ViT AN IMAGE IS WORTH 16X16 WORDS TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
[attention sequence axial-attention vit deep-learning image-recognition transformer Vision Transformer (ViT) is a pure transformer architecture (no CNN is required) applied directly to a sequence of image patches for classification tasks. The order of patches in sequence capture the spatial information of those patches, similar to words in sentences.
It also outperforms the state-of-the-art convolutional networks on many image classification tasks while requiring substantially fewer computational resources (at least 4 times fewer than SOTA CNN) to pre-train.)
Architecture
The architecture of ViT could be described as below:
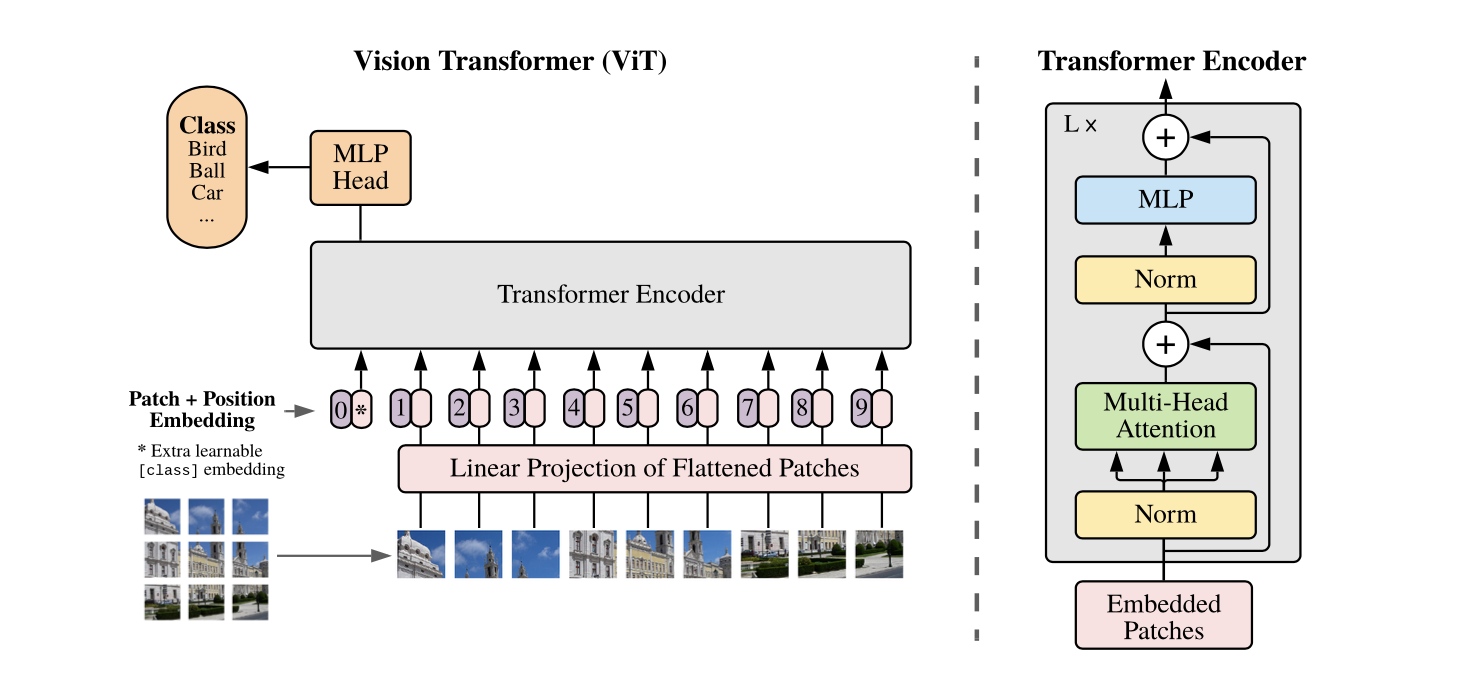
-
Features:
-
Input are images and each is \(H\times W\times C\) and then converted to a sequence of \(P\times P \times C\) patches. Let us say \(N=\frac{H}{P}\times\frac{W}{P}\) patches.
- for images at different size, the patch size is identical which results in sequence of different length.
