Multimodality face animation model
[jali face-animation vatt face-tracking meshtalk faceformer avatar arvr avface Audio-vision modaility model could improve the quality of face tracking (in speech) as well the robustness (when face get occluded) over vision based solutions. This is my reading note on Audio-vision modaility face tracking.
MeshTalk
Meshtalk is a generic audio-driven facial animation approach that achieves highly realistic motion synthesis results for the entire face. At the core of our approach is a categorical latent space for facial animation that disentangles audio-correlated and audio-uncorrelated information based on a novel cross-modality loss.
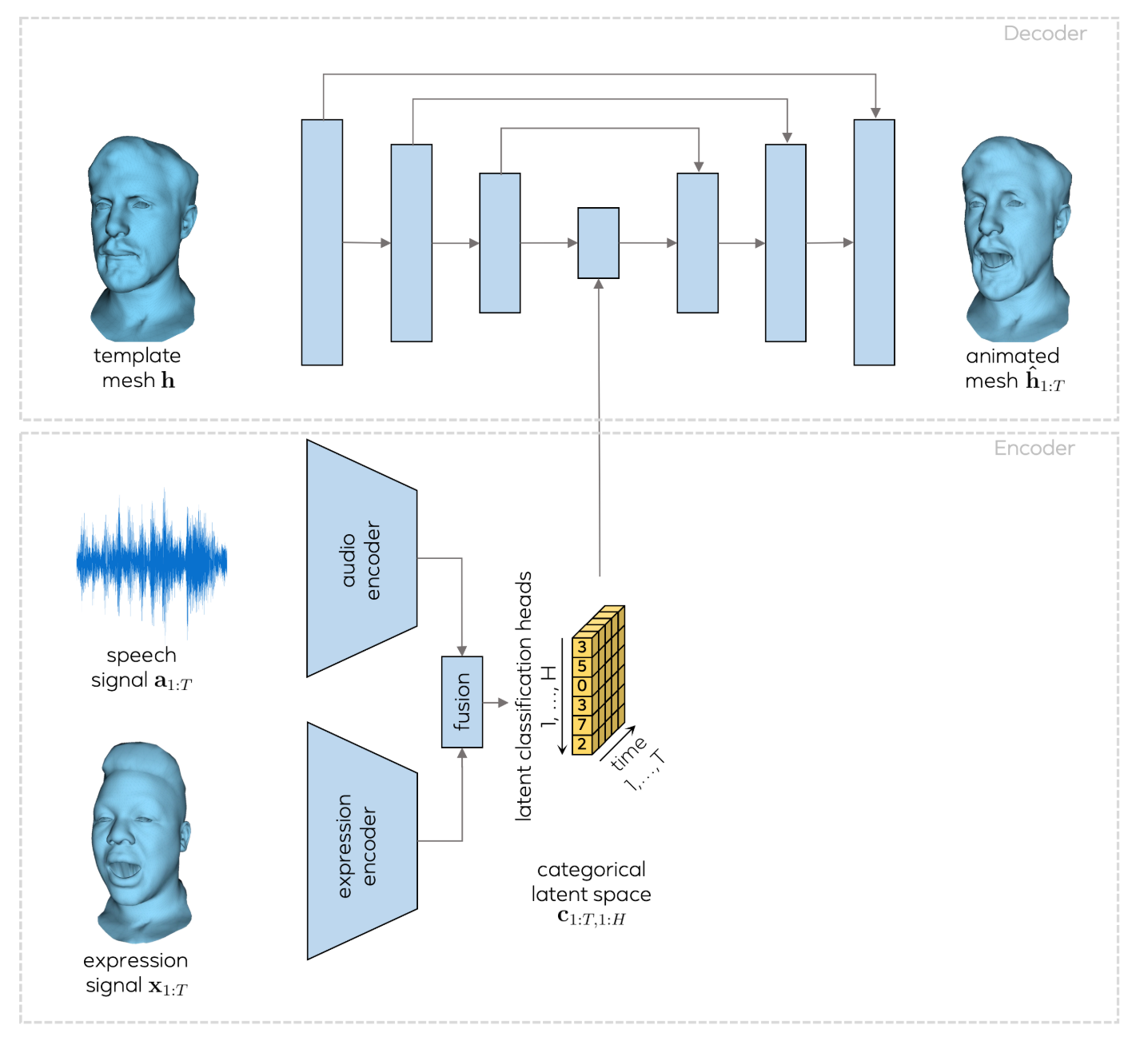 Figure 2. System overview. A sequence of animated face meshes (the expression signal) and a speech signal are mapped to a categorical latent expression space. A UNet-style decoder is then used to animate a given neutral-face template mesh according to the encoded expressions.
