AutoMix Automatically Mixing Language Models
[verification auto-mix llm deep-learning few-shot-learning This is my reading note for AutoMix: Automatically Mixing Language Models. Thy paper posses a verifier to verity the correctness of answer of small model and decide whether need to redirect the question to a larger model.
Introduction
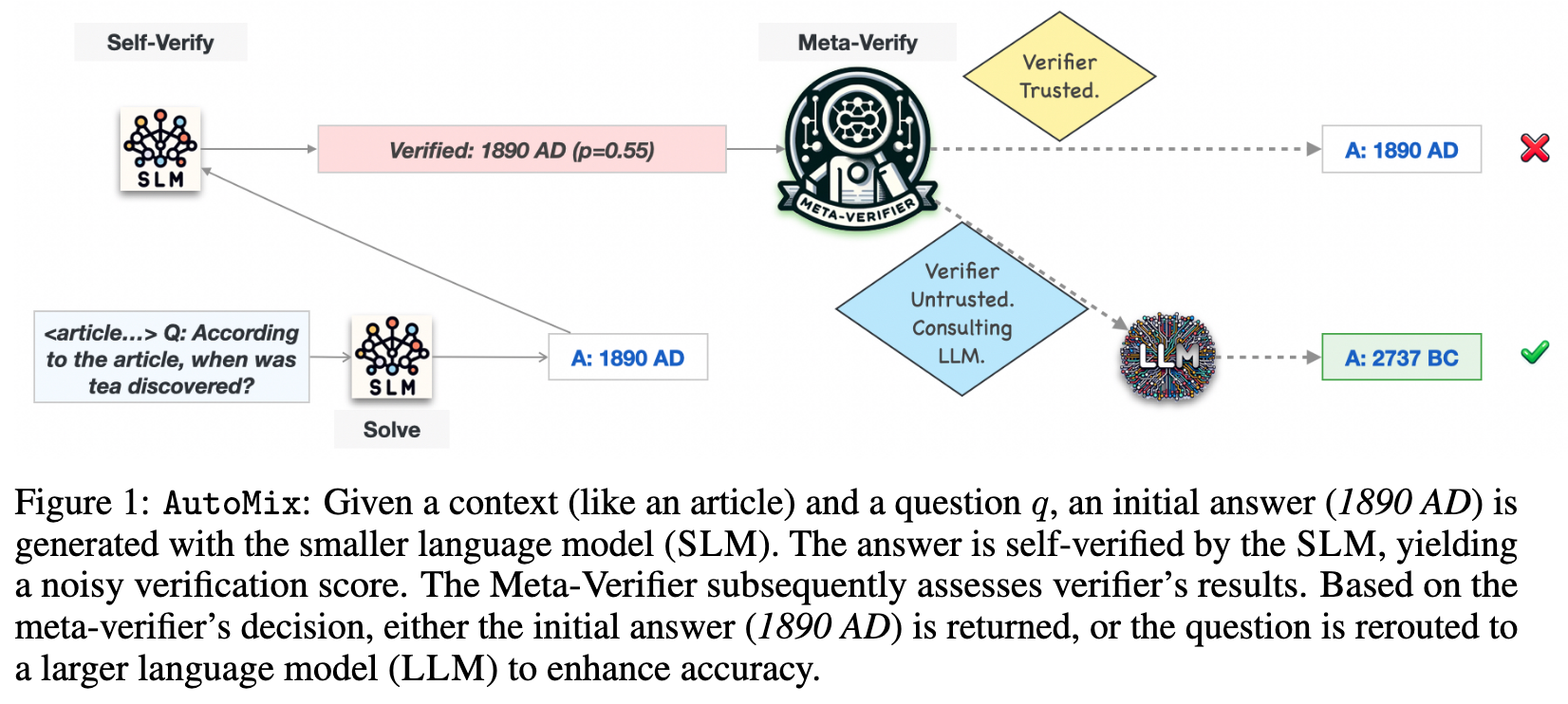
In this work, we present AutoMix, an approach that strategically routes queries to larger LMs, based on the approximate correctness of outputs from a smaller LM. Central to AutoMix is a few-shot self-verification mechanism, which estimates the reliability of its own outputs without requiring training. Given that verifications can be noisy, we employ a meta verifier in AutoMix to refine the accuracy of these assessments (p. 1)
Human problem-solving inherently follows a multi-step process: generate a solution, verify its validity, and refine it further based on verification outcomes (p. 1)
However, modern LLM often provide access solely through black-box APIs, restricting direct model optimization and adaptability due to the unavailability of fine-tuning capabilities and weight access. In response to this, we introduce AutoMix, a method that utilizes black-box LLM APIs, circumventing the necessity for separate models or logits access by adopting few-shot learning strategies (Brown et al., 2020) and implementing self-verification. Our method proposes strategies for each step of problem-solving: solution generation, verification, and routing, all assuming we only have access to black-box LLMs (p. 1)
