AVIS Autonomous Visual Information Seeking with Large Language Models
[multimodal llm deep-learning bad tool This is my reading note on AVIS Autonomous Visual Information Seeking with Large Language Models. The paper proposes a method on how to use L lm to use tools or APIs to solve different visual questions. The biggest contribution is this page collect how seal human uses the same set of tools and APIs to solve different visual question. The collected data generates a translation graph between states and action to take.
Introduction
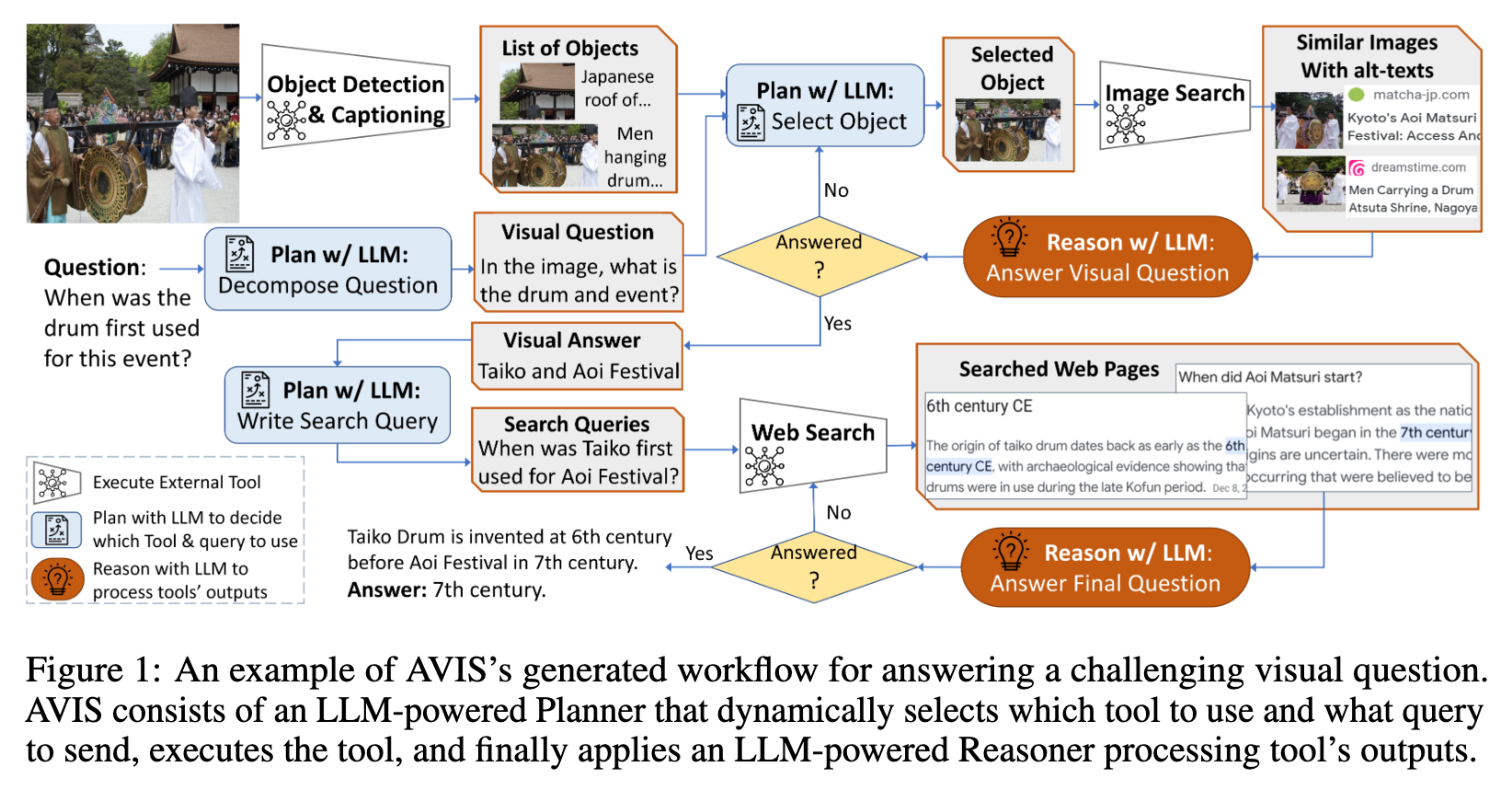
In this paper, we propose an autonomous information seeking visual question answering framework, AVIS. Our method leverages a Large Language Model (LLM) to dynamically strategize the utilization of external tools and to investigate their outputs, thereby acquiring the indispensable knowledge needed to provide answers to the posed questions (p. 1)
Current state-of-the-art vision-language models (VLMs) find it challenging to answer such questions for several reasons. Firstly, they are not trained with objectives that encourage them to discern fine-grained categories and details within images. Secondly, they utilize a relatively smaller language model compared to state-of-the-art Large Language Models (LLMs), which constrains their reasoning capabilities. Lastly, they do not compare the query image against a substantial corpus of images associated with varying metadata, unlike systems that employ image search techniques. (p. 2)
To overcome these challenges, we introduce a novel method in this paper that achieves state-of-the- art results on visual information seeking tasks by integrating LLMs with three types of tools: (i) computer vision tools such as object detection, OCR, image captioning models, and VQA models, which aid in extracting visual information from the image, (ii) a web search tool that assists in retrieving open world knowledge and facts, and (iii) an image search tool that enables us to glean relevant information from metadata associated with visually similar images. Our approach utilizes an LLM-powered planner to dynamically determine which tool to use at each step and what query to send to it. Furthermore, we employ an LLM-powered reasoner that scrutinizes the output returned by the tools and extracts the crucial information from them. To retain the information throughout the process, we use a working memory component. (p. 2)
While this method has shown potential in elementary visual-language tasks, it frequently fails in more complex real-world situations. In such cases, a comprehensive plan cannot be inferred merely from the initial question. Instead, it necessitates dynamic modifications based on real-time feedback. (p. 2)
The primary innovation in our proposed method lies in its dynamic decision-making capability. Answering visual information seeking questions is a highly complex task, requiring the planner to take multiple steps. At each of these steps, the planner must determine which API to call and what query to send. It is unable to predict the output of complex APIs, such as image search, or to anticipate the usefulness of their responses prior to calling them. Therefore, unlike previous methods that pre-plan the steps and API calls at the beginning of the process, we opt for a dynamic approach. We make decisions at each step based on the information acquired from previous API calls, enhancing the adaptability and effectiveness of our method. (p. 3)
