VPA Fully Test-Time Visual Prompt Adaptation
[dda multimodal tpt vpa deep-learning tent memo transformer coop prompt cocoop This is my reading note for VPA: Fully Test-Time Visual Prompt Adaptation. VPA introduces a small number of learnable tokens, enabling fully test-time and storage-efficient adaptation without necessitating source-domain information.
Introduction
However, it remains challenging to address these generalization problems solely during the training phase, as a single training recipe cannot encompass all underlying distributions. Test-time updates serve as valuable complements, focusing on tailored adaptation for specific test data [61] (p. 2)
Prompting is a similar paradigm that aids machine learning models in adapting to various contexts or even new tasks through specific textual input. (p. 2)
Test time Prompt Tuning (TPT) is a pioneering technique that leverages textual prompting during testing to improve the generalization capability of vision-language models [45, 49]. Prompt tuning is efficient in adapting a pretrained model, as it does not modify the original model parameters. In addition to prompting in NLP, recent studies have explored visual prompting during the training phase [3, 29], yielding substantial improvements on numerous vision benchmarks. (p. 2)
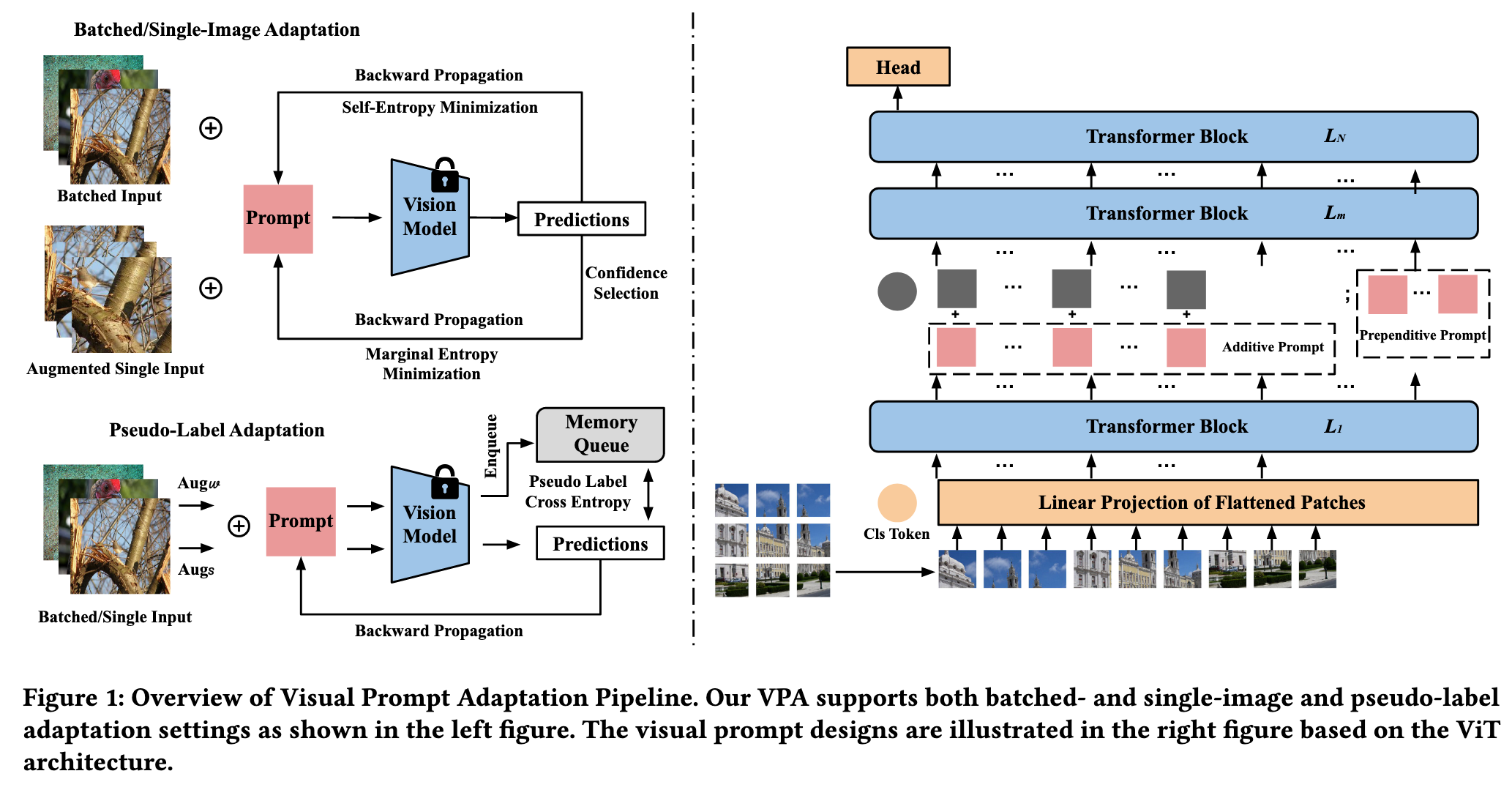