AutoMix integrates a third category of Unsolvable queries. These queries are likely unsolvable even by a Large Language Model (LLM) and should not be routed to larger models if identified early. This consideration allows AutoMix to judiciously allocate computational resources, preventing unwarranted computational spending on these particularly challenging instances. (p. 2)
AutoMix: Few-shot Self-Verification and Meta-Verification
Task and setup
We tackle the problem of context-grounded question answering, where given a context C (e.g., stories, newswire, or research article) and a question q, the model is tasked with generating an accurate and coherent answer, consistent with the provided context. Our choice of tasks is motivated by two key concerns: (1) longer queries are more computationally demanding, underscoring the need for an approach like AutoMix to navigate the cost-accuracy trade-off, and (2) the context allows for cross-checking preliminary answers with available information using self-verification (described shortly), aiding in identifying inconsistencies as ungrounded is challenging (p. 2)
Few-shot Verification
To assess the trustworthiness of As, we employ a few-shot verifier, V, which ascertains the validity of SLM’s outputs and decides if a query should be redirected to LLM. Verification is framed as an entailment task (Poliak, 2020; Dagan et al., 2022), aiming to determine if the answer generated by SLM aligns with the provided context. (p. 3)
Meta-verifier

Given the potential inconsistency or noise in verifier outcomes, a secondary evaluation mechanism, which we term the meta-verifier, is crucial to vet the verifier’s conclusions. In particular, the verifier is tasked with determining whether the SLM’s answer is entailed by the context, and this decision is made without considering the inherent difficulty of the problem. Notably, routing