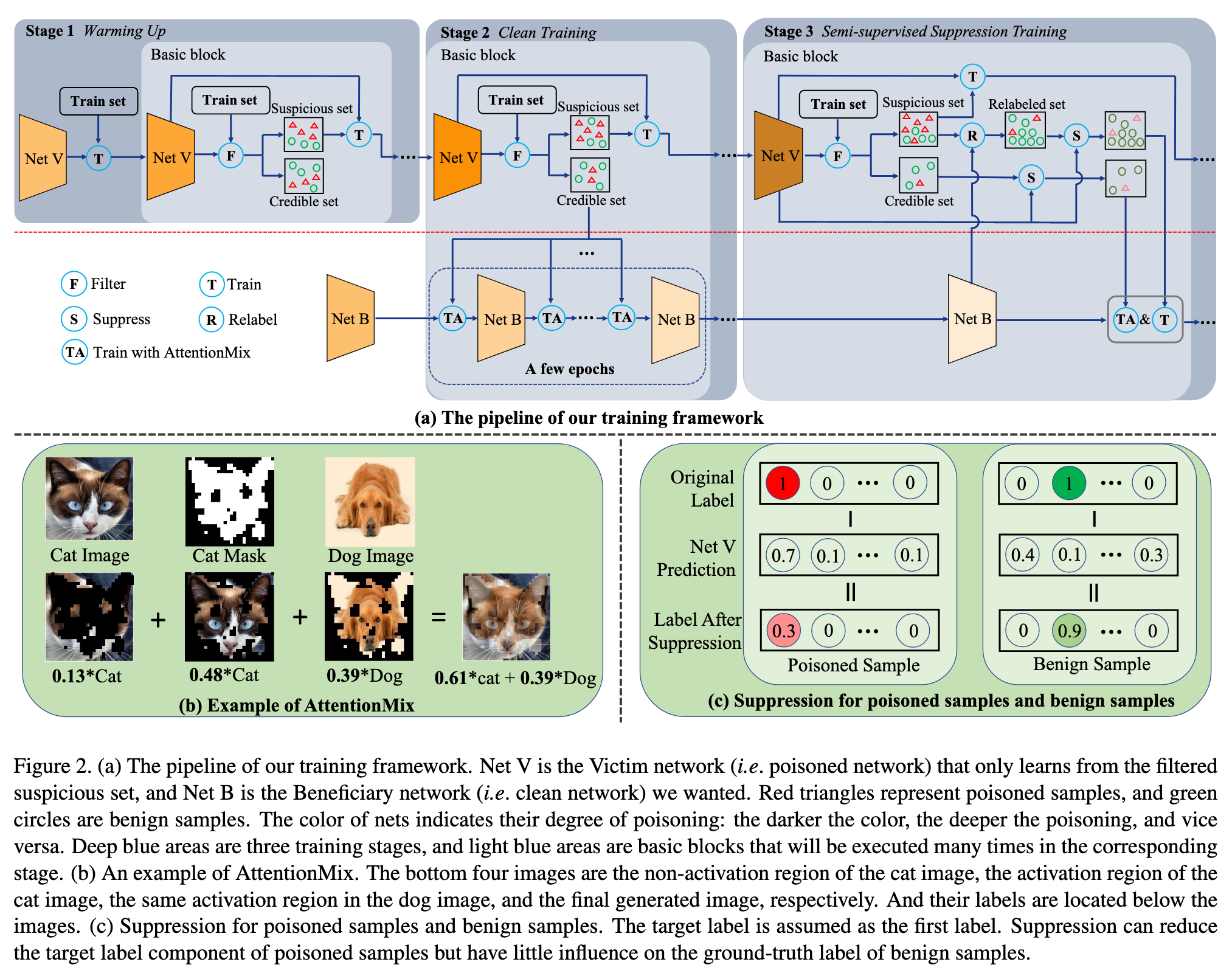
Therefore we train the Victim network with only filtered suspicious samples (i.e. suspicious set) except for the first epoch. During clean training, we adopt credible samples (i.e. credible set) to train the Beneficiary network with our proposed AttentionMix data augmentation. The strong data augmentation can effectively prevent missed poisoned samples from creating backdoors. As the Victim network is trained, the entropy of its prediction for benign samples will also slowly decrease below the filtering threshold, leading to a reduction in the credible set size. So one credible set will be used for a few epochs to ensure the Beneficiary network gets enough training samples. (p. 3)
To further improve the Beneficiary network performance and erase its potential backdoor, we regard the credible set as a labeled dataset and the suspicious set as an unlabeled dataset to train the Beneficiary network via semi-supervised learning. Following conventional practice [2, 15], each unlabeled sample will be assigned a pseudo label generated by the Beneficiary network, forming the relabeled set (p. 3)
Warming Up
At this stage, we aim to obtain a poisoned network that has only learned trigger patterns. In this way, the entropy of its prediction for poisoned samples will be significantly lower than that of benign samples. Then we can use a threshold to filter out poisoned samples. (p. 3)
We first use the whole training set to train the Victim network for one epoch with cross-entropy loss. (p. 4)
