AnyMAL An Efficient and Scalable Any-Modality Augmented Language Model
[multimodal llm deep-learning bad anymal transformer This is my reading note for AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model. The papa proposes a multi modality model which uses a projection layer to align the features of frozen modality encoder to the space of frozen LLM

Introduction
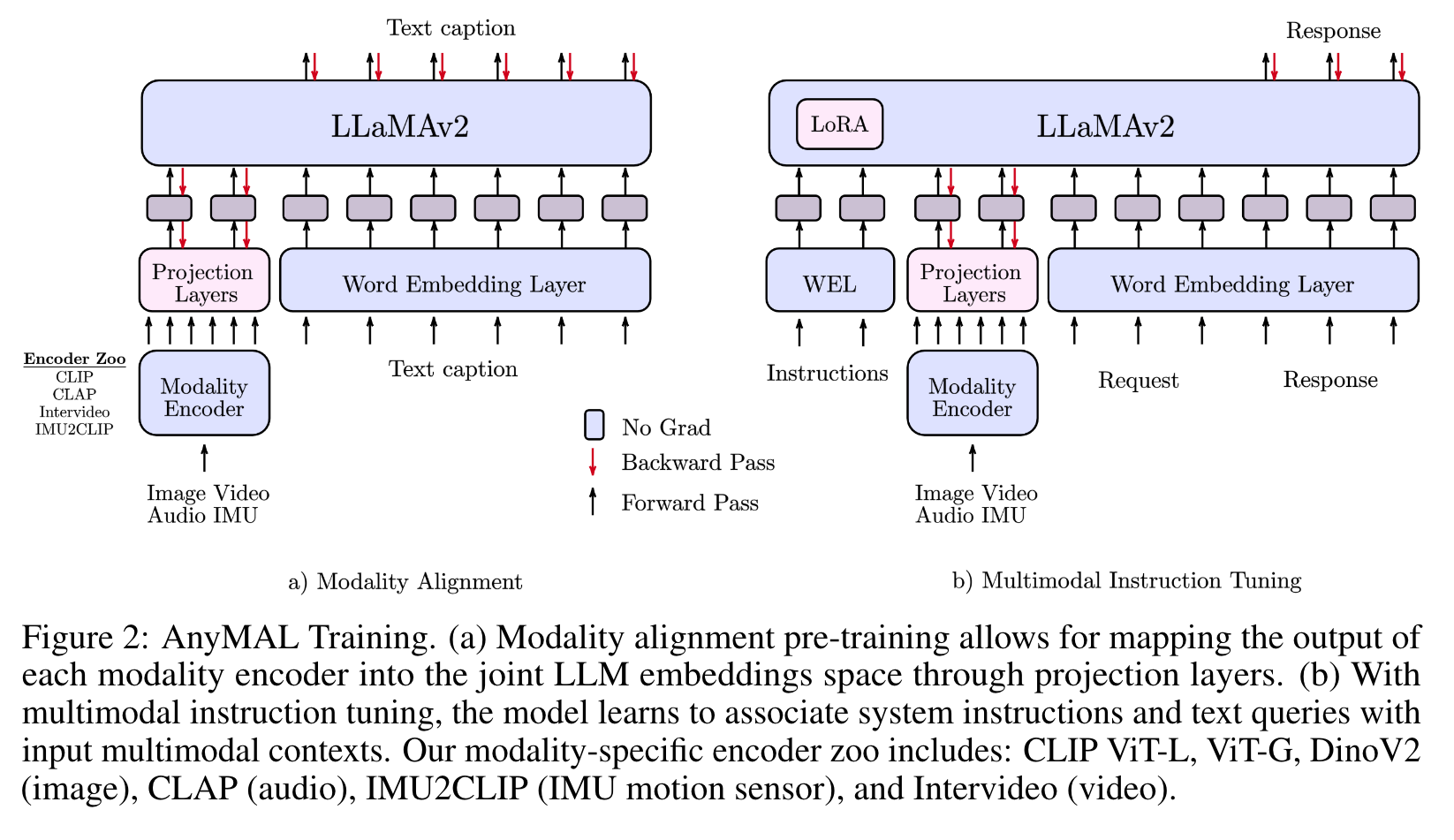
we introduce Any-Modality Augmented Language Model (AnyMAL) — a collection of multi-modal encoders trained to transform data from various modalities, including images, videos, audio, and IMU motion sensor data, into the text embedding space of an LLM. To achieve this, we extend the work by [1] to (1) more capable instruction-tuned LLMs (i.e. LLaMA-2-70B-chat [6]), (2) larger pre-trained modality encoders, and (3) advanced projection layers to handle variable input lengths. The model output examples are shown in Figure 1, and an illustration of the overall methodology is shown in Figure 2. (p. 1)