Figure 2. System overview. A sequence of animated face meshes (the expression signal) and a speech signal are mapped to a categorical latent expression space. A UNet-style decoder is then used to animate a given neutral-face template mesh according to the encoded expressions.
The audio encoder is a four-layer 1D temporal convolutional network similar to the one used in [26]. The expression encoder has three fully connected layers followed by a single LSTM layer to capture temporal dependencies. The fusion module is a three-layer MLP.
Cross Modality Loss
Existing approaches normally exhibit uncanny or static upper face animation [8]. The reason for this is that audio does not animation [8]. The reason for this is that audio does not encode all aspects of the facial expressions, thus the audio-encode all aspects of the facial expressions, thus the audio- driven facial animation problem tries to learn a one-to-many driven facial animation problem tries to learn a one-to-many mapping, i.e., there are multiple plausible outputs for every mapping, i.e., there are multiple plausible outputs for every input. This often leads to over-smoothed results, especially input.
In Meshtalk, the latent space is trained based on a novel cross-modality loss that encourages the based on a novel cross-modality loss that encourages the model to have an accurate upper face reconstruction inde-model to have an accurate upper face reconstruction inde- pendent of the audio input and accurate mouth area that only dependent of the audio input and accurate mouth area that only depends on the provided audio input. This disentangles the depends on the provided audio input. This disentangles the motion of the lower and upper face.
- Categorical. Most successful temporal models operate on categorical spaces [33, 32, 34]. In order to use such models, categorical spaces [33, 32, 34]. In order to use such models, the latent expression space should be categorical as well. the latent expression space should be categorical as well.
- Expressive. The latent space must be capable of encoding diverse facial expressions, including sparse events like eye diverse facial expressions, including sparse events like eye blinks.
- Semantically disentangled. Speech-correlated and speech- uncorrelated information should be at least partially disen-uncorrelated information should be at least partially disen- tangled, e.g., eye closure should not be bound to a specific tangled, e.g., eye closure should not be bound to a specific lip shape.
The cross modality loss could be written as: \(\ell_{xMOD}=\sum_{t=1}^T\sum_{v=1}^V M_v^{upper}(\lVert \hat{h}_{t,v}^{expr}-x_{t,v}\rVert_2^2)+M_v^{mouth}(\lVert \hat{h}_{t,v}^{audio}-x_{t,v}\rVert_2^2)\)
where M(upper) is a mask that assigns a high weight to ver- tices on the upper face and a low weight to vertices around vertices on the upper face and a low weight to vertices around the mouth. Similarly, M(mouth) assigns a high weight to ver-the mouth. Similarly, M(mouth) assigns a high weight to vertices around the mouth and a low weight to other vertices. vertices around the mouth and a low weight to other vertices.
The cross-modality loss encourages the model to have an accurate upper face reconstruction independent of the audio input and, accordingly, to have an accurate reconstruction of the mouth area based on audio independent of the expres- sion sequence that is provided. Since eye blinks are quick and sparse events that affect only a few vertices, we also found it crucial to emphasize the loss on the eye lid vertices during training.

Figure: the importance of the cross modality loss.
