BLIP-Diffusion Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
[multimodality prompt2prompt clip imagen blip2 read diffusion blip text2image instructpix2pix textual-inversion re-imagen dreambooth transformer image2image suti This is my reading note for BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing. The paper proposes a method for generating an image with text prompt and target visual concept. To do that the paper trained blip model to align visual features with text prompt and then concatenate the visual embedding to the text prompt to generate the need. Code and models will be released at https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion. Project page at https://dxli94.github.io/BLIP-Diffusion-website/.
Introduction

BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup (p. 1)
The common approach to subject-driven generation [8–11] is through inverting subject visuals into text embedding space. Specifically, with a pretrained text-to-image generation model, a placeholder text embedding is optimized to reconstruct a set of subject images. The embedding is then composed into natural language prompts to create different subject renditions. One known inefficiency of this approach is that it requires reiterating hundreds [9, 10] or thousands [8] tedious fine-tuning steps for each new subject, which hinders it from efficiently scaling to a wide range of subjects. (p. 2)
We attribute such inefficiency to the fact that most pre-trained text-to-image models do not natively support multimodal control - using both images and texts as control input. As a result, it becomes challenging to learn subject representation that aligns with the text space while capturing the subject visuals with high fidelity. To overcome these limitations, we introduce BLIP-Diffusion, the first subject-driven text-to-image generation model with pre-trained generic subject representation, which enables subject-driven generation in zero-shot or with few-step fine-tuning. Our model builds upon a vision-language encoder (i.e. BLIP-2 [12]) and a latent diffusion model [6] (i.e. Stable Diffusion). The BLIP-2 encoder takes as input the subject image and its category text; it produces text-aligned subject representation as output. We then infix the subject representation in the prompt embedding to guide the latent diffusion model for subject-driven image generation and editing. (p. 2)
