Blended Latent Diffusion
[deep-learining diffusion blended-diffusion sdedit gan variational-auto-encoder glide dall-e2 style-gan palette vae image2image paint-by-words This is my reading note for Blended Latent Diffusion. The major innovation of the paper is to apply mask in latent space instead of image space to reduce boundary inconsistency, as the foreground is generated from the VAE but the background is not. in addition to handle the thin detail of mask got lost due to downs sample step, it dilate the mask first.

Introduction
Our solution leverages a text-to-image Latent Diffusion Model (LDM), which speeds up diffusion by operating in a lower-dimensional latent space and eliminating the need for resource-intensive CLIP gradient calculations at each diffusion step. (p. 1)
We know of only three methods to date that explicitly address the local editing scenario: Blended Diffusion [Avrahami et al. 2022b], GLIDE [Nichol et al. 2021] and DALL·E 2 [Ramesh et al. 2022]. Among these, only Blended Diffusion is publicly available in full. (p. 2) %%Dall E2:vit+clip%%
Some recent works have thus proposed to perform the diffusion in a latent space with lower dimensions and higher-level semantics, compared to pixels, yielding competitive performance on various tasks with much lower training and inference times. (p. 2)
Next, we address the imperfect reconstruction inherent to LDM, due to the use of VAE-based lossy latent encodings. This is especially problematic when the original image contains areas to which human perception is particularly sensitive (e.g., faces or text) or other non-random high frequency details. We present an approach that employs latent optimization to effectively mitigate this issue. To overcome this issue, we propose a solution that starts with a dilated mask, and gradually shrinks it as the diffusion process progresses. (p. 2)
RELATED WORK
Text-to-image synthesis and global editing
DALL·E [Ramesh et al. 2021] proposed a two-stage approach: first, train a discrete VAE [Razavi et al. 2019; van den Oord et al. 2017] to learn a rich semantic context, then train a transformer model to autoregressively model the joint distribution over the text and image tokens. (p. 2)
Palette [Saharia et al. 2022a] trains a designated diffusion model to perform four image-to-image translation tasks, namely colorization, inpainting, uncropping, and JPEG restoration. SDEdit [Meng et al. 2021] demonstrates stroke painting to image, image compositing, and stroke-based editing. RePaint [Lugmayr et al. 2022] uses a diffusion model for free-form inpainting of images. None of the above methods tackle the problem of local text-driven image editing. (p. 2)