Given a pretrained model, we attach additive and prependitive prompts to the frozen model during the adaptation phase. VPA requires only a small number of prompts to be stored. (p. 2)
In contrast to the pixel-space prompts in [3] and the randomized initialization for embedding-space prompts in [29], we design a straightforward but intuitive paradigm using zero attention to initialize our prompts, ensuring that the original performance remains unaffected. (p. 2)
Additionally, we employ confidence selection to identify images with high confidence, which allows for more effective adaptation. By focusing on these high-confidence images, the VPA framework can better leverage the information contained within them. (p. 2)
RELATED WORK
Prompting in Foundation Models
For instance, CoOp [67] and CoCoOp [66] both employ trainable prompts to improve zero-shot recognition performance, while TPT [49] leverages test-time adaptation of language prompts to improve out-of-distribution robustness. Visual prompting has also been proposed to reprogram recognition tasks [14] and to enhance model performance on various downstream tasks [3]. Recent research has also introduced memory-efficient prompt tuning purely for vision models [29] to improve model generalization. (p. 3)
Test-Time Adaptation
Fully test-time adaptation is more rigorous, as it necessitates on-the-fly model updates without delaying inference.[42, 48] represent initial efforts towards achieving fully test-time adaptation, which involves updating or replacing the statistics of batch normalization (BatchNorm) layers[27] during inference. TENT accomplishes fully test-time adaptation by updating the model parameters in BatchNorm layers, using self-entropy minimization as its objective [61]. MEMO takes advantage of input augmentations to achieve single image adaptation, circumventing the batch-level adaptation requirement in TENT [63]. In contrast to optimizing model parameters, an alternative approach is to adapt input with minor modifications. DDA employs diffusion models to purify input data, although it is limited to specific types of corruption [16]. TPT introduces test-time adaptation via language prompting to enhance the OOD robustness of the CLIP model [49]. (p. 3)
VPA: VISUAL PROMPT ADAPTATION
Training a language model from scratch can be a time-consuming process; however, incorporating visual prompts can accelerate the training process by providing the model with relevant visual cues. This enables the model to learn and converge more quickly, resulting in improved efficiency and reduced training time. (p. 4)
Prompt Design
there exist only a few visual prompt designs aimed at improving recognition performance in the training phase [7, 29]. We formally define these designs as additive and prependitive prompts and illustrate them using the architecture of the Vision Transformer (ViT) model. (p. 4)
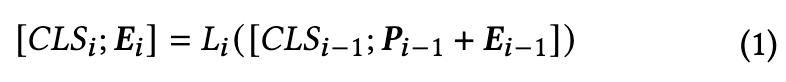
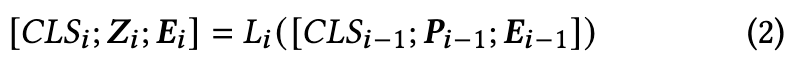
