Tag: vatt
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
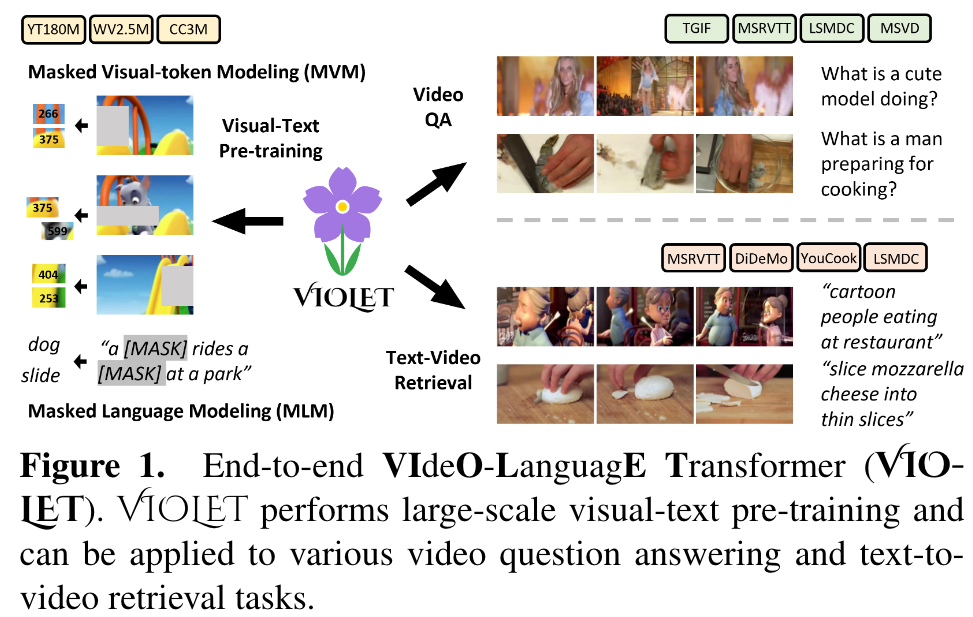
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- Multimodality face animation model (26 Dec 2022)
Audio-vision modaility model could improve the quality of face tracking (in speech) as well the robustness (when face get occluded) over vision based solutions. This is my reading note on Audio-vision modaility face tracking.