| Once all samples’ prediction entropy is obtained, we normalize them to [0, 1] through mix-max normalization. Then a threshold tf is set to filter out suspicious samples Ds = {(xi, yi) | (xi, yi) ∈ D, ei < tf } and the remaining samples are regarded as credible samples Dc. To strengthen the learning of poisoned samples and delay the learning of benign samples, the Victim network will only be trained on suspicious sets in the future. (p. 4) |
So we set a smaller tf and wait for the prediction entropy of these poisoned samples to decrease. As training progresses, their prediction entropy will drop below tf , making the credible set cleaner. (p. 4)
Clean Training
So we design a strong data augmentation called AttentionMix to inhibit the missed poisoned samples from working. Compared with existing augmentations [27, 30, 31], AttentionMix has a stronger inhibition effect on stealthy backdoor attacks. (p. 5)
The core idea of AttentionMix is to generate a new training sample (x˜, y˜) by mixing two training samples (x_1, y_1) and (x_2, y_2) according to their attention maps. Following [18], we adopt one sample’s final feature maps to compute its attention map (p. 5)

For each attention map, we first bilinearly interpolate it to the original image size H × W, and then normalize its elements to [0, 1] by min-max normalization. (p. 5)
After getting the attention map, we set a threshold t_m to obtain the activation region that we want to mix: (p. 5)
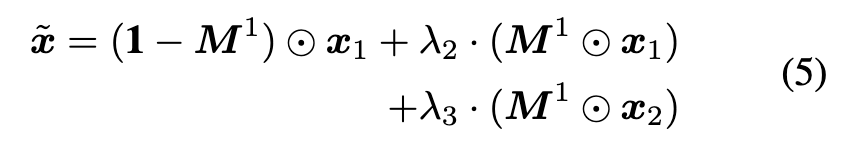
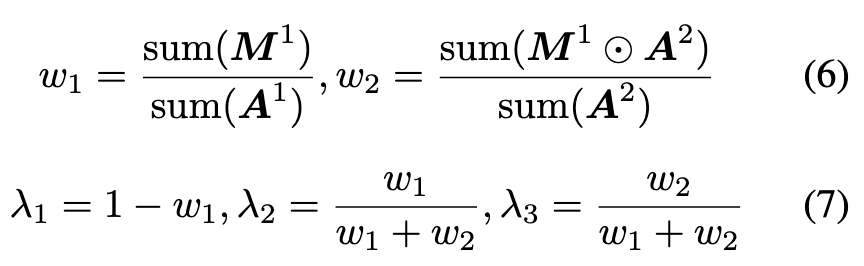