In contrast to randomized initialization, we design a zero attention scheme to initialize the prompt with zero tensors. This approach ensures that the initialization process does not impact the original performance of the frozen model. (p. 4)
Prompt Adaptation
In this section, we present the test-time adaptation procedure. Our study investigates two setups, namely episodic and continual adaptations. Episodic adaptation only applies to incoming data, and the model will be reset afterward. In contrast, continual adaptation lasts throughout the entire inference procedure. (p. 4)
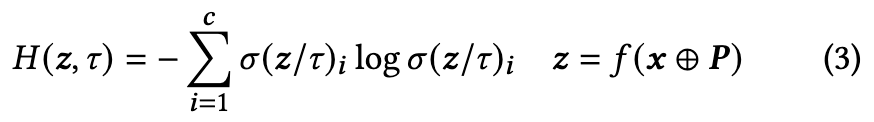
𝜏 is a tunable hyper-parameter that controls the softmax temperature. Self-entropy is an unsupervised loss function as it relies only on predictions and not on ground-truth information. However, since entropy reflects the prediction confidence, it can serve as an indicator of the model’s performance on the supervised task [61]. As VPA is a general adaptation framework, we leverage both batched- and single-image adaptation settings in our work, as introduced below. (p. 4)
Batched-Image Adaptation (BIA)
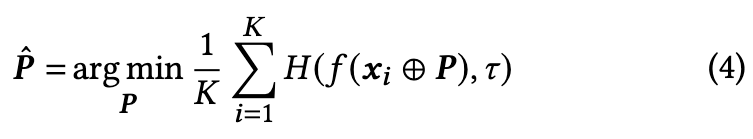
In BIA, VPA optimizes a visual prompt for all the test images in a given batch, which is the same setup as TENT [61], the SOTA method under BIA. (p. 4)
Single-Image Adaptation (SIA)
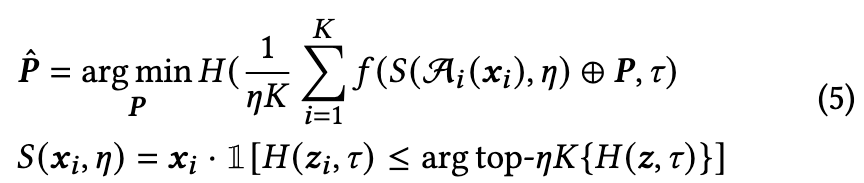