Local text-guided image manipulation
paint-by-words first to address the problem of zero-shot local text-guided image manipulation by combining BigGAN / StyleGAN with CLIP a (p. 2)
GLIDE employs a two-stage diffusion-based approach for text-to-image synthesis: the first stage generates a low-resolution version of the image, while the second stage generates a higher resolution version of the image, conditioned on both the low-resolution version and the guiding text (p. 3)
DALL·E 2 performs text-to-image synthesis by mapping text prompts into CLIP image embeddings, followed by decoding such embeddings to images (p. 3)
LATENT DIFFUSION AND BLENDED DIFFUSION
each of the noisy images progressively generated by the CLIP-guided process is spatially blended with the corresponding noisy version of the input image. The main limitations of this method is its slow inference time (about (p. 3)
METHOD
Given an image 𝑥, a guiding text prompt 𝑑 and a binary mask𝑚 that marks the region of interest in the image, our goal is to produce a modified image 𝑥ˆ, s.t. the content 𝑥ˆ ⊙ 𝑚 is consistent with the text description 𝑑, while the complementary area remains close to the source image, i.e., 𝑥 ⊙ (1−𝑚) ≈ 𝑥ˆ ⊙ (1−𝑚) (p. 3)
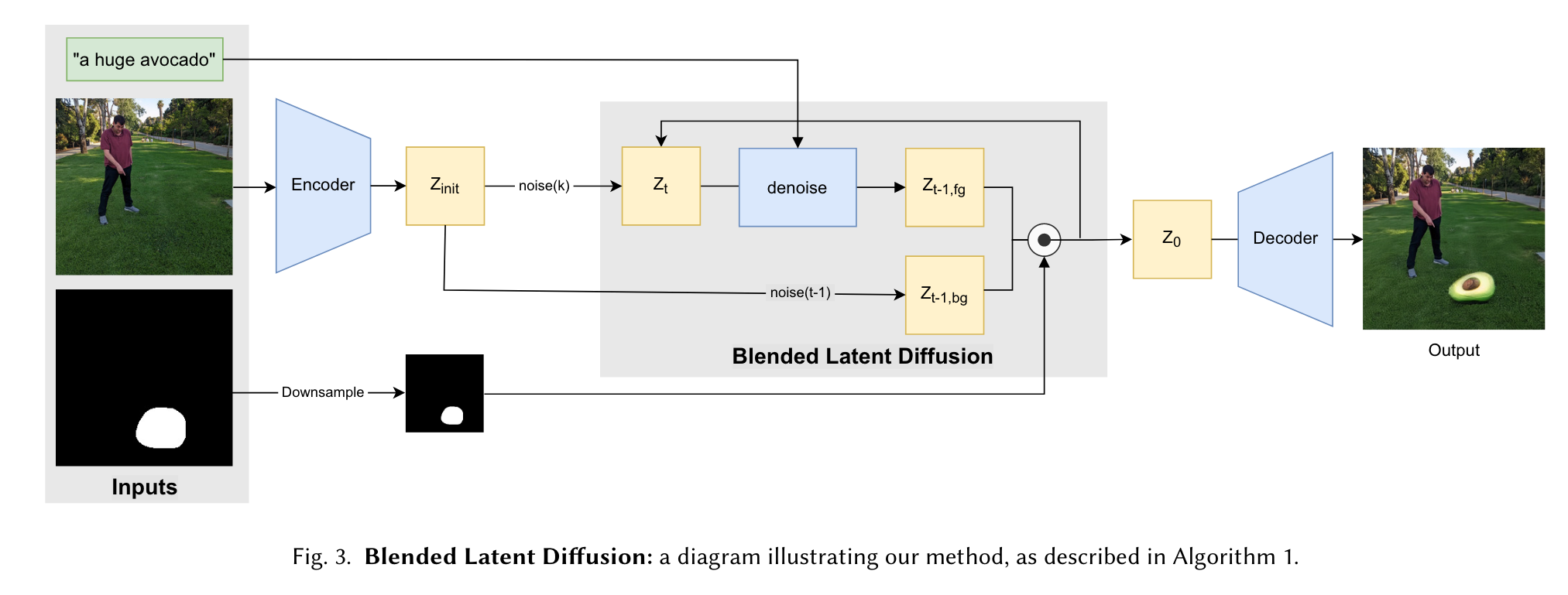
while also noising the original latent 𝑧_init to the current noise level to obtain a noisy background latent 𝑧_bg. The two latents are then blended using the resized mask, i.e. 𝑧_fg ⊙ 𝑚_latent + 𝑧_bg ⊙ (1 − 𝑚_latent). While the resulting blended latent is not guaranteed to be coherent, the next latent denoising step makes it so. (p. 4)
Background Reconstruction

A naïve way to deal with this problem is to stitch the original image and the edited result 𝑥ˆ at the pixel level, using the input mask 𝑚. However, because the unmasked areas were not generated by the decoder, there is no guarantee that the generated part will blend seamlessly with the surrounding background. Indeed (p. 5)
utilizing Poisson Image Editing [Pérez et al. 2003], which uses gradient-domain reconstruction in pixel space. However, this often results in a noticeable color shift of the edited area, as demonstrated in Figure 4(d). (p. 5)
could use latent optimization to search for a better vector 𝑧∗, s.t. the masked area will be similar to the edited image 𝑥ˆ and the unmasked area will be similar to the input image: \(z^\*=\mbox{argmin}_z{\lVert D(z)\cdots m-\hat{x}\cdots m\rVert+\lambda\lVert D(z)\cdots (1-m)-\hat{x}\cdots (1-m\rVert }\)