For a poisoned network, the activation region of poisoned samples is more likely their trigger locations. Mixing the activation region can destroy the completeness of trigger patterns. While for benign samples, the mixing plays a regularization role that prevents the network from overfitting a particular subject and forces it to learn abundant features. (p. 5)
Semi-supervised Suppression Training
In the previous stage, the Beneficiary network is trained only with partial training samples (i.e. the credible set), which may harm its performance on benign samples. Thus we intend to enable the deprecated suspicious samples via semi-supervised learning at this stage to improve the Beneficiary network while erasing its potential backdoor. (p. 5)
Given a credible set D_c and a suspicious set D_s, we use samples in D_c as labeled samples and remove the labels of samples in D_s to transform the problem into a semisupervised learning setting. For each unlabeled sample, we average the predictions of the Beneficiary network over its multiple augmentations (e.g. random crop and random flip) and select the class with max probability as its pseudo-label, (p. 5)
However, the poisoned samples in D_s may be relabeled as the target label, i.e. y~_i = y_t, if the Beneficiary network still contains the backdoor. We can mitigate the impact of such mislabeling by exploiting the knowledge learned by the Victim network. Specifically, we adopt the Victim network’s prediction to suppress the pseudo-label (i.e. Suppress in Figure 2(a)): (p. 5)
Experiment
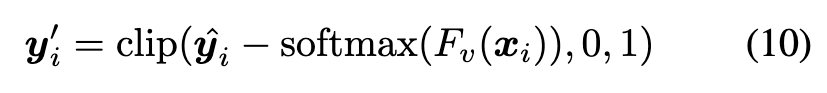
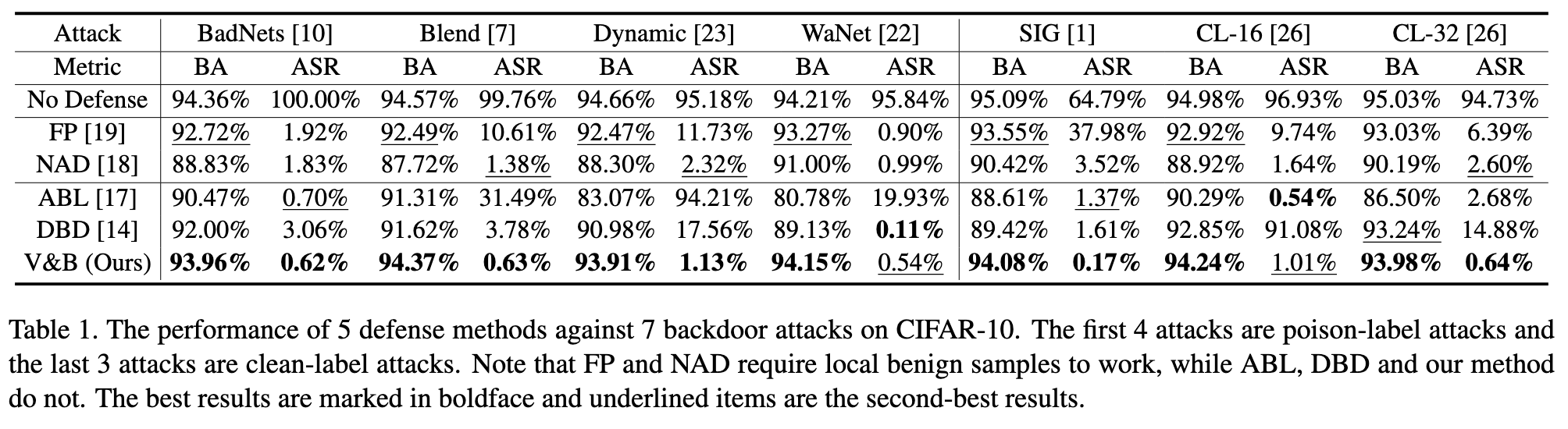
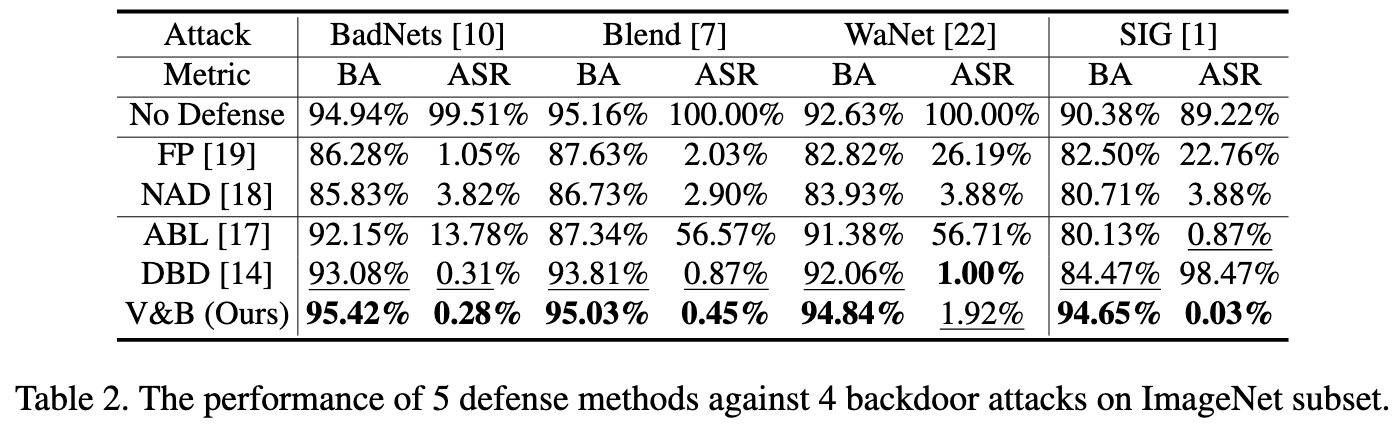
Ablation Studies
Component Effects
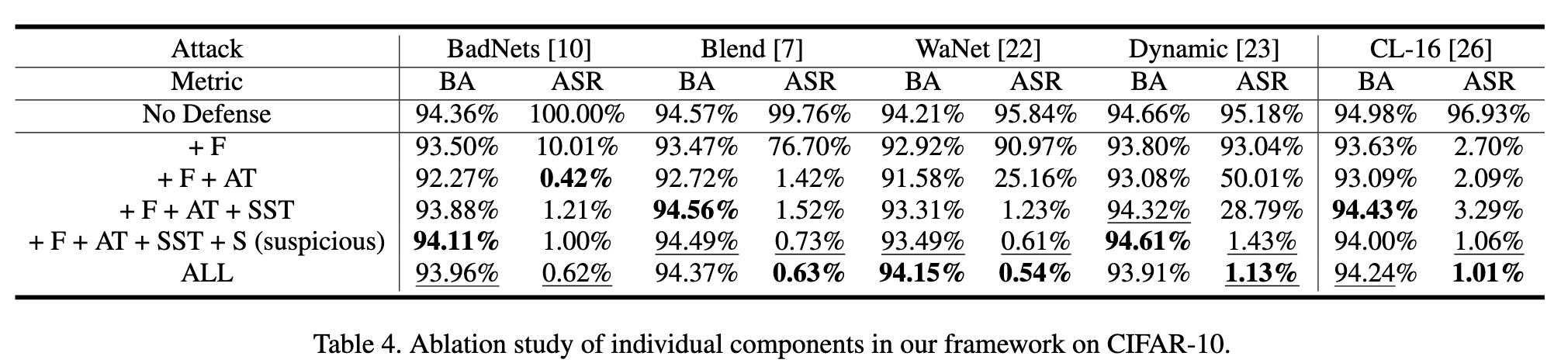
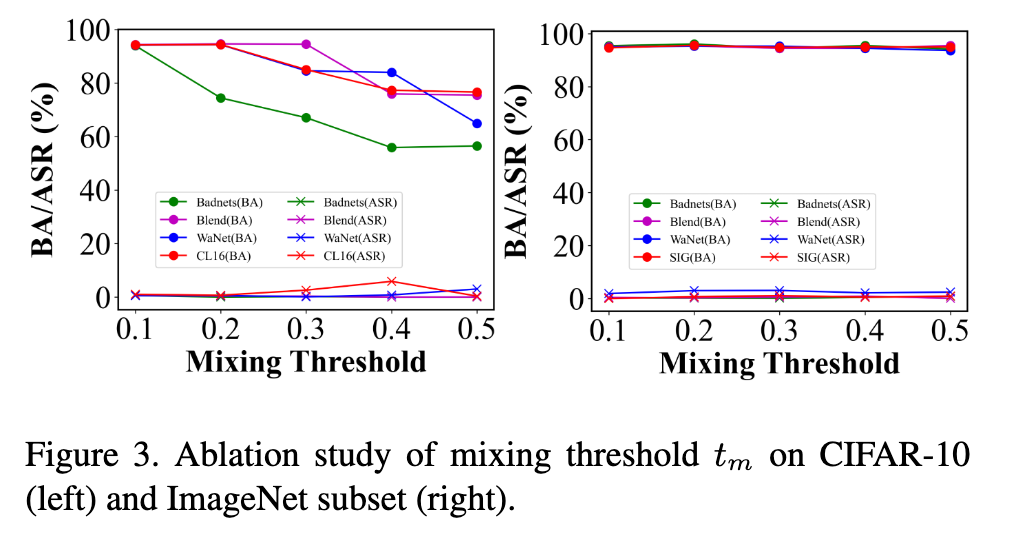