where A denotes a random augmentation function, 𝐾 is the augmented batch size, and 𝑆 () is a confidence selection function to pick augmented images with high confidence with a percentile of 𝜂, following the setting in [49]. The intuition behind SIA is to use marginal entropy minimization on the augmented input to optimize the prompt and enhance generalization. (p. 5)
During both BIA and SIA, the visual prompt 𝑷 is optimized by computing the gradient of the entropy loss w.r.t. 𝑷 (i.e., 𝜕𝐻 𝜕𝑷 ) during the backward pass. As self-entropy only relies on the network’s predictions without labels or source domain information, and our visual prompt 𝑷 is independent of model parameters, VPA achieves fully test-time adaptation. Additionally, besides episodic test-time adaptation, we also explore the application of continual online learning in test-time adaptation. (p. 5)
Pseudo-Labeling Adaptation (PLA)
To implement this approach, we use a memory queue M with size 𝑠 that stores the final 𝐶𝐿𝑆_𝑁 token, along with the prediction of historic data 𝒛𝑖 for reference when processing an incoming batch, i.e., M = {𝐶𝐿𝑆_𝑁_𝑖, 𝒛_𝑖 }𝑠 1. During adaptation, we generate reference labels for the incoming test data using its 𝑘 nearest-neighbor (𝑘NN) predictions on the 𝐶𝐿𝑆_𝑁 token before feeding into the head classifier. We then average the 𝑘NN predictions to produce the eventual pseudo label. We apply weak and strong augmentations to every incoming data sample