Method
Pre-training
Modality Alignment
We achieve the multimodal understanding capabilities by pre-training LLMs with paired multimodal data (modality-specific signals and text narrations) (Figure 2). Specifically, we train a lightweight adapter for each modality to project the input signals into the text token embedding space of a specific LLM. In this way, the text token embedding space of the LLM becomes a joint token embedding space, with tokens representing either text or other modalities. The number of token embeddings used to represent each input modality is fixed per adapter, ranging from 64 - 256 in this work. During the alignment training, we freeze the model parameters of the underlying LLM (p. 3)
In addition, to maximize the feature compatibility, for each modality we use an encoder g(·) that has already been aligned to a text embeddings space, e.g. CLIP [30, 31] for images, CLAP [32] for Audio signals, or IMU2CLIP [33] for IMU signals (p. 3)
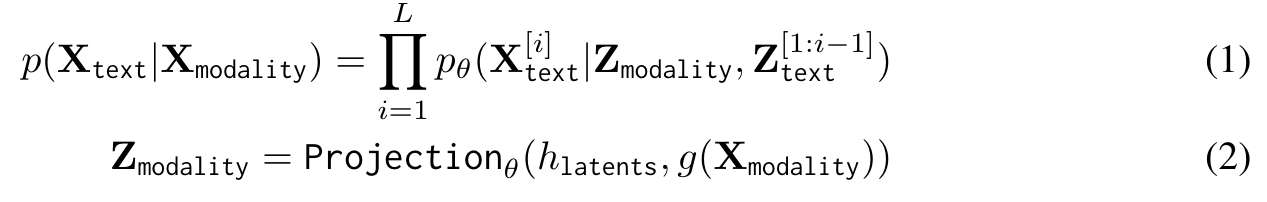
Datasets
For image alignment, we use a cleaned subset of the LAION-2B dataset, filtered using the CAT method and with any detectable faces blurred [34]. For audio alignment, we use AudioSet [35] (2.1M samples), AudioCaps [36] (46K samples), and CLOTHO [37] (5K samples) datasets. We use the Ego4D dataset [38] for IMU and text alignment (528K). (p. 3)
Quantization
To effectively scale our training, we implement the quantization strategies (4 bits and 8 bits) [40] in our multimodal settings, in which we keep the LLM component of our model frozen and only have the modality tokenizers trainable. This approach shrinks the memory requirement by an order of magnitude. Thus, we are able to train 70B AnyMAL on a single 80GB VRAM GPU with a batch size of 4 (p. 3)