In the first pre-training stage, we perform multimodal representation learning, which enforces BLIP-2 to produce text-aligned visual features based on the input image. In the second pre-training stage, we design a subject representation learning task where the diffusion model learns to generate novel subject renditions based on the input visual features. To achieve this, we curate pairs of input-target images with the same subject appearing in different contexts. Specifically, we synthesize input images by composing the subject with a random background. During pre-training, we feed the synthetic input image and the subject class label through BLIP-2 to obtain the multimodal embeddings as subject representation. The subject representation is then combined with a text prompt to guide the generation of the target image (p. 2)
Related Works
- Textual Inversion [8] proposes to represent visual concepts using a placeholder text embedding, and optimize the embedding to reconstruct the subject images.
- DreamBooth [9] shares a similar methodology while additionally fine-tunes the diffusion model, which leads to better expressiveness and subject fidelity. One known drawback for both methods is their lengthy fine-tuning time for each new subject, which prevents the approaches from easily scaling up. (p. 3)
- the work [11, 17, 18] pre-train the diffusion model on domain-specific images, (p. 3)
- SuTI [19] proposes a knowledge distillation approach, which learns zero-shot generation from millions of fine-tuned expert models (p. 3)
Proposed Method
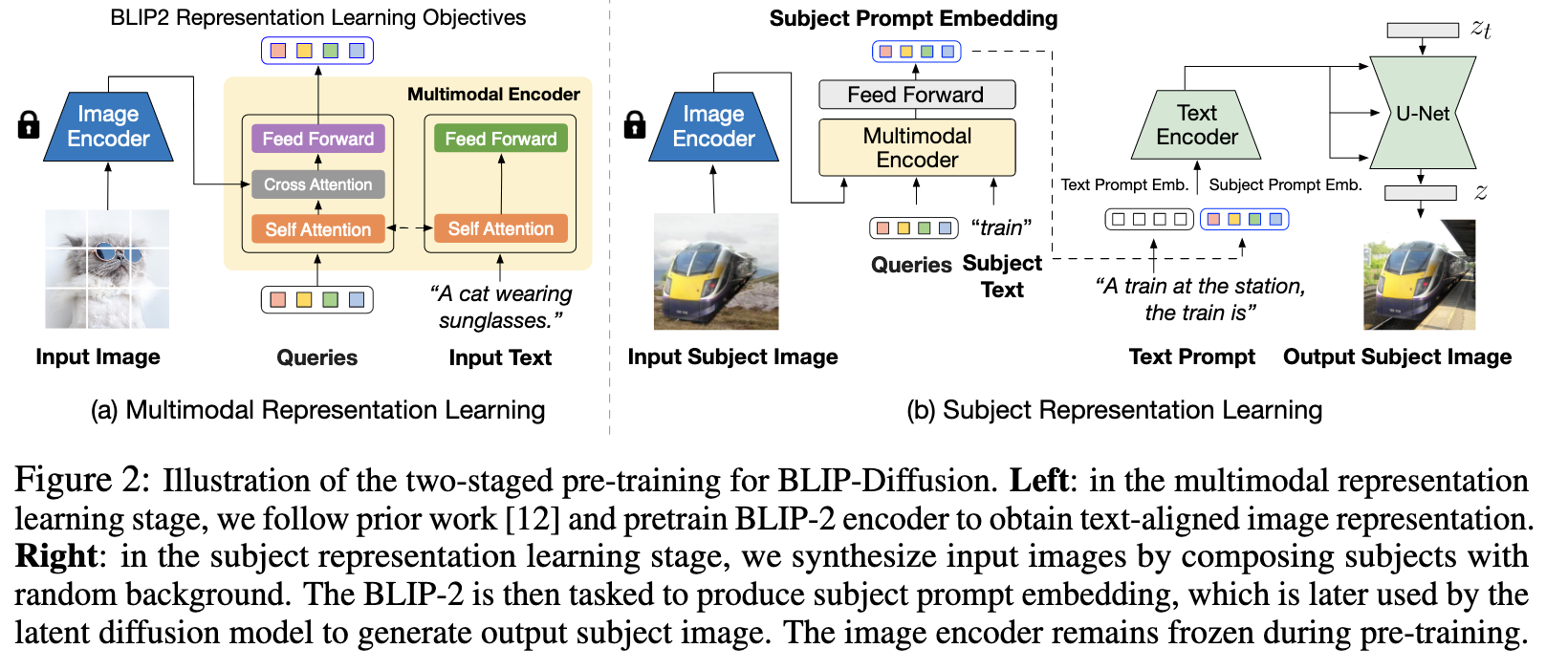
Multimodal Representation Learning with BLIP-2
Specifically, as shown in Figure 2a, we employ two main modules from BLIP-2 to learn multimodal representation: a frozen pre-trained image encoder to extract generic image features, and a multimodal encoder (i.e. Q-Former) for image-text alignment. The multimodal encoder is a transformer that accepts a fixed number of learnable query tokens and an input text. The query tokens interact with text through self-attention layers, and interact with frozen image features through cross-attention layers, and produces text-aligned image features as output. (p. 4)