inspired by FixMatch [50]. Specifically, we obtain the soft predictions for the weakly and strongly augmented samples, denoted as 𝒛_W and 𝒛_S, respectively. We then generate the pseudo label for the incoming data based on the soft voting mechanism in our memory queue: (p. 5)
Finally, we dynamically update the 𝐶𝐿𝑆𝑁 token along with its pre- diction 𝒛W into our memory queue for next-round adaptation. (p. 5)
EXPERIMENTS AND RESULTS
Evaluation of OOD Generalization
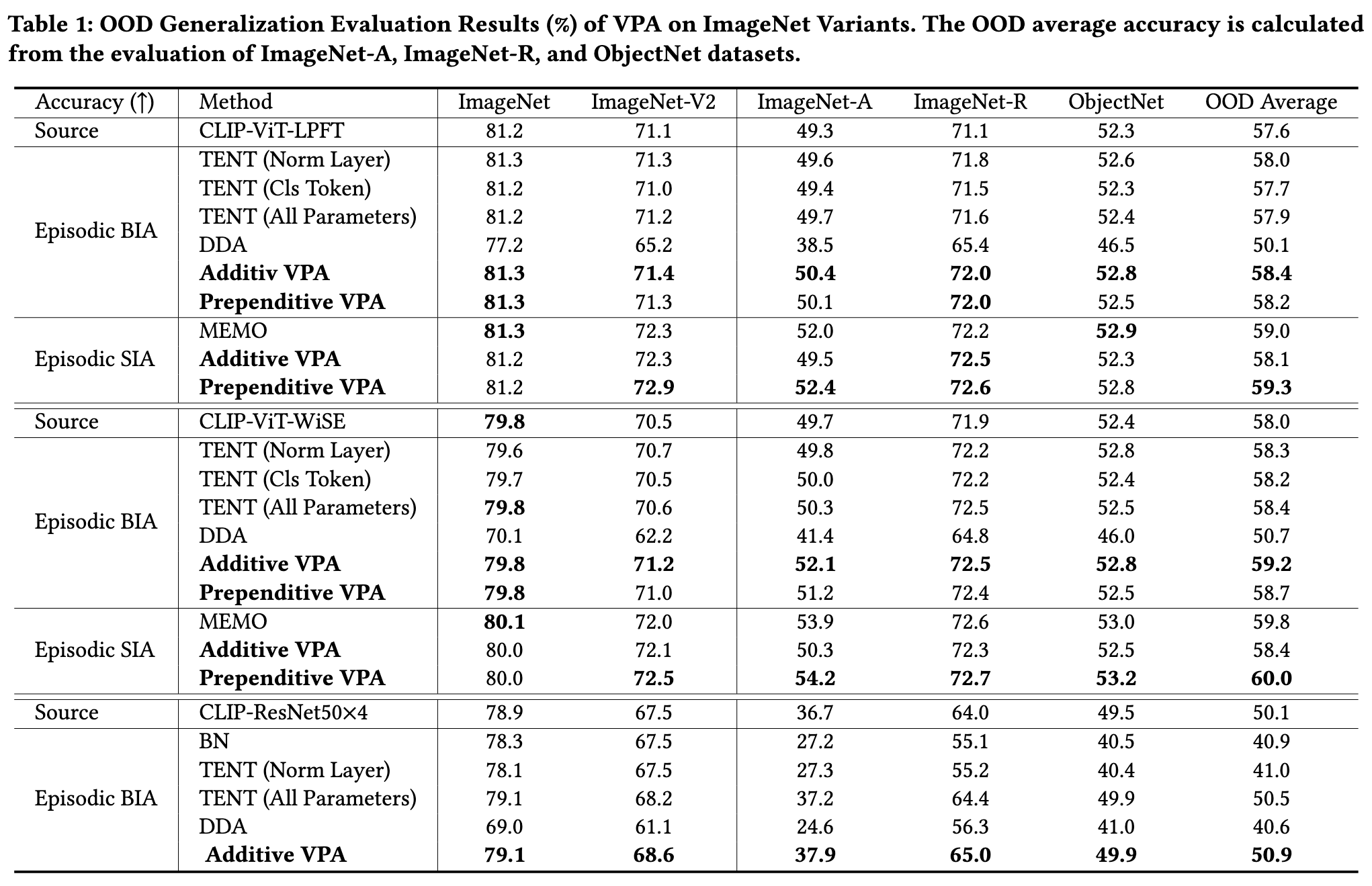
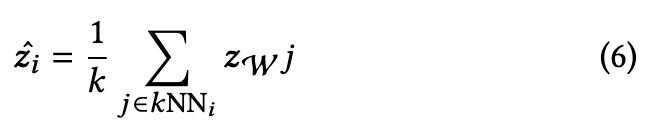
To study model robustness to realistic OOD data that naturally occurs in the physical world, we leverage ImageNet-A [26], ImageNetR [23], and ObjectNet [4]. ImageNet-A consists of 7,500 test images denoted as “natural adversarial examples” that are misclassified by a collection of standard models overlapped with 200 ImageNet categories. ImageNet-R collects 30,000 images of 200 ImageNet categories with artistic renditions. ObjectNet is a large real-world test set for object recognition with control where object backgrounds, rotations, and imaging viewpoints are random. We chose the ObjectNet subset that overlaps 113 classes with ImageNet in our study. We also use ImageNet-V2 [46], a robustness benchmark with mild distribution shift, to further validate our results. (p. 6)