-
Each of the patch is then converted to \(D\times 1\) feature vector, by one layer MLP in the paper. But any neurtal network could be used here, e.g., CNN, which is referred as hybrid architecture in the paper. This image visualizes the one layer MLP, where each small image is one chanel.

-
A learnable embedding is prepended to the sequence of embedded patches (\(z_0^0=x_{class}\)), which could be vewied to denote the start of sentence in NLP. The embededing is learned as part of VIT.
-
Learnable 1D position embededdings are then combined with the sequence of embeded patches as feature for the transformer encoder.
-
The paper indicates no significant advantages of using 2D position embedding over 1D position embedding.
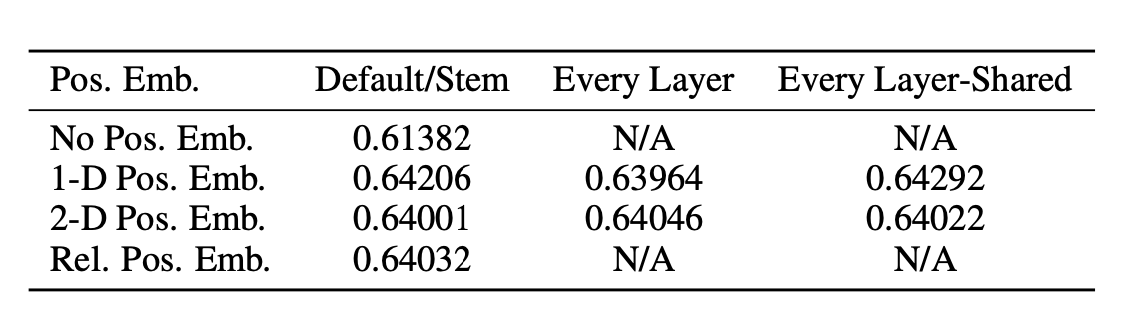
-
-
-
Transformer ender:
- the transformer encoder is consisted of alternative layerse of multi-head self attention.
- the performance of network increases with the # of layers in encoder and saturates at around 10~20 layers.
-
Recognition:
- the image label is estimated from the first element of output sequence via MLP head.
Implementations
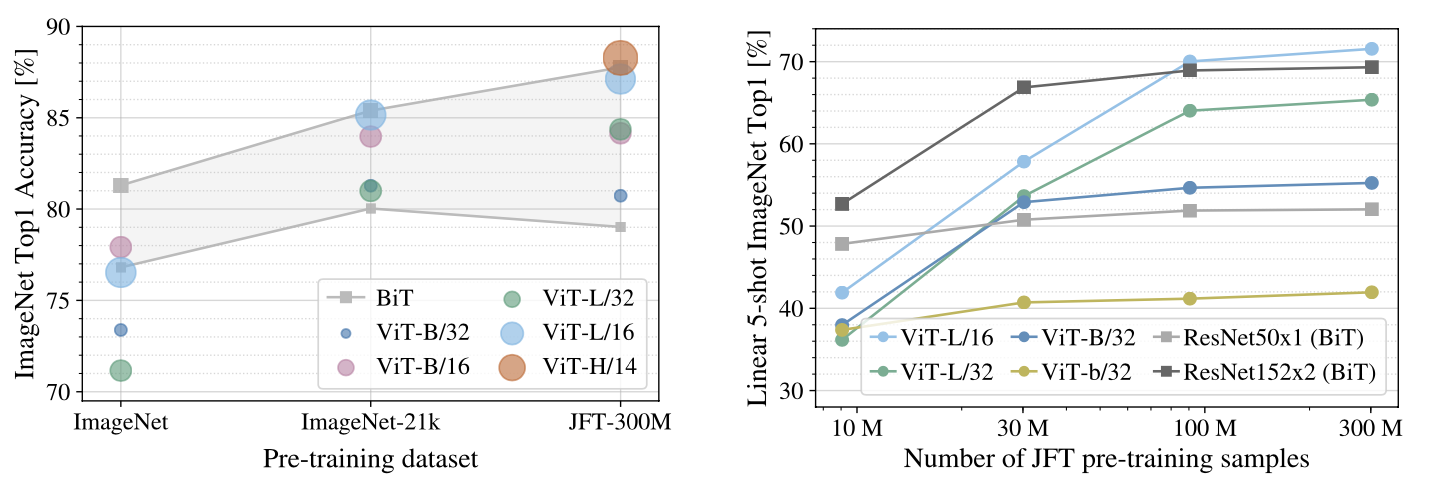
ViT needs to pre-train on large scale of data and then transferred (fine-tuned) to targeted dataset, which could be mid-scale or even small scale. This is critical to get competive performance. The figure below indicates 100M images are required for pre-training to get full potential of ViT.