We do note that the training / validation loss were constantly higher compared to the FSDP training, but nevertheless did not impact the generation quality (at inference time, we use the original LLM at full precision to maximize the accuracy). (p. 3)

Fine-tuning with Multimodal Instruction Datasets
we perform additional fine-tuning with our multimodal instruction-tuning (MM-IT) dataset. Specifically, we concatenate the input as [<instruction> <modality_tokens>], such that the response target is grounded on both textual instructions and the modality input. (p. 5)
Specifically, we use various Creative Commons licensed, publicly available images, and augment these images with manually created instructions and responses. Annotators are required to provide instruction and answer pairs that are strictly multimodal, (p. 5)
Specifically, we use a textual representation of the image (i.e. multiple captions, bounding boxes information and objects) to generate question-answer pairs for the image. (p. 5)
Experiments

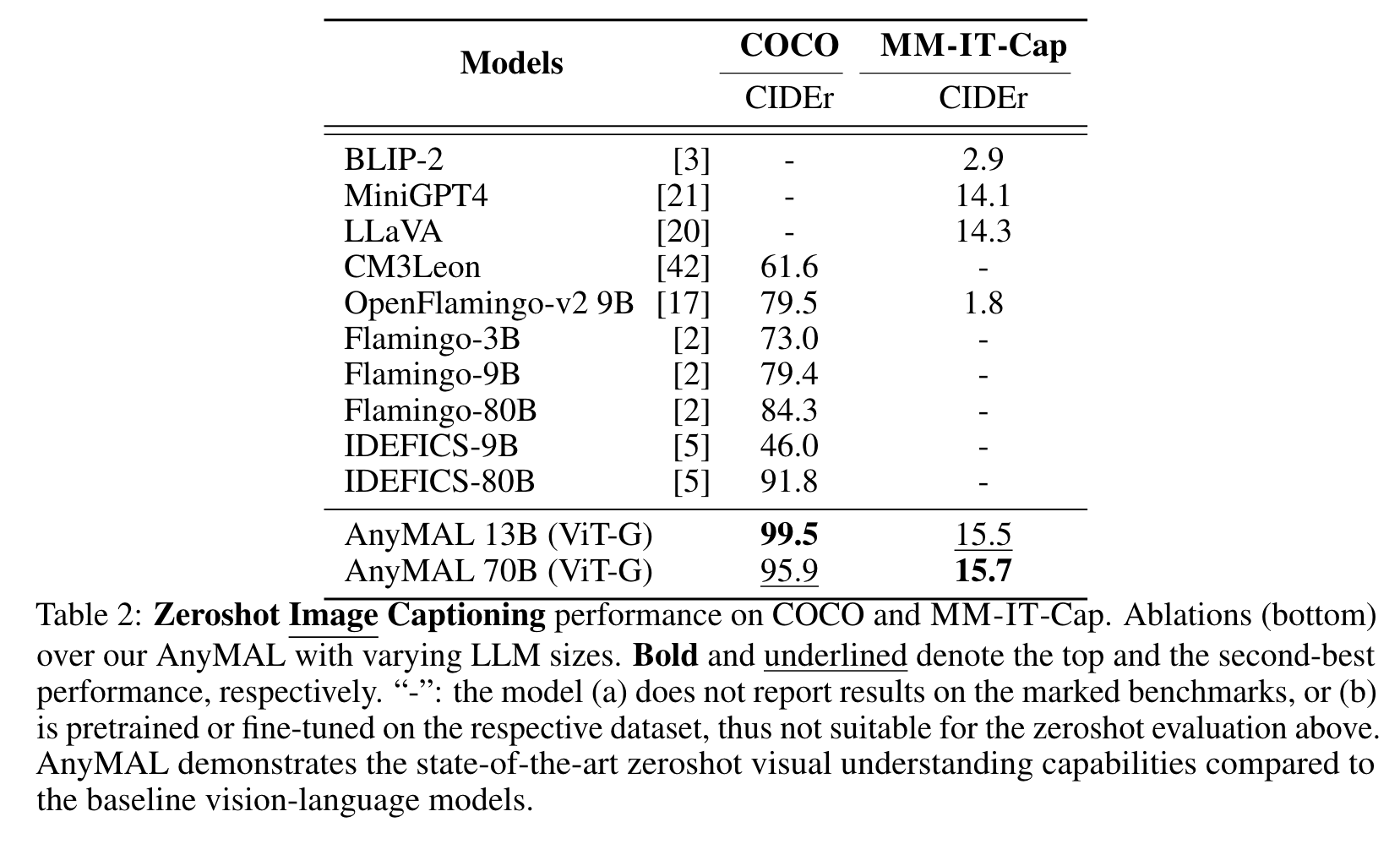
Image Caption Generation
It is worthwhile to note that there is no significant gap between the performance of the AnyMAL-13B and the AnyMAL-70B variants. This result indicates that the underlying LLM capability has smaller impact to the image caption generation task (which corresponds to the core visual understanding capability), but is largely dependent on the scale of the data and the alignment methods. (p. 5)
Human Evaluation on Multimodal Reasoning Tasks
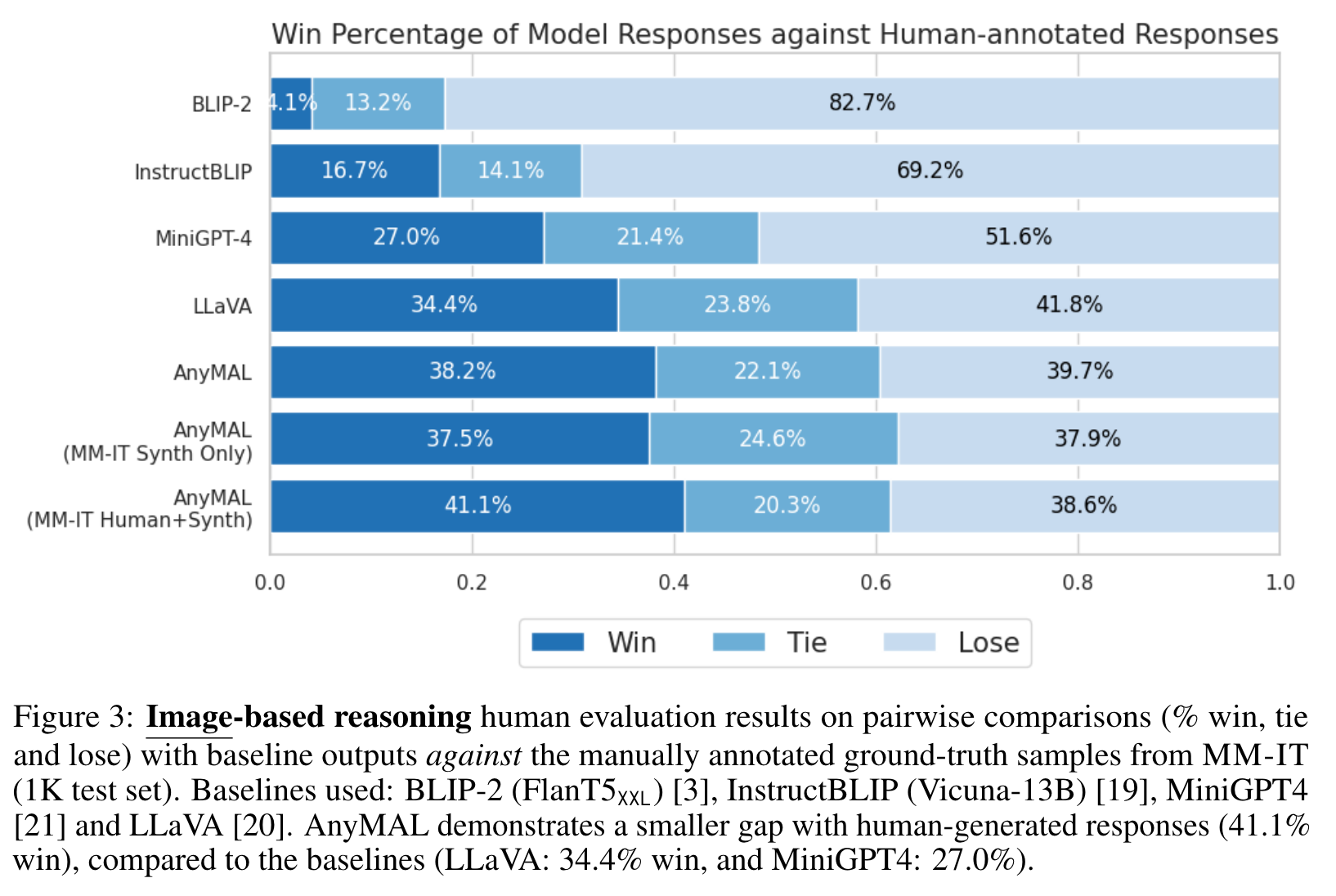
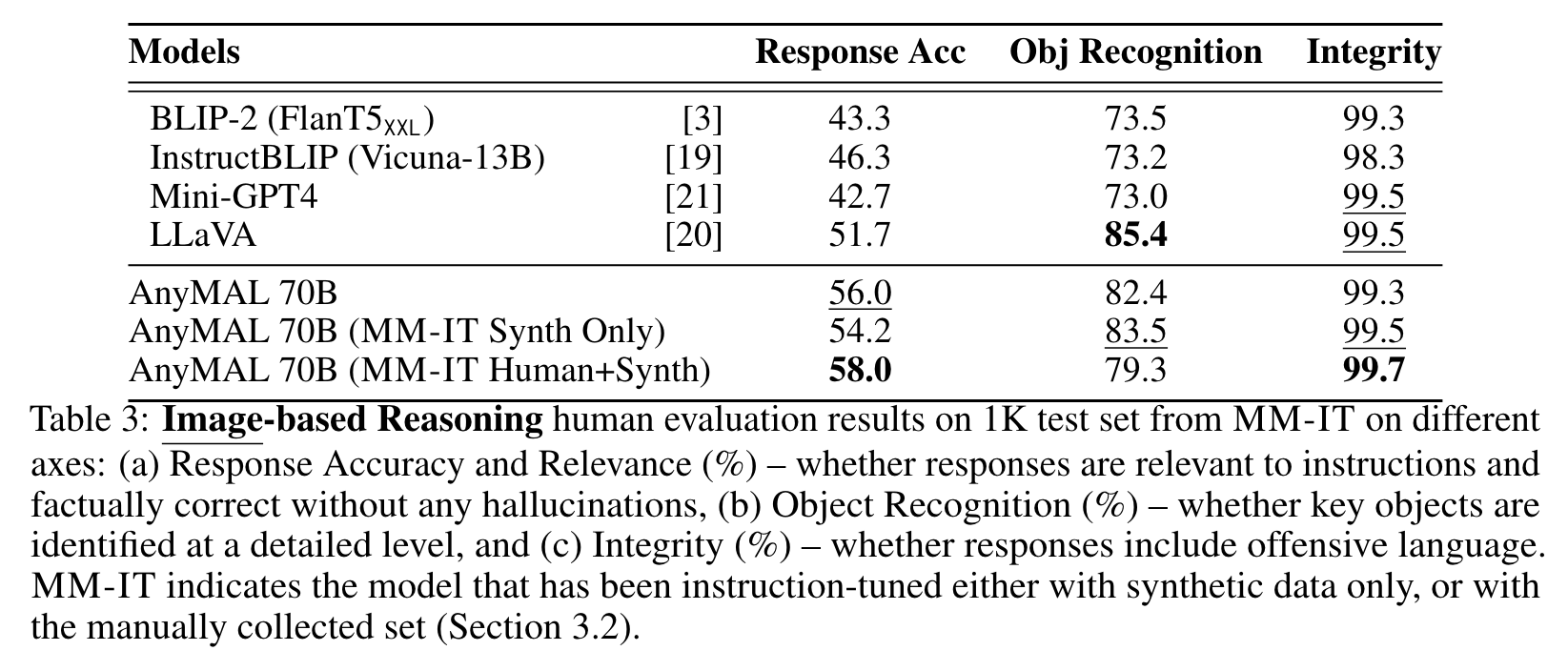
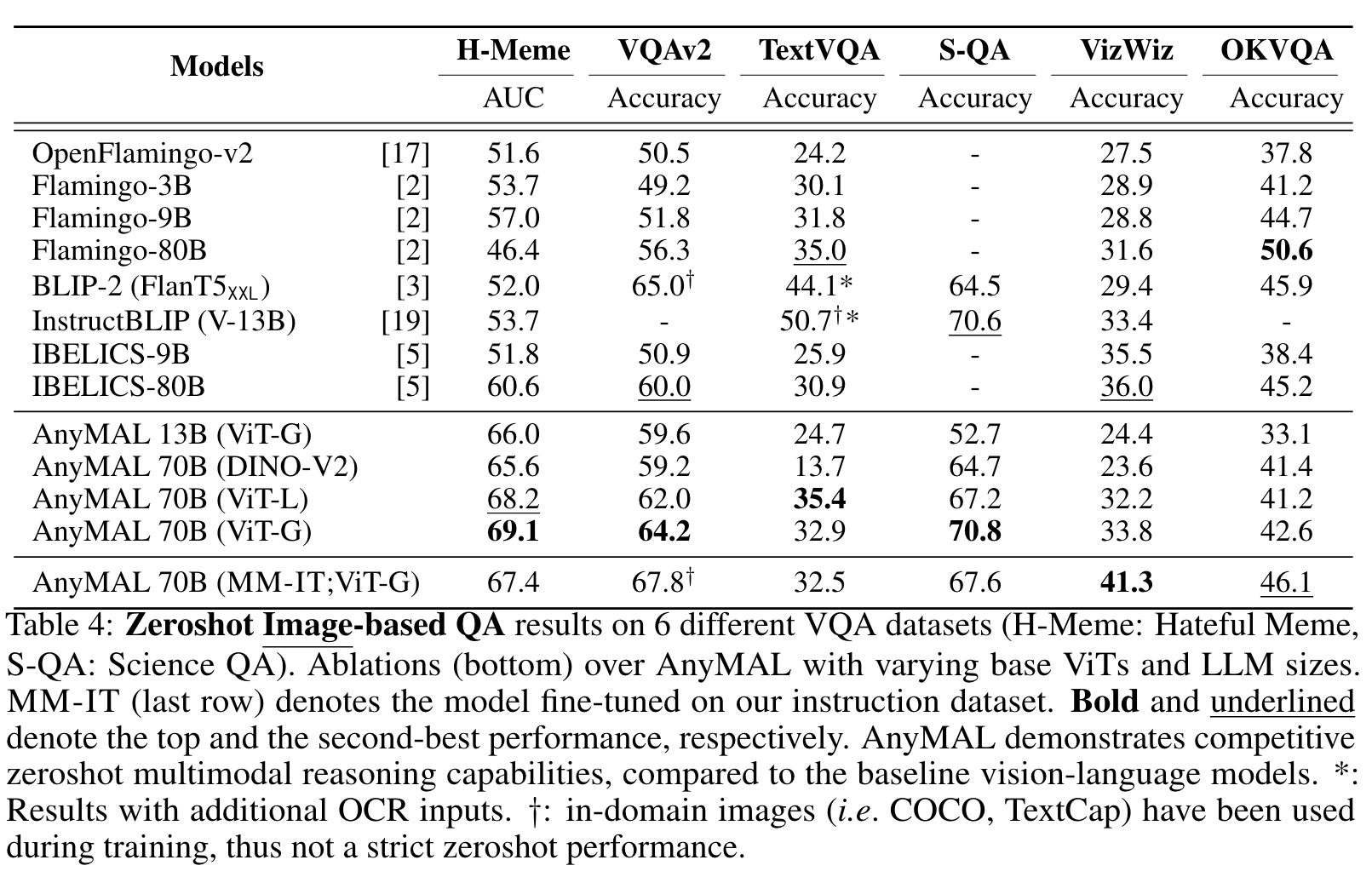
Image QA
Ablation Study
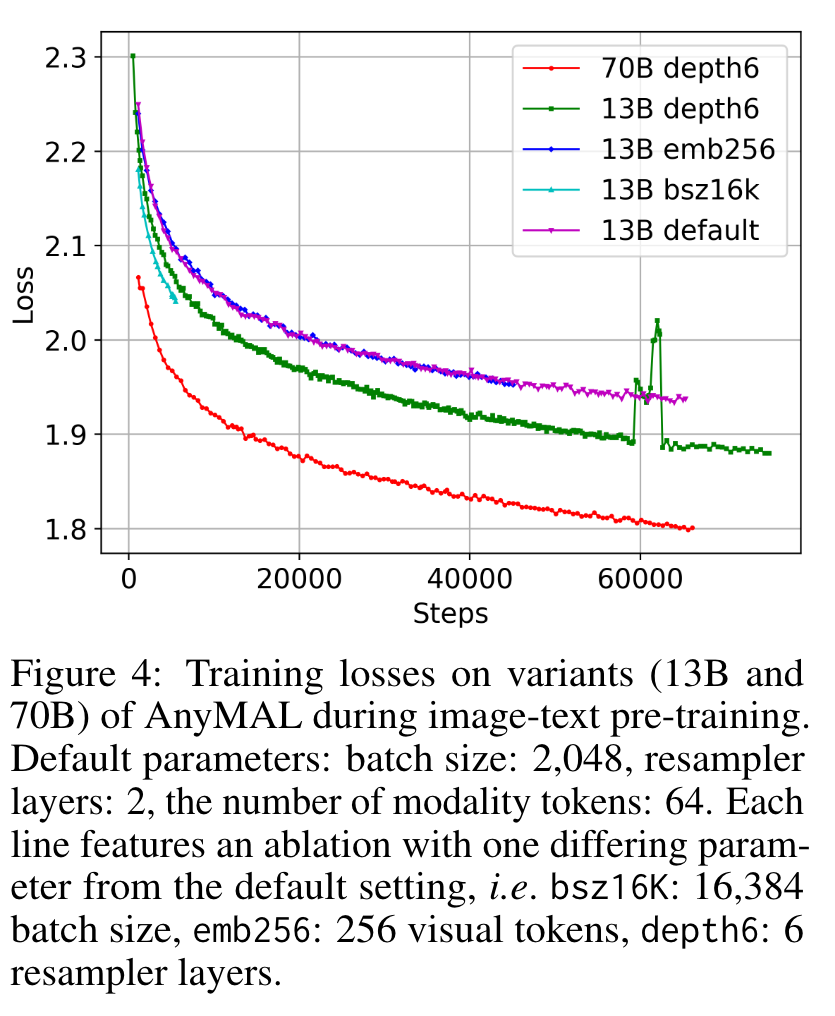
Ablations on Hyperparameters
