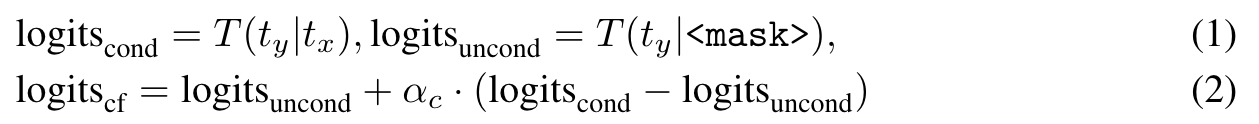Scaling Autoregressive Multi-Modal Models Pretraining and Instruction Tuning
[audio transformer multimodal deep-learning diffusion auto-regressive text2image This is my reading note for Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning. This paper proposes a method for text to image generation which is NOT based on diffusion. It utilizes auto-regressive model on tokens.

Introduction
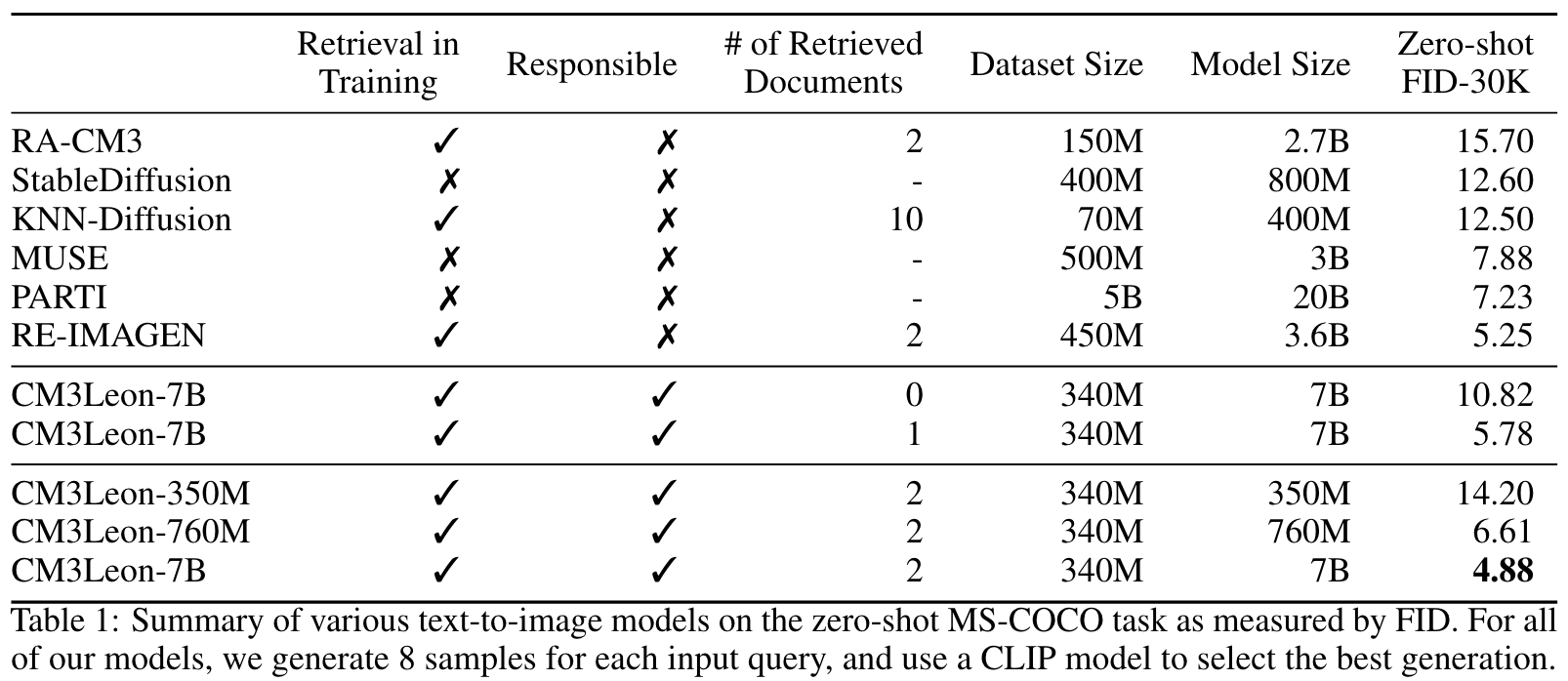
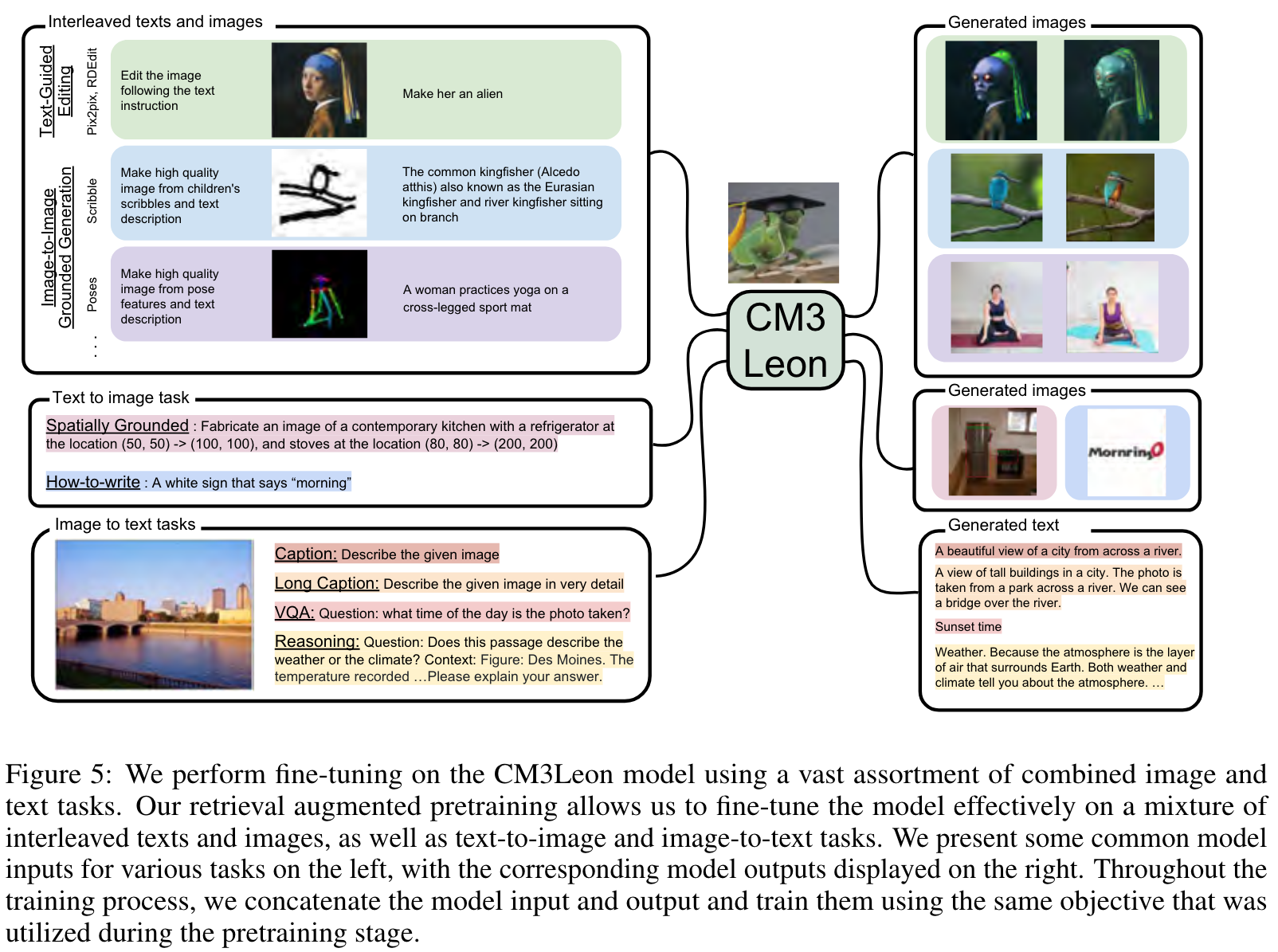
We present CM3Leon (pronounced “Chameleon”), a retrieval-augmented, tokenbased, decoder-only multi-modal language model capable of generating and infilling both text and images. It is the first multi-modal model trained with a recipe adapted from text-only language models, including a large-scale retrieval-augmented pretraining stage and a second multi-task supervised fine-tuning (SFT) stage. We introduce self-contained contrastive decoding methods that produce high-quality outputs (p. 2)