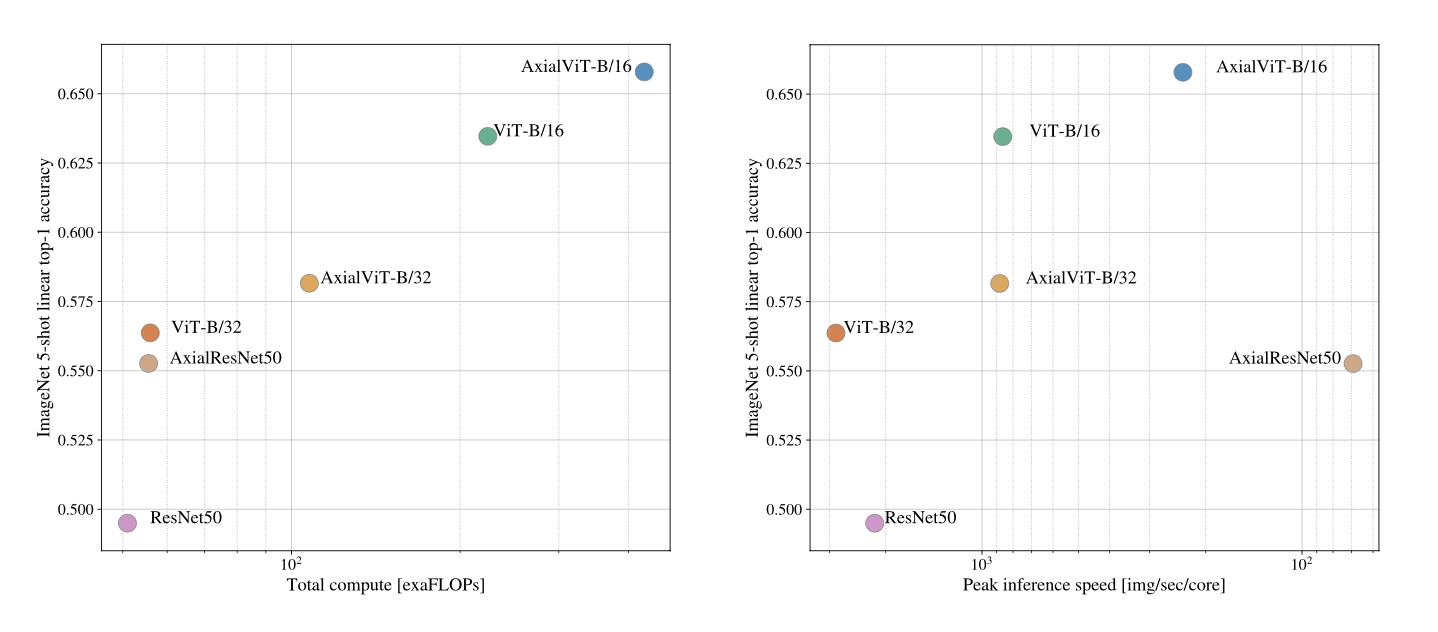
Axial Attention
The general idea of axial attention is to perform multiple attention operations, each along a single axis of the input tensor, instead of applying 1-dimensional attention to the flattened version of the input. In axial attention, each attention mixes information along a particular axis, while keeping information along the other axes independent. In AxialResNet50, all 3x3 convolution of ResNet50 is replaced by axial self-attention
ViT tested to replace multi-head self attention by axial self-attention (referred as AxialVit) and the result is shown as blow. Here ViT-B/16 means ViT baseline model with 16x16 patches in transformer encoder. It shows axial self attention obviously outperforms the multi-head self attention basedline, but at cost of more computation.