Unsolvable queries to the LLM is resource-inefficient and does not enhance performance. While ascertaining the ground truth of query difficulty is non-trivial, verification probability and trends from historical data inferred using validation set, can provide insightful guidance. Formally, we define the meta-verifier’s outputs as m(v, As, C, q) → {0, 1}, where m = 1 implies the verifier’s output can be trusted. (p. 3)
Addressing the notable challenges of self-correction in large language models (Madaan et al., 2023; Huang et al., 2023), our method employs a non-LLM setup for meta-verification to avoid escalating issues like hallucination and reasoning errors (Dziri et al., 2023). The versatile meta-verifier can adopt various advanced learning strategies, from supervised to reinforcement learning, explored further in upcoming sections. (p. 3)
Thresholding
For black-box language models, the probability of correctness can be derived by sampling k > 1 samples at a higher sampling temperature. (p. 3)
Using a POMDP

Since the ground truth state, i.e category of query, is not known and unobserved, we formulate this decision problem as a Partially Observable Markov Decision Process (POMDP) (Monahan, 1982). POMDP presents a robust framework, offering a structured way to manage and navigate through the decision spaces where the system’s state is not fully observable. A POMDP is defined by a tuple (S, A, T, R, Ω, O), where S is a set of states, A is a set of actions, T represents the state transition probabilities, R is the reward function, Ω is a set of observations, and O is the observation function. (p. 4)