As shown in Table 4, We first train the network without any defense as a baseline and then add our components one by one to investigate their effect. The variants are as follows: (1) + F: filtering the training set and training on credible samples; (2) + F + AT: using AttentionMix when training with credible samples; (3) + F + AT + SST: adding standard semi-supervised training [2] on the basis of the second variant; (4) + F + AT + SST + S (suspicious): suppressing suspicious samples during semisupervised training on the basis of the third variant. (p. 8)
As can be seen from Table 4, when defending against Blend, WaNet, and Dynamic, only filtering will fail because enough poisoned samples are missed to create backdoors. After using AttentionMix, although the attack success rate of most attacks is severely decreased, the benign accuracy also drops slightly. Thus semi-supervised training is adopted to improve the performance of the network on benign samples. For WaNet and Dynamic, semi-supervised training also reduces their attack success rate by relabeling poisoned samples as ground-truth labels. However, the Beneficiary network is not completely clean, so a small number of poisoned samples may be relabeled as the target label, causing the attack success rate to rebound (e.g. BadNets, Blend and Cl-16). Suppression to suspicious samples can make up for the weakness of relabeling and adding suppression to credible samples will further reduce the attack success rate. We say that the complete framework is more secure when facing backdoor attacks, although its benign accuracy may be lower than other variants. (p. 8)