We observe that TENT (Norm) only achieves slight improvements against natural distribution shifts compared to the source-only baseline. While the LayerNorm layer is a linear module that is preferred by the adaptation assumption in TENT [61], it is independent of the input data. Additionally, natural OOD data does not follow a clear distributional pattern, unlike synthesized corruptions. Therefore, the benefits of linear module adaptation do not transfer to our setting [61]. (p. 6)
Evaluation of Corruption Robustness
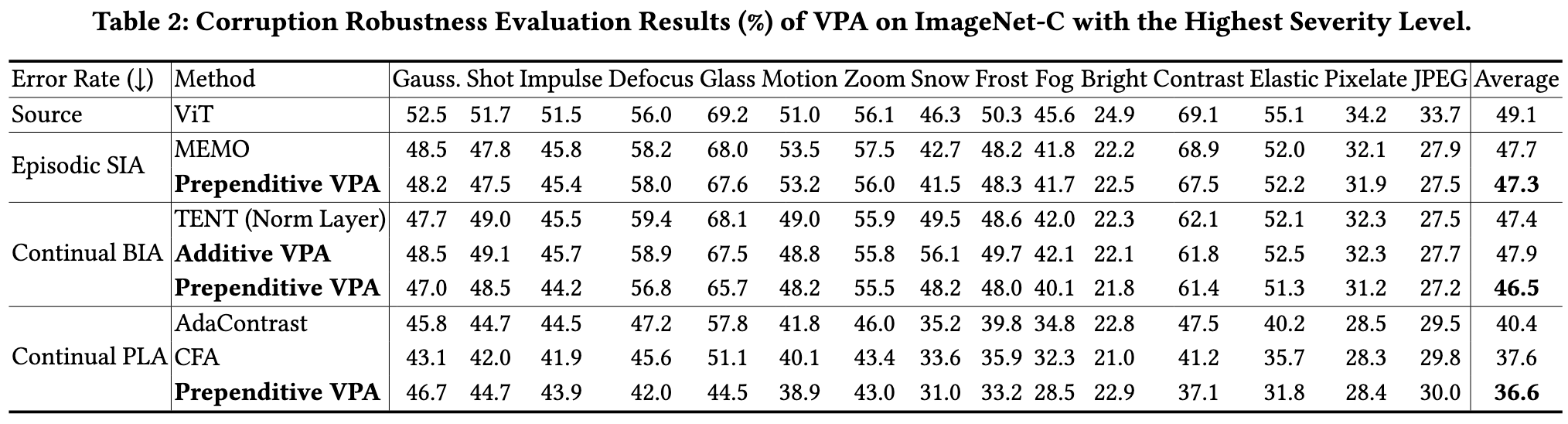
Experimental Setups. In this section, we evaluate the performance of VPA against common corruptions using the ImageNet-C dataset [24]. ImageNet-C is designed to assess the robustness and generalization capabilities of computer vision models by introducing 15 different corruptions at five severity levels to the original ImageNet validation dataset. These corruptions include various types of noise, blur, and distortion, making ImageNet-C a more realistic and challenging test of model robustness and generalization. (p. 7)
Evaluation of Domain Adaptation
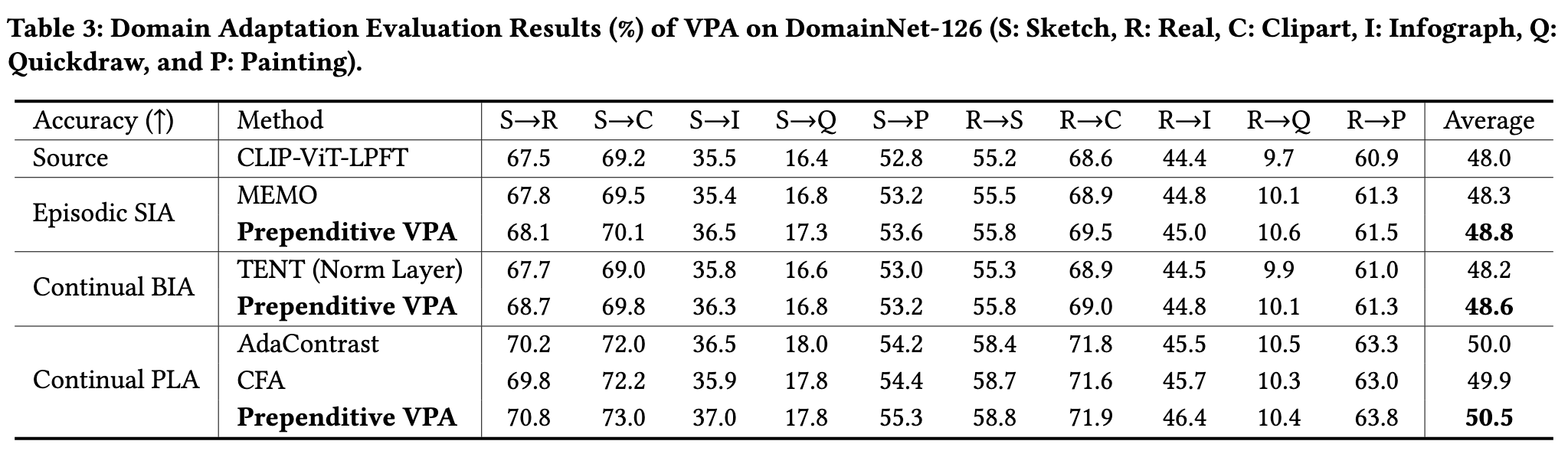
Experimental Setups. In this section, we discuss our experiments and results related to the domain adaptation task. We employ the DomainNet-126 dataset [43] for this purpose. DomainNet encompasses common objects from six domains (i.e., sketch, real, clipart, infograph, quickdraw, and painting) and 345 categories. In our study, we empirically use the sketch (S) and real (R) images as the training sets and evaluate the adaptation performance on the remaining subsets. (p. 7)