Following BLIP-2 pre-training, we jointly train three vision-language pre-training objectives, includ- ing an image-text contrastive learning (ITC) loss that aligns the text and image representation by maximizing their mutual information, an image-grounded text generation (ITG) loss that generates texts for input images, and an image-text matching (ITM) loss that captures fine-grained image- text alignment via a binary prediction. (p. 4)
Subject Representation Learning with Stable Diffusion
We connect the output of the BLIP-2 multimodal encoder to the input of the diffusion model’s text encoder (p. 4)
To address these issues, we propose a new pre-training task for learning subject-generic representation, called prompted context generation, where we curate input-target training pairs by synthesizing images of the subject in random background. The model takes the synthesized subject image as input, and aims to generate the original subject image as output according to a text prompt. (p. 5)
Finally, we use the synthetic image as the input and the original subject image as the output to serve as one training image pair (p. 5)
Fine-tuning and Controllable Inference
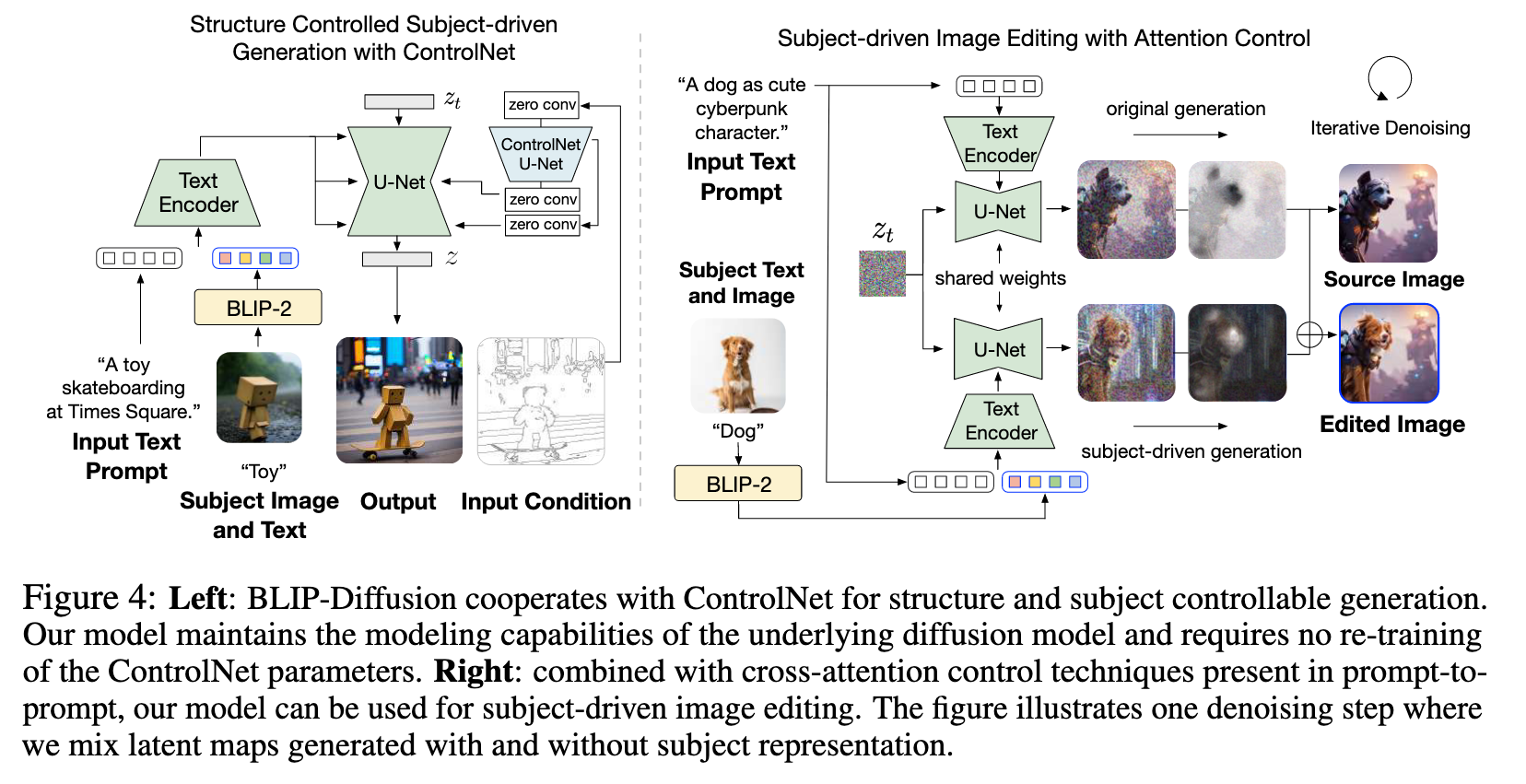
Subject-specific Fine-tuning and Inference. The pre-trained generic subject representation enables efficient fine-tuning for highly personalized subjects. Given a few subject images and the subject category text, we first use the multimodal encoder to obtain the subject representation individually. (p. 5) We then initialize the subject prompt embedding using the mean subject representation of all the subject images. In this way, we cache the subject prompt embedding without needing a forward pass of the multimodal encoder during fine-tuning. The diffusion model is fine-tuned to generate subject images as target by considering the text prompt embedding and the mean subject embedding. We also freeze the text encoder of the diffusion model, which we find helpful to counteract overfitting to target images. (p. 6)
Structure-controlled Generation with ControlNet. Our model introduces a multimodal condition-ing mechanism for subject-control. In the meanwhile, the architecture is also compatible to integrate with ControlNet [1] to achieve simultaneous structure-controlled and subject-controlled generation. (p. 6)
Subject-driven Editing with Attention Control. Our model combines subject prompt embeddingswith text prompt embeddings for multimodal controlled generation. Inspired by prompt-to-prompt [2], our model enables subject-driven image editing by manipulating the cross-attention maps of prompt tokens. (p. 6)