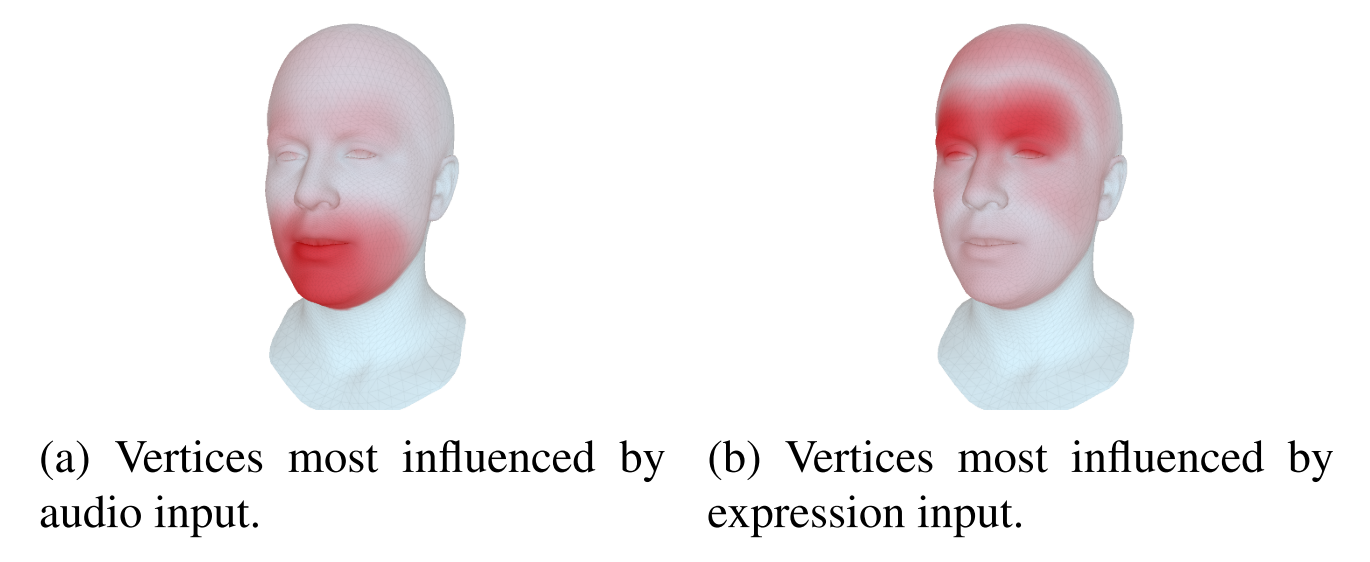 Figure 5. Impact of the audio and expression modalities on the generated face meshes. Audio steers primarily the mouth area but has also a visible impact on eyebrow motion. Expression meshes influence primarily the upper face parts including the eye lids.
Figure 5. Impact of the audio and expression modalities on the generated face meshes. Audio steers primarily the mouth area but has also a visible impact on eyebrow motion. Expression meshes influence primarily the upper face parts including the eye lids.
Audio-Conditioned Autoregressive Modeling
When driving a template mesh using audio input alone, the expression input x1:T is not available. With only one modality given, missing information that can not be inferred from audio has to be synthesized. Therefore, we learn an autoregressive temporal model over the categorical latent space. This model allows to sample a latent sequence that generates plausible expressions and is consistent with the audio input.
We model this quantity with an autore- gressive convolutional network similar to PixelCNN [33]. Our autoregressive temporal CNN has four convolutional layers with increasing dilation along the temporal axis.
Our audio data is recorded at 16kHz. For each tracked mesh, we compute the Mel spectrogram of a 600ms audio snippet starting 500ms before and end- ing 100ms after the respective visual frame. We extract 80- dimensional Mel spectral features every 10ms, using 1, 024 frequency bins and a window size of 800 for the underlying Fourier transform.
Meshtalk relies on audio inputs that extend 100ms beyond the respec- tive visual frame. This leads to an inherent latency of 100ms and prevents the use of our approach for online applications. Please note, this ‘look ahead’ is beneficial to achieve highest quality lip-sync, e.g., for sounds like ‘/p/’ the lip closure can be modeled better.
VATT
Video- Audio-Text Transformer (VATT) takes raw signals as inputs and extracts multi- modal representations that are rich enough to benefit a variety of downstream tasks. We train VATT end-to-end from scratch using multimodal contrastive losses and evaluate its performance by the downstream tasks of video action recognition, audio event classification, image classification, and text-to-video retrieval. Furthermore, we study a modality-agnostic, single-backbone Transformer by sharing weights among the three modalities.