Diffusion models have recently dominated image generation work due to their strong performance and relatively modest computational cost (Saharia et al., 2022; Chen et al., 2022; Rombach et al., 2022). In contrast, token-based autoregressive models (Ramesh et al., 2021; Yu et al., 2022) are known to also produce strong results, with even better global image coherence in particular, but are much more expensive to train and use for inference. In this paper, we show that it is possible to extend training and inference ideas originally developed for text-only models to flip this narrative; autoregressive models can be efficient and performant while also generalizing beyond the strict text-to-image format to be tuneable for a wide range of image and text generation tasks. (p. 2)
Pretraining
Data
Image Tokenization
We use the image tokenizer from Gafni et al. (2022a), which encodes a 256 × 256 image into 1024 tokens from a vocabulary of 8192. (p. 3)
Retrieval Augmentation
Our retrieval approach aims to retrieve relevant and diverse multi-modal documents from a memory bank, given an input sequence (Yasunaga et al., 2022). It includes both a dense retriever and a retrieval strategy. (p. 3)
The dense retriever takes a query q (e.g., the input sequence x) and a candidate document m from the memory bank M and returns a relevance score r(q, m). We adopt the dense retrieval method from Karpukhin et al. (2020), which uses a bi-encoder architecture. The encoder is CLIP-based. We split the multi-modal document into a text part and an image part, encode them separately using off-the-shelf frozen CLIP text and image encoders, and then average the two as a vector representation of the document (Radford et al., 2021). (p. 3)