Experiment Results

Zero-shot Subject-driven Image Manipulation
Our model is able to extract subject features toguide the generation. In addition to applications of subject-driven generations and editing, we show that such pre-trained subject representation enables intriguing and useful applications of zero-shot image manipulation, including subject-driven style transfer and subject interpolation. (p. 9)
Subject-driven Style Transfer. When provided with a subject, the model can encode the appearancestyle of it and transfer to other subjects. We refer such an application as subject-driven style transfer. In Figure 8, we generate stylized reference subjects with the aid of edge-guided ControlNet. (p. 9)
Subject Interpolation. It is also possible to blend two subject representation to generate subjects witha hybrid appearance. This can be achieved by traversing the embedding trajectory between subjects. (p. 9)


Ablation Studies
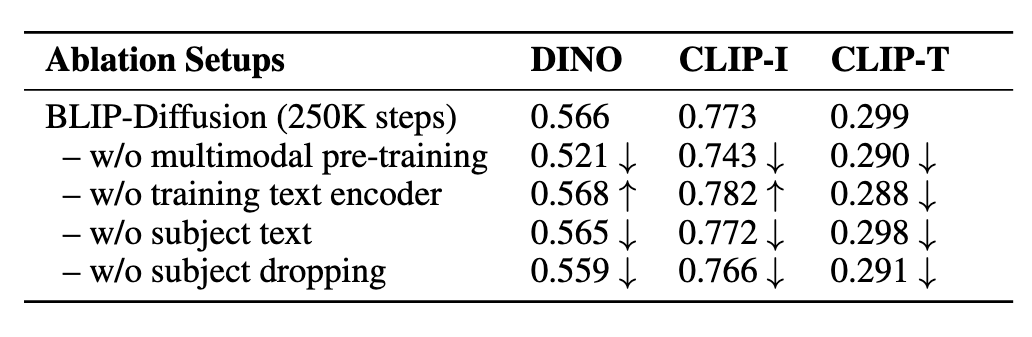
We conduct ablation studies using 250K subject representation learning steps.Table 2 shows zero-shot evaluation results. Our findings are: (i) it is critical to conduct multimodal representation learning (Section 3.1), which bridges the representation gap between subject embeddings and text prompt embeddings. (ii) freezing text encoder of the diffusion model worsens the interaction between subject embedding and text embedding. This leads to generations copying subject inputs and not respecting the text prompts. Despite leading to higher subject alignment scores, it does not allow text control, falsifying the task of text-to-image generation. (iii) Giving subject text to the multimodal encoder is helpful to inject class-specific visual priors, thereby leading to moderate improvement in metrics. (iv) Pre-training with random subject embedding dropping helps to better preserve the diffusion model’s generation ability, thus benefiting the results. (p. 9)
Limitations
Our model suffers from common failures of subject-driven generation models, such as incorrect context synthesis, overfitting to training set as detailed in [9]. In addition, it inherits some weakness of the underlying diffusion model, which may fail to understand text prompts and fine-grained composition relations. We show some of such failure examples in Figure10. (p. 10)