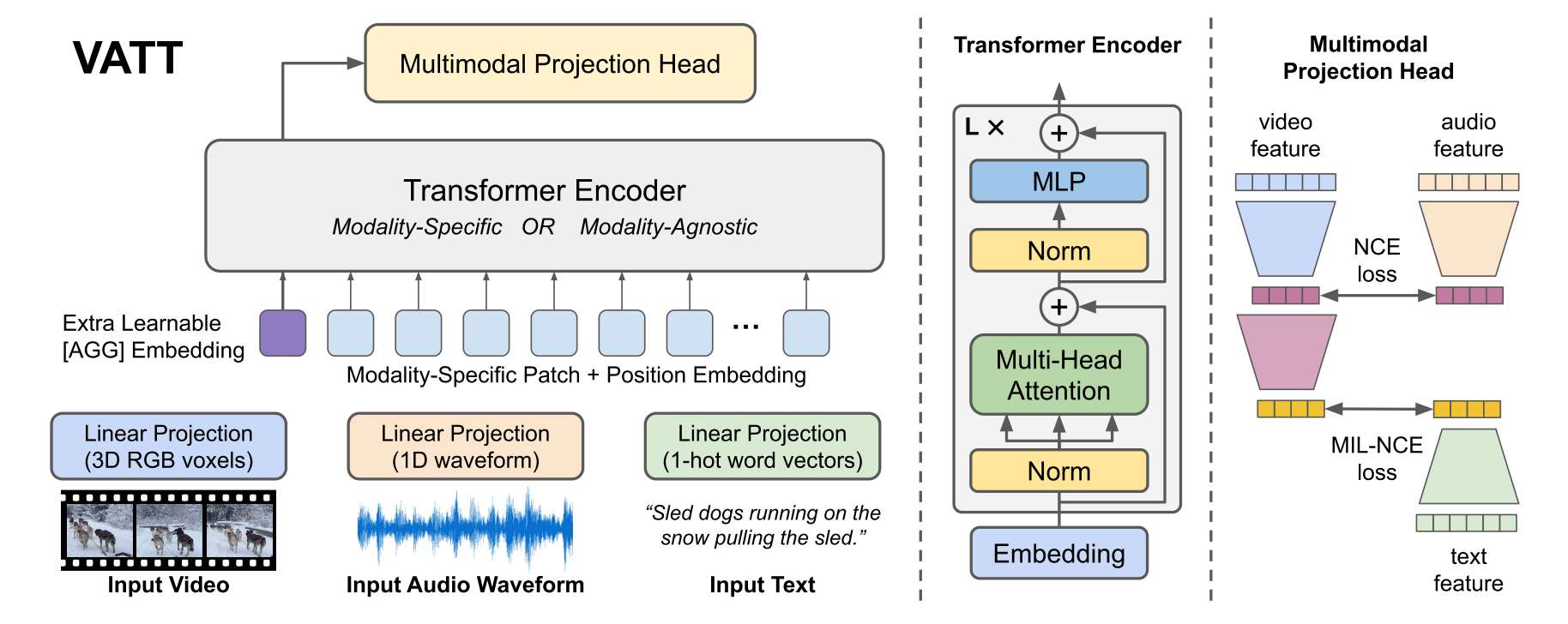 Figure 1: Overview of the VATT architecture and the self-supervised, multimodal learning strategy. VATT linearly projects each modality into a feature vector and feeds it into a Transformer encoder. We define a semantically hierarchical common space to account for the granularity of different modalities and employ the Noise Contrastive Estimation (NCE) to train the model.
Figure 1: Overview of the VATT architecture and the self-supervised, multimodal learning strategy. VATT linearly projects each modality into a feature vector and feeds it into a Transformer encoder. We define a semantically hierarchical common space to account for the granularity of different modalities and employ the Noise Contrastive Estimation (NCE) to train the model.
Tokenization and Positional Coding
VATT operates on raw signals. The vision-modality input consists of 3-channel RGB pixels of video frames, the audio input is in the form of air density amplitudes (waveforms), and the text input is a sequence of words. We first define a modality-specific tokenization layer that takes as input the raw signals and returns a sequence of vectors to be fed to the Transformers. Besides, each modality has its own positional encoding, which injects the order of tokens into Transformers [88].
The raw audio waveform is a 1D input with length T’, and we partition it to [T’/t’] segments each containing t’ waveform amplitudes. Similar to video, we apply a linear projection with a learnable weight $W_{ap}\in\mathbb{R}^{v\times d}$ to all elements in a patch to get a d-dimensional vector representation.
Once we get the token sequence for the video or audio modality, we randomly sample a portion of the tokens and then feed the sampled sequence, not the complete set of tokens, to the Transformer. This is crucial for reducing the computational cost because a Transformer’s computation complexity is quadratic, O(N2), where N is number of tokens in the input sequence.
Architecture
we adopt the most established Transformer architecture [23], which has been widely used in NLP. We use common space projection and contrastive learning in that common space to train our networks. More specifically, given a video-audio-text triplet, we define a semantically hierarchical common space mapping that enables us to directly compare video-audio pairs as well as video-text pairs by the cosine similarity.
we use Noise Contrastive Estimation (NCE) to align video-audio pairs and Multiple Instance Learning NCE (MIL-NCE) to align video-text pairs. The pairs are composed from different temporal locations in the video-audio-text stream. Positive pairs from two modalities are constructed by sampling their corresponding streams from the same location in the video, and negative pairs are constructed by sampling from any non-matching locations in the video.