Overall, we observed that increasing the batch size and the number of visual tokens yields minimal improvement. In contrast, increasing the number of resampling layers significantly reduces the loss without substantially increasing the training budget. (p. 10)
Effects of Scaling LLM Parameter Size (70B vs. 13B)
The 70B model demonstrates a reduced training loss overall when compared with the 13B versions. This loss performance also aligns with the downstream task results in Tables 2 and 4. We attribute this result to the inherent reasoning abilities and the knowledge assimilated within the 70B models, (p. 10)
Limitation
First, the proposed causal multimodal language modeling approach still encounters challenges in establishing a robust grounding with the input modality. Specifically, we observe that during the generation, the model occasionally prioritizes focusing more on the generated text rather than the input image. This leads to the generation of output that incorporates biases acquired from the underlying language model (LLM), which can incur inaccuracies when compared against the image context. We expect that additional architectural adjustments or unfreezing LLM parameters are necessary to address this limitation effectively (albeit the much higher computational costs it might entail). (p. 14)
Second, while we greatly increase the size of the pretraining dataset, the understanding of visual concepts and entities remains constrained by the quantity of paired image-text data included in the training process. In the domain of text-only language models, it is commonly observed that approaches incorporating external knowledge retrieval significantly enhance the model’s ability to overcome its knowledge limitations. These approaches offer a potential means to alleviate the limitations mentioned earlier. (p. 14)