Ablation Studies
Prompt Size
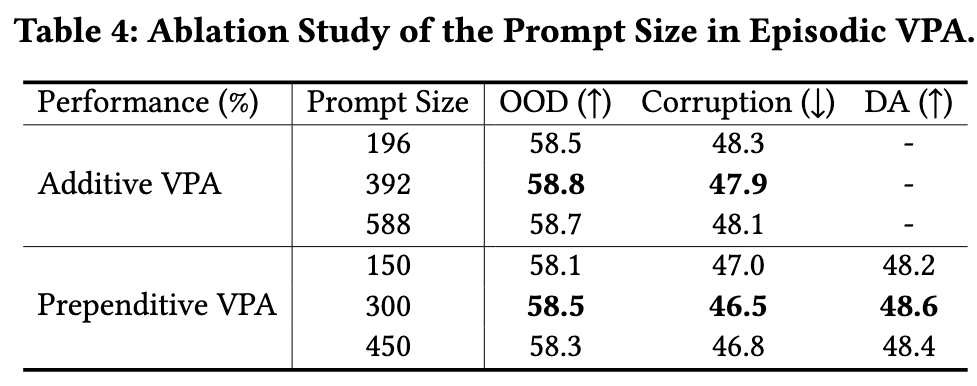
The evaluation highlights the existence of an optimal point for the number of prompting tokens. Having too many prompts can make it difficult to optimize, while a relatively small number of prompts may restrict the capability of VPA. (p. 8)
Adaptation Steps and Temperature 𝜏
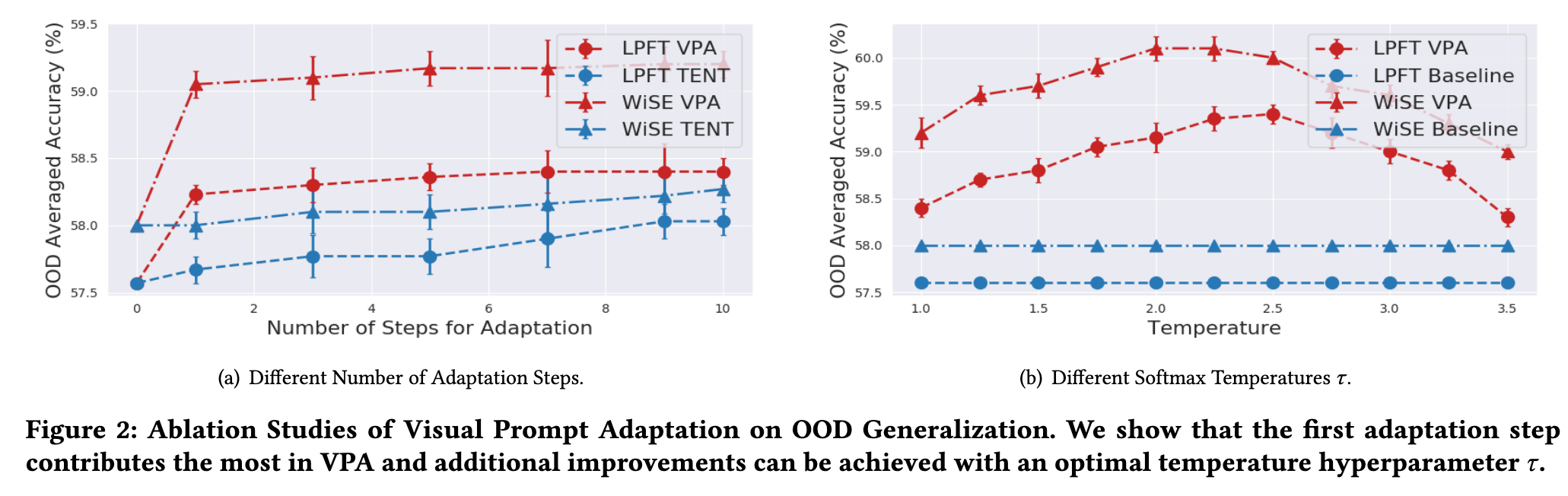
Figure 2(b) shows that there is a sweet point for the temperature parameter for OOD robustness improvement: We find that with an optimal temperature, the OOD robustness of the LPFT model could further improve by 1.5% on average. However, selecting an optimal 𝜏 requires an additional validation set with access to the label (p. 8)
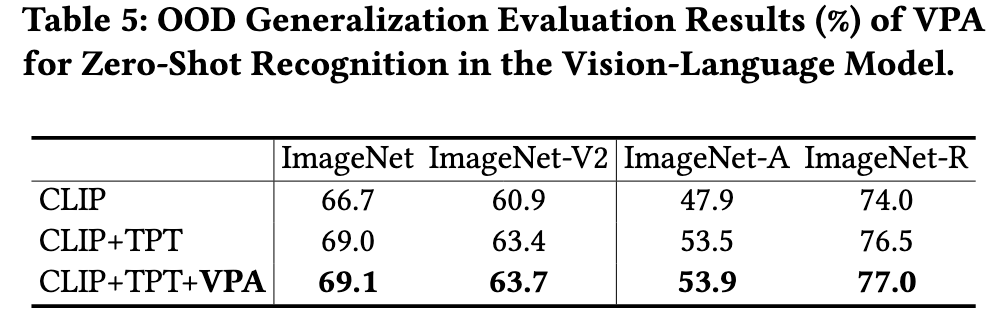
Vision-Language Model
Augmentation
We further conducted two ablation studies on the augmentation and 𝑘NN soft majority voting in PLA. (p. 11)
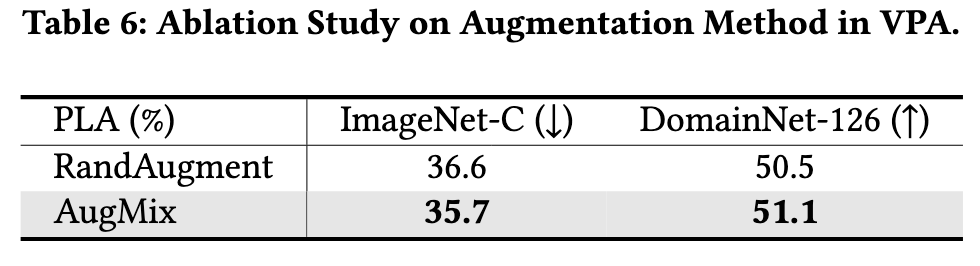
These findings illustrate the considerable potential for performance enhancement through the thoughtful selection and application of image augmentation techniques. (p. 11)
KNN
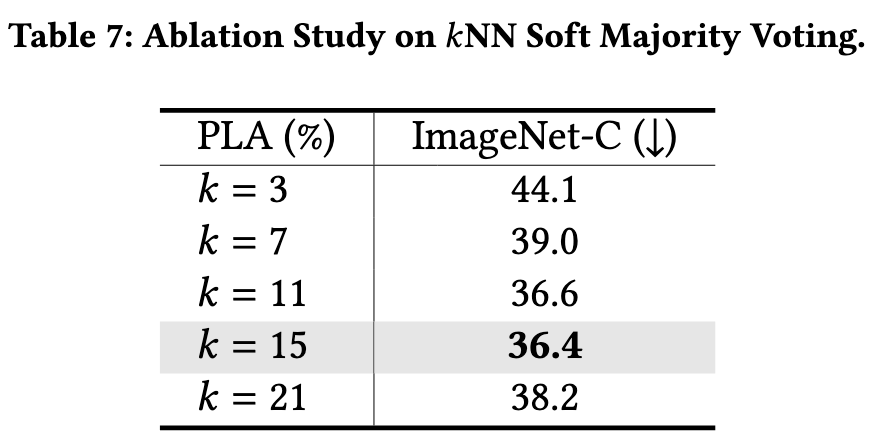
As presented in Table 7, 𝑘 is indeed an essential hyper-parameter in pseudo-label adaptation. We find that 𝑘 ∈ [11, 15] generally achieves the highest performance gain (p. 11)