The collected user behavior informs our system in two significant ways. First, by analyzing the sequence of user decisions, we construct a transition graph. This graph delineates distinct states and constrains the set of actions available at each state. Second, we use the examples of user decision-making to guide our planner and reasoner with pertinent contextual instances. These contextual examples contribute to improving the performance and effectiveness of our system. (p. 3)
Related Work
Augmenting LLMs with Tool
Such limitations include providing up-to-date answers based on external knowledge or performing mathematical reasoning. Consequently, a recent surge of techniques have integrated LLMs with various external tools [27]. For example, TALM [31] and ToolFormer [35] use in-context learning to teach the language model how to better leverage various tools on benchmarks such as question answering and mathematical reasoning. In the computer vision domain, LLMs also show significant improvements when combined with external visual tools. For example, Visual ChatGPT [40] and MM-ReAct [42] enable LLMs to call various vision foundation models as tools to understand visual inputs, and even better control the image generation. VisProg [13] and ViperGPT [36] explore the decomposition of visual language tasks into programs, where each line corresponds to general code or a visual API. Chameleon [23] uses an LLM as a natural language planner to infer the appropriate sequence of tools to utilize, and then executes these tools to generate the final response. (p. 3)
Most of these previous works follow a plan-then-execute paradigm, i.e., i) they pre-plan the sequence of actions (API calls) that they will take (either hard coded or using code generation); and ii) they execute the generated plan. One drawback of such an approach is that it cannot update and improve its plan based on the output of the tools it calls. This is not a trivial problem, as it requires to predict the output quality of each tools beforehand. In contrast, our proposed method allows the system to dynamically decide its next steps based on the output it receives from the tools at each step. (p. 3)
Decision Making with LLM as an Agent
There has also been a surge of interest in applying Large Language Models (LLMs) as autonomous agents. These agents are capable of interacting with external environments, making dynamic decisions based on real-time feedback, and consequently achieving specific goals. For example, WebGPT [28] enables an LLM to access real-time information from the web search engines. ReAct [43] further improves external search engine usage via the self- reasoning of LLM in an interleaved manner. Similar ideas have also been adopted for robotic action planning. SayCan [3], for instance, uses LLMs to directly predict robot actions, and PALM-E [10] further fine-tunes LLMs to make better decisions based on instructions and open web media. (p. 3)