To sample informative retrieved documents for the generator during training, we consider three key factors: relevance, modality, and diversity. (p. 3)
Objective Function
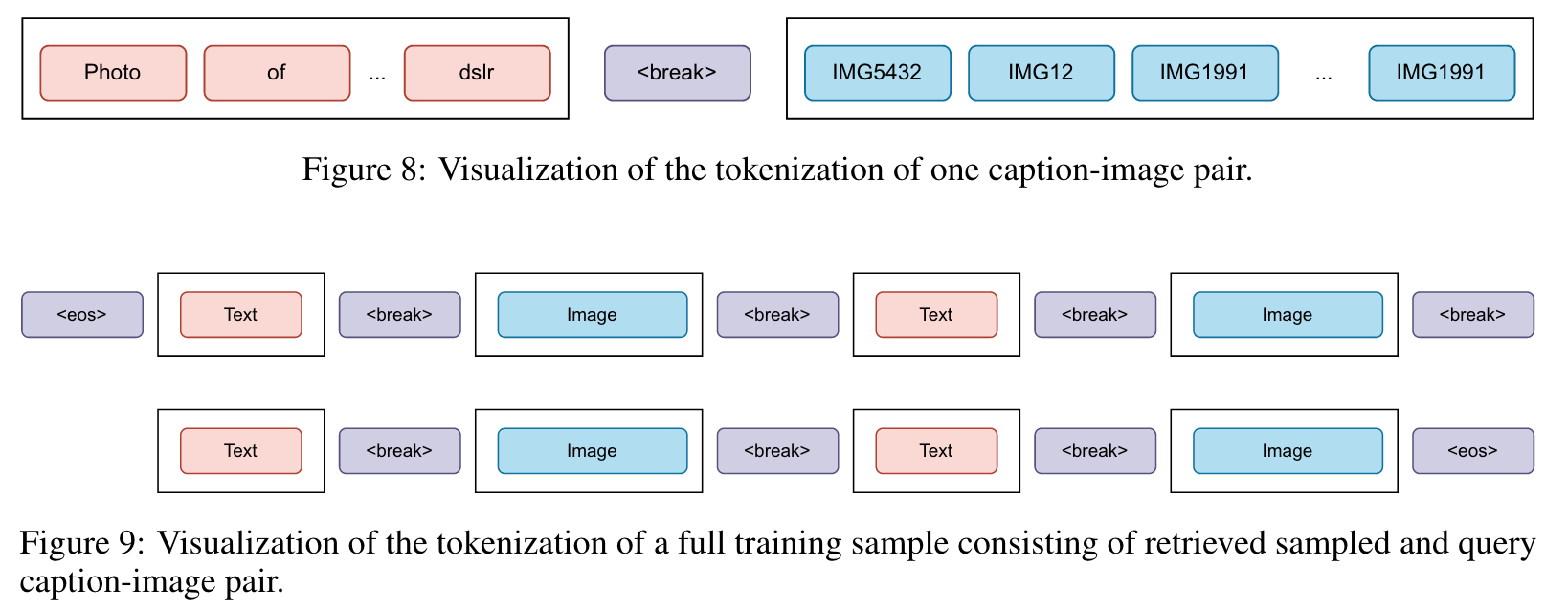
It uses a standard next token prediction loss, − log p(xinput). Yasunaga et al. (2022) built upon the original CM3 by including retrieved multi-modal documents in the context for each training example and up weighting the query image-caption pair loss, as illustrated in the last image-caption pair in Figure 9. (p. 3)
Text-To-Image Results
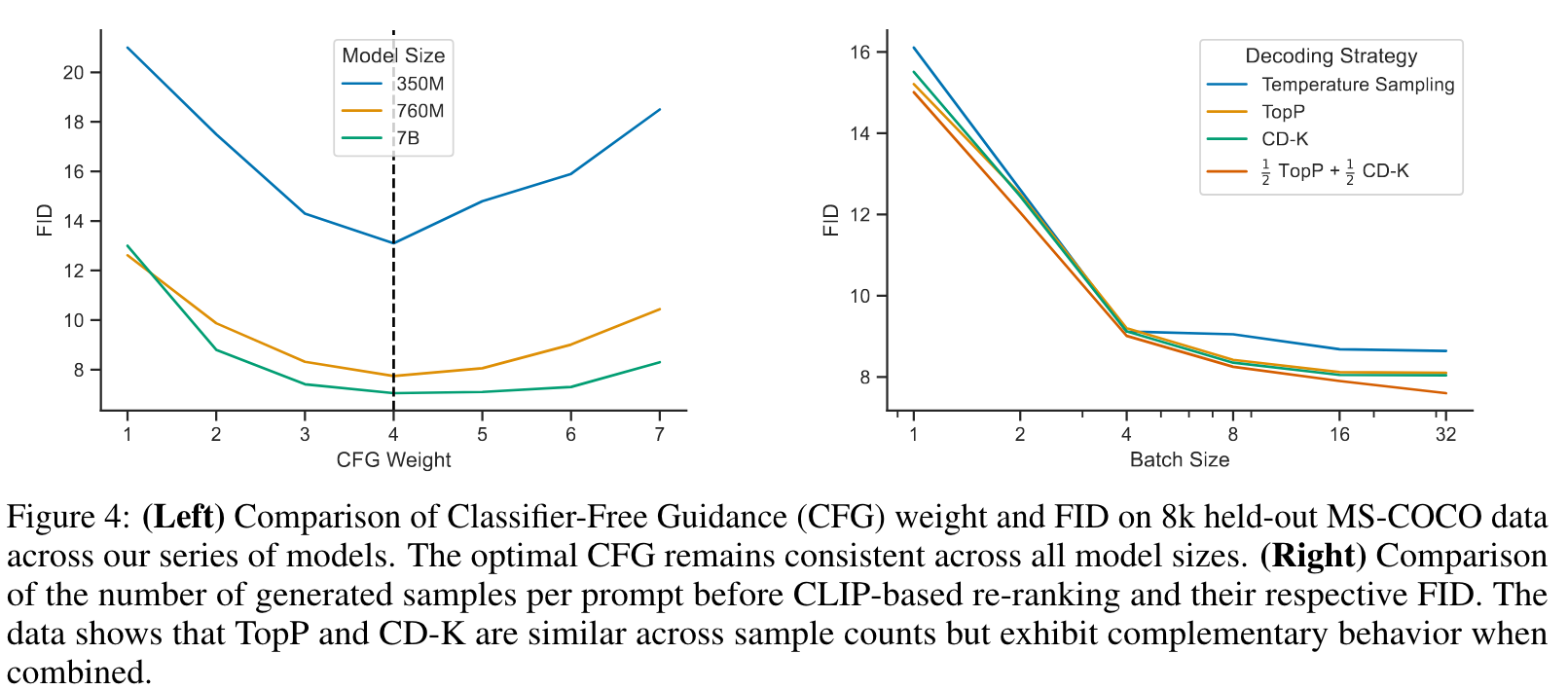
DALL-E employs temperature sampling and a re-ranking stage via CLIP over 512 prompt candidates. (p. 4)
Classifier Free Guidance (CFG)
During the inference stage, two concurrent token streams are generated: a conditional token stream, which is contingent on the input text, and an unconditional token stream, which is conditioned on a mask token. (p. 5)