The inability of latent space optimization to capture the high frequency details suggests that the expressivity of the decoder 𝐷(𝑧) is limited. we can achieve seamless cloning by fine-tuning the decoder’s weights 𝜃 on a per-image basis (p. 5) \(\theta^\*=\mbox{argmin}_\theta{\lVert D_\theta(z)\cdots m-\hat{x}\cdots m\rVert+\lambda\lVert D_\theta(z)\cdots (1-m)-\hat{x}\cdots (1-m\rVert }\)
Progressive Mask Shrinking
The top row shows that even though the guiding text “fire” is echoed in the latents early in the process, blending these latents with 𝑧_bg using a thin 𝑚latent mask may cause the effect to disappear. (p. 6)
because the early noisy latents correspond to only the rough colors and shapes, we start with a rough, dilated version of 𝑚latent, and gradually shrink it as the diffusion process progresses, s.t. only the last denoising steps employ the thin𝑚latent mask when blending 𝑧fg with 𝑧bg. (p. 6)
Prediction Ranking
We rank the predictions by the normalized cosine distance between their CLIP embeddings and the CLIP embedding of the guiding prompt 𝑑 (p. 6)
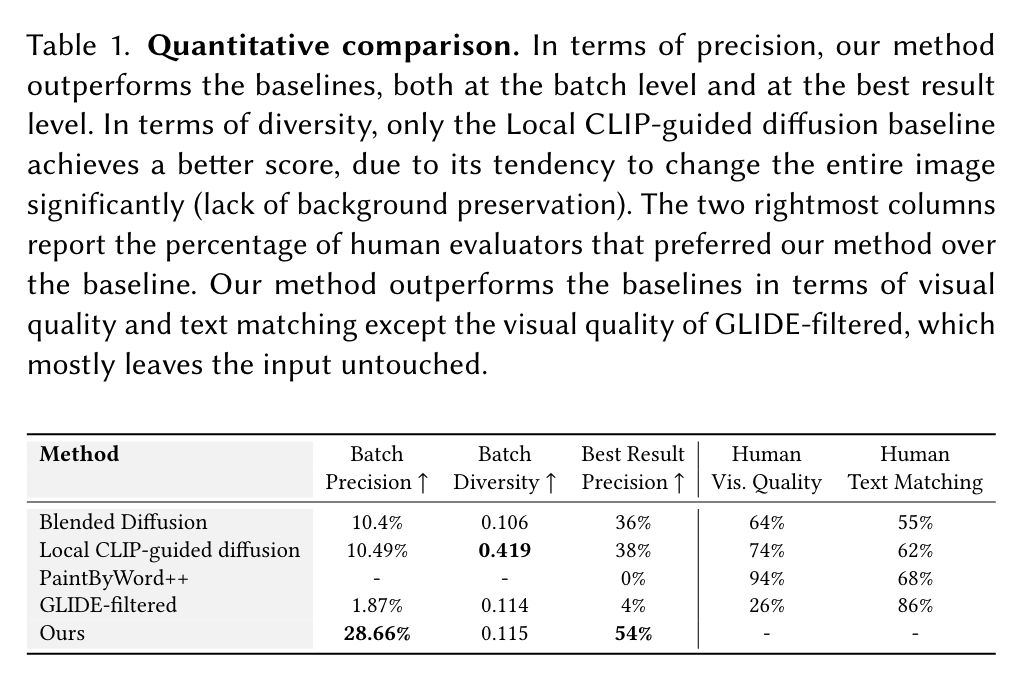
Experiment Result




Limitation
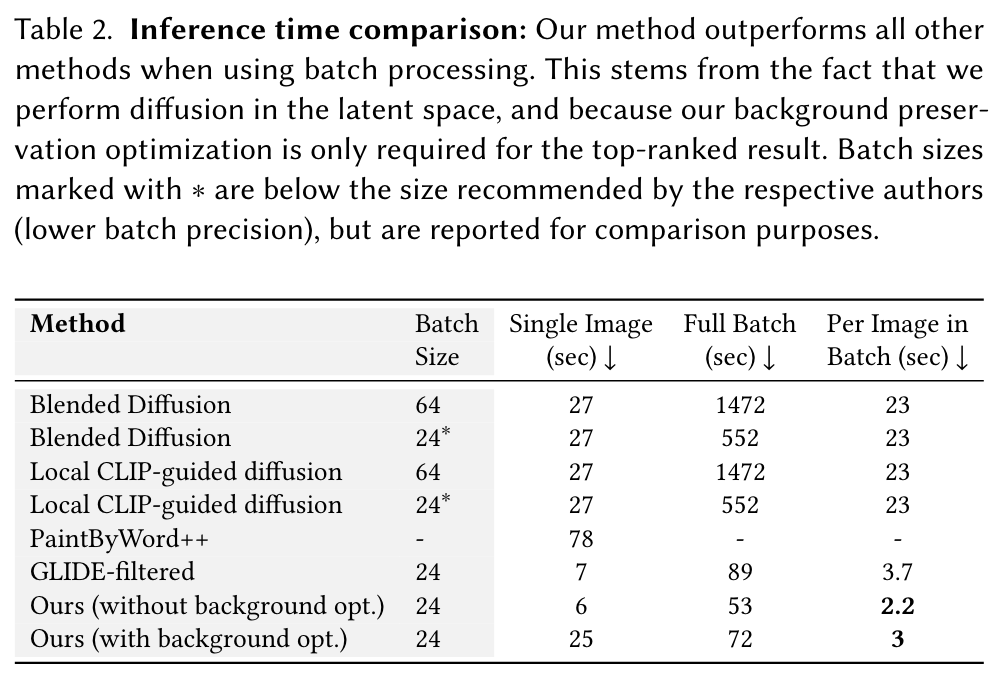
Although our method is significantly faster than prior works, it still takes over a minute on an A10 GPU to generate a ranked batch of predictions, due to the diffusion process. This limits the applicability of our method on lower-end devices. Hence, accelerating the inference time further is still an important research avenue.
As in Blended Diffusion, the CLIP-based ranking only takes into account the generated masked area. Without a more holistic view of the image, this ranking ignores the overall realism of the output image, which may result in images where each area is realistic, but the image does not look realistic overall, e.g., Figure 10(top). Thus, a better ranking system would prove useful.
Furthermore, we observe that LDM’s amazing ability to generate texts is a double-edged sword: the guiding text may be interpreted by the model as a text generation task. For example, Figure 10(bottom) demonstrates that instead of generating a big mountain, the model tries to generate a movie poster named “big mountain”.
In addition, we found our method to be somewhat sensitive to its inputs. Figure 11 demonstrates that small changes to the input prompt, to the input mask, or to the input image may result in small output changes. For more examples and details, please read Section D in the supplementary material.
Even without solving the aforementioned open problems, we have shown that our system can be used to locally edit images using text. Our results are realistic enough for real-world editing scenarios, and we are excited to see what users will create with the source code that we will release upon publication.