When compared to works that follow a plan-then-execute paradigm, these AI agents exhibit increased flexibility, adjusting their actions based on the feedback that they receive. However, many of these methods do not restrict the potential tools that can be invoked at each stage, leading to an immense search space. This becomes particularly critical for web search APIs [1, 2] that return extensive result lists and span a combinatorial search space of multiple tools. Consequently, even the most advanced LLMs today can fall into infinite loops or propagate errors. To alleviate this issue, we propose restricting and guiding LLMs to mimic human behavior when solving complex visual questions with APIs. This idea is similar to the AI alignment research [30, 21] that teaches LLMs to follow human instructions. The difference is that our model only uses the human prior at the decision-making stage via prompt guidance, instead of re-training the model. (p. 4)
Proposed Method
Our approach employs a dynamic decision-making strategy designed to respond to visual information- seeking queries. Our system is comprised of three primary components. First, we have a planner P, whose responsibility is to determine the subsequent action, including the appropriate API call and the query it needs to process. Second, we have a working memory M that retains information about the results obtained from API executions. Lastly, we have a reasoner R, whose role is to process the outputs from the API calls. It determines whether the obtained information is sufficient to produce the final response, or if additional data retrieval is required. (p. 4)

Next, it collects a set of relevant in-context examples Es that are assembled from the decisions previously made by humans during the user study relevant to actions As, that is Es ← θ(E, As). With the gathered in-context examples Es and the working memory M that holds data collected from past tool interactions, the planner formulates a prompt, denoted by ps ← ψ(Es,M). The prompt ps is then sent to the LLM which returns a structured answer, determining the next tool ts to be activated and the query qs to be dispatched to it. We (p. 4)
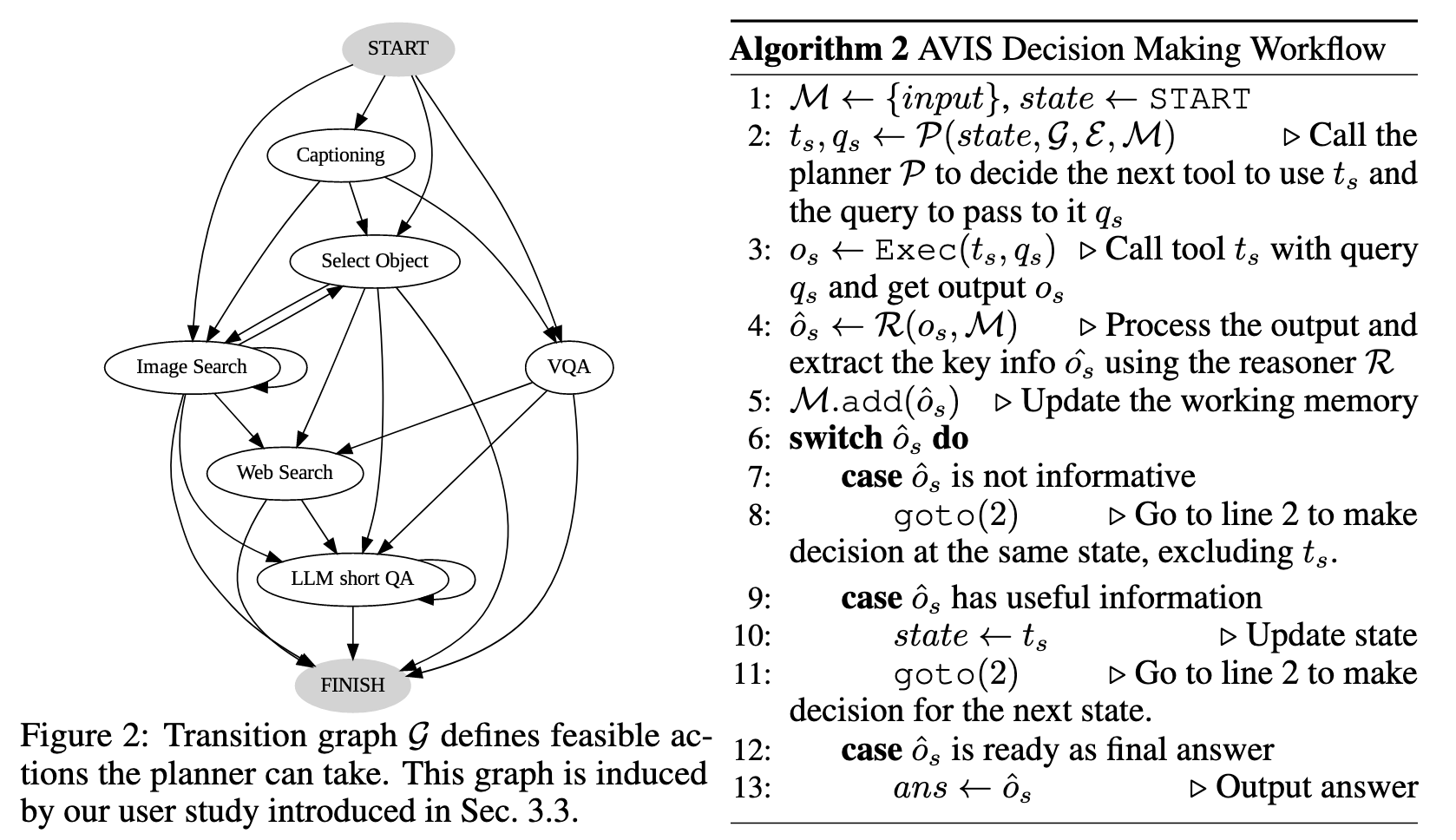
Therefore, we employ a reasoner R to analyze the output os, extract the useful information and decide into which category the tool output falls: informative, uninformative, or final answer. Our method utilizes the LLM with appropriate prompting and in-context examples to perform the reasoning. If the reasoner concludes that it’s ready to provide an answer, it will output the final response, thus concluding the task. If it determines that the tool output is uninformative, it will revert back to the planner to select another action based on the current state. If it finds the tool output to be useful, it will modify the state and transfer control back to the planner to make a new decision at the new state. (p. 5)
Gathering User Behavior to Inform LLM Decision Making

One of the significant contributions of this paper lies in the use of a transition graph, synthesized from an authentic user study. (p. 13)

Experiment