FaceFormer
we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased cross-modal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy.
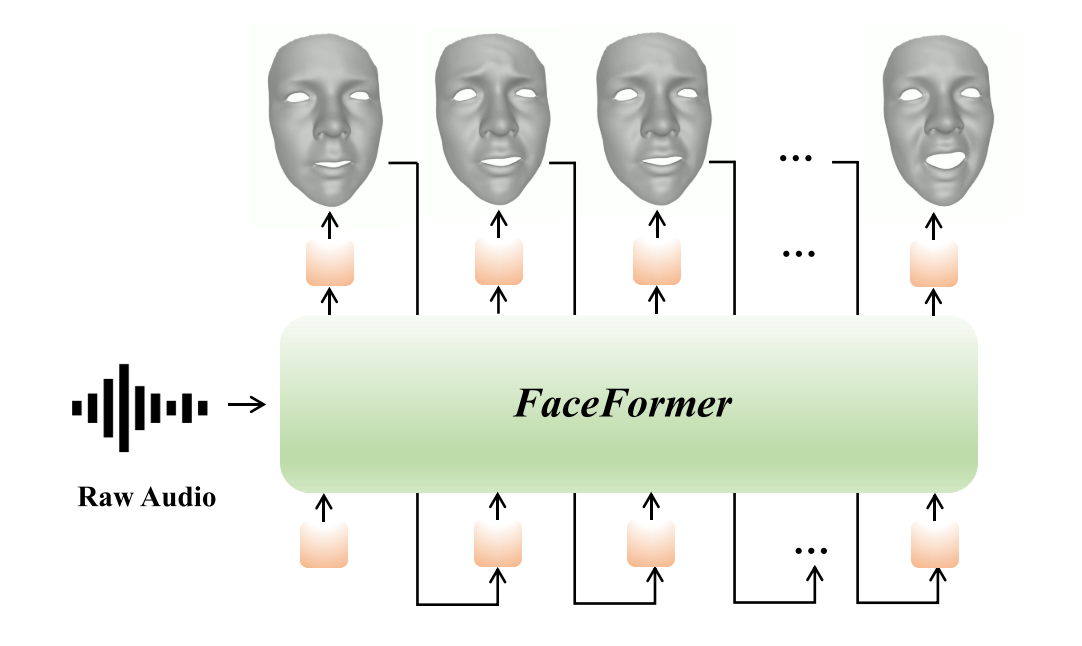 Figure 1. Concept diagram of FaceFormer. Given the raw au- dio input and a neutral 3D face mesh, our proposed end-to-end Transformer-based architecture, dubbed FaceFormer, can autore- gressively synthesize a sequence of realistic 3D facial motions with accurate lip movements.
Figure 1. Concept diagram of FaceFormer. Given the raw au- dio input and a neutral 3D face mesh, our proposed end-to-end Transformer-based architecture, dubbed FaceFormer, can autore- gressively synthesize a sequence of realistic 3D facial motions with accurate lip movements.
The major contributions of this paper are:
- Given the limited availability of 3D audio-visual data, we explore the use of the self-supervised pre-trained speech model wav2vec 2.0
- the default encoder-decoder attention of transformer can not handle modality alignment, and thus we add an alignment bias for audio-motion alignment.
- transformer with the sinusoidal position encoding has weak abilities to generalize to sequence lengths longer than the ones seen during training [19, 50]. Inspired by Attention with Linear Biases (ALiBi) [50], we add a temporal bias to the query-key attention score and design a periodic positional encoding strategy to improve the model’s generalization ability to longer audio sequences.
Architecture
The design of our FaceFormer encoder follows the state-of-the-art self-supervised pre-trained speech model, wav2vec 2.0 [2]. Specifically, the encoder is composed of an audio feature extractor and a multi-layer transformer encoder [58]. The audio feature extractor, which consists of several temporal convolutions layers (TCN), transforms the raw waveform input into feature vectors with frequency $f_a$.