In our scenario, the states S correspond to the three question categories: Simple, Complex, and Unsolvable. Actions are denoted as either reporting the SLM answer or routing to the LLM. Observations, in the form of verifier output v, enable the POMDP to ascertain its belief state, which is a probability distribution over S. (p. 4)
Another advantage of the POMDP-based meta-verifier is its interpretability and customizability via reward assignment. For instance, in a Complex state, assigning a very high reward of +50 for invoking the LLM indicates a preference for accurate solutions over computational cost. (p. 4)
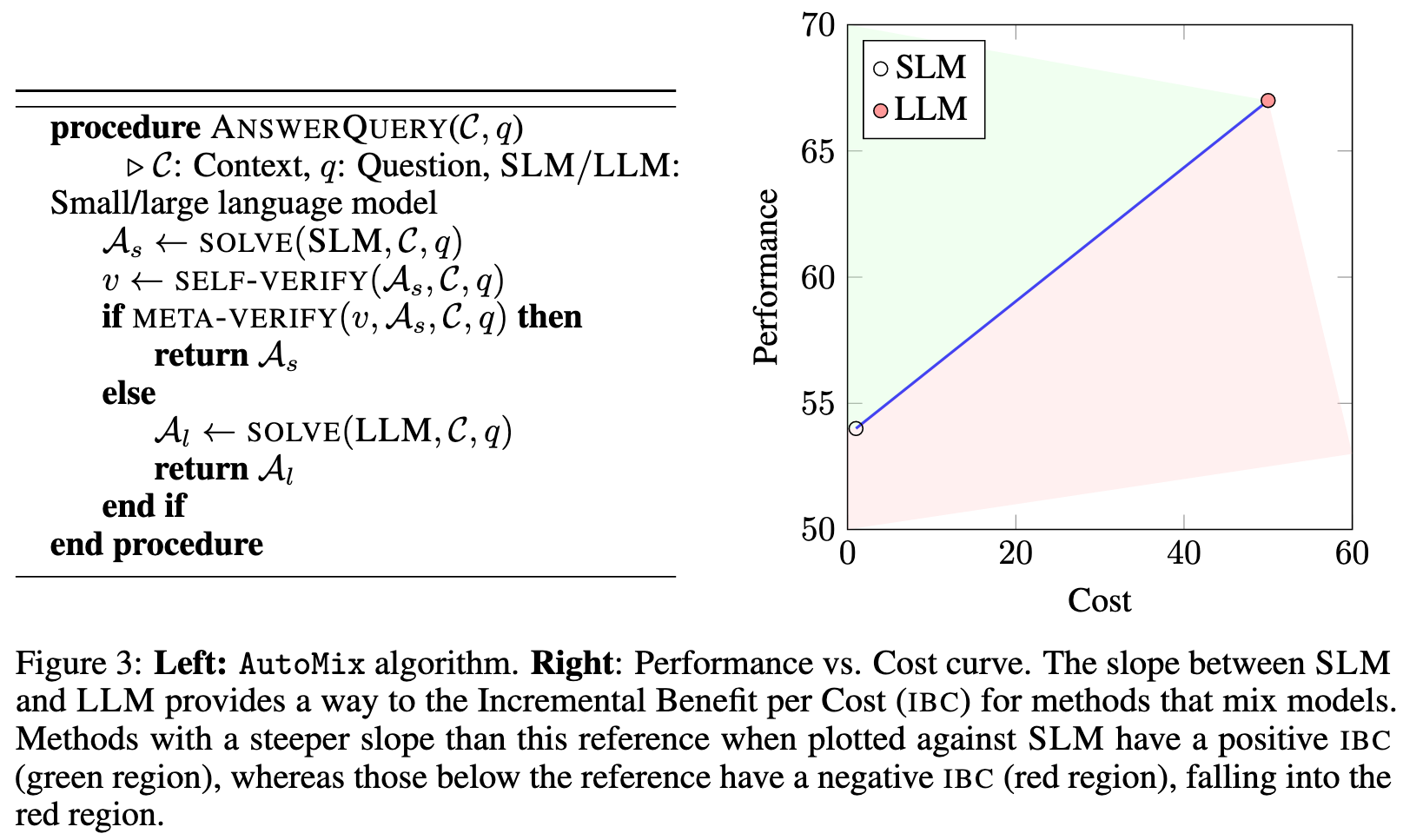
Cost-Performance Efficiency Analysis
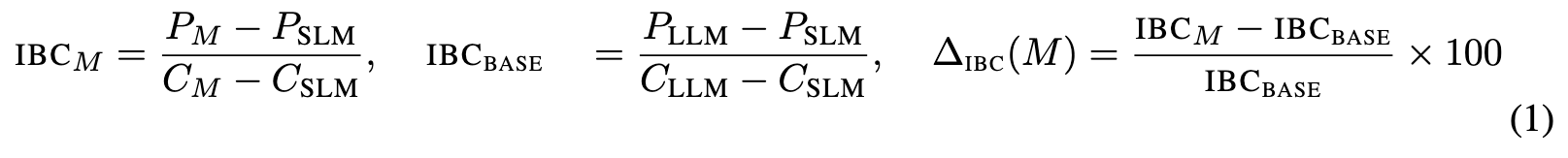
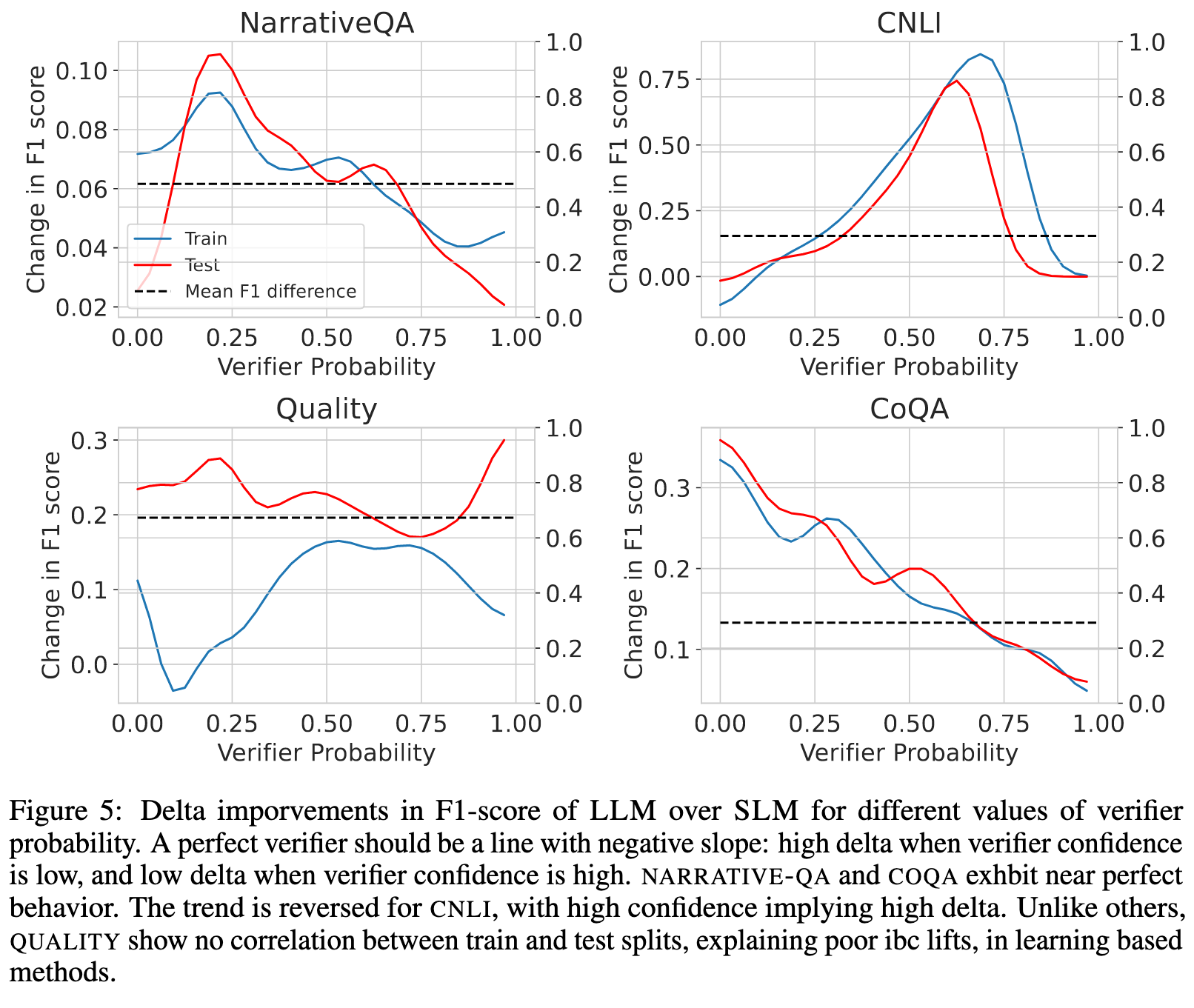
When and Why does meta-verification help?
Ideally, points with a high ∆PLLM−SLM should be directed to LLM, as they result in significant gains in F1 score. Consequently, a well-calibrated verifier is expected to exhibit a decreasing linear trend: assign higher confidence to points where the gains from using a LLM are lower. However, this expected behavior is only observed in the NARRATIVE-QA and COQA datasets. In such scenarios, the necessity for a robust meta-verifier is reduced as raw outputs from the verifier can be trusted. As a result, self-verification performs well out-of-the-box with simple techniques such as self-consistency and thresholding (p. 7)
When does AutoMix not work?
Analyzing the relatively poor performance of all methods on QUALITY, we find a substantial distribution shift between the training and testing splits for the QUALITY dataset in Figure 5. Consequently, AutoMix +POMDP overfits a policy on the training set, which fails to generalize to the test set, resulting in a performance that is inferior to AutoMix +SC (p. 7)