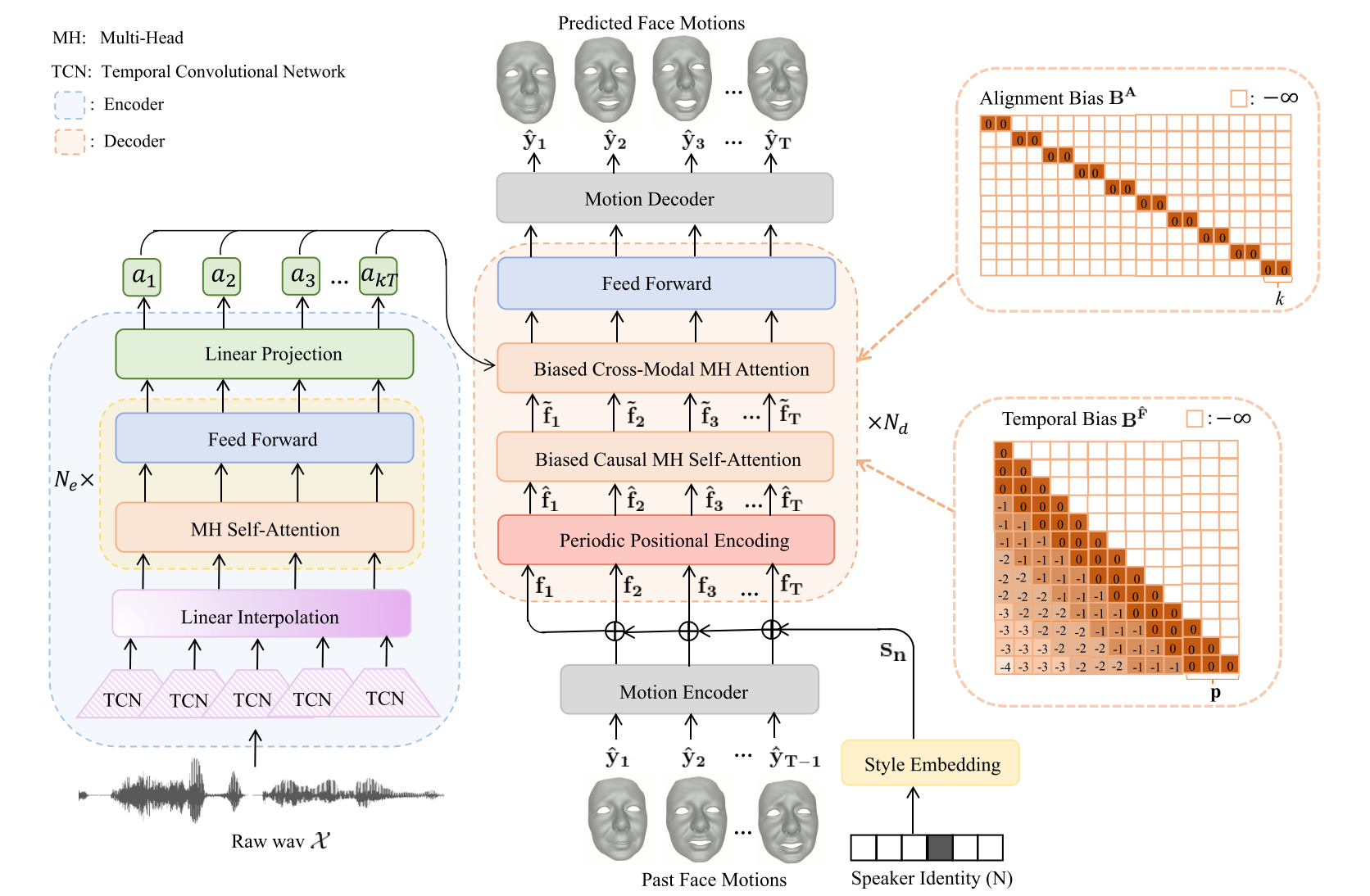 Figure 2. Overview of FaceFormer. An encoder-decoder model with Transformer architecture takes raw audio as input and autore- gressively generates a sequence of animated 3D face meshes. Layer normalizations and residual connections are omitted for simplicity. The overall design of the FaceFormer encoder follows wav2vec 2.0 [2]. In addition, a linear interpolation layer is added after TCN for resampling the audio features. We initialize the encoder with the corresponding pre-trained wav2vec 2.0 weights. The FaceFormer de- coder consists of two main modules: a biased causal MH self-attention with a periodic positional encoding for generalizing to longer input sequences, and a biased cross-modal multi-head (MH) attention for aligning audio-motion modalities. During training, the parameters of TCN are fixed, whereas the other parts of the model are learnable.
Figure 2. Overview of FaceFormer. An encoder-decoder model with Transformer architecture takes raw audio as input and autore- gressively generates a sequence of animated 3D face meshes. Layer normalizations and residual connections are omitted for simplicity. The overall design of the FaceFormer encoder follows wav2vec 2.0 [2]. In addition, a linear interpolation layer is added after TCN for resampling the audio features. We initialize the encoder with the corresponding pre-trained wav2vec 2.0 weights. The FaceFormer de- coder consists of two main modules: a biased causal MH self-attention with a periodic positional encoding for generalizing to longer input sequences, and a biased cross-modal multi-head (MH) attention for aligning audio-motion modalities. During training, the parameters of TCN are fixed, whereas the other parts of the model are learnable.
To learn the dependencies between each frame in the context of the past facial motion sequence, a weighted con- textual representation is calculated by performing the scaled dot-product attention: \(Att(Q^F,K^F,V^F,B^F)=\text{softmax}(\frac{Q^F(K^F)^T}{\sqrt{d_k}}+B^F)V^F\) where $B^F$ is the temporal bias we add to ensure causality and to improve the ability to generalize to longer sequences.
The biased cross-modal multi-head attention aims to com- bine the outputs of Faceformer encoder (speech features) and biased causal MH self-attention (motion features) to align the audio and motion modalities. \(Att(Q^F,K^A,V^A,B^A)=\text{softmax}(\frac{Q^F(K^A)^T}{\sqrt{d_k}}+B^A)V^A\) The alignment bias $B^A (1 \leq i \leq t, 1 \leq j \leq kT)$ is represented as: \(B^A(i,j)=\begin{cases} 0 & \text{ if } ki\leq j\leq k(i+1) \\ -\infty & \text{ otherwise } \end{cases}\)
Ablation Study
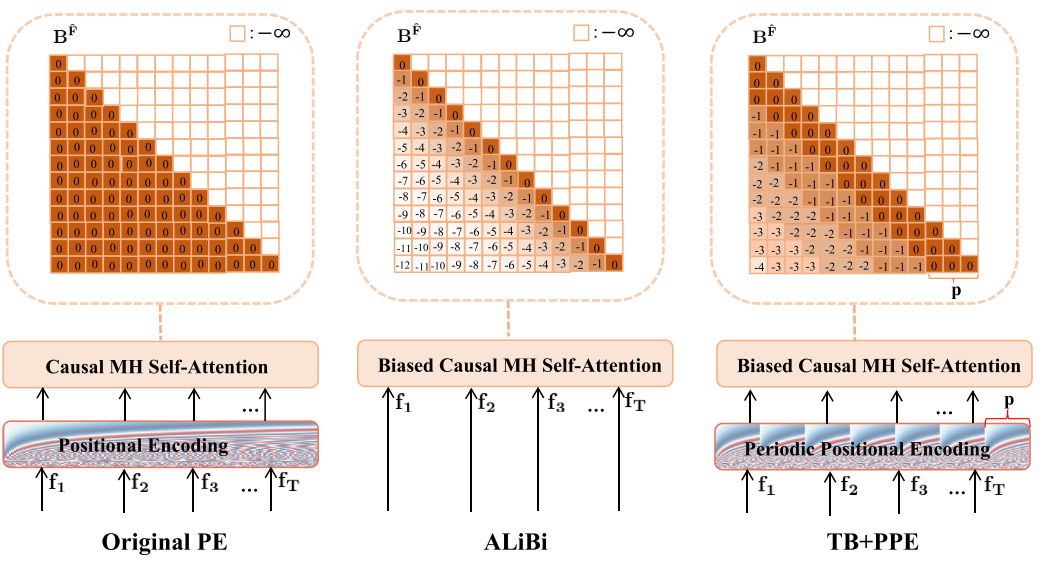 Figure 4. Illustration of different positional encoding strategies.
Figure 4. Illustration of different positional encoding strategies.
The model without the alignment bias (denoted as “FaceFormer w/o AB”) tends to generate muted facial expressions across all frames.
The results show “Original PE” can still produce well-synchronized mouth motions with proper lip closures, yet has a temporal jitter effect around the lips during silent frames, especially as the test audio sequence exceeds the